真正的打包scrapy单文件(不包含cfg)
前置:https://www.cnblogs.com/luocodes/p/11827850.html
解决最后一个问题,如何将scrapy真正的打包成单文件
耗了一晚上时间,今天突然有灵感了
错误分析
不将scrapy.cfg文件与可执行文件放一起,那么就会报错---爬虫没有找到
报错的原因
1.scrapy.cfg文件放入不进可执行文件中
2.scrapy目录读取不到scrapy.cfg文件
问题1
pyinstaller是将可执行文件解压到系统的临时文件中,在进行运行的
所以我们只需要在可执行文件中找到它的目录就能了解我们打包的文件中到底包含了什么
这里还有一个问题,每当可执行文件运行完毕后,它产生的temp文件将会被删除,所以我们在start.py中加一下输入
这样一来程序不退出,临时文件也随之保留了下来,方便我们查看
# -*- coding: utf-8 -*-
from scrapy.cmdline import execute
from scrapy.utils.python import garbage_collect
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings # import robotparser
import os
import sys
import scrapy.spiderloader
import scrapy.statscollectors
import scrapy.logformatter
import scrapy.dupefilters
import scrapy.squeues import scrapy.extensions.spiderstate
import scrapy.extensions.corestats
import scrapy.extensions.telnet
import scrapy.extensions.logstats
import scrapy.extensions.memusage
import scrapy.extensions.memdebug
import scrapy.extensions.feedexport
import scrapy.extensions.closespider
import scrapy.extensions.debug
import scrapy.extensions.httpcache
import scrapy.extensions.statsmailer
import scrapy.extensions.throttle import scrapy.core.scheduler
import scrapy.core.engine
import scrapy.core.scraper
import scrapy.core.spidermw
import scrapy.core.downloader import scrapy.downloadermiddlewares.stats
import scrapy.downloadermiddlewares.httpcache
import scrapy.downloadermiddlewares.cookies
import scrapy.downloadermiddlewares.useragent
import scrapy.downloadermiddlewares.httpproxy
import scrapy.downloadermiddlewares.ajaxcrawl
import scrapy.downloadermiddlewares.chunked
import scrapy.downloadermiddlewares.decompression
import scrapy.downloadermiddlewares.defaultheaders
import scrapy.downloadermiddlewares.downloadtimeout
import scrapy.downloadermiddlewares.httpauth
import scrapy.downloadermiddlewares.httpcompression
import scrapy.downloadermiddlewares.redirect
import scrapy.downloadermiddlewares.retry
import scrapy.downloadermiddlewares.robotstxt import scrapy.spidermiddlewares.depth
import scrapy.spidermiddlewares.httperror
import scrapy.spidermiddlewares.offsite
import scrapy.spidermiddlewares.referer
import scrapy.spidermiddlewares.urllength import scrapy.pipelines import scrapy.core.downloader.handlers.http
import scrapy.core.downloader.contextfactory import scrapy.core.downloader.handlers.file
import scrapy.core.downloader.handlers.ftp
import scrapy.core.downloader.handlers.datauri
import scrapy.core.downloader.handlers.s3 print(sys.path[0]) print(sys.argv[0]) print(os.path.dirname(os.path.realpath(sys.executable))) print(os.path.dirname(os.path.realpath(sys.argv[0])))
cfg=os.path.join(os.path.split(sys.path[0])[0],"scrapy.cfg")
print(cfg)
input() process = CrawlerProcess(get_project_settings()) process.crawl('biqubao_spider',domain='biqubao.com')
process.start() # the script will block here until the crawling is finished
经过尝试只有sys.path这个函数是获取到temp文件的位置.
cfg这个变量就是我后来得出的scrapy.cfg在temp目录下的位置 产生的temp文件如下:
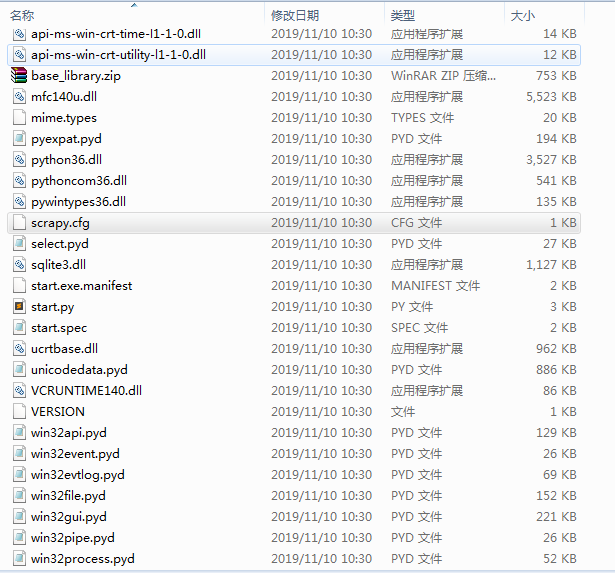
temp文件中包含了cfg,我们继续测试一下,在temp文件中运行start.py文件,发现这里是可以正常运行的
那么问题所在就是scrapy读取不到cfg文件所产生的
问题2
如何让scrapy读取到cfg文件呢?
经过调试,我找到了一个scrapy读取cfg文件路径的函数
#scrapy\utils\conf.py
def get_sources(use_closest=True):
xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or \
os.path.expanduser('~/.config')
sources = ['/etc/scrapy.cfg', r'c:\scrapy\scrapy.cfg',
xdg_config_home + '/scrapy.cfg',
os.path.expanduser('~/.scrapy.cfg')]
if use_closest:
sources.append(closest_scrapy_cfg())
return sources
函数的sources 是一个cfg文件路径的数组
经过问题1的测试,那么我们这时候会想到了我们执行了单文件,导致了scrapy读取的是单文件路径下的cfg,而不是temp文件中的cfg
那么这时候只要在sources中添加单文件执行后产生的temp文件就能正确的读取到cfg文件了
def get_sources(use_closest=True):
xdg_config_home = os.environ.get('XDG_CONFIG_HOME') or \
os.path.expanduser('~/.config')
sources = ['/etc/scrapy.cfg', r'c:\scrapy\scrapy.cfg',
xdg_config_home + '/scrapy.cfg',
os.path.expanduser('~/.scrapy.cfg'),os.path.join(os.path.split(sys.path[0])[0],"scrapy.cfg")]
if use_closest:
sources.append(closest_scrapy_cfg())
return sources
重新打包,发现移动单个的可执行文件也不会报错了!
真正的打包scrapy单文件(不包含cfg)的更多相关文章
- webpack打包vue单文件组件
一.vue单文件组件 ①文件扩展名为 .vue 的 就是single-file components(单文件组件) ②参考文档:单文件组件 二.webpack加载第三方包 ①项目中,如果需要用到一些第 ...
- maven打包可以行文件,包含依赖包等
<build> <!-- 设定打包的名称 --> <finalName>ismp2xy</finalName> <plugins> < ...
- .NET5.0 单文件发布打包操作深度剖析
.NET5.0 单文件发布打包操作深度剖析 前言 随着 .NET5.0 Preview 8 的发布,许多新功能正在被社区成员一一探索:这其中就包含了"单文件发布"这个炫酷的功能,实 ...
- [原创] 绿色单文件封装程序GreenOne V3.0
1.原理 将包含可执行文件的多个文件 调用Winrar,创建自解压格式压缩文件 设置高级自解压选项中的文本和图标,设置解压后运行的文件为选中的可执行文件. 这种创建单文件封装其实也就是一个Winrar ...
- AOT和单文件发布对程序性能的影响
前言 这里先和大家介绍一下.NET一些发布的历史,以前的.NET框架原生并不支持最终编译结果的单文件发布(需要依赖第三方工具),我这里新建了一个简单的ASP.NET Core项目,发布以后的目录就会像 ...
- 将Python项目打包成EXE可执行文件(单文件,多文件,包含图片)
解决 将Python项目打包成EXE可执行文件(单文件,多文件,包含图片) 1.当我们写了一个Python的项目时,特别是一个GUI项目,我们特备希望它能成为一个在Windows系统可执行的EXE文件 ...
- 《DotNet Web应用单文件部署系列》二、打包wwwroot文件夹
在这篇文章中,你将学到web缓存规则,文件传输中用到的压缩格式,以及如何手写代码响应请求.最后还能学到快速打包wwwroot文件夹组件用法. 一.了解Response Header 当第一次加载程序时 ...
- 软件打包为exe NSIS单文件封包工具V2.3
NSIS单文件封包工具V2.3 这是一款基于NSIS模块的封包制作工具,lzma算法最大压缩率,支持制作单文件,以及NSIS自定义解压封包. 支持注册dll,exe,reg,bat文件 默认提取设置程 ...
- QT发布的EXE打包压缩成单文件
Enigma virtual box 是免费的软件虚拟化工具,它可以将多个文件封装到您的应用程序主文件,这样您的软件就可以制作成为单文件的绿色软件. enigma virtual box 支持所有类型 ...
随机推荐
- CSS 选择符有哪些?哪些属性可以继承?优先级算法如何计算?
CSS 选择符有哪些? 1.id选择器(#id) 2.类选择器(.class) 3.标签选择器(div,h1,p) 4.相邻选择器(h1 + p) 5.子选择器(ul > li) 6.后代选择器 ...
- python编程基础之十六
for in 循环,与其说是循环不如说精确点交遍历 for 变量名 in + 迭代对象 语句A else: 语句B 作用:一次访问迭代对象中的元素并赋值给变量 循环终止时,执行else语句块,如果br ...
- 【元学习】Meta Learning 介绍
目录 元学习(Meta-learning) 元学习被用在了哪些地方? Few-Shot Learning(小样本学习) 最近的元学习方法如何工作 Model-Agnostic Meta-Learnin ...
- Mac搭建 Eclipse +Pydev+Python 环境
Mac配置Python开发环境(Eclipse +Pydev+Python) 1.首先下载MAC版的64位Eclipse. eclips下载地址打开链接,选择需要的版本下载 2.下载Python. M ...
- sql数据文件导入数据库
1.首先通过xshell连接数据库服务器,执行命令mysql -u root -p 命令,按照提示输入密码.连接上数据库. 2.在连接终端上执行命令create database JD_Model; ...
- Java 面试-即时编译( JIT )
当我们在写代码时,一个方法内部的行数自然是越少越好,这样逻辑清晰.方便阅读,其实好处远不止如此,通过即时编译,甚至可以提高执行时的性能,今天就让我们好好来了解一下其中的原理. 简介 当 JVM 的初始 ...
- 渗透测试-基于白名单执行payload--Regsvr32
复现亮神课程 基于白名单执行payload--Regsvr32 0x01 Regsvr32 Regsvr32命令用于注册COM组件,是 Windows 系统提供的用来向系统注册控件或者卸载控件的命令, ...
- Vuex使用总结
Vuex 是什么? Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化. Vuex的五个核心概念 ...
- photometric_stereo halcon光度立体法三维表面重建
官方文档翻译 名称: photometric_stereo -- 通过光度立体技术重建表面. 签名: photometric_stereo(Images : HeightField, Gradient ...
- 从Go语言编码角度解释实现简易区块链——实现交易
在公链基础上实现区块链交易 区块链的目的,是能够安全可靠的存储交易,比如我们常见的比特币的交易,这里我们会以比特币为例实现区块链上的通用交易.上一节用简单的数据结构完成了区块链的公链,本节在此基础上对 ...