HashMap深入分析及使用要点
本文内容来自深入理解HashMap、从数据结构谈HashMap、HashMap深度分析
先说使用要点。
1、不要在并发场景中使用HashMap
HashMap是线程不安全的,如果被多个线程共享的操作,将会引发不可预知的问题。
2、如果数据大小是固定的,那么最好给HashMap设定一个合理的容量值
HashMap的初始默认容量是16,默认加载因子是0.75,也就是说,如果采用HashMap的默认构造函数,当增加数据时,数据实际容量超过16*0.75=12时,HashMap就扩容,扩容带来一系列的运算,新建一个是原来容量2倍的数组,对原有元素全部重新哈希,这是很耗费资源的。
好了,现在来对HashMap进行“深入分析”。
1、hashmap的数据结构
在java编程语言中,最基本的结构就是两种,一个是数组,另外一个是模拟指针(引用),所有的数据结构都可以用这两个基本结构来构造的,hashmap也不例外。Hashmap实际上是一个数组和链表的结合体(在数据结构中,一般称之为“链表散列“),请看下图(横排表示数组,纵排表示数组元素【实际上是一个链表】)。
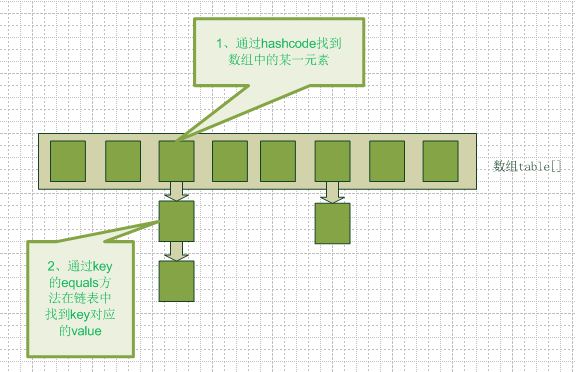
从图中我们可以看到一个hashmap就是一个数组结构,当新建一个hashmap的时候,就会初始化一个数组。
在HashMap里有这样的一句属性声明:
transient Entry[] table;
Entry就是HashMap存储数据所用的类,它拥有的属性如下:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
final int hash;
Entry<K,V> next;
..........
}
看到next了吗?它是一个指向下一个元素的引用,这就构成了链表。
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,将这个位置的原有Entry赋值给当前新加的 Entry的next属性,这样新加入的就放在了链头,而最先加入的就放在了链尾。
从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的,但是理想总是美好的,现实总是有困难需要我们去克服。哈希碰撞总是难免的,不过java里面使用了一个聪明的办法减少了哈希碰撞的几率,这个后面会讲到。
2、HashMap的操作。
现在来看看,当我们new、get、put的时候,HashMap到底都是怎么处理的。
先看初始化。
与初始化有关的关键参数如下:
/**
* 默认容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 等于 16 /**
* 最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30; //2的30次方 /**
* 默认加载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 当实际数据容量超过threshold时,HashMap会将容量扩容,threshold=容量*加载因子
*/
int threshold; /**
* 加载因子
*/
final float loadFactor;
HashMap有4个构造方法,值得一提的是下面这个:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
看这句: threshold = initialCapacity;
也就是说,如果构造时写成new HashMap(9,0.75);那么当容量超过9时,HashMap才会扩容,而不是9*0.75时就扩容。这里的initialCapacity建议写成2的倍数,至于为什么后面会说到。
然后是get。即如何获取我们要的元素。
其实前面已经提过了,在hashmap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。然后通过key的equals方法在对应位置的链表中找到需要的元素。
接下来是put 。
我们可以看到在hashmap中要找到某个元素,需要根据key的hash值来求得对应数组中的位置。如何计算这个位置就是hash算法。前面说过hashmap的数据结构是数组和链表的结合,所以我们当然希望这个hashmap里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个,那么当我们用hash算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。
所以我们首先想到的就是把hashcode对数组长度取模运算,这样一来,元素的分布相对来说是比较均匀的。但是,“模”运算的消耗还是比较大的,能不能找一种更快速,消耗更小的方式那?java中时这样做的:
static int indexFor(int h, int length) {
return h & (length-1);
}
首先算得key得hashcode值,然后跟数组的长度-1做一次“与”运算(&)。看上去很简单,其实比较有玄机。比如数组的长度是2的4次方,那么hashcode就会和2的4次方-1做“与”运算。很多人都有这个疑问,为什么hashmap的数组初始化大小都是2的次方大小时,hashmap的效率最高,我以2的4次方举例,来解释一下为什么数组大小为2的幂时hashmap访问的性能最高。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
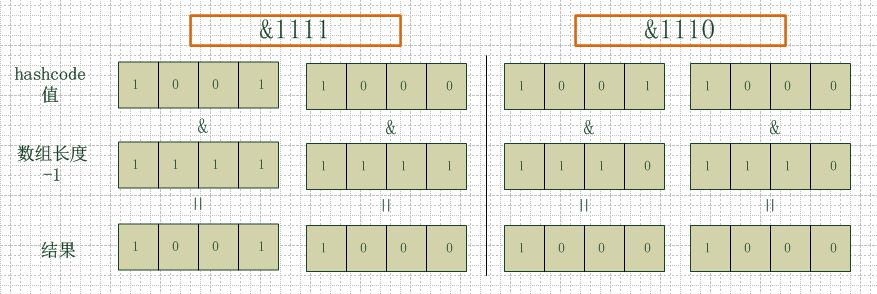
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
所以,在存储大容量数据的时候,最好预先指定hashmap的size为2的整数次幂次方。
接下来是resize,也就是扩容。
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。
最后说说HashMap死锁。才
死锁是扩容操作与put或get方法并发引起的,看源码:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;//切换线程1
e = next;
}
}
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];//切换线程2
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
table初始状态:
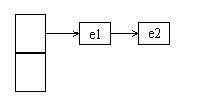
假设执行getEntry的线程1在e = table[indexFor(hash, table.length)]后切换到线程2的put方法,而且进行了扩容。此时table和newTable的状态是:
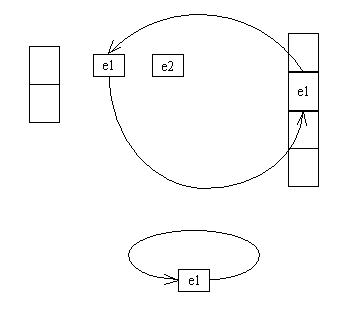
线程2在newTable[i] = e后切换到线程1,在for循环里e.next==e,永远不为空,若
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
不满足,就会进入死循环。
ok,先说这么多,感谢各位同行的分享。
HashMap深入分析及使用要点的更多相关文章
- Java中HashMap等的实现要点浅析
@南柯梦博客中的系列文章对Jdk中常用容器类ArrayList.LinkedList.HashMap.HashSet等的实现原理以代码注释的方式给予了说明(详见http://www.cnblogs.c ...
- JAVA提高十二:HashMap深入分析
首先想说的是关于HashMap源码的分析园子里面应该有很多,并且都是分析得很不错的文章,但是我还是想写出自己的学习总结,以便加深自己的理解,因此就有了此文,另外因为小孩过来了,因此更新速度可能放缓了, ...
- HashMap 深入分析
/** *@author annegu *@date 2009-12-02 */ Hashmap是一种非常常用的.应用广泛的数据类型,最近研究到相关的内容,就正好复习一下.网上 ...
- Eclipse的调试功能的10个小窍门[转]
原文链接:http://www.importnew.com/6164.html 你可能已经看过一些类似“关于调试的N件事”的文章了.但我想我每天大概在调试上会花掉1个小时,这是非常多的时间了.所以非常 ...
- 集合各个实现类的底层实现原理 ----- 原文地址:https://blog.csdn.net/qq_25868207/article/details/55259978
ArrayList实现原理要点概括 参考文献: http://zhangshixi.iteye.com/blog/674856l https://www.cnblogs.com/leesf456/p/ ...
- Java 集合类实现原理
转载自:http://blog.csdn.net/qq_25868207/article/details/55259978 :##ArrayList实现原理要点概括 参考文献:http://zhang ...
- Eclipse的调试功能的10个小窍门
你可能已经看过一些类似“关于调试的N件事”的文章了.但我想我每天大概在调试上会花掉1个小时,这是非常多的时间了.所以非常值得我们来了解一些用得到的功能,可以帮我们节约很多时间.所以在这个主题上值得我再 ...
- Java提高合集(转载)
转载自:http://www.cnblogs.com/pony1223/p/7643842.html Java提高十五:容器元素比较Comparable&Comparator深入分析 JAVA ...
- java23种设计模式等等。。
23种设计模式http://www.cnblogs.com/maowang1991/archive/2013/04/15/3023236.html 提升Java代码性能和安全性https://blog ...
随机推荐
- Scanner接收字符
char num = input.next().charAt(0); //截取指定位置的字符,下标从0开始 System.out.println("helloworld".char ...
- python selenium下拉框定位
一.前言 总结一下python+selenium select下拉选择框定位处理的两种方式,以备后续使用时查询: 二.直接定位(XPath) 使用Firebug找到需要定位到的元素,直接右键复制XPa ...
- C、C++的Makefile模板
目录 Makefile模板 用法 编译C程序 编译C++程序 其他 Tips Makefile模板 CC = gcc LD = $(CC) TARGET = $(notdir $(CURDIR)) S ...
- Qt5教程: (1) Hello World 程序
1. 新建工程 在Welcome界面选择New Project --> Application --> Qt Widgets Application --> Choose 输入工程名 ...
- ubuntu16.04安装zlib
sudo apt-get install zlib1g-dev 下载:libzip-1.0.1.tar.gztar zxcv libzip-1.0.1.tar.gzcd libzip-1.0.1./c ...
- 利用python模拟菜刀反弹shell绕过限制
有的时候我们在获取到目标电脑时候如果对方电脑又python 编译环境时可以利用python 反弹shell 主要用到python os库和sokect库 这里的服务端在目标机上运行 from sock ...
- python学习-列表、元组和字典(三)
学习笔记中的源码:传送门 3.1 列表和元组 3.2 不同类型变量的初始化: 数值 digital_value = 0 字符串 str_value = "" 或 str_value ...
- FileZilla Server超详细配置
FileZilla Server下载安装完成后,必须启动软件进行设置,由于此软件是英文,本来就是一款陌生的软件,再加上英文(注:本站提供中文版本,请点击下载),配置难度可想而知,站长从网上找到一篇非常 ...
- C# 表达式树 Expression
表达式树是定义代码的数据结构. 它们基于编译器用于分析代码和生成已编译输出的相同结构. 几种常见的表达式 BinaryExpression 包含二元运算符的表达式 BinaryExpression b ...
- 如何在 GitHub 的项目中创建一个分支呢?
如何在 GitHub 的项目中创建一个分支呢? 其实很简单啦,直接点击 Branch,然后在弹出的文本框中添加自己的 Branch Name 然后点击蓝色的Create branch就可以了,这样一来 ...