『Scrapy』爬取腾讯招聘网站
分析爬取对象
初始网址,
http://hr.tencent.com/position.php?@start=0&start=0#a
(可选)由于含有多页数据,我们可以查看一下这些网址有什么相关

page2:http://hr.tencent.com/position.php?@start=0&start=10#a
page3:http://hr.tencent.com/position.php?@start=0&start=20#a
也就是说末尾id每次递增10(#a无实际意义,输入start=0也能进入第一页)。
确定想爬取的信息:
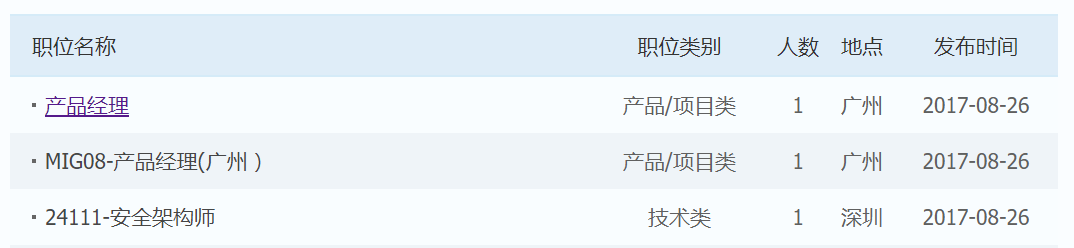
我们爬取表格中的5类信息和每个招聘的具体网页地址,共6个条目,在查看源码的过程中我们可以使用F12开发者工具辅助定位,
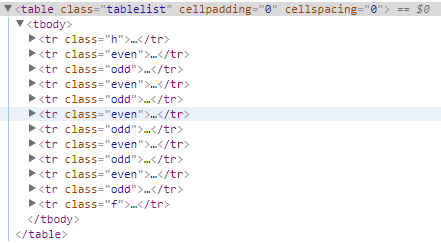
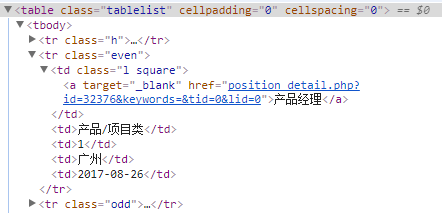
其中class=event的tr表示白色背景条目,class=odd表示灰色背景条目,点击开查看具体信息如下,
爬虫编写
使用框架初始化项目,
scrapy startproject Tencent
修改items.py,对应上面需要记录的六组数据,
import scrapy class TencentItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名
positionName = scrapy.Field()
# 职位详情链接
positionLink = scrapy.Field()
# 职位类别
positionType = scrapy.Field()
# 招聘人数
peopleNumber = scrapy.Field()
# 工作地点
workLocation = scrapy.Field()
# 发布时间
publishtime = scrapy.Field()
生成初始爬虫spider命名为tensent.py,
scrapy genspider tencent "tencent.com"
修改tencent.py,注意函数需要返回item
import scrapy
from Tencent.items import TencentItem class TencentSpider(scrapy.Spider):
name = "tencent"
allowed_domains = ["tencent.com"] baseURL = "http://hr.tencent.com/position.php?@start="
offset = 0
start_urls = [baseURL + str(offset)] def parse(self, response):
node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']") for node in node_list:
item = TencentItem() # 职位名
item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0]
print(node.xpath("./td[1]/a/text()").extract()) # 职位详情链接
item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0] # 职位类别
if len(node.xpath("./td[2]/text()")):
item['positionType'] = node.xpath("./td[2]/text()").extract()[0]
else:
item['positionType'] = '' # 招聘人数
item['peopleNumber'] = node.xpath("./td[3]/text()").extract()[0] # 工作地点
item['workLocation'] = node.xpath("./td[4]/text()").extract()[0] # 发布时间
item['publishtime'] = node.xpath("./td[5]/text()").extract()[0] yield item # 换页方法一:直接构建url
if self.offset <2190:
self.offset += 10
url = self.baseURL + str(self.offset)
yield scrapy.Request(url, callback=self.parse) # callback函数可以更换,即可以使用不同的处理方法处理不同的页面
两个yield连用使得不同的调用次数函数输出不同的表达式,这是一个很好的技巧,不过第二个yield是可以替换为return的,毕竟提交一个新请求后引擎会自动调用parse去处理响应
这里面使用提取下一页的方法是自己拼接之后的网址,这是一种相对而言笨拙一点的手法,一般会直接在网页中提取下一页的网址,但是这对于一些无法提取下一页网址的情况很实用。
更新一下直接在网页提取下一页的方法,
# 换页方法二:提取下页链接
if not len(response.xpath("//a[@class='noactive' and @id='next']")):
url = 'http://hr.tencent.com/' + response.xpath("//a[@id='next']/@href").extract()[0]
yield scrapy.Request(url, callback=self.parse)
对于静态页面这很容易,但是如果是动态页面就可能需要其他的辅助手段了。另外settings中有有关请求头文件的设置部分,有需求的话可以改写之。
取消settings.py对于管线文件的注释,

修改pipelines.py文件,
import json class TencentPipeline(object):
def __init__(self):
self.f = open('tencent.json','w') def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii=False) + ',\n'
self.f.write(content)
return item def close_spider(self,spider):
self.f.close()
这样一个初级的爬虫项目就完成了。
测试并运行,
scrapy check tencent
scarpy srawl tencent
打开保存的json文件,可以看到类似下面的输出,每一行为一条招聘信息,
{"workLocation": "深圳", "positionType": "技术类", "positionName": "24111-安全架构师", "peopleNumber": "1", "publishtime": "2017-08-26", "positionLink": "position_detail.php?id=32378&keywords=&tid=0&lid=0"},完成后整个文件夹变化如下,
实际爬取过程是要消耗一点时间的。
『Scrapy』爬取腾讯招聘网站的更多相关文章
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- scrapy框架爬取智联招聘网站上深圳地区python岗位信息。
爬取字段,公司名称,职位名称,公司详情的链接,薪资待遇,要求的工作经验年限 1,items中定义爬取字段 import scrapy class ZhilianzhaopinItem(scrapy.I ...
- 使用Scrapy框架爬取腾讯新闻
昨晚没事写的爬取腾讯新闻代码,在此贴出,可以参考完善. # -*- coding: utf-8 -*- import json from scrapy import Spider from scrap ...
- python3 scrapy 爬取腾讯招聘
安装scrapy不再赘述, 在控制台中输入scrapy startproject tencent 创建爬虫项目名字为 tencent 接着cd tencent 用pycharm打开tencent项目 ...
- scrapy 第一个案例(爬取腾讯招聘职位信息)
import scrapy import json class TzcSpider(scrapy.Spider): # spider的名字,唯一 name = 'tzc' # 起始地址 start_u ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
- Python 爬取腾讯招聘职位详情 2019/12/4有效
我爬取的是Python相关职位,先po上代码,(PS:本人小白,这是跟着B站教学视频学习后,老师留的作业,因为腾讯招聘的网站变动比较大,老师的代码已经无法运行,所以po上),一些想法和过程在后面. f ...
- 利用Crawlspider爬取腾讯招聘数据(全站,深度)
需求: 使用crawlSpider(全站)进行数据爬取 - 首页: 岗位名称,岗位类别 - 详情页:岗位职责 - 持久化存储 代码: 爬虫文件: from scrapy.linkextractors ...
随机推荐
- 生成word附件和word域动态赋值
生成word文档和word域动态赋值,很多时候需要生成这样的word文档供下载和打印,先制作一个包含了域的 word的模板附件,放在服务器端或者字节流存入数据库,以供需要的时候代码可以获取到,如: 其 ...
- python服务器端、客户端的模型,客服端发送请求,服务端进行响应(web.py)
服务器端.客户端的模型,客服端发送的请求,服务端的响应 相当于启动了一个web server install web.py 接口框架用到的包 http://webpy.org/tutorial3.zh ...
- java模拟表单上传文件,java通过模拟post方式提交表单实现图片上传功能实例
java模拟表单上传文件,java通过模拟post方式提交表单实现图片上传功能实例HttpClient 测试类,提供get post方法实例 package com.zdz.httpclient; i ...
- Window下安装npm
Node.js停火各大技术论坛都在讨论,前段时间工作太忙没时间学习,趁着周末空闲玩玩,在网上找了些资料发现Node.js本身有windows版和unix版下载和使用都挺方便但是其扩展模块依赖复杂通过手 ...
- P2455 [SDOI2006]线性方程组(real gauss)
P2455 [SDOI2006]线性方程组 (upd 2018.11.08: 这才是真正的高斯消元模板) 找到所消未知数(设为x)系数最大的式子,把它提上来 把这个式子的 x 系数约成1 把这个式子用 ...
- updateByPrimaryKeySelective更新失败
问题:使用Mybatis中Mapper内置方法updateByPrimaryKeySelective更新失败. 发现:控制台打印出来的sql语句发现where条件出现所有属性. 解决:映射的实体类没有 ...
- IDEA 插件-码云
插件安装 最新插件版本: 2018.3.1.(2019-01-10 发布)注意:码云 IDEA 插件已由 gitosc 更名为 gitee.新版插件 gitee 菜单已经和 git 菜单合并 通过「插 ...
- Python3基础 __add__,__sub__ 两个类的实例相互加减
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- DPDK的安装与绑定网卡
DPDK的安装有两种方法: 第一种是使用dpdk/tools/setup.sh选择命令字来安装:第二种是自己手动安装.为了更好地熟悉DPDK,我使用第二种方法. 0.设定环境变量 export RTE ...
- #网页中动态嵌入PDF文件/在线预览PDF内容#
摘要:在web开发时我们有时会需要在线预览PDF内容,在线嵌入pdf文件: 问题1:如何网页中嵌入PDF: 在网页中: 常用的几种PDF预览代码片段如下: 代码片段1: 1 <object ty ...