Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言
最近 TL 分享了下 《Elasticsearch基础整理》https://www.jianshu.com/p/e8226138485d ,蹭着这个机会。写个小文巩固下,本文主要讲 ES -> Lucene
的底层结构,然后详细描述新数据写入 ES 和 Lucene 的流程和原理。这是基础理论知识,整理了一下,希望能对 Elasticsearch 感兴趣的同学有所帮助。
一、Elasticsearch & Lucene 是什么

什么是 Elasticsearch ?
Elasticsearch 是一个基于 Apache Lucene(TM) 的开源搜索引擎。
那 Lucene 是什么?
无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库,并通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 不仅仅是 Lucene 和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
二、Elasticsearch & Lucene 的关系

就像很多业务系统是基于 Spring 实现一样,Elasticsearch 和 Lucene 的关系很简单:Elasticsearch 是基于 Lucene 实现的。ES 基于底层这些包,然后进行了扩展,提供了更多的更丰富的查询语句,并且通过 RESTful API 可以更方便地与底层交互。类似 ES 还有 Solr 也是基于 Lucene 实现的。
在应用开发中,用 Elasticsearch 会很简单。但是如果你直接用 Lucene,会有大量的集成工作。
因此,入门 ES 的同学,稍微了解下 Lucene 即可。如果往高级走,还是需要学习 Lucene 底层的原理。因为倒排索引、打分机制、全文检索原理、分词原理等等,这些都是不会过时的技术。
三、新文档写入流程
3.1 数据模型
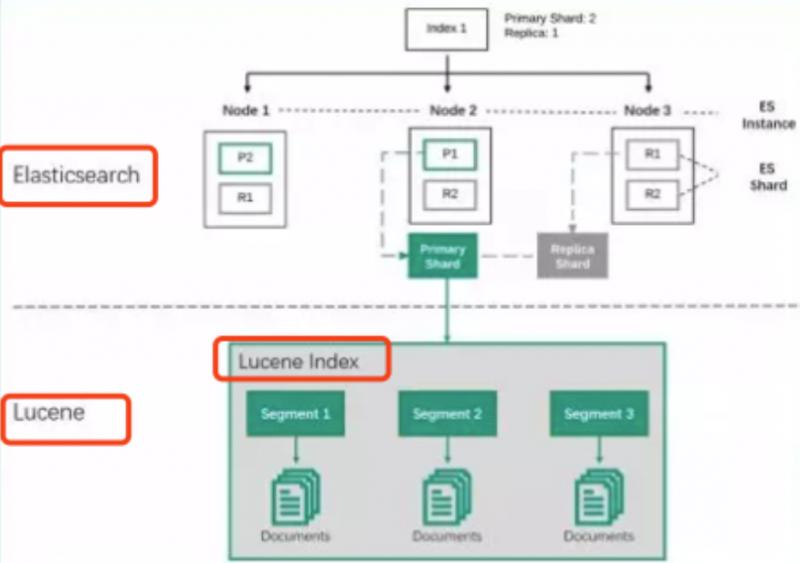
如图
- 一个 ES Index (索引,比如商品搜索索引、订单搜索索引)集群下,有多个 Node (节点)组成。每个节点就是 ES 的实例。
- 每个节点上会有多个 shard (分片), P1 P2 是主分片 R1 R2 是副本分片
- 每个分片上对应着就是一个 Lucene Index(底层索引文件)
- Lucene Index 是一个统称。由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
3.2 Lucene Index
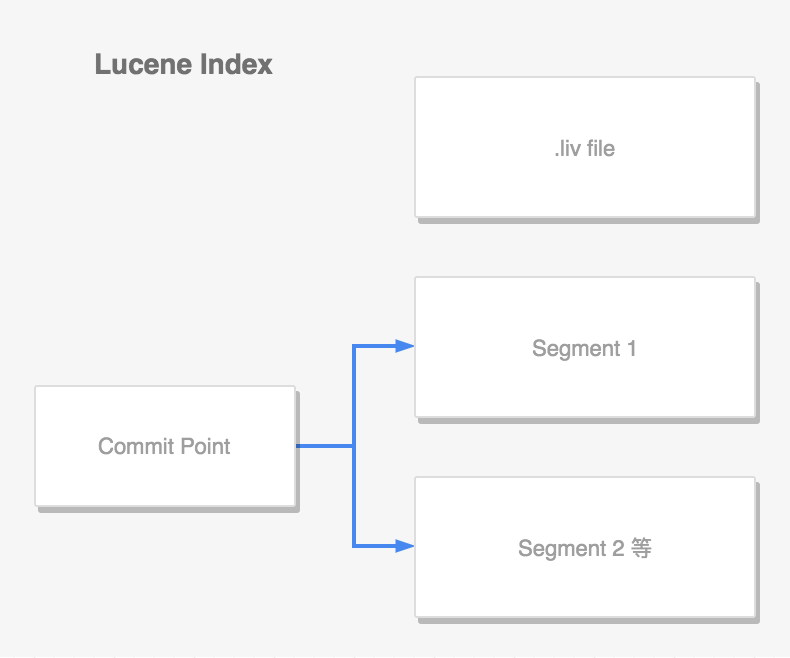
lucene 中,单个倒排索引文件称为 segment。其中有一个文件,记录了所有 segments 的信息,称为 commit point:
- 文档 create 新写入时,会生成新的 segment。同样会记录到 commit point 里面
- 文档查询,会查询所有的 segments
- 当一个段存在文档被删除,会维护该信息在 .liv 文件里面
3.3 新文档写入流程
新文档创建或者更新时,进行如下流程:
更新不会修改原来的 segment,更新和创建操作都会生成新的一个 segment。数据哪里来呢?先会存在内存的 bugger 中,然后持久化到 segment 。
数据持久化步骤如下:write -> refresh -> flush -> merge
3.3.1 write 过程
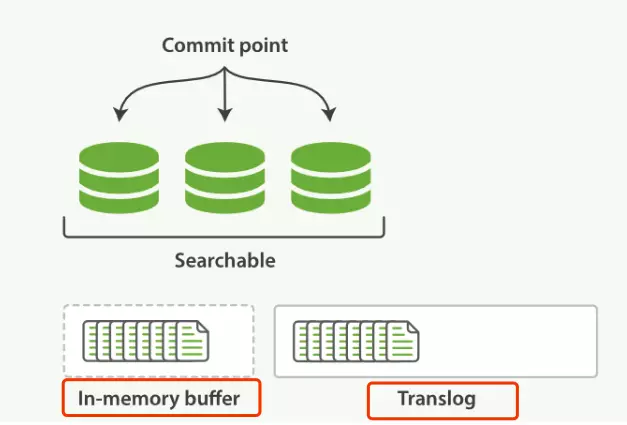
一个新文档过来,会存储在 in-memory buffer 内存缓存区中,顺便会记录 Translog。
这时候数据还没到 segment ,是搜不到这个新文档的。数据只有被 refresh 后,才可以被搜索到。那么 讲下 refresh 过程
3.3.2 refresh 过程

refresh 默认 1 秒钟,执行一次上图流程。ES 是支持修改这个值的,通过 index.refresh_interval 设置 refresh (冲刷)间隔时间。refresh 流程大致如下:
- in-memory buffer 中的文档写入到新的 segment 中,但 segment 是存储在文件系统的缓存中。此时文档可以被搜索到
- 最后清空 in-memory buffer。注意: Translog 没有被清空,为了将 segment 数据写到磁盘
文档经过 refresh 后, segment 暂时写到文件系统缓存,这样避免了性能 IO 操作,又可以使文档搜索到。refresh 默认 1 秒执行一次,性能损耗太大。一般建议稍微延长这个 refresh 时间间隔,比如 5 s。因此,ES 其实就是准实时,达不到真正的实时。
3.3.3 flush 过程
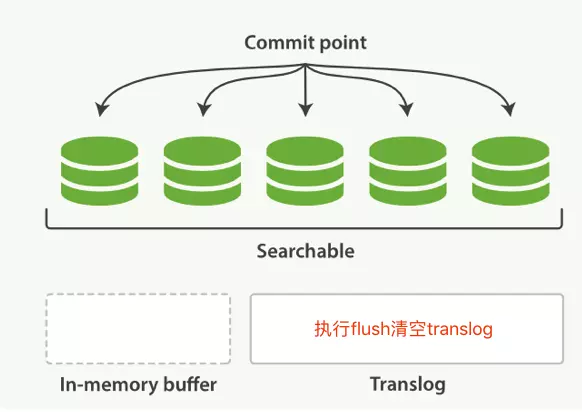
上个过程中 segment 在文件系统缓存中,会有意外故障文档丢失。那么,为了保证文档不会丢失,需要将文档写入磁盘。那么文档从文件缓存写入磁盘的过程就是 flush。写入次怕后,清空 translog。
translog 作用很大:
- 保证文件缓存中的文档不丢失
- 系统重启时,从 translog 中恢复
- 新的 segment 收录到 commit point 中
具体可以看官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/indices-flush.html
3.3.4 merge 过程

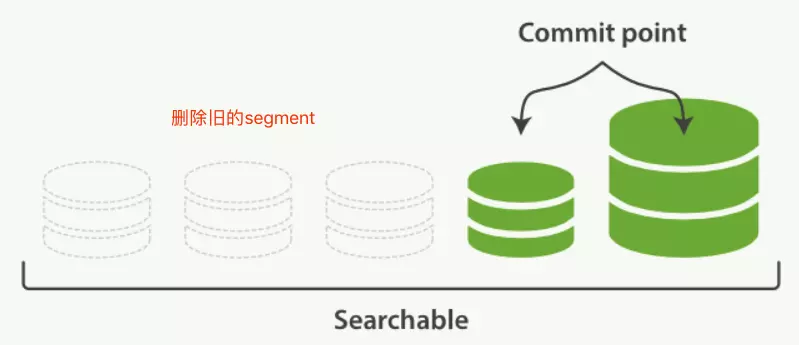
上面几个步骤,可见 segment 会越来越多,那么搜索会越来越慢?怎么处理呢?
通过 merge 过程解决:
- 就是各个小段文件,合并成一个大段文件。段合并过程
- 段合并结束,旧的小段文件会被删除
- .liv 文件维护的删除文档,会通过这个过程进行清除
四、小结
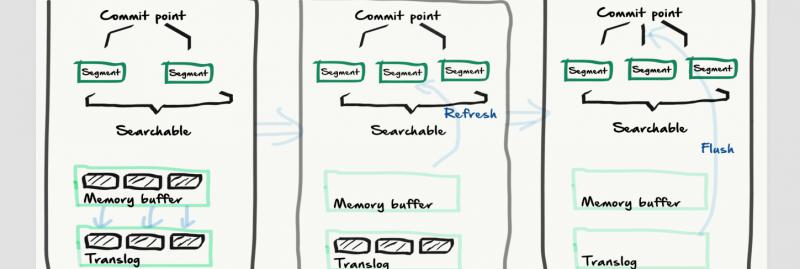
如这个图,ES 写入原理不难,记住关键点即可。
write -> refresh -> flush
- write:文档数据到内存缓存,并存到 translog
- refresh:内存缓存中的文档数据,到文件缓存中的 segment 。此时可以被搜到
- flush 是缓存中的 segment 文档数据写入到磁盘
写入的原理告诉我们,考虑的点很多:性能、数据不丢失等等
(完)
参考资料:
Java微服务资料,加我微w信x:bysocket01 (加的人,一般很帅)
- 《深入理解 Elasticsearch》
- https://lucene.apache.org/core/8_2_0/core/org/apache/lucene/codecs/lucene80/package-summary.html#package.description
- https://www.jianshu.com/p/e8226138485d
Elasticsearch Lucene 数据写入原理 | ES 核心篇的更多相关文章
- Elasticsearch准实时索引实现(数据写入到es分片并存储到文件中的过程)
溢写到文件系统缓存 当数据写入到ES分片时,会首先写入到内存中,然后通过内存的buffer生成一个segment,并刷到文件系统缓存中,数据可以被检索(注意不是直接刷到磁盘) ES中默认1秒,refr ...
- elasticsearch的数据写入流程及优化
Elasticsearch 写入流程及优化 一. 集群分片设置:ES一旦创建好索引后,就无法调整分片的设置,而在ES中,一个分片实际上对应一个lucene 索引,而lucene索引的读写会占用很多的系 ...
- Elasticsearch(GEO)数据写入和空间检索
Elasticsearch简介 什么是 Elasticsearch? Elasticsearch 是一个开源的分布式 RESTful搜索和分析引擎,能够解决越来越多不同的应用场景. 本文内容 本文主要 ...
- Flink 实践教程 - 入门(4):读取 MySQL 数据写入到 ES
作者:腾讯云流计算 Oceanus 团队 流计算 Oceanus 简介 流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发.无缝连接. ...
- 如何将爬取的数据写入ES中
前面章节一直在说ES相关知识点,现在是如何实现将爬取到的数据写入到ES中,首先的知道ES的python接口叫elasticsearch dsl 链接:https://github.com/elasti ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- elasticsearch备份与恢复4_使用ES-Hadoop将ES中的索引数据写入HDFS中
背景知识见链接:elasticsearch备份与恢复3_使用ES-Hadoop将HDFS数据写入Elasticsearch中 项目参考<Elasticsearch集成Hadoop最佳实践> ...
- Elasticsearch原理学习--为什么Elasticsearch/Lucene检索可以比MySQL快?
转载于:http://vlambda.com/wz_wvS2uI5VRn.html 同样都可以对数据构建索引并通过索引查询数据,为什么Lucene或基于Lucene的Elasticsearch会比关系 ...
- ES核心概念和原理
ES:1:倒排索引 基于Document 关键词索引实现 . 根据关键词做索引 相关度 a. 数据结构 i. 包含关键词的Document List ii. 关键词在每个doc中出现的次数 词频 TF ...
随机推荐
- Jenkins+SVN+Maven+shell 自动化部署实践
JAVA环境中利用Jenkins+svn+maven进行自动化部署实践 一. 前言2 1.介绍jenkins2 1.本地项目打包2 2.通过secureCRT工具,手动传输到服务器2 3.然后 ...
- servlet的几个函数
request.getContextPath 上下文,例如 /bignews1 (自带 “ / ”) request.getScheme() 协议,例如HTTP request.getServer ...
- 剑指offer第二版-7.重建二叉树
描述:输入某二叉树的前序遍历和中序遍历结果,重建该二叉树.假设前序遍历或中序遍历的结果中无重复的数字. 思路:前序遍历的第一个元素为根节点的值,据此将中序遍历数组拆分为左子树+root+右子树,前序遍 ...
- 小代学Spring Boot之集成MyBatis
想要获取更多文章可以访问我的博客 - 代码无止境. 上一篇小代同学在Spring Boot项目中配置了数据源,但是通常来讲我们访问数据库都会通过一个ORM框架,很少会直接使用JDBC来执行数据库操作的 ...
- Linux中的保护机制
Linux中的保护机制 在编写漏洞利用代码的时候,需要特别注意目标进程是否开启了NX.PIE等机制,例如存在NX的话就不能直接执行栈上的数据,存在PIE 的话各个系统调用的地址就是随机化的. 一:ca ...
- 个人永久性免费-Excel催化剂功能第37波-把Sqlserver的强大分析函数拿到Excel中用
本人一直钟情于使用Sqlserver数据库的一大原因是其提供了非常好用.高效的数据分析函数(窗口函数),可以在做数据清洗和数据分析场合等多个场景使用.只需简单的一个函数即可做出常规SQL语句很难以实现 ...
- ThreadLocal的使用场景:Web容器、Spring容器、日志打印
一.对于HTTP事务的理解 一次HTTP请求,就是一个事务.事务者,必须完整的执行其中的所有步骤,不能中断. 二.HTTP事务的隔离 每次HTTP请求对应一个HTTP事务,而每个请求都对应一个线程,线 ...
- VUE过滤器的使用 vue 时间格式化
过滤器介绍 官方教程地址:https://cn.vuejs.org/v2/guide/filters.html 过滤器常被用于一些文本格式化 我们可以自定义过滤器,可以实现各种各样的功能. vue时间 ...
- git,github,gitlab,码云的区别
git 是版本控制工具. github https://github.com/和gitlab https://about.gitlab.com/都是基于git仓库的web开发流程代码托管平台.两者的区 ...
- Python在office开发中的应用
Python with Excel 有几个很好的Python模块能够方便地操作Excel的数据,包括读与写,不要求本地安装Excel.例如pandas, openpyxl, xlrd, xlutils ...