《Kafka Stream》调研:一种轻量级流计算模式
原文链接:https://yq.aliyun.com/articles/58382
摘要: 流计算,已经有Storm、Spark,Samza,包括最近新起的Flink,Kafka为什么再自己做一套流计算呢?Kafka Stream 与这些框架比有什么优势?Samza、Consumer Group已经包装了Kafka轻量级的消费功能,难道不够吗?
Confluent Inc(原LinkedIn Kafka作者离职后创业公司)在6月份预告推出Kafka Stream,Kafka Stream会在Kafka 0.10版本中推出。
对于流计算,已经有Storm、Spark,Samza,包括最近新起的Flink,Kafka为什么再自己做一套流计算呢?Kafka Stream 与这些框架比有什么优势?Samza、Consumer Group已经包装了Kafka轻量级的消费功能,难道不够吗?
花了一些时间阅读docs 和一些PPT,写一份粗略的调研材料供大家参考。
什么是流计算?流是计算的一个连续计算类型
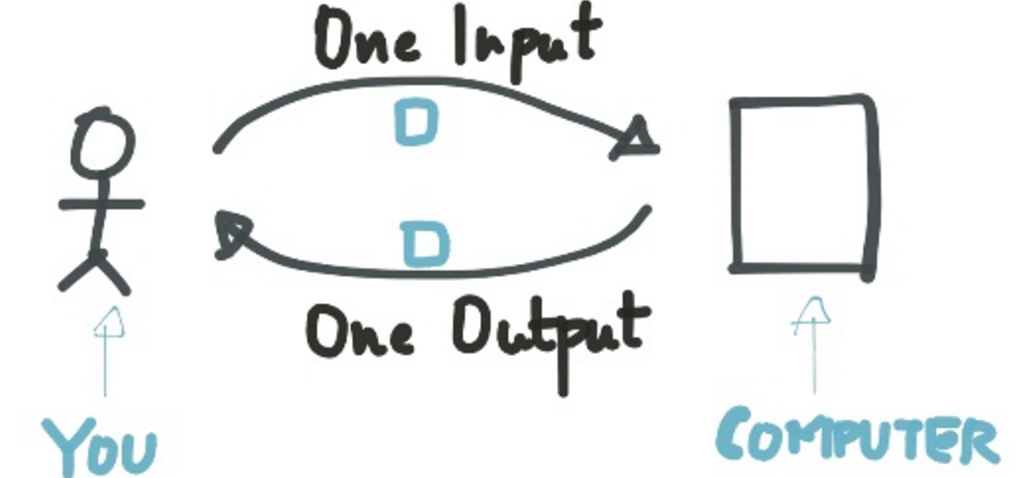
Single:例如HTTP,发送一个Request请求、返回一个Response
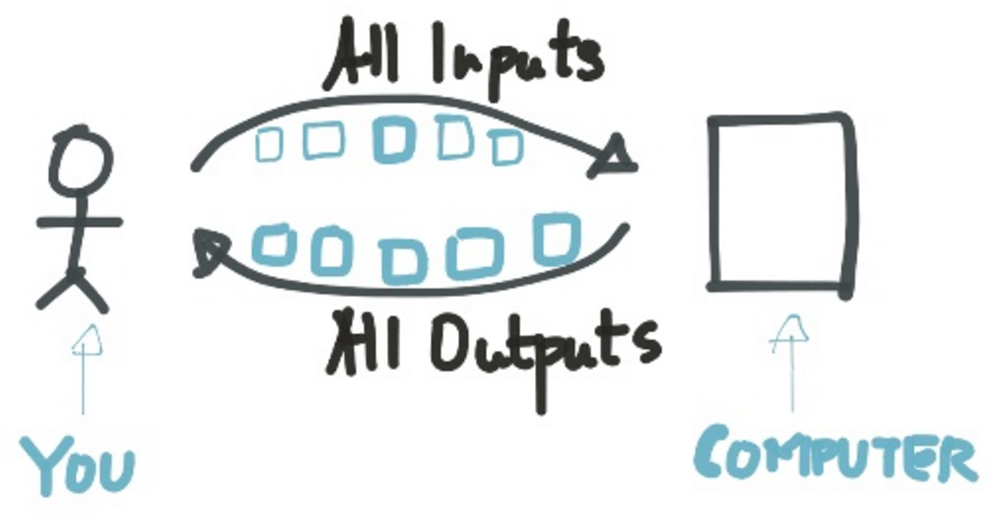
Batch:将一组作业提交给计算机,返回一组,优势是减少IO等待时间
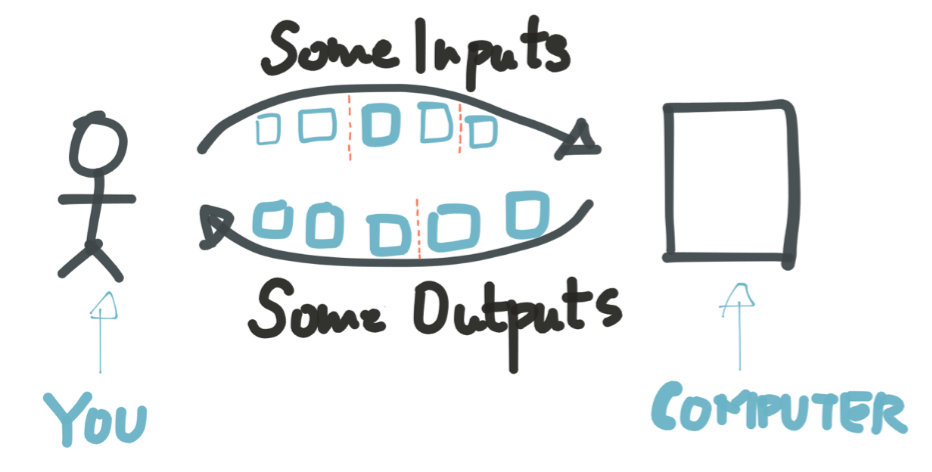
Stream:Batch异步过程,任务和任务之间没有明显的边界
流计算一般有哪些方式?
DIY 简单实现
以wordcount来作例子,我们可以启动一个server,内存中建立一个HashMap,把输入先分词,然后根据word视图更新HashMap。是不是很简单?但带来的问题是什么?
- 如果挂了,数据都被清空,数据重复怎么办?
- 如果数据量非常大,一块内存放不下怎么办?
- 如果在多台机器上部署,如何保证分配策略和先后顺序?
我们把这些问题做一个分类,主要有这样几个:
- 保序处理
- 规模和切片
- 异常恢复
- 状态类计算(例如TopK,UV等)
- 重新计算
- 时间、窗口等相关问题
利用现有框架
比较成熟度的框架有:Apache Spark, Storm(我们公司开源Jstorm), Flink, Samza 等。第三方有:Google’s DataFlow,AWS Lambda
现有框架的好处是什么?
强大计算能力,例如Spark Streaming上已经包含Graph Compute,MLLib等适合迭代计算库,在特定场景中非常好用。
问题是什么?
- 使用起来比较复杂,例如将业务逻辑迁移到完备的框架中,Spark RDD,Spout等。有一些工作试图提供SQL等更易使用模式降低了开发门槛,但对于个性化ETL工作(大部分ETL其实是不需要重量级的流计算框架的)需要在SQL中写UDF,流计算框架就退化为一个纯粹的容器或沙箱。
- 作者认为部署Storm,Spark等需要预留集群资源,对开发者也是一种负担。
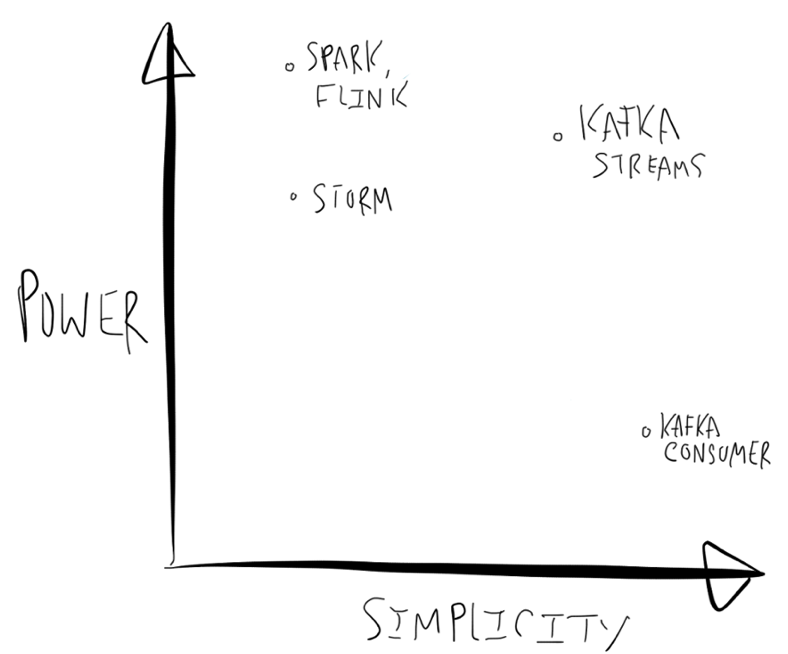
Kafka Stream定位是轻量级的流计算类库,简单体现在什么方面?
- 所有功能放在Lib中实现,实现的程序不依赖单独执行环境
- 可以用Mesos,K8S,Yarn和Ladmda等独立调度执行Binary,试想可以通过Lamdba+Kafka实现一个按需付费、并能弹性扩展的流计算系统,是不是很cool?
- 可以在单集成、单线程、多线程进行支持
- 在一个编程模型中支持Stateless,Stateful两种类型计算
- 编程模型比较简洁,基于Kafka Consumer Lib,及Key-Affinity特性开发,代码只要处理执行逻辑就可以,Failover和规模等问题由Kafka本身特性帮助解决
个人感觉Kafka Lib是Samza一个增强版(Samza也是Linkedin与Kafka深度集成的流计算框架),将来可以替换Samza,但无法撼动Spark、Flink等语义上比较高级的流计算系统地位,只能做一些轻量级流处理的场景(例如ETL,数据集成,清洗等)。
Kafka Stream 例子
先来看一个例子,通过Kafka Stream代码开发:

这里面做了这样几件事情:
- 构建了Kafka中数据序列化/反序列化方式
- 构建了2个计算节点
- 分词(flatMapValues),并将结果根据Key来Map
- Reduce(根据Key来计算结果)
- 将结果写到Kafka一个结果Topic中(增量方式)
在2个结算节点中,使用了一个Kafka Topic将计算结果序列化、并反序列化。相当于Map-Reduce中Streamline。
这段程序可以执行在一个Thread中,也可以执行在N台机器上,主要归结于Kafka Consumer Lib可以帮助对数据与计算解耦分离。
基本概念
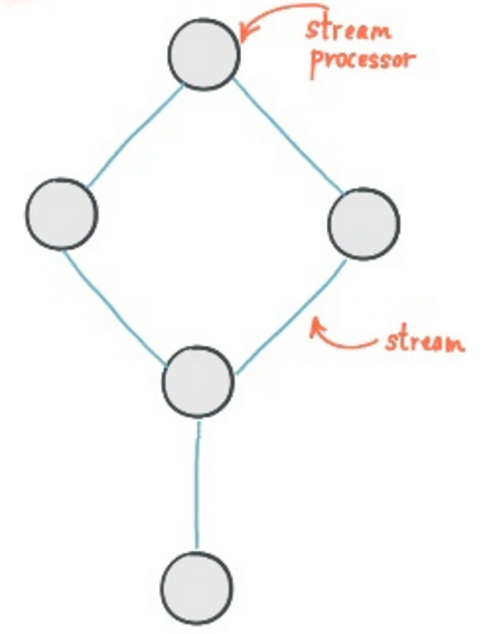
Processor:Processor是一个基本的计算节点
public interface Processor<K, V> {
void process (K key, V Value);
void punctuate(long time stampe);
}
Stream: Processor 处理后后结果输出
两者的关系如图:
Kafka Stream如何解决流计算中6个问题:
保序(Ordering)
对Kafka而言,在一个Partition(Shard)下,数据是先进先出严格有序的,因此不是问题。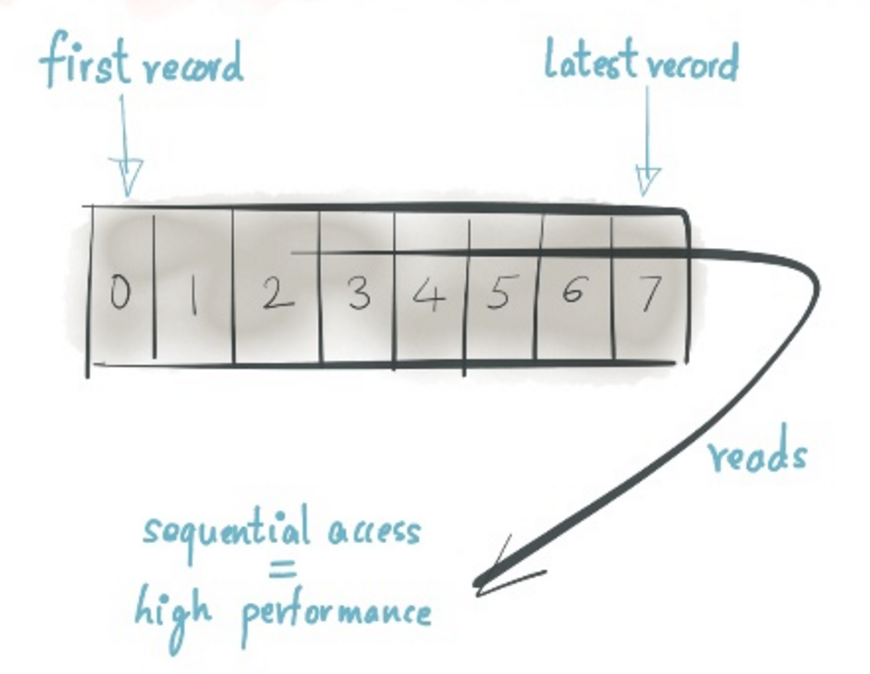
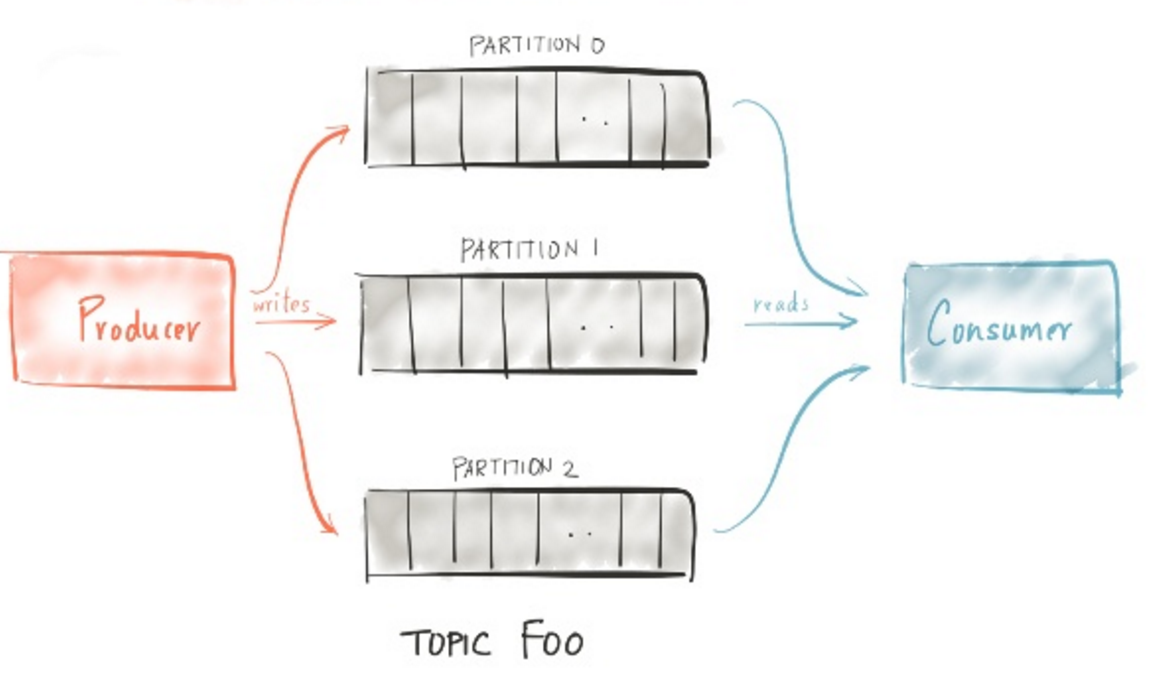
分区与规模(Partition & Scalability)
流计算规模取决于2个因素:数据是否能线性扩容、计算能否线性扩容。
数据
Kafka中的数据通过Partition方式划分,每个Partition严格有序,可以做到弹性伸缩(实际上目前版本中弹性伸缩是不完整的,Kafka在0.10版本中能提供完全弹性伸缩的能力)。
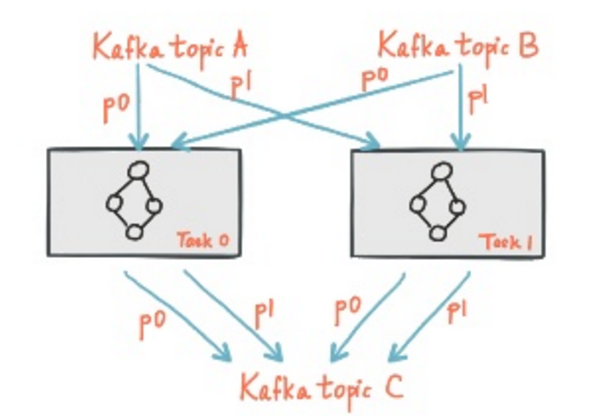
计算
Kafka对于消费端提供Consumer Group功能,可以扩展消费Instance达到与Partition同样的水平扩展能力,过程中保证一个消费Instance只能消费一个Partition。
故障恢复(Fault Tolerance)
Kafka Consumer Group已实现了负载均衡,因此当有消费实例crash时也能保证迅速未完成的任务,过程中数据不丢,可能会重复(取决于消费checkpoint配合)
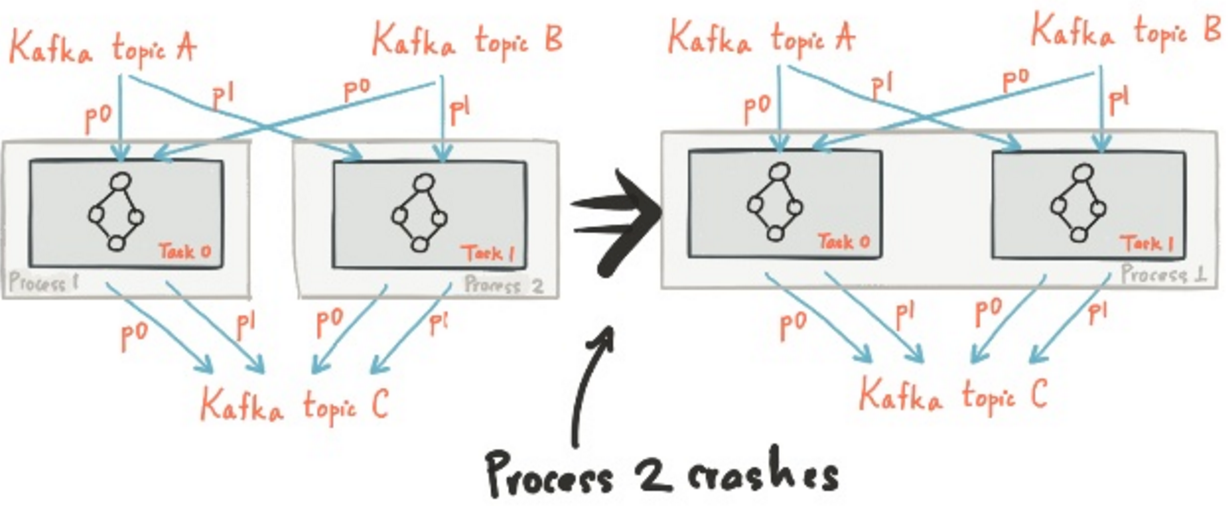
状态处理(State)
这个问题相对比较复杂,在流计算场景中,分为两类计算:
- Stateless(无状态):例如Filter,Map,Joins,这些只要数据流过一遍即可,不依赖于前后的状态
- Stateful(有状态):主要是基于时间Aggregation,例如某段时间的TopK,UV等,当数据达到计算节点时需要根据内存中状态计算出数值
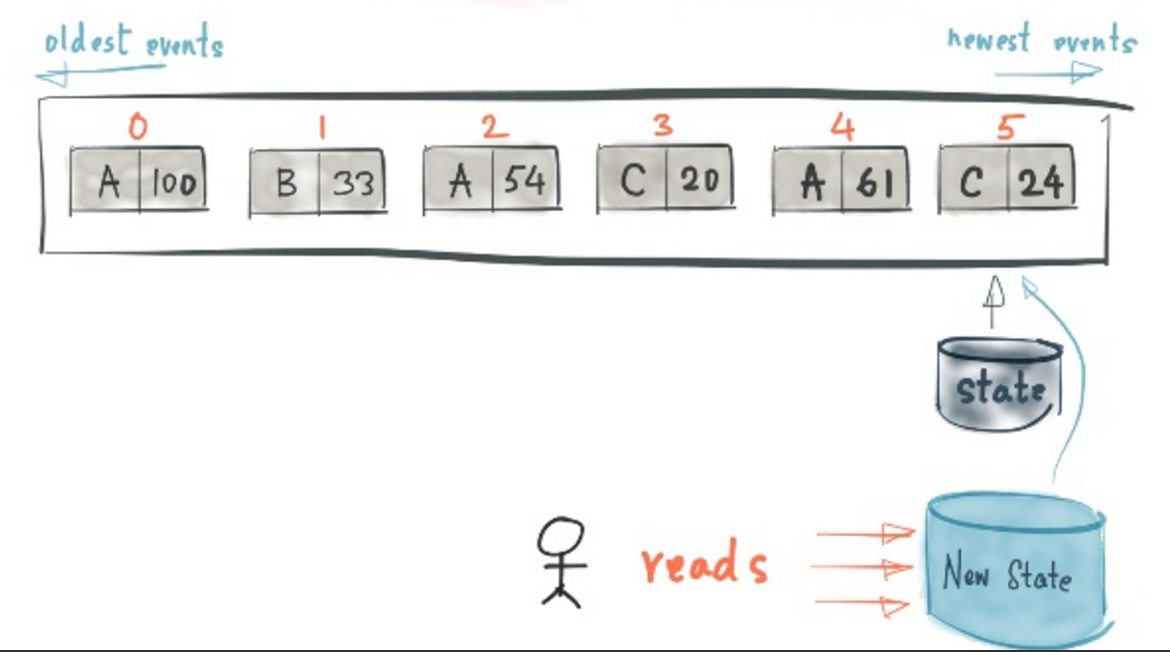
Kafka Stream 提供了一个抽象概念KTable,KStream来解决状态存储和数据变化的问题,见下面的章节解释。
重放(Reprocessing)
在了解了RedoLog和State后,重放这个概念并不难理解
基于时间窗口计算(Time, Windowsing)
时间是流计算的一个重要熟悉,因为在现实过程中数据采集往往并不是很完美的,历史数据的到来会打断我们对计算的假设。时间有两个概念:
- Event Time: 物理时间中的客观时间,代表事件发生时的一刻
- Processing Time: 实际处理的时间(到达服务器时间)
虽然Processing Time对处理比较容易,但因历史数据的影响,采用Event Time更为准确。一个零售业中比较典型的场景是:统计每10分钟内每个产品的销量(或网站每个时间点UV、PV的统计)。销售数据可能会从不同的渠道实时流入,因此我们必须依赖于销售数据产生的时间点来作为窗口,而不是数据达到计算的点。
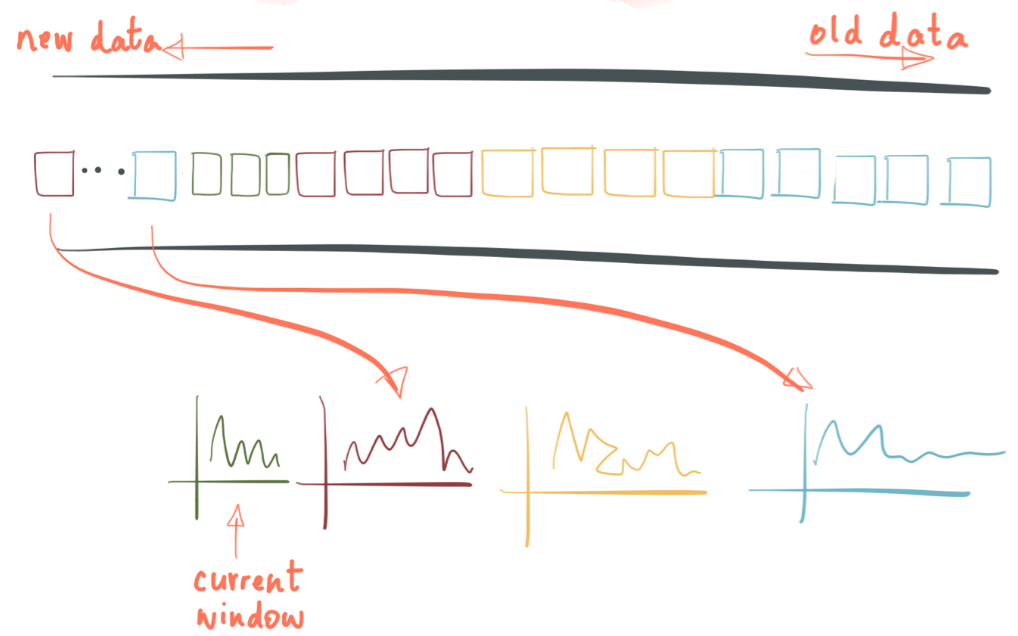
Kafka Stream用一种比较简单粗暴方式来解决这个问题,他会给每个windows一个状态,这个状态只是代表当前时刻的数值,当有新数据达到该窗口时,状态就被改变了。对于windows based aggregation,Kafka Stream做法是:
Table (状态数据) + Library = Stateful Service
Stream & Table
为了实现状态的概念,Kafka 抽象了两种实体Kstream, KTable
- Stream 等同于数据库中Change log
- Table 等同于数据库在一个时间点Snapshot,两个不同的Snapshot之间通过1个或多个changelog造成
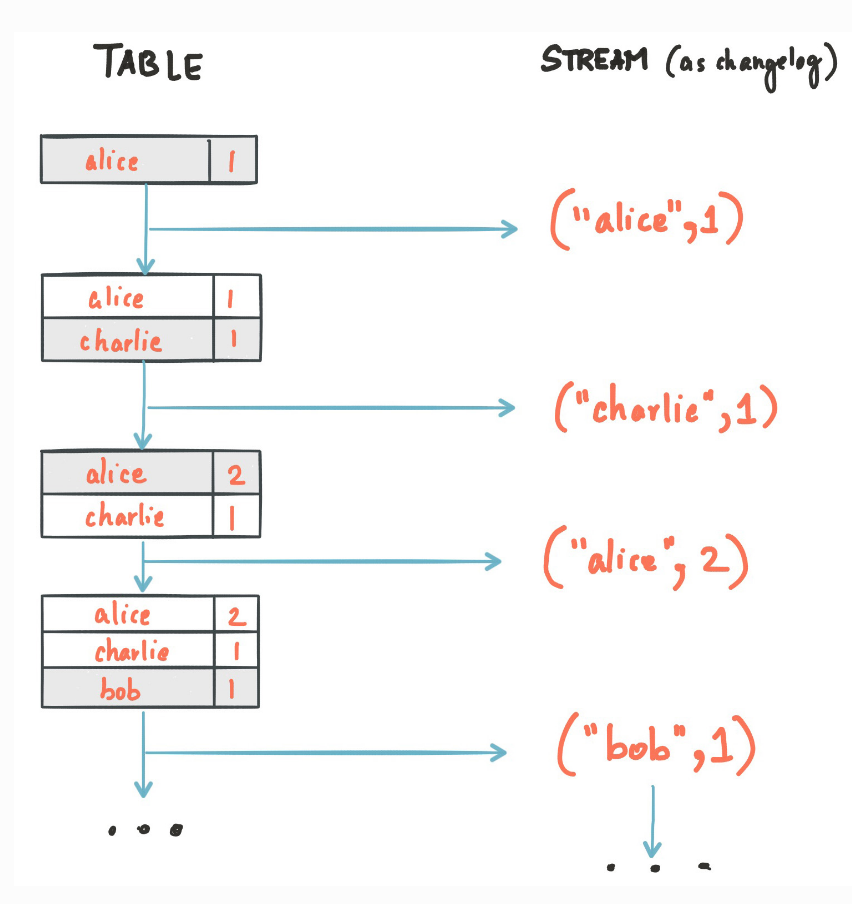
假设有2个流,一个流是送货,另外一个流是销售,我们对着两个流进行Join,获得当前的库存状态:
shipment stream:
item ID
store code
count
10
CA
200
23
NY
50
23
CA
101
54
WA
1000
sale stream:
item ID
store code
count
10
CA
20
23
NY
10
当这两个流中的记录先后达到情况下,会影响库存状态,整个库存的变化状态如下:
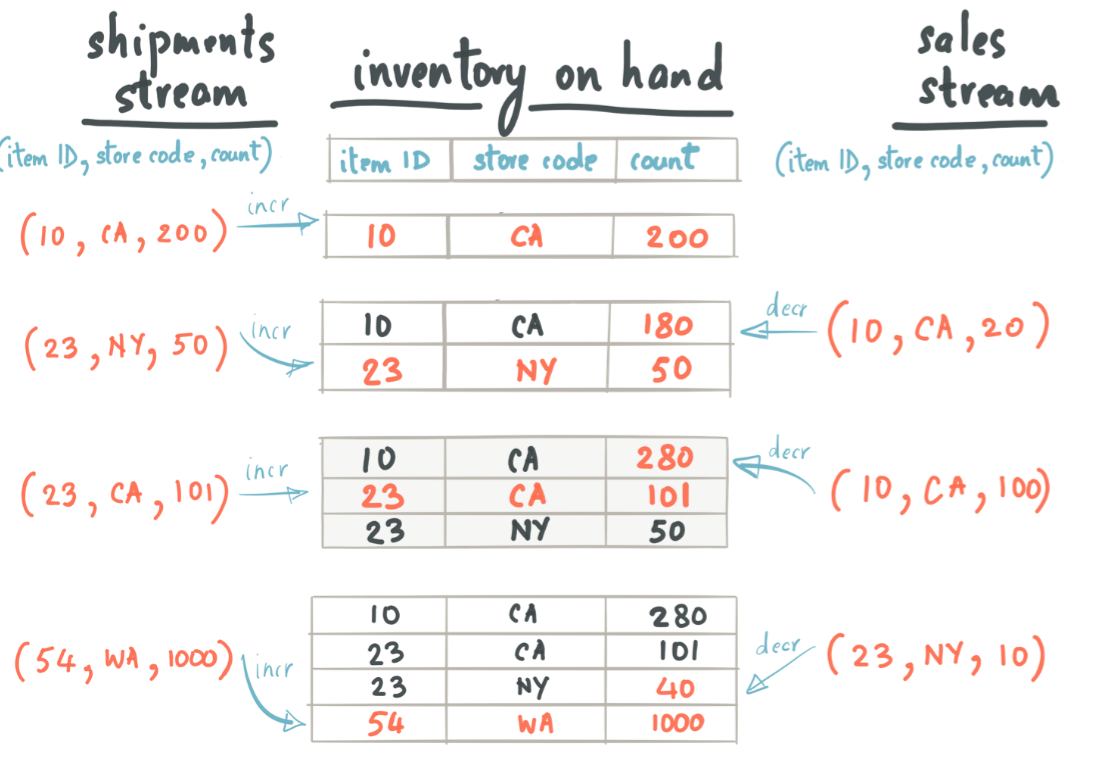
我们把这两个流放到Kafka Stream中,就会看到一个Processor节点中的状态变化如下:
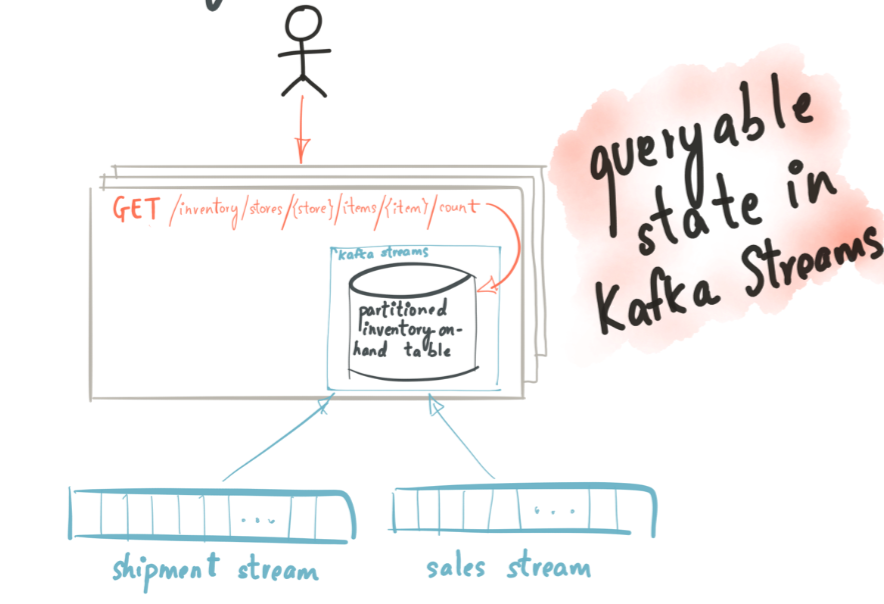
基于状态数据,我们可以在该节点定义处理的逻辑:
if (state.inventory[item].size < 10)
{
notify the manager;
}
else if (state.inventory[item] > 100)
{
on sale;
}
KTable,KStream可能比较抽象,KafkaStream包装了high-level DSL,直接提供了filter, map, join等算子,当然如果有个性化需求可以使用更低抽象程度API来完成。
粗浅的看法
流计算场景中,是否会有两个极端:复杂内存操作+迭代计算,轻量级数据加工与ETL。这两个比例分别占据多少?在我们常用的ETL场景里,大部分其实是轻量级Filter,LookUP,Write Storage等操作,有时候我们为了对数据做加工,不得不借助一个执行容器去选择流计算的框架。Docker,Lamdba可以解决这类问题,但需要有一定流计算的开发量。
我觉得对轻量级ETL场景,一个而理想的架构是Kafka Stream这样的轻量级计算库+Lamdba,这样就能做到安全按需使用的流计算模式。
Kafka Stream有一些关键东西没有解决,例如在join场景中,需要保证来源2个Topic数据Shard个数必须是一定的,因为本身做不到MapJoin等技术。在之前的版本中,也没有提供EventTime等Meta字段。
《Kafka Stream》调研:一种轻量级流计算模式的更多相关文章
- 使用Python的yield实现流计算模式
首先先提一下上一篇<如何猜出Y combinator>中用的方法太复杂了.其实在Lambda演算中实现递归的思想很简单,就是函数把自己作为第一个参数传入函数,然后后面就是简单的Lambda ...
- 流式计算新贵Kafka Stream设计详解--转
原文地址:https://mp.weixin.qq.com/s?__biz=MzA5NzkxMzg1Nw==&mid=2653162822&idx=1&sn=8c4611436 ...
- 流式处理的新贵 Kafka Stream - Kafka设计解析(七)
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/kafka/kafka_stream/ Kafka Stream背景 Ka ...
- Kafka设计解析(七)- Kafka Stream
本文介绍了Kafka Stream的背景,如Kafka Stream是什么,什么是流式计算,以及为什么要有Kafka Stream.接着介绍了Kafka Stream的整体架构,并行模型,状态存储,以 ...
- Kafka Stream
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature(当前:1.0.0-rc0,参见:https://github.com/apache/kafka/releas ...
- Kafka设计解析(七)Kafka Stream
转载自 技术世界,原文链接 Kafka设计解析(七)- Kafka Stream 本文介绍了Kafka Stream的背景,如Kafka Stream是什么,什么是流式计算,以及为什么要有Kafka ...
- FLINK流计算拓扑任务代码分析<一>
我打算以 flink 官方的 例子 <<Monitoring the Wikipedia Edit Stream>> 作为示例,进行 flink 流计算任务 的源码解析说明. ...
- 流式计算(二)-Kafka Stream
前面说了Java8的流,这里还说流处理,既然是流,比如水流车流,肯定得有流的源头,源可以有多种,可以自建,也可以从应用端获取,今天就拿非常经典的Kafka做源头来说事,比如要来一套应用日志实时分析框架 ...
- 告别Kafka Stream,让轻量级流处理更加简单
一说到数据孤岛,所有技术人都不陌生.在 IT 发展过程中,企业不可避免地搭建了各种业务系统,这些系统独立运行且所产生的数据彼此独立封闭,使得企业难以实现数据共享和融合,并形成了"数据孤岛&q ...
随机推荐
- 实现textarea高度自适应内容,无滚动条
最近接触到一个很好用的js插件,可以实现textarea高度随内容增多而改变,并且不显示滚动条,推荐给大家: http://www.jacklmoore.com/autosize/
- 倒计时的js实现 倒计时 js Jquery
by zhangxinxu from http://www.zhangxinxu.com本文地址:http://www.zhangxinxu.com/wordpress/?p=987 一.如火如荼的团 ...
- C语言中的插入排序(2016-12-30)
直接插入排序: 算法思想:假设待排序的记录存放在数组R[1--n]中,初始时,i=1,R[1]自成一个有序区,无序区为R[2--n].然后从i=2起直到i=n,依次将R[i]插入当前的有序区R[1.. ...
- 达梦7的试用 与SQLSERVER的简单技术对比
达梦7的试用 与SQLSERVER的简单技术对比 达梦数据库公司推出了他们的数据库服务管理平台,可以在该平台使用达梦数据库而无须安装达梦7数据库 地址:http://online.dameng.com ...
- Replication的犄角旮旯(三)--聊聊@bitmap
<Replication的犄角旮旯>系列导读 Replication的犄角旮旯(一)--变更订阅端表名的应用场景 Replication的犄角旮旯(二)--寻找订阅端丢失的记录 Repli ...
- 关于大型网站技术演进的思考(二十一)--网站静态化处理—web前端优化—下【终篇】(13)
本篇继续web前端优化的讨论,开始我先讲个我所知道的一个故事,有家大型的企业顺应时代发展的潮流开始投身于互联网行业了,它们为此专门设立了一个事业部,不过该企业把这个事业部里的人事成本,系统运维成本特别 ...
- C#开发EyeLink眼动仪的实验程序
[题外话] Eyelink眼动仪是SR Research推出的一款眼动仪,很多高校都在使用其做实验.其官方提供了COM的接口,所以支持COM接口的开发平台都可以开发使用.官方甚至提供了一个C#的样例供 ...
- python实现grep
import sys import os import re def usage(): print "[Usage]: python grep.py filename grepString. ...
- 开始用Word 2013来写博客
第一步:如果从未发布过博客文章的话,需要在菜单里面选这里添加博客账号 第二步:选择正确的设置 第三步:写完博客之后,按这里就可以发布了! 如果以后需要写新的博客的话,还可以直接点这里: ...
- 用FlexGrid做开发,轻松处理百万级表格数据
表格数据处理是我们项目开发中经常会遇到的设计需求之一,所需处理的数据量也较大,通常是万级.甚至百万级.此时,完全依赖平台自带的表格工具,往往无法加载如此大的数据量,或者加载得很慢影响程序执行. 那么, ...