Json模块(dumps、loads、dump、load)函数篇
# dumps、loads函数
"""
json.dumps()用于将dict类型的数据转成str
json.loads()用于将str类型的数据转成dict。 """
import json student = {
"name":"liuming",
"age":18,
"mobile":"13585660040"
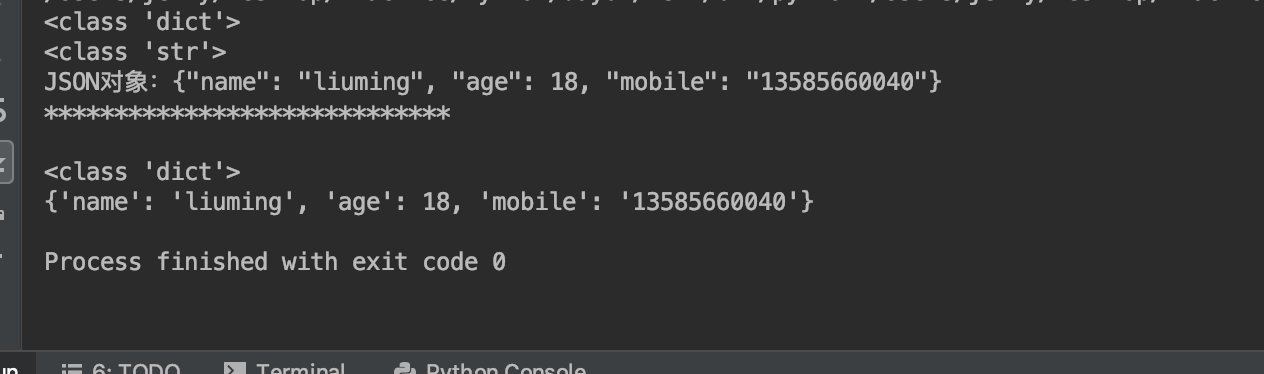
} print(type(student)) # 把python对象(字典)转化为json格式
stu_json = json.dumps(student)
print(type(stu_json))
print("JSON对象:{0}".format(stu_json)) print("*****************************\n\r") # 把json格式转化为 python对象(字典dict)
stu_dict = json.loads(stu_json)
print(type(stu_dict))
print(stu_dict) 运行结果如下:
# dump、load函数
"""
json.dump()用于将dict类型的数据转成str,并写入到json文件中。
json.load()用于从json文件中读取数据。 """
import json student = {
"name":"liuming",
"age":18,
"mobile":"13585660040"
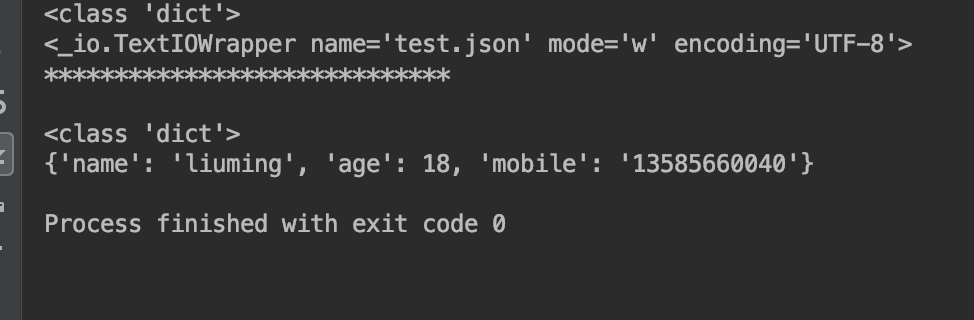
} print(type(student)) # 将dict类型转为str,并写入到json文件中
# 把内容写入文件
with open("test.json", "w") as f:
print(f)
json.dump(student,f) print("*****************************\n\r") with open("test.json","r") as r:
d = json.load(r)
print(type(d))
print(d) 运行结果如下:
Json模块(dumps、loads、dump、load)函数篇的更多相关文章
- 细说【json&pickle】dumps,loads,dump,load的区别
1 json.dumps() json.dumps()是将字典类型转化成字符串类型. import json name_emb = {'a':'1111','b':'2222','c':'3333', ...
- Python json模块dumps loads
python中json数据的使用. dumps和loads也是需要成对使用的,就像c++ new/delete malloc/free一样需要成对使用. 看着像json的字符串,也不一定是json字符 ...
- Json模块dumps、loads、dump、load函数介绍
转自:http://blog.csdn.net/mr_evanchen/article/details/77879967 Json模块dumps.loads.dump.load函数介绍 1.json. ...
- Python中的Json模块dumps、loads、dump、load函数介绍
Json模块dumps.loads.dump.load函数介绍 1.json.dumps() json.dumps() 用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json ...
- JSON实现序列化dump和dumps方法,JSON实现反序列化loads和load方法
通过文件操作,我们可以将字符串写入到一个本地文件.但是,如果是一个对象(例如列表.字典.元组等),就无 法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里. 设计一套协议,按照某种 ...
- python:Json模块dumps、loads、dump、load介绍
由上篇文章(python3+requests:get/post请求)涉及到的json.dumps()扩展 1.json.dumps()用于将dict类型的数据转成str 备注:文件路径前面加上 r 是 ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- Python中的序列化以及pickle和json模块介绍
Python中的序列化指的是在程序运行期间,变量都是在内存中保存着的,如果我们想保留一些运行中的变量值,就可以使用序列化操作把变量内容从内存保存到磁盘中,在Python中这个操作叫pickling,等 ...
- json模块和pickle模块的用法
在python中,可以使用pickle和json两个模块对数据进行序列化操作 其中: json可以用于字符串或者字典等与python数据类型之间的序列化与反序列化操作 pickle可以用于python ...
随机推荐
- 致初学者(二): HDU 2014~ 2032题解
下面继续给出HDU 2014~2032的AC程序,供大家参考.2014~2032这19道题就被归结为“C语言程序设计练习(三) ”~“C语言程序设计练习(五) ”. HDU 2014:青年歌手大奖赛_ ...
- [大数据学习研究]1.在Mac上利用VirtualBox搭建本地虚拟机环境
1. 大数据和Hadoop 研究学习大数据,自然要从Hadoop开始. Hadoop不是一个简单的软件,而是有一些列软件形成的生态,其核心思想来自Google当初发布的三篇论文,后来做了开源的实现, ...
- RocksDB线程局部缓存
概述 在开发过程中,我们经常会遇到并发问题,解决并发问题通常的方法是加锁保护,比如常用的spinlock,mutex或者rwlock,当然也可以采用无锁编程,对实现要求就比较高了.对于任何一个共享变量 ...
- 基于vue实现搜索高亮关键字
有一个需求是在已有列表中搜索关键词,然后在列表中展示含有相关关键字的数据项并且对关键字进行高亮显示,所以该需求需要解决的就两个问题: 1.搜索关键词过滤列表数据 2.每个列表高亮关键字 ps: 此问题 ...
- spring项目与logstash和Elasticsearch整合
原创/朱季谦 最近在做一个将项目日志通过logstash传到Elasticsearch的功能模块,经过一番捣鼓,终于把这个过程给走通了,根据自己的经验,做了这篇总结文章,希望可以给各位玩logst ...
- MySQL性能优化以及常用命令
1.将查询操作SELECT中WHERE条件后面和排序字段建立索引 2.按需查询,需要哪个字段就查哪个字段,禁止使用"SELECT * " 3.数据库引擎最好选用InnoDB,少用M ...
- [python]兔子问题,斐波那契数列 递归&非递归
假设一对幼年兔子需要一个月长成成年兔子,一对成年兔子一个月后每个月都可以繁衍出一对新的幼年兔子(即兔子诞生两个月后开始繁殖).不考虑死亡的情况,问第 N 个月时共有多少对兔子? 结果前几个月的兔子数量 ...
- abp(net core)+easyui+efcore实现仓储管理系统——EasyUI之货物管理二 (二十)
abp(net core)+easyui+efcore实现仓储管理系统目录 abp(net core)+easyui+efcore实现仓储管理系统——ABP总体介绍(一) abp(net core)+ ...
- Javascript的基础
ECMAScript(语法.标准) BOM(浏览器) DOM(网页) ECMAScript是一个标准,它规定了语法.类型.语句.关键字.保留子.操作符.对象.(相当于法律) BOM(浏览器对象模型): ...
- 单例模式-全局可用的 context 对象,这一篇就够了
单例模式在各个方面都有着极为广泛的使用,所谓单例,顾名思义就是整个程序中只有一个该类的实例,所以它成功保证了整个程序的生命周期内该类的对象只能创建一次,并且提供全局唯一访问该类的方法:getInsta ...