Hadoop入门学习笔记---part2
在《Hadoop入门学习笔记---part1》中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱。不够系统化,不够简洁。经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建hadoop环境时,需要在linux机器上做一些设置,在搭建Hadoop集群环境前,需要在本地机器上做以下设置:
- 修改ip地址;
- 关闭防火墙;
- Hostname的修改;
- Ssh自动登陆的设置(也即:免密码登录);
**关于以上操作的详细命令可以查看上一篇博客《Hadoop入门学习笔记---part1》 。 作者:itRed 邮箱:it_red@sina.com 博客:http://itred.cnblogs.com
然后是安装过程,分为两步:
- 安装jdk;
- 安装hadoop;
Part2的重点就是安装和配置hadoop:在myeclipse中查看Hadoop的源码。
在安装之前,说一说hadoop的版本:
- Apache :官方版;
- Cloudera: 使用下载最多的版本,稳定,有商业支持,在Apache基础上打上了patch。应该说是比较推荐的一种;
- Yahoo :内部使用的版本,发布过两次,已有的版本放到Apache上,后续的还在继续发布,并且是集中在Apache的版本上。
本人使用的Hadoop版本是1.1.2,使用的软件为Hadoop-1.1.2.tar.gz
在以上的设置工作完之后,正式进入安装和配置阶段:
- 将该软件放到linux系统中,解压,为了方便,修改一下文件名和权限;
- 设置环境变量;
#vi /etc/profile
加上一行:export HADOOP_HOME=/usr/local/Hadoop
在PATH后添加:$HADOOP_HOME/bin:
然后执行这个命令让其立即生效:
#source /etc/profile
3. 修改hadoop的配置文件,用以实现伪分布,这里主要修改4个配置文件:
(1) Hadoop-env.sh
主要是修改jdk的路径:
在该文件的第9行,修改JAVA_HOME的路径,根据自己的实际情况就行。
(2) Core-site.xml
在configuration里面加入一下配置代码,需要注意自己的主机名,即最开始修改的hostname:
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>Hadoop.tmp.dir</name>
<value>/usr/local/Hadoop/tmp</value>
</property>
(3) Hdfs-site.xml:
<property>
<name>dfs.replication</name>
<value>1</value>
<property>
<property>
<name>dfs.permission</name>
<value>true</value>
<property>
(4) Mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>Hadoop:9001</value>
</property>
4. 待配置完成后,需要对hadoop进行格式化,很多哦人开始不理解。这样想就行了,因为HDFS是一个文件系统,专门用来存储的。想想U盘什么的都需要格式化。
格式化的命令为:#hadoop namenode –format
(总结:如果启动后发现有进程没有启动,需要重新格式化,那么首先得把已经启动了的进程停止掉,才能进行操作。#stop-all.sh)
5. 启动Hadoop:
命令:#start-all.sh (注意:中间没有空格)
很自然能想到关闭停止的命令:#stop-all.sh
可以进行单个启动和关闭。
启动完成后,需要验证是否正确,用命令jps来验证,注意不是jsp:
#jps
这时会出现5个java进程(一共6个,其中包含一个jps),分别为:
SecondaryNameNode DataNode TaskTracker NameNode JobTracker Jps
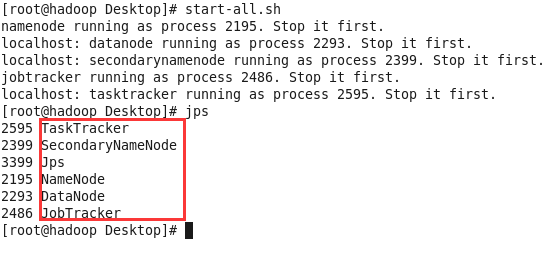
这样就算安装成功了!如果还不甘心,希望在浏览器中查看,不慌。这就说来。
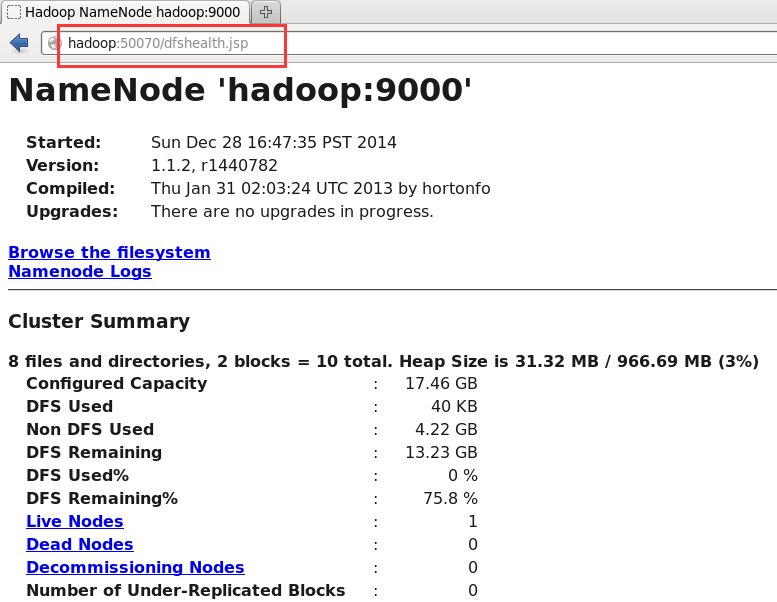
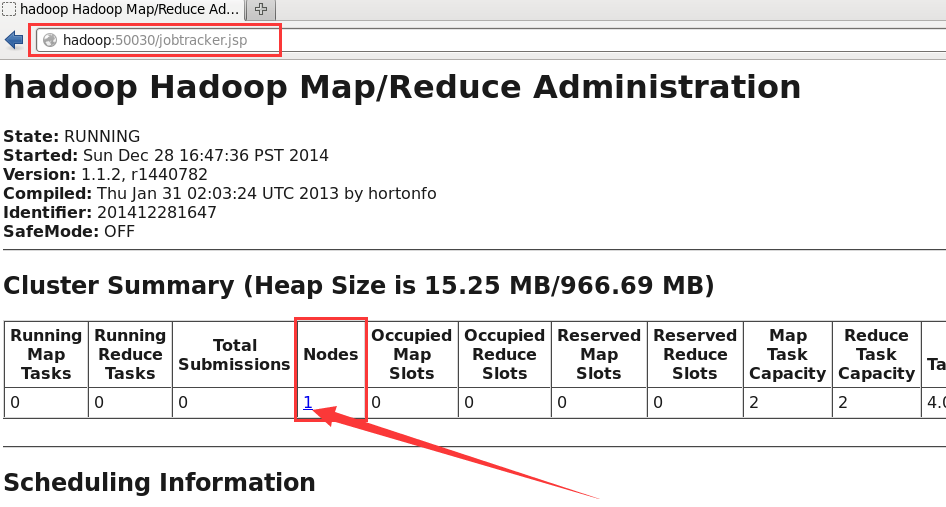
如果你的操作界面时命令行模式,首先#startx 进入操作系统的界面模式,然后打开浏览器,在浏览器中输入hadoop:50070或输入 Hadoop:50030就可以看到如下界面:
hadoop:50070页面:
hadoop:50030页面:
关于某进程没有启动的常见解决办法:
HDFS在安装后没有格式化;
4个配置文件修改可能存在问题;
Hostname与ip没有绑定;
Ssh的免密码登录没有配置成功。
如果确保没有任何操作失误,或者在多次格式化后,还是不能启动某个进程,那么去删除/usr/local/Hadoop/目录下的tmp文件夹,然后再重新格式化。应该就没有什么问题了。
那么如何在myeclipse中查看Hadoop的源码呢?
首先解压hadoop软件。我使用的版本是:hadoop-1.1.2.tar.gz
解压后的文件目录结构如下:
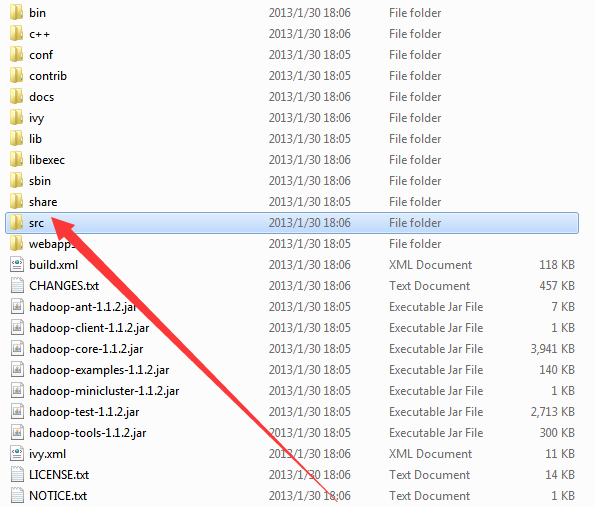
然后打开myeclipse,新建一个java工程,把src目录下的core文件夹,hdfs文件夹,mapred文件夹拷贝到src目录下。然后选择你的jdk,然后把那个src包调一下,就可以打开看到Hadoop的源码了。
作者:itRed
邮箱:it_red@sina.com
博客:http://www.cnblogs.com/itred
***版权声明:本文版权归作者和博客园共有,欢迎转载,但请在文章显眼位置标明文章出处。未经本人书面同意,将其作为他用,本人保留追究责任的所有权利。
Hadoop入门学习笔记---part2的更多相关文章
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记(一)
Week2 学习笔记 Hadoop核心组件 Hadoop HDFS(分布式文件存储系统):解决海量数据存储 Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度 Hadoop Map ...
- Hadoop入门学习笔记总结系列文章导航
一.为何要学习Hadoop? 这是一个信息爆炸的时代.经过数十年的积累,很多企业都聚集了大量的数据.这些数据也是企业的核心财富之一,怎样从累积的数据里寻找价值,变废为宝炼数成金成为当务之急.但数据增长 ...
- Hadoop入门学习笔记之一
http://hadoop.apache.org/docs/r1.2.1/api/index.html 适当的利用 null 在map中可以实现对文件的简单处理,如排序,和分集合输出等. 需要关心的内 ...
- Hadoop入门学习笔记(二)
Yarn学习 YARN简介 YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 YARN功能说明 资源管理系统:集群的硬件资源,和程序运行相关,比如内存.CPU等. 调度平 ...
- Hadoop入门学习笔记-第一天 (HDFS:分布式存储系统简单集群)
准备工作: 1.安装VMware Workstation Pro 2.新建三个虚拟机,安装centOS7.0 版本不限 配置工作: 1.准备三台服务器(nameNode10.dataNode20.da ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
随机推荐
- C\C++ 生成各位数不相等的随机数
最近想写一个1A2B的小游戏来练习一下,结果在第一步生成随机数的时候就遇到了一点点问题. 游戏初始化时需要先生成一个四位随机数,且各位各不相等.于是最开始的思路是生成一个整数数组,只需要判断生成的随机 ...
- 解决WARN: Timeout/setRollbackOnly of ACTIVE coordinator !的问题
该问题是CoordinatorImp上面的一个定时器造成的,一个活动的session如果在一定的时间内没有执行完毕就会rollback,就算没有sql执行也会不断的进行. 可以参考该链接:https: ...
- 嵌入式linux下如何尽快播放开机音乐
今天在考虑如何尽快启动一个应用程序,播个开机音乐什么的. 最开始的启动流程是这样的,bootloader 启动kernel,kernel跑完挂载文件系统, 然后会执行/init,而这个init 是指向 ...
- ScrollView嵌套RecyclerView时滑动出现的卡顿
原文连接:http://zhanglu0574.blog.163.com/blog/static/113651073201641853532259/ 现象: 一个界面有多个RecyclerView ...
- RunLoop
一.什么是RunLoop 从字面意思理解:运行循环.跑圈. 基本作用: 保持程序(应用)的持续运行. 处理程序(APP)中的各种事件(比如:触摸事件.定时事件.Selector事件等) 节省CPU资源 ...
- C#线程入门---转载
C#中的线程(一)入门 文章系参考转载,英文原文网址请参考:http://www.albahari.com/threading/ 作者 Joseph Albahari, 翻译 Swanky Wu 中 ...
- iOS开发系列--Objective-C之KVC、KVO
概述 由于ObjC主要基于Smalltalk进行设计,因此它有很多类似于Ruby.Python的动态特性,例如动态类型.动态加载.动态绑定等.今天我们着重介绍ObjC中的键值编码(KVC).键值监听( ...
- 实战JS正则表达式
-正则表达式是一种文本模式的匹配工具. -文章导读: --1.正则对象的属性和方法 --2.字符串对象的方法 --3.使用正则表达式: ---3.1 给字符串加上千分符 ---3.2 字符串中出现次数 ...
- MySQL 基础及性能优化工具
数据库,用户及权限 常用用户管理操作 # 创建本地用户 abc create user abc@localhost # 创建内网能够访问的用户 abc create user abc@'192.168 ...
- 京东招聘Java开发人员
软件开发工程师(JAVA) 岗位职责: 1. 负责京东核心业务系统的需求分析.设计.开发工作 2. 负责相关技术文档编写工作 3. 解决系统中的关键问题和技术难题 任职要求: 1. 踏实诚恳.责任心强 ...