“达观杯”文本分类--baseline
结合tfidf权重,对“达观杯”提供的文本,进行文本分类,作为baseline,后续改进均基于此。
1.比赛地址及数据来源
2.代码及解析
# -*- coding: utf-8 -*- """
@简介:tfidf特征/ SVM模型
@成绩: 0.77
"""
#导入所需要的软件包
import pandas as pd
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer print("开始...............") #====================================================================================================================
# @代码功能简介:从硬盘上读取已下载好的数据,并进行简单处理
# @知识点定位:数据预处理
#====================================================================================================================
df_train = pd.read_csv('./data/train_set.csv') # 数据读取
df_test = pd.read_csv('./data/test_set.csv') # 观察数据,原始数据包含id、article(原文)列、word_seg(分词列)、class(类别标签)
df_train.drop(columns=['article', 'id'], inplace=True) # drop删除列
df_test.drop(columns=['article'], inplace=True) #==========================================================
# @代码功能简介:将数据集中的字符文本转换成数字向量,以便计算机能够进行处理(一段文字 ---> 一个向量)
# @知识点定位:特征工程
#==========================================================
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9)
'''
ngram_range=(1, 2) : 词组长度为1和2
min_df : 忽略出现频率小于3的词
max_df : 忽略在百分之九十以上的文本中出现过的词
'''
vectorizer.fit(df_train['word_seg']) # 构造tfidf矩阵
x_train = vectorizer.transform(df_train['word_seg']) # 构造训练集的tfidf矩阵
x_test = vectorizer.transform(df_test['word_seg']) # 构造测试的tfidf矩阵 y_train = df_train['class']-1 #训练集的类别标签(减1方便计算) #==========================================================
# @代码功能简介:训练一个分类器
# @知识点定位:传统监督学习算法之线性逻辑回归模型
#========================================================== classifier = LinearSVC() # 实例化逻辑回归模型
classifier.fit(x_train, y_train) # 模型训练,传入训练集及其标签 #根据上面训练好的分类器对测试集的每个样本进行预测
y_test = classifier.predict(x_test) #将测试集的预测结果保存至本地
df_test['class'] = y_test.tolist()
df_test['class'] = df_test['class'] + 1
df_result = df_test.loc[:, ['id', 'class']]
df_result.to_csv('./results/beginner.csv', index=False) print("完成...............")
3.问题修复
由于提供的数据集较大,一般运行时间再10到15分钟之间,基础电脑配置在4核8G的样子(越消耗内存在6.2G),因此,一般可能会遇到内存溢出的错误。

可限制每次读取的数据量,具体解决办法如下:
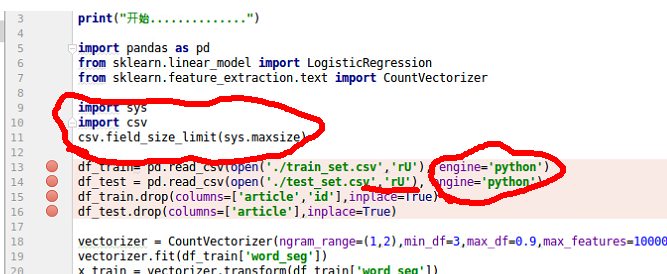
当然,你也可以换一个配置更高的电脑。
“达观杯”文本分类--baseline的更多相关文章
- Bert文本分类实践(一):实现一个简单的分类模型
写在前面 文本分类是nlp中一个非常重要的任务,也是非常适合入坑nlp的第一个完整项目.虽然文本分类看似简单,但里面的门道好多好多,作者水平有限,只能将平时用到的方法和trick在此做个记录和分享,希 ...
- Bert文本分类实践(二):魔改Bert,融合TextCNN的新思路
写在前面 文本分类是nlp中一个非常重要的任务,也是非常适合入坑nlp的第一个完整项目.虽然文本分类看似简单,但里面的门道好多好多,博主水平有限,只能将平时用到的方法和trick在此做个记录和分享 ...
- python - 实现文本分类[简单使用第三方库完成]
第三方库 pandas sklearn 数据集 来自于达观杯 训练:train.txt 测试:test.txt 概述 TF-IDF 模型提取特征值建立逻辑回归模型 代码 # _*_ coding:ut ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- fastText文本分类算法
1.概述 FastText 文本分类算法是有Facebook AI Research 提出的一种简单的模型.实验表明一般情况下,FastText 算法能获得和深度模型相同的精度,但是计算时间却要远远小 ...
- FastText 文本分类使用心得
http://blog.csdn.net/thriving_fcl/article/details/53239856 最近在一个项目里使用了fasttext[1], 这是facebook今年开源的一个 ...
- NLP(七) 信息抽取和文本分类
命名实体 专有名词:人名 地名 产品名 例句 命名实体 Hampi is on the South Bank of Tungabhabra river Hampi,Tungabhabra River ...
- NLP(十六)轻松上手文本分类
背景介绍 文本分类是NLP中的常见的重要任务之一,它的主要功能就是将输入的文本以及文本的类别训练出一个模型,使之具有一定的泛化能力,能够对新文本进行较好地预测.它的应用很广泛,在很多领域发挥着重要 ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
随机推荐
- unity UI事件
由于工作需要到持续按键,所以了解了一下unity UI事件,本文主要转载于http://www.cnblogs.com/zou90512/p/3995932.html?utm_source=tuico ...
- 三、进程和线程、协程在python中的使用
三.进程和线程.协程在python中的使用 1.多进程一般使用multiprocessing库,来利用多核CPU,主要是用在CPU密集型的程序上,当然生产者消费者这种也可以使用.多进程的优势就是一个子 ...
- MySQL存储引擎简介-MyISAM和InnoDB的区别
上篇文章<MySql逻辑结构简介>我们聊到了存储引擎,可以说MySQL可插拔的多元化存储引擎给我们的使用者带来了很灵活的选择. 这篇文章我们来聊一下目前主流的两种存储引擎MyISAM和In ...
- 开源.Net Standard版华为物联网北向接口SDK
最近用到了华为的物联网平台API,但是官方没有.Net版的SDK,所以就自己封装了一个,开源出来给有需要的朋友,同时也算是为.Net Core的发展做点小贡献~ 源码地址:https://github ...
- [考试反思]0926csp-s模拟测试52:审判
也好. 该来的迟早会来. 反思再说吧. 向下跳过直到另一条分界线 %%%cbx也拿到了他的第一个AK了呢. 我的还是遥不可及. 我恨你,DeepinC. 我恨透你了.你亲手埋葬所有希望,令我无比气愤. ...
- 如何在SqlServer中使用层级节点类型hierarchyid
Sql Server2008开始新增的 hierarchyid 数据类型使存储和查询层次结构数据变得更为简单. 为了使用这个类型,笔者在此进行简单记录,同时为需要的朋友提供一个简单的参考. --获取层 ...
- vscode react自动补全html标签
第一步:点击上图左下角设置,找到Settings,搜索includeLanguages 第二步:如上图点击图中红色区域,settings.json 第三部:把代码加入,如上图红色选择区域. " ...
- NOIP 模拟29 B 侥幸
这次考得好纯属是侥幸,我T3打表试数试了两个小时,没有想打T2的正解(其实是打不出来)所以这个T3A掉纯属是侥幸,以后还是要打正解 (以下博客最好按全选观看,鬼知道为啥这个样子!) 在这里也口胡一下我 ...
- Elasticsearch系列---Elasticsearch的基本概念及工作原理
基本概念 Elasticsearch有几个核心的概念,花几分钟时间了解一下,有助于后面章节的学习. NRT Near Realtime,近实时,有两个层面的含义,一是从写入一条数据到这条数据可以被搜索 ...
- PHP curl下载图片的方法
PHP curl下载图片的方法 <pre> <?php $images = [ 'http://wx.qlogo.cn/mmopen/vi_32/Q0j4TwGTfTKPkia3rx ...