c++11特性学习总结
ubuntu 16.04 自带gcc 5.4 支持c++11
ubuntu 18.04 自带gcc 7.3 支持c++14
查看编译器支持:
c++11 feature
- nullptr/constexpr
- enum class
- auto/decltype
- for iteration
- initialize_list
- lamda
- template
- rvalue/move
nullptr
以前的编译器实现,可能会把NULL定义为0.所以,当你有两个同名函数foo(int),foo(char*)时,foo(NULL)你的本意可能是调用后者,但实际调用的是前者.nullptr的引入就是为了解决这个问题.
void foo(char *ch){std::cout << "call foo(char*)" << std::endl;}void foo(int i){std::cout << "call foo(int)" << std::endl;}void test_nullptr(){if (NULL == (void *)0)std::cout << "NULL == 0" << std::endl;elsestd::cout << "NULL != 0" << std::endl;foo(0);//foo(NULL); // 编译无法通过foo(nullptr);}
constexpr
常量表达式的引入是为了提高性能,将运行期间的行为放到编译期间去完成.如下代码
constexpr long int fib(int n){return (n <= 1)? n : fib(n-1) + fib(n-2);}void test_constexpr(){auto start = std::chrono::system_clock::now();const long int res = fib(30);auto end = std::chrono::system_clock::now();std::chrono::duration<double> elapsed_seconds = end-start;cout << "elapsed_seconds:"<<elapsed_seconds.count()<<endl;start = std::chrono::system_clock::now();long int res2 = fib(30);end = std::chrono::system_clock::now();elapsed_seconds = end-start;cout << "elapsed_seconds:"<<elapsed_seconds.count()<<endl;
由于传给fib(int n)的参数是30,是个固定的值.所以可以在编译期间就求出来.当我们用const long和long声明返回值时,对前者会在编译期就做计算优化.如下图,可以看到二者运行时间有数量级上的差异.

enum class
c++11中把枚举认为是一个类,以前的标准中枚举值就是一个整数而已.看如下代码
void test_enum(){enum color {black,white};//auto white = true; //redeclaredenum class Color{r,g,b};auto r = 1;}
以前的标准中enum color {black,white};相当于定义了两个int变量black,white.所以//auto white = true;编译期会报错.引入了enum class则不再有这个问题.
auto/decltype
这个是c++11中非常重要的一点特性,极大地简化了编码的复杂.编译期自动去推导变量的类型.再也不需要我们操心了.
auto做变量类型推导,decltype做表达式类型推导.
void test_auto(){std::vector<int> v;v.push_back(1);v.push_back(2);for (std::vector<int>::iterator it = v.begin(); it != v.end(); it++){cout << *it << endl;}for (auto it = v.begin(); it != v.end(); it++){cout << *it << endl;}for (auto &i : v){cout << i << endl;i = 100; //修改掉v中的元素值}for (auto i : v){cout << i << endl; //输出100i = 200; //不会修改v中的元素值}for (auto i : v){cout << i << endl; //输出为100}}
用法如上述代码所示.比如遍历vector,写法由for (std::vector::iterator it = v.begin(); it != v.end(); it++)简化到for (auto it = v.begin(); it != v.end(); it++),如果配合上for迭代,则进一步简化到for (auto &i : v).
注意c++11中,auto变量自动推导有2个例外
- //int add(auto x,auto y); //c++14才支持函数参数为auto
- //auto arr[10] = {0}; //编译错误 auto不能用于数组类型的推导
decltype做表达式类型推导.假设我们要写一个加法的模板函数,比如
template<typename R, typename T, typename U>R add(T x, U y){return x+y;}
对于返回值类型R的话,我们必须在模板的参数列表中手动指明.调用的时候形式则为add<R,T,U>(x,y).而很可能我们并不知道返回类型是什么,比如我使用一个第三方库,我只是想对x,y做一个add操作,后续我可能会从x,y取一些数据做后续处理,此时我并不关心add操作返回值类型是什么.
c++11中用decltype自动推导表达式类型解决这个问题.
template<typename T, typename U>auto add_cxx11(T x, U y) -> decltype(x+y){return x+y;}
用decltype(x+y)声明返回值类型,让编译器自动推导就好了.
在c++14中,有了更好的支持,已经不再需要显示地声明返回值类型了.
//c++14支持/*template<typename T, typename U>auto add_cxx14(T x, U y){return x+y;}*/
for迭代
基于范围的for迭代,非常类似与python中的用法了.代码在前面auto/decltype一节已经展示.需要注意的是for (auto i : v)拿出的i是副本,不会修改v中的元素的值.for (auto &i : v)拿到的是引用,会修改掉v中的值.
初始化列表
c++11之前对象的初始化并不具有统一的表达形式,比如
int a[3] = {4,5,6}/*以前类的初始化只能通过拷贝构造函数或者()比如 */class A{A(int x,int y,int z)}A b;A a(b);A a2(1,2,3)
c++11提供了统一的语法来初始化任意对象.
比如
class XX{public:XX(std::initializer_list<int> v):v_int(v){}vector<int> v_int = {3,4,5};};XX xxxxxx = {6,7,8,9,10};
或者
struct A{int a_;int b_;};A a {1,2};
此外,初始化列表还可以作为函数的入参.
void f_take_initialize(initializer_list<int> list){int sum = 0;for (auto l : list){sum += l;}cout << sum << endl;}void test_initialize(){f_take_initialize({1, 2, 3});}
using关键字
using并不是c++11才有的,但是c++11中提升了这个关键字的功能,用于取代typedef,提供更加统一的表达形式.
template <typename T, typename U>class SuckType;typedef SuckType<std::vector<int>, std::string> NewType;using NewType = SuckType<std::vector<int>, std::string>;typedef int(*mycallback)(void*);using mycallback = int(*)(void*);
lamda表达式
即匿名函数,这也是c++11中一个相当重要的特性.有的时候,我们可能需要使用某个功能,但这个功能可能只在某一个函数内部有用,那么我们则没有必要去写一个全局函数或者类的成员函数去抽象这个功能.这时候就可以实现一个匿名函数.
[捕获列表](参数列表) -> 返回类型{// 函数体}
匿名函数的形式如上所示.参数列表,返回类型都很好理解.默认情况下,匿名函数是不可以使用匿名函数外部的变量的,捕获列表就起到一个传递外部参数的作用
捕获列表有下述几种情况
- 值捕获
- 引用捕获
- 隐式捕获
- 表达式捕获 //c++14支持
值得注意的是,值捕获的话,值是在匿名函数定义好的时候就做传递,而不是调用的时候做传递.
如下代码
void test_lamda(){auto add_func = [](int x,int y) -> int{return x+y;};auto sum = add_func(3,4);cout<<"sum="<<sum<<endl;int a = 1;auto copy_a = [a]{return a;};a = 100;auto a_i_get = copy_a();printf("a_i_get=%d,a=%d\n",a_i_get,a);auto copy_a_refrence = [&a]{a=50;return a;};auto a_refrence_i_get = copy_a_refrence();printf("a_i_get=%d,a=%d\n",a_refrence_i_get,a);int b = 1;auto f = [&](){return b;} ;}

注意,第一个输出的a_i_get=1而不是100.尽管a是100.这是因为在copy_a定义的时候,a的值是1. copy_a_refrence的捕获列表是引用,函数体内修改a=50,所以输出的是50
当要捕获的变量非常多的时候,一个个写是非常麻烦的,所以可以直接在捕获列表里用=和&表示传值和传引用
[](){} //传空[=](){} //传值[&](){} //传引用
变长模板
template<typename... Ts> class Magic;
c++11之前,模板的参数是固定个数的.c++11之后支持不定长参数的模板.用...表示不定长.
c++11标准库新引入的数据结构tuple就是用了这个特性实现的.
move语义和右值引用.
这也是c++11中引入的非常重要的一个特性.主要作用在于性能的提升.
通俗地讲,一个可以取地址的变量,即为左值,不可以取地址的即为右值.
以之前的vector.push_back()为例,插入的是数据的一份拷贝.当要插入的数据结构本身内存特别大的时候,这种拷贝带来的性能消耗是非常大的.
move的引入即用于解决此类问题,move()将一个值转换为右值. 标准库的数据结构里实现了void push_back( T&& value );的版本.
move()名字叫move,但他本身并不做任何move的操作,move更类似于浅拷贝,即拷贝待拷贝内容的地址过去.但是浅拷贝并不会使得之前的对象失去所有权,而move会,所以move所做的事情就是资源的所有权的转移

先看一下这段代码
void test_move(){std::string str = "Hello world.";std::vector<std::string> v;// 将使用 push_back(const T&), 即产生拷贝行为v.push_back(str);// 将输出 "str: Hello world."std::cout << "str: " << str << std::endl;// 将使用 push_back(const T&&), 不会出现拷贝行为// 而整个字符串会被移动到 vector 中,所以有时候 std::move 会用来减少拷贝出现的开销// 这步操作后, str 中的值会变为空v.push_back(std::move(str));// 将输出 "str: "std::cout << "str: " << str << std::endl;}
即我们前面提到的"hello world"这些内容的所有权的转移.move之后,原先的str已经失去了所有权,打印为空.
再来看一段代码.
void test_move_efficience(){vector<int> v_i;for(auto i = 0;i<10000000;i++){v_i.push_back(i);}auto f = [&](vector<int> v){return v;};auto g = [&](vector<int>& v){return v;};auto start = std::chrono::system_clock::now();f(v_i);auto end = std::chrono::system_clock::now();std::chrono::duration<double,std::milli> elapsed_seconds = end-start;cout << "f(v_i) elapsed_seconds:"<<elapsed_seconds.count()<<endl;start = std::chrono::system_clock::now();f(move(v_i));end = std::chrono::system_clock::now();elapsed_seconds = end-start;cout << "f(move(v_i)) elapsed_seconds:"<<elapsed_seconds.count()<<endl;start = std::chrono::system_clock::now();g(v_i);end = std::chrono::system_clock::now();elapsed_seconds = end-start;cout << "g(v_i) elapsed_seconds:"<<elapsed_seconds.count()<<endl;list<int> li;for(auto i = 0;i<10000000;i++){li.push_front(i);li.push_back(i+1);}vector<list<int>> vl;start = std::chrono::system_clock::now();vl.push_back(li);end = std::chrono::system_clock::now();elapsed_seconds = end-start;cout << "vl.push_back(li) elapsed_seconds:"<<elapsed_seconds.count()<<endl;start = std::chrono::system_clock::now();vl.push_back(move(li));end = std::chrono::system_clock::now();elapsed_seconds = end-start;cout << "vl.push_back(move(li)) elapsed_seconds:"<<elapsed_seconds.count()<<endl;}
先贴输出
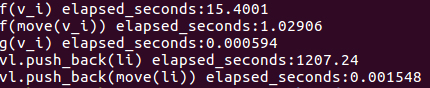
我们知道,函数传参的时候,值传递的话,实际上是做了一份参数的拷贝.所以f(v_i)的开销是最高的,达15ms,f(move(v_i))的话,没有了拷贝的操作,耗时1ms.对于g(v_i)的话,参数为引用,没有拷贝操作,耗时只有0.000594ms. 因为不管是f(),g(),函数内部都是非常简单的,没有任何操作,而move()本身会带来一定消耗,所以f(move(v_i))耗时比g(v_i)更高.
而move语义更常见的使用在于标准库里的封装.比如上述代码,vl.push_back(li)和vl.push_back(move(li))调用了不同的push_back(). 其性能是有着数量级的差异. 以我们的例子为例,其耗时分别为1207ms和0.001548ms.
所以如果我们自己的数据类型,内部含有大量的数据,我们应当自己去实现move构造函数.这样使用标准库时才可以更好的提高性能.
c++11特性学习总结的更多相关文章
- C++开发者都应该使用的10个C++11特性
转载自http://blog.jobbole.com/44015/ 在C++11新标准中,语言本身和标准库都增加了很多新内容,本文只涉及了一些皮毛.不过我相信这些新特性当中有一些,应该成为所有C++开 ...
- 转载:每个C++开发者都应该使用的十个C++11特性
这篇文章讨论了一系列所有开发者都应该学习和使用的C++11特性,在新的C++标准中,语言和标准库都加入了很多新属性,这篇文章只会介绍一些皮毛,然而,我相信有一些特征用法应该会成为C++开发者的日常用法 ...
- C++开发者都应该使用的10个C++11特性 转
http://blog.jobbole.com/44015/// | 分类: C/C++, 开发 | 条评论 | 标签: C++, C语言 分享到: 本文由 伯乐在线 - 治不好你我就不是兽医 翻译自 ...
- 开发者都应该使用的10个C++11特性
摘要: 在C++11新标准中,语言本身和标准库都增加了很多新内容,本文只涉及了一些皮毛.不过我相信这些新特性当中有一些,应该成为所有C++开发者的常规装备.你也许看到过许多类似介绍各种C++11特性的 ...
- C++11并发学习之三:线程同步(转载)
C++11并发学习之三:线程同步 1.<mutex> 头文件介绍 Mutex又称互斥量,C++ 11中与 Mutex 相关的类(包括锁类型)和函数都声明在 <mutex> 头文 ...
- java8 新特性学习笔记
Java8新特性 学习笔记 1主要内容 Lambda 表达式 函数式接口 方法引用与构造器引用 Stream API 接口中的默认方法与静态方法 新时间日期 API 其他新特性 2 简洁 速度更快 修 ...
- 201521123082 《Java程序设计》第11周学习总结
201521123082 <Java程序设计>第11周学习总结 标签(空格分隔):java 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. Answe ...
- 201521123067 《Java程序设计》第11周学习总结
201521123067 <Java程序设计>第11周学习总结 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多线 ...
- 201521123045 <java程序设计>第11周学习总结
201521123045 <java程序设计>第11周学习总结 1. 本周学习总结 2. 书面作业 2. 书面作业 Q1.1.互斥访问与同步访问完成题集4-4(互斥访问)与4-5(同步访问 ...
随机推荐
- drf之序列化
在django视图中使用serializer 只是使用serializer类编写API视图,没有用到REST框架 app01下的models.py from django.db import mode ...
- vue通信、传值的多种方式(详细)
转载自https://blog.csdn.net/qq_35430000/article/details/79291287
- centos7安装mongodb详解
记录一下linux下安装mongodb数据库过程. 安装mongodb #下载linux版本的tar文件# 例如笔者下载的是:mongodb-linux-x86_64-rhel70-3.4.4.tg ...
- linux环境下搭建自动化Jenkins管理工具
一.搭建一个jak--tomcat服务器到自己的linux服务器上 具体的服务器搭建这里可以参考华华大佬的博客:https://www.cnblogs.com/liulinghua90/p/46614 ...
- 利用DoHome APP和音箱控制小车的实验参考步骤
准备材料: Arduino Uno 一块 Arduino 扩展板 购买链接 DT-06模块一个 购买链接 安卓手机一个 小度音箱一个 小车一个 杜邦线若干 1.DT-06固件 ...
- Golang 解决 Iris 被墙的依赖包
使用 Golang 的 Iris web 框架时,用 go get github.com/kataras/iris 命令久久无法下载,最后还报一堆错误. 使用 GOPROXY 可解决问题,也可参考如 ...
- U盘制作启动盘后空间容量变小解决方法
WinAll的快速恢复方式: 0.windows键+R(调出运行窗口)输入:diskpart回车(调出磁盘管理器) 1.输入:list disk回车(从大小容量确定目标U盘的盘符X) 2.输入:sel ...
- 解决问题:安装Ubuntu时遇到nouveau sched_error问题
当我们在为有独立显卡gpu的电脑安装Ubuntu系统时,有可能会遇到nouveau sched_error问题. 方法一:安装系统时,开机出现dell图标时长按F12进入启动项选择界面, 然后选择UE ...
- 常用高效 Java 工具类总结
一.前言 在Java中,工具类定义了一组公共方法,这篇文章将介绍Java中使用最频繁及最通用的Java工具类.以下工具类.方法按使用流行度排名,参考数据来源于Github上随机选取的5万个开源项目源码 ...
- python学习笔记(6)--面向对象学习
本节内容: 面向对象编程介绍 为什么要用面向对象进行开发? 面向对象的特性:封装.继承.多态 类.方法. 引言 你现在是一家游戏公司的开发人员,现在需要你开发一款叫做(人狗大战)的游戏,你就思 ...