Kubernetes增强型调度器Volcano算法分析
【摘要】 Volcano 是基于 Kubernetes 的批处理系统,源自于华为云开源出来的。Volcano 方便 AI、大数据、基因、渲染等诸多行业通用计算框架接入,提供高性能任务调度引擎,高性能异构芯片管理,高性能任务运行管理等能力。

1 为什么K8S需要Volcano
K8S自带的的资源调度器,有一个明显的特点是:依次调度每个容器。但在AI训练或者大数据,这种必须多个容器同时配合执行的情况下,容器依次调度是无法满足需要的。因为这些计算任务包含的容器们想要的是,要么同时都成功,要么就都别执行。
比如,某个大数据应用需要跑1个Driver容器+10个Executor容器(对应AI训练的话,就是1个PS容器+10个Worker容器)。如果容器是一个一个的调度,假设在启动最后一个executor容器(对应AI是Worker容器)时,由于资源不足而调度失败无法启动。那么前面的9个executor容器虽然运行着,其实也是浪费的。AI训练也是一样的道理,必须所有的Worker都同时运行,才能进行训练,坏一个,其他的容器就等于白跑。而GPU被容器霸占着却不能开始计算,成本是非常高的。
所以当你的(1)总体资源需求<集群资源的时候,普通的K8S自带调度器可以跑,没问题。但是当(2)总体资源需求>集群资源的时候,K8S自带调度器会因为随机依次调度容器,使得部分容器无法调度,从而导致业务占着资源又不能开始计算,死锁着浪费资源。那么场景(1)和场景(2)谁说常态呢?不用说,肯定是(2)了,谁能大方到一直让集群空着呢对吧。这个时候就必须需要增强型的K8s资源调度器Volcano了。
2 资源调度领域
当用户向K8s申请容器所需的计算资源(如 CPU、Memory、GPU等)时,调度器负责挑选出满足各项规格要求的节点来部署这些容器。通常,满足各项要求的节点并非唯一,且水位(节点已有负载)各不相同,不同的分配方式最终得到的分配率存在差异,因此,调度器的一项核心任务就是以最终资源利用率最优的目标从众多候选机器中挑出最合适的节点。
除了资源维度上的要求,实际调度中还有容灾和干扰隔离上的考虑:比如同一应用的容器不允许全部部署到同一台节点上,很多应用会要求每台节点上只允许有一个实例。另外,某些应用组件之间还存在互斥关系(如资源争抢),严重影响应用的性能,因此也不允许它们被部署到同一台节点上。这些限制条件的引入,使得想新写一款调度器,能替代原生K8S调度器并不容易。
3 算法分析
Volcano首先要解决的问题就是Gang Scheduling的问题,即一组容器要么都成功,要么都别调度。这个是最基本的用来解决资源死锁的问题,可以很好的提高集群资源利用率(在高业务负载时)。除此之外,它还提供了多种调度算法,例如priority优先级,DRF(dominant resource fairness), binpack等。 我们今天就是挖一挖Volcano内部的各种调度算法实现。
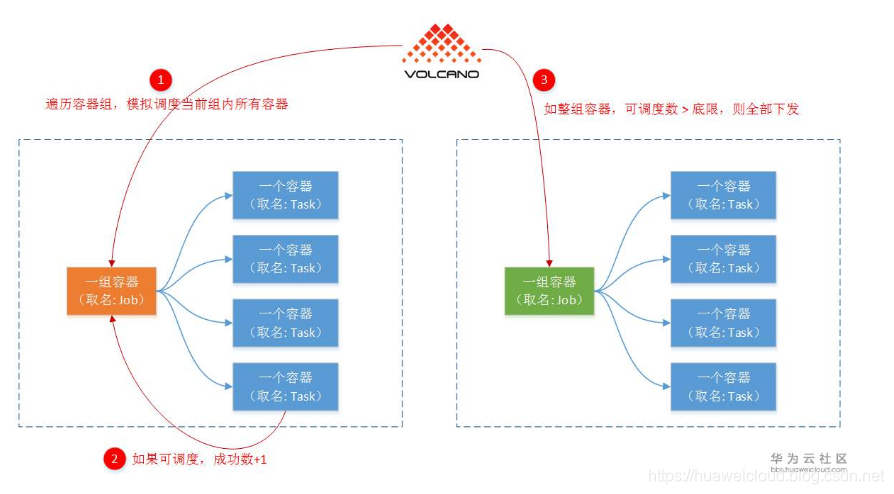
3.1 Gang Scheduling
这种调度算法,首先就是有’组’的概念,调度结果成功与否,只关注整一’组’容器。
具体算法是,先遍历各个容器组(代码里面称为Job),然后模拟调度这一组容器中的每个容器(代码里面称为Task)。最后判断这一组容器可调度容器数是否大于最小能接受底限,可以的话就真的往节点调度(代码里面称为Bind节点)。
3.2 DRF(dominant resource fairness)
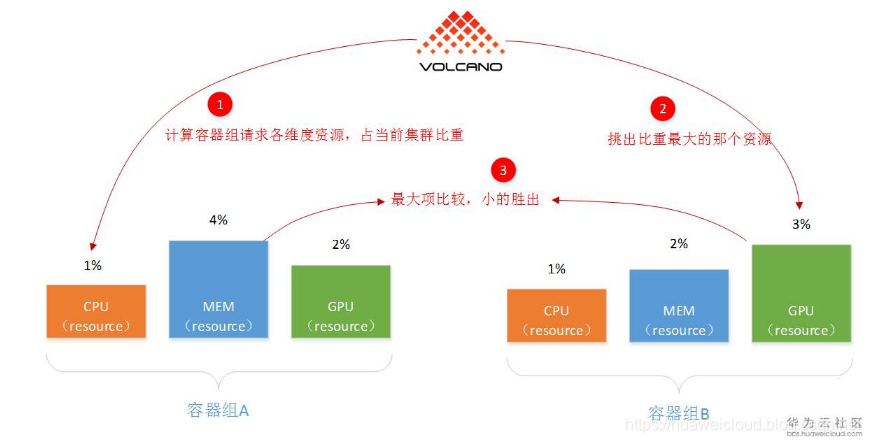
这种调度算法,主要是Yarn和Mesos都有,而K8S没有,需要补齐。概括而言,DRF意为:“谁要的资源少,谁的优先级高”。因为这样可以满足更多的作业,不会因为一个胖业务,饿死大批小业务。注意:这个算法选的也是容器组(比如一次AI训练,或一次大数据计算)。
3.3 binpack
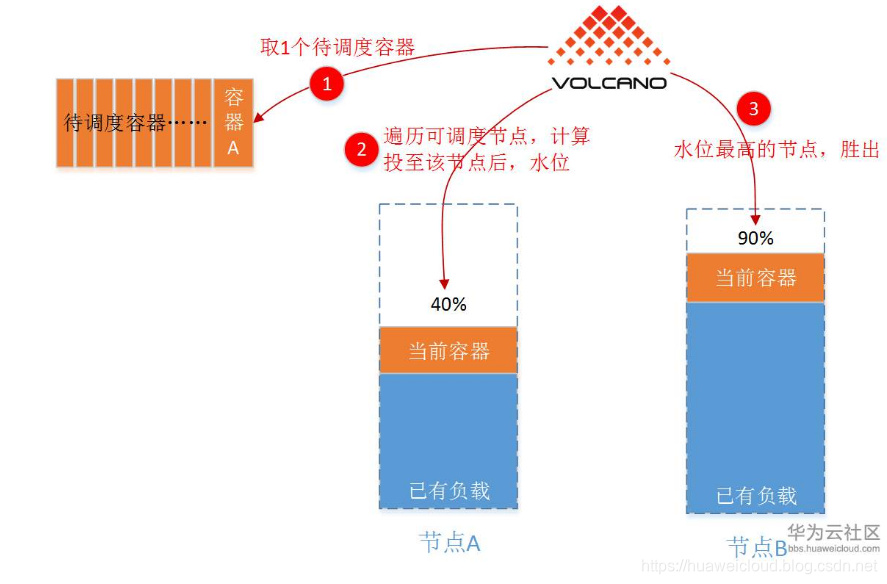
这种调度算法,目标很简单:尽量先把已有节点填满(尽量不往空白节点投)。具体实现上,binpack就是给各个可以投递的节点打分:“假如放在当前节点后,谁更满,谁的分数就高”。因为这样可以尽量将应用负载靠拢至部分节点,非常有利于K8S集群节点的自动扩缩容功能。注意:这个算法是针对单个容器的。
3.4 proportion(Queue队列)
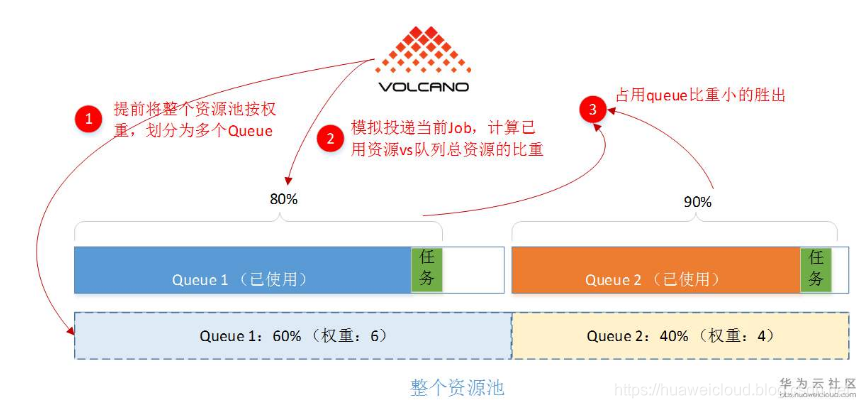
Queue功能是Yarn调度器有的功能,K8S需要补齐。不过我对Queue这个取名有些不太满意。因为它实际上是用来控制集群总资源分配比例的。比如说某厂有2个团队,共享一个计算资源池。管理员设置:A团队最多使用总集群的60%。然后B团队最多使用总集群的40%。那投递的任务量,超过该团队的可用资源怎么办?那就排队等呗,所以特性取名Queue。
3.5 最终权重
由于Volcano的调度算法插件实在太多,每个插件的决策又有可能互相干扰。所以为了在各个算法间做权衡,又给插件设置了权重,这样可以控制每种调度算法插件的影响因子。比如NodeOrder算法里面,就是在优选阶段(注:k8s调度,分预选阶段和优选阶段。预选就是排除不符合的节点。优选就是给所有符合的节点打分)给节点打分的算法。各个算法有自己的权重可以配置。
4 Volcano
Volcano项目的前身是Kube-Batch,一个带着想解决k8s不支持Gang Scheduling问题初衷的项目。后来由于AI和大数据等业务领域也开始对K8s有述求情况下,团队成员希望有一种喷薄而出的感觉,所以带上具体场景实践经验,重新将项目命名为Volcano,火山。希望能够推动K8S在各个场景下向火山一样热烈绽放。
如果有兴趣共享一份力量,可以访问 https://volcano.sh/ 参与。
作者:tsjsdbd
Kubernetes增强型调度器Volcano算法分析的更多相关文章
- Kubernetes增强型调度器Volcano算法分析【华为云技术分享】
[摘要] Volcano 是基于 Kubernetes 的批处理系统,源自于华为云开源出来的.Volcano 方便 AI.大数据.基因.渲染等诸多行业通用计算框架接入,提供高性能任务调度引擎,高性能异 ...
- 第十四章 kubernetes 核心技术-调度器
一.概述 一个容器平台的主要功能就是为容器分配运行时所需要的计算,存储和网络资源.容器调 度系统负责选择在最合适的主机上启动容器,并且将它们关联起来.它必须能够自动的处 理容器故障并且能够在更多的主机 ...
- TKE 用户故事 | 作业帮 Kubernetes 原生调度器优化实践
作者 吕亚霖,2019年加入作业帮,作业帮架构研发负责人,在作业帮期间主导了云原生架构演进.推动实施容器化改造.服务治理.GO微服务框架.DevOps的落地实践. 简介 调度系统的本质是为计算服务/任 ...
- Kubernetes之调度器和调度过程
scheduler 当Scheduler通过API server 的watch接口监听到新建Pod副本的信息后,它会检查所有符合该Pod要求的Node列表,开始执行Pod调度逻辑.调度成功后将Pod绑 ...
- Kubernetes集群调度器原理剖析及思考
简述 云环境或者计算仓库级别(将整个数据中心当做单个计算池)的集群管理系统通常会定义出工作负载的规范,并使用调度器将工作负载放置到集群恰当的位置.好的调度器可以让集群的工作处理更高效,同时提高资源利用 ...
- 第十五章 Kubernetes调度器
一.简介 Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上.听起来非常简单,但有很多要考虑的问题: ① 公平:如何保证每个节点都能被分配资源 ② ...
- kubernetes 调度器
调度器 kube-scheduler 是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理.更加充分 ...
- Kubernetes容器调度
Kubernetes的调度器是Kubernetes众多组件的一部分,独立于API服务器之外.调度器本身是可插拔的,任何理解调度器和API服务器之间调用关系的工程师都可以编写定制的调度器.本文后面的介绍 ...
- 泡面不好吃,我用了这篇k8s调度器,征服了他
1.1 调度器简介 来个小刘一起 装逼吧 ,今天我们来学习 K8的调度器 Scheduler是 Kubernetes的调度器,主要的任务是把定义的 pod分配到集群的节点上,需要考虑以下问题: 公平: ...
随机推荐
- RocketMQ 主从同步若干问题答疑
目录 1.初识主从同步 2.提出问题 3.原理探究 3.1 RocketMQ主从读写分离机制 3.2 消息消费进度同步机制 4.总结 温馨提示:建议参考代码RocketMQ4.4版本,4.5版本引入了 ...
- Appium+python自动化(四十)-Appium自动化测试框架综合实践 - 代码实现(超详解)
1.简介 今天我们紧接着上一篇继续分享Appium自动化测试框架综合实践 - 代码实现.由于时间的关系,宏哥这里用代码给小伙伴演示两个模块:注册和登录. 2.业务模块封装 因为现在各种APP的层出不群 ...
- Spring Boot2 系列教程(二十四)Spring Boot 整合 Jpa
Spring Boot 中的数据持久化方案前面给大伙介绍了两种了,一个是 JdbcTemplate,还有一个 MyBatis,JdbcTemplate 配置简单,使用也简单,但是功能也非常有限,MyB ...
- pat 1120 Friend Numbers(20 分)
1120 Friend Numbers(20 分) Two integers are called "friend numbers" if they share the same ...
- 【dp】 AreYouBusy
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3535 题意: 多组背包, 0类型为为至少去1样, 1为至多取1样, 2 为随意. 如果将2类型 再添加 ...
- 数据类型转换&运算符
基本数据类型注意事项 整型类型:long>int>short>byte java默认类型为int型 long a = 123 表示将int类型的数值赋给更大范围的long类型,当数据 ...
- 纯css实现tab导航
仿照这个 实现了一个纯css的导航功能 html <div class="main"> <div id="contain1">列表一内容 ...
- MyEclipse使用总结
0.快捷键 ================================================================================ 编辑: Ctrl+Shif ...
- 容器镜像服务联手 IDE 插件,实现一键部署、持续集成与交付
容器技术提供了一种标准化的交付方式,将应用的代码以及代码环境依赖都打包在一起,成为一个与环境无关的交付物,可以被用在软件生命周期的任何阶段,彻底改变了传统的软件交付方式. 甚至可以说,是在容器技术之后 ...
- 驰骋工作流系统-Java共工作流引擎配置定时任务
关键词:工作流定时任务 流程引擎定时任务设置 工作流系统定时任务配置 开源工作流引擎 开源工作流系统 一.定时任务的作用 发送邮件,发送短信. 处理节点自动执行的任务.比如:一个节点的待办工作是 ...