MongoDB 数据库的学习与使用
MongoDB 数据库
一、MongoDB 简介(了解)
MongoDB 数据库是一种 NOSQL 数据库,NOSQL 数据库不是这几年才有的,从数据库的初期发展就以及存在了 NOSQL 数据库。数据库之中支持的 SQL 语句是由 IBM 开发出来的,并且最早就应用在了 Oracle 数据库,但是 SQL 语句的使用并不麻烦,就是几个简单的单词:SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY,但是在这个时候有人开始反感于编写 SQL 操作。于是有一些人就开始提出一个理论 —— 不要去使用 SQL ,于是最早的 NOSQL 概念产生了。可是后来的发展产生了一点变化,在 90 年代到 2010 年之间,世界上最流行的数据库依然是关系型数据库,并且围绕着关系型数据库开发出了大量的程序应用。后来又随着移动技术(云计算、大数据)的发展,很多公司并不愿意去使用大型的厂商数据库 —— Oracle 、DB2,因为这些人已经习惯于使用 MYSQL 数据库了,这些人发现在大数据以及云计算的环境下,数据存储受到了很大的挑战,那么后来就开始重新进行了 NOSQL 数据库的开发,但是经过长期的开发,发现 NOSQL 数据库依然不可能离开传统的关系型数据库 (NOSQL = Not Only SQL)。
实际上在现实的开发之中一直存在一种神奇的问题:
数据表 → JDBC 读取 → POJO(VO、PO) → 控制层转化为 JSON 数据 → 客户端
可是这样的转换实在是太麻烦了,那么最好的做法是,直接有一个数据库就存放有要显示的 JSON 数据该有多好,那么就省略所有需要进行转换的过程。所以在实际的开发之中,往往除了关系型数据库之外还要提供有一个 NOSQL 数据库,其中 NOSQL 数据库负责数据的读取,因为直接保存的就是 JSON (前提:MongoDB 中的数据是排列好的组合数据)。
例如:现在要求显示出每个雇员的编号、姓名、职位、部门名称、部门位置、工资等级。传统的关系型数据库之中一定要存放大量的冗余数据,不合理。而有了 NOSQL 数据库之后,可以直接在业务层里面将数据交给 NOSQL 数据库保存,按照指定的结构进行存储。
在 MongoDB 数据库之中与 Oracle 数据库有如下的概念对应:
| NO. | 关系型数据库 | NOSQL 数据库 |
|---|---|---|
| 1 | 数据库 | 数据库 (类似于 MySQL) |
| 2 | 表 | 集合 |
| 3 | 行 | 文档 |
| 4 | 列 | 成员 |
| 5 | 主键 | Object ID (自动维护的) |
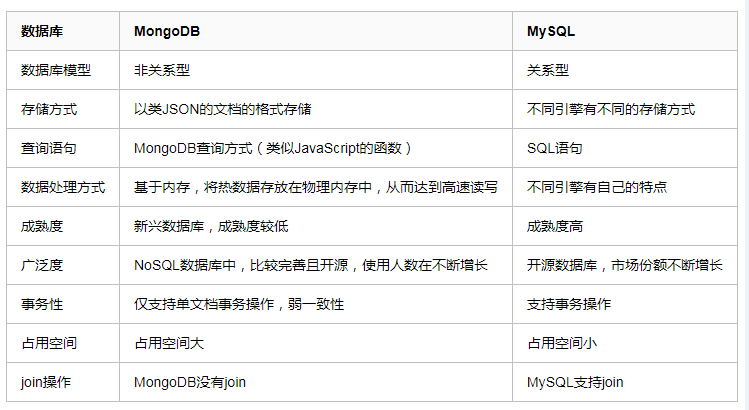
MongoDB 和 MySQL 的对比:
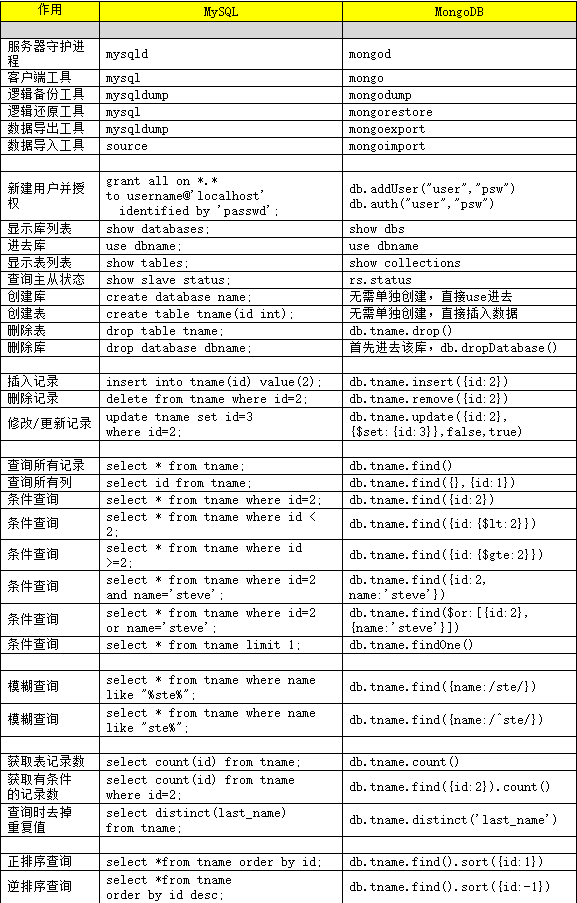
MongoDB 和 MySQL 的操作命令对比:
在整个行业之中,MongoDB 数据库是发展最好的一个 NOSQL 数据库,因为它与 Node.JS 捆绑在一起了,也就是说如果你要从事 Node.JS 的开发,那么一定要使用 MongoDB,而 Node.JS (基于 JavaScript )在国内最成功的应用 —— taobao 。
MongoDB 之所以能够更好的发展也取决于:面向集合的存储过程、模式自由(无模式)、方便的进行数据存储扩充、支持索引、支持短暂数据保留、具备完整的数据库状态监控、基于 BSON (MongoDB 自己的JSON )应用。
MongoDB 支持现在各种主流的编程语言,如:Python、.NET、PHP 等。
二、MongoDB 的安装
如果想要得到 MongoDB 数据库只需要登录 (www.mongodb.org) 上就可以直接下载可用版本,最新的版本是 3.0.x ,但是这个版本变为了 Windows 安装版(只是把原来的解压缩版变为了安装拷贝)。
msi 格式文件是点击安装文件, zip 格式是压缩包文件,一般下载 msi 文件。
将下载下来的 MongoDB 数据库直接进行安装。安装的时候需要选择好对应的操作系统,本次使用的是64位的安装系统。
第一步:打开安装文件
第二步:接受协议
第三步:选择自定义安装
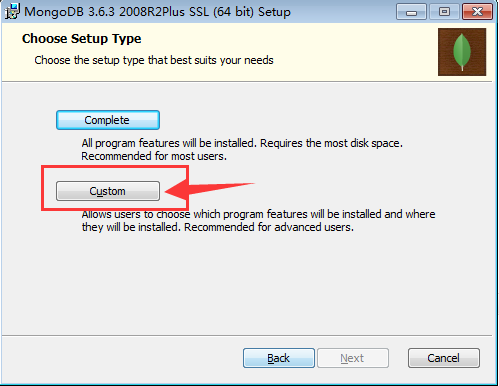
第四步:点击浏览
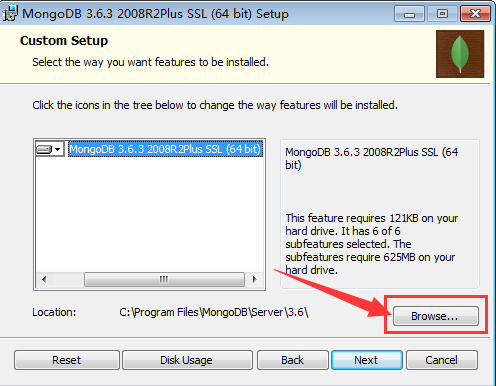
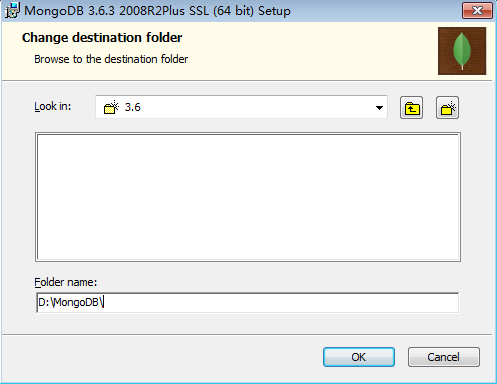
第五步:更改目录
安装路径一般放在一个盘的根目录下 D:\MongoDB 。
第六步:点击安装

MongoDB 安装完成之后,严格来讲并不能够在 Windows 下使用,需要为它配置 path 环境属性,配置目录:“E:\MongoDB\bin” 。
计算机 - 属性 - 高级系统设置 - 环境变量 - 系统变量,在最前面加上:" E:\MongoDB\bin; "
如果要想正常启动 MongoDB 数据库,那么必须建立一个文件夹,这个文件夹将保存所有的数据库的信息,现在将在 MongoDB 文件夹之中建立一个 db 的目录(E:\MongoDB\db),并且在此目录下保存所有的数据文件。
MongoDB 数据库的启动需要使用 mongod.exe 命令完成,启动的时候可以设置端口号,也可以不设置端口号。
- 不设置端口号启动 MongoDB 服务(命令行中编写:cmd )
mongod --dbpath D:\MongoDB\db
- 设置端口号启动
mongod --dbpath D:\MongoDB\db --port=27001
如果日后需要通过程序访问数据库的话,那么一定要设置端口号。
当 MongoDB 服务启动之后,可以使用 mongo 命令连接数据库。
MongoDB shell version v3.6.3
connecting to: mongodb://127.0.0.1:27017
MongoDB server version: 3.6.3
Server has startup warnings:
2019-07-01T15:40:20.741+0800 I CONTROL [initandlisten]
2019-07-01T15:40:20.741+0800 I CONTROL [initandlisten] ** WARNING: Access control is not enabled for the database.
2019-07-01T15:40:20.741+0800 I CONTROL [initandlisten] ** Read and write access to data and configuration is unrestricted.
2019-07-01T15:40:20.742+0800 I CONTROL [initandlisten]
2019-07-01T15:40:20.742+0800 I CONTROL [initandlisten] ** WARNING: This server is bound to localhost.
2019-07-01T15:40:20.743+0800 I CONTROL [initandlisten] ** Remote systems will be unable to connect to this server.
2019-07-01T15:40:20.743+0800 I CONTROL [initandlisten] ** Start the server with --bind_ip <address> to specify which IP
2019-07-01T15:40:20.744+0800 I CONTROL [initandlisten] ** addresses it should serve responses from, or with --bind_ip_all to
2019-07-01T15:40:20.744+0800 I CONTROL [initandlisten] ** bind to all interfaces. If this behavior is desired, start the
2019-07-01T15:40:20.744+0800 I CONTROL [initandlisten] ** server with --bind_ip 127.0.0.1 to disable this warning.
2019-07-01T15:40:20.745+0800 I CONTROL [initandlisten]
2019-07-01T15:40:20.745+0800 I CONTROL [initandlisten] Hotfix KB2731284 or later update is not installed, will zero-out data files.
2019-07-01T15:40:20.745+0800 I CONTROL [initandlisten]
2019-07-01T15:40:20.745+0800 I CONTROL [initandlisten] ** WARNING: The file system cache of this machine is configured to be greater than 40% of the total memory. This can lead to increased memory pressure and poor performance.
2019-07-01T15:40:20.746+0800 I CONTROL [initandlisten] See http://dochub.mongodb.org/core/wt-windows-system-file-cache
2019-07-01T15:40:20.746+0800 I CONTROL [initandlisten]
>
范例:查询所有的数据库
show databases;
此时只存在有一个 local 的本地数据库,不过这个数据库不使用。
虽然以上的代码实现了数据库的启动与连接操作,但是从严格意义上来讲,以上的代码没有任何的用处,因为从实际的开发来讲,在 MongoDB 启动的时候需要设置一些相应参数:端口号、是否启用用户验证、数据文件的位置等等。
范例:在 E:\MongoDB 目录下建立一个文件 "mongodb.conf"
# 设置数据目录的路径
dbpath = D:\MongoDB\db
# 设置日志信息的文件路径
logpath = D:\MongoDB\log\mongodb.log
# 打开日志输出操作
logappend = true
# 在以后进行用户管理的时候使用它
noauth = true
port = 27001
- 随后重新启动 MongoDB 数据库服务
// 切换到 admin 数据库
use admin
// 关闭数据库服务
db.shutdownServer()
// 重新启动服务
mongod -f d:\MongoDB\mongodb.conf
范例:连接数据库
此时服务器已经存在有指定的端口号了。
mongo --port=27001
使用端口号启动在日后的程序开发部分是非常有用处的。
三、MongoDB 的基础操作
在 MongoDB 数据库里面是存在有数据库的概念,但是没有模式(所有的信息都是按照文档保存的),保存数据的结构就是 JSON 结构,只不过在进行一些数据处理的时候才会使用到 MongoDB 自己的一些操作符。
3.1、使用 mldn 数据库:
use mldn
实际上这个时候并不会创建数据库,只有在数据库里面保存集合数据之后才能够真正创建数据库。
查看数据库信息
show databases
或者:
show dbs
结果显示如下:
admin 0.000GB
local 0.000GB
3.2、创建一个集合 —— 创建一个 emp 集合
db.createCollection("emp")
这个时候 mldn 数据库才会真正的存在。
show dbs
结果显示如下:
admin 0.000GB
local 0.000GB
mldn 0.000GB
3.3、创建一个集合 —— 创建一个 dept 集合
但是很多的时候如果按照以上的代码形式进行会觉得你不正常,因为正常人使用 MongoDB 数据库集合操作的时候都是直接向里面保存一个数据。
db.emp.find();
相当于Oracle的 select * from emp;
结果显示是没有数据的
db.dept.insert({"deptno":10,"dname":"财务部","loc":"北京"});
回车后显示如下,代表写入一条数据
WriteResult({ "nInserted" : 1 })
3.4、查看所有集合
show collections;
结果显示如下:
dept
emp
发现 dept 集合自动创建了。
3.5、查看 dept 表的数据
- 语法:db.集合名称.find({若干条件})
db.dept.find();
{ "_id" : ObjectId("5d048f4ddb2a129b32288893"), "deptno" : 10, "dname" : "财务部", "loc" : "北京" }
从传统的数据表来看(集合就相当于表的结构),表的结构一旦定义就必须按照其定义的要求进行内容的编写,但是 MongoDB 不一样,它可以自己随意扩充数据。
3.6、增加不规则数据
var deptData = {
"deptno":20,
"dname":"研发部",
"loc":"深圳",
"count":20,
"avg":8000.0
};
db.dept.insert(deptData);
var deptData = {
"deptno":30,
"dname":"市场部",
};
db.dept.insert(deptData);
db.dept.find();
{ "_id" : ObjectId("5d048f4ddb2a129b32288893"), "deptno" : 10, "dname" : "财务部", "loc" : "北京" }
{ "_id" : ObjectId("5d0492d3db2a129b32288894"), "deptno" : 20, "dname" : "研发部", "loc" : "深圳", "count" : 20, "avg" : 8000 }
{ "_id" : ObjectId("5d0493c2db2a129b32288895"), "deptno" : 30, "dname" : "市场部" }
此时 dept 集合的内容可以由用户随便去定义,完全不用考虑其他的结构,那么实际上就必须明确一点了,在 MongoDB 数据库之中是绝对不可能存在有查看集合结构的操作。
3.7、关于 ID 的问题
在 MongoDB 集合中的每一行记录都会自动的生成一个 “"_id" : ObjectId("5d0493c2db2a129b32288895")” 数据,这个数据的组成是:“时间戳 + 机器码 + 进程 PID + 计数器“,这个 ID 的信息是 MongoDB 数据库自己为用户生成的。
8、查看单独的一个文档信息
db.dept.findOne();
{
"_id" : ObjectId("5d048f4ddb2a129b32288893"),
"deptno" : 10,
"dname" : "财务部",
"loc" : "北京"
}
3.9、删除数据
db.dept.remove({"_id" : ObjectId("5d048f4ddb2a129b32288893")});
WriteResult({ "nRemoved" : 1 })
db.dept.find();
"_id" : ObjectId("5d0492d3db2a129b32288894"), "deptno" : 20, "dname" : "研发部", "loc" : "深圳", "count" : 20, "avg" : 8000 }
"_id" : ObjectId("5d0493c2db2a129b32288895"), "deptno" : 30, "dname" : "市场部" }
发现财务部的信息就被删除了
3.10、更新数据(是最麻烦的)
var deptData = {
"deptno":50,
"dname":"乞讨部",
"loc":"家里蹲",
"count":60,
"avg":9000.0
};
db.dept.update({"_id" : ObjectId("5d0492d3db2a129b32288894")},deptData);
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
db.dept.find();
"_id" : ObjectId("5d0492d3db2a129b32288894"), "deptno" : 50, "dname" : "乞讨部", "loc" : "家里蹲", "count" : 60, "avg" : 9000 }
"_id" : ObjectId("5d0493c2db2a129b32288895"), "deptno" : 30, "dname" : "市场部" }
现在更新也完成了,但这个更新意义不大,因为对于更新的操作在整个集合里面是非常麻烦的,而对于整个 MongoDB 而言,能够使用的数据类型基本上也是我们熟悉的几种数据类型,比如: int 、string 、date 等。
3.11、删除集合
- 语法: db.集合名称.drop();
db.dept.drop();
true
show collections;
emp
只有 emp 表了
3.12、删除数据库(删除当前所在的数据库)
db.dropDatabase();
{ "dropped" : "mldn", "ok" : 1 }
需要注意的是,当前在哪个数据库下,执行语句后就删除哪个数据库,所有必须先切换到数据库后才可以删除。
四、数据操作(重点)
只要是数据库那么就绝对离不开最为核心的功能: CRUD ,所以在 MongoDB 里面对于数据的操作也是有支持的,但是需要提醒的是,除了增加之外,其它的都很麻烦。
4.1、数据增加
使用 “db.集合.insert()” 可以实现数据的增加操作。
范例:增加一个简单数据
use mldn # 之前被删除了,现在先切换到 mldn 数据库
db.infos.insert({"url":"www.mldn.cn"});
WriteResult({ "nInserted" : 1 })
db.infos.find();
"_id" : ObjectId("5d04a652db2a129b32288896"), "url" : "www.mldn.cn" }
范例:保存数组
> db.infos.insert([
... {"url":"www.mldn.cn"},
... {"url":"www.mldnjava.cn"}
... ]);
BulkWriteResult({
"writeErrors" : [ ],
"writeConcernErrors" : [ ],
"nInserted" : 2, # n 表示更新的行数
"nUpserted" : 0,
"nMatched" : 0,
"nModified" : 0,
"nRemoved" : 0,
"upserted" : [ ]
db.infos.find();
"_id" : ObjectId("5d04a652db2a129b32288896"), "url" : "www.mldn.cn" }
"_id" : ObjectId("5d04a78ddb2a129b32288897"), "url" : "www.mldn.cn" }
"_id" : ObjectId("5d04a78ddb2a129b32288898"), "url" : "www.mldnjava.cn" }
如果要保存多个数据,那么就使用数组。
范例:保存 10000 个数据
for (var x = 0; x < 10000; x++) {
db.infos.insert({"url" : "mldn - " + x});
}
// 此时电脑会卡一回儿
WriteResult({ "nInserted" : 1 })
db.infos.find();
"_id" : ObjectId("5d04a652db2a129b32288896"), "url" : "www.mldn.cn" }
"_id" : ObjectId("5d04a78ddb2a129b32288897"), "url" : "www.mldn.cn" }
"_id" : ObjectId("5d04a78ddb2a129b32288898"), "url" : "www.mldnjava.cn" }
"_id" : ObjectId("5d04aac0db2a129b32288899"), "url" : "mldn - 0" }
"_id" : ObjectId("5d04aac0db2a129b3228889a"), "url" : "mldn - 1" }
"_id" : ObjectId("5d04aac0db2a129b3228889b"), "url" : "mldn - 2" }
"_id" : ObjectId("5d04aac0db2a129b3228889c"), "url" : "mldn - 3" }
"_id" : ObjectId("5d04aac0db2a129b3228889d"), "url" : "mldn - 4" }
"_id" : ObjectId("5d04aac0db2a129b3228889e"), "url" : "mldn - 5" }
"_id" : ObjectId("5d04aac0db2a129b3228889f"), "url" : "mldn - 6" }
"_id" : ObjectId("5d04aac0db2a129b322888a0"), "url" : "mldn - 7" }
"_id" : ObjectId("5d04aac0db2a129b322888a1"), "url" : "mldn - 8" }
"_id" : ObjectId("5d04aac0db2a129b322888a2"), "url" : "mldn - 9" }
"_id" : ObjectId("5d04aac0db2a129b322888a3"), "url" : "mldn - 10" }
"_id" : ObjectId("5d04aac0db2a129b322888a4"), "url" : "mldn - 11" }
"_id" : ObjectId("5d04aac0db2a129b322888a5"), "url" : "mldn - 12" }
"_id" : ObjectId("5d04aac0db2a129b322888a6"), "url" : "mldn - 13" }
"_id" : ObjectId("5d04aac0db2a129b322888a7"), "url" : "mldn - 14" }
"_id" : ObjectId("5d04aac0db2a129b322888a8"), "url" : "mldn - 15" }
"_id" : ObjectId("5d04aac0db2a129b322888a9"), "url" : "mldn - 16" }
Type "it" for more
如果数据保存很多的情况下,列表时不会全部列出,它只会列出部分的内容。
4.2、数据查询
任何的数据库之中,数据的查询操作都是最为麻烦的,而在 MongoDB 数据库里面,对于查询的支持非常到位,包含有关系运算、逻辑运算、数组运算、正则运算等等。
首先对于数据的查询操作核心的语法:“db.集合名称.find({查询条件}[,{设置显示的字段}])”
范例:最简单的用法就是直接使用 find() 函数完成查询
db.infos.find();
范例:希望查询出 url 为 “www.mldn.cn” 的数据
db.infos.find({"url":"www.mldn.cn"});
{ "_id" : ObjectId("5d04a652db2a129b32288896"), "url" : "www.mldn.cn" }
{ "_id" : ObjectId("5d04a78ddb2a129b32288897"), "url" : "www.mldn.cn" }
发现在进行数据查询的时候也是按照 JSON 的形式设置的相等关系。它的整个开发之中都不可能离开 JSON 数据。
对于设置的显示字段严格来讲就称为数据的投影操作,如果不需要显示的字段设置 “ 0 ”,而需要显示的字段设置 “ 1 ”。
范例:不想显示 "_id"
db.infos.find({"url":"www.mldn.cn"},{"_id":0});
{ "url" : "www.mldn.cn" }
{ "url" : "www.mldn.cn" }
db.infos.find({"url":"www.mldn.cn"},{"_id":0,"url":1});
{ "url" : "www.mldn.cn" }
{ "url" : "www.mldn.cn" }
大部分的情况下,这种投影操作的意义不大。同时对于数据的查询也可以使用 “pretty()” 函数进行漂亮显示。
范例:漂亮显示
db.infos.find({"url":"www.mldn.cn"},{"_id":0,"url":1}).pretty();
数据列多的时候一定可以看出华丽的显示效果。
范例:查询单个数据
db.infos.findOne({"url":"www.mldn.cn"},{"_id":0,"url":1});
利用以上的查询可以实现格式化的输出效果,前提:列的内容必须多。
4.2.1 关系查询
在 MongoDB 里面支持的关系查询操作:大于($gt)、小于($lt)、大于等于($gte)、小于等于($lte)、不等于($ne)、等于(key:value,$eq)。但是要想让这些操作可以正常使用,那么需要准备出一个数据集合。
范例:定义一个学生集合
db.students.drop()
db.students.insert({"name":"张三","sex":"男","age":19,"score":89,"address":"海淀区"});
db.students.insert({"name":"李四","sex":"女","age":20,"score":59,"address":"朝阳区"});
db.students.insert({"name":"王五","sex":"女","age":19,"score":99,"address":"西城区"});
db.students.insert({"name":"赵六","sex":"男","age":20,"score":100,"address":"东城区"});
db.students.insert({"name":"孙七","sex":"男","age":19,"score":20,"address":"海淀区"});
db.students.insert({"name":"王八","sex":"女","age":21,"score":0,"address":"海淀区"});
db.students.insert({"name":"刘九","sex":"男","age":19,"score":70,"address":"朝阳区"});
db.students.insert({"name":"钱十","sex":"女","age":21,"score":56,"address":"西城区"});
db.students.find().pretty();
{
"_id" : ObjectId("5d04ba95db2a129b3228b391"),
"name" : "张三",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区"
}
{
"_id" : ObjectId("5d04ba95db2a129b3228b392"),
"name" : "李四",
"sex" : "女",
"age" : 20,
"score" : 59,
"address" : "朝阳区"
}
{
"_id" : ObjectId("5d04ba95db2a129b3228b393"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区"
}
{
"_id" : ObjectId("5d04ba96db2a129b3228b394"),
"name" : "赵六",
"sex" : "男",
"age" : 20,
"score" : 100,
"address" : "东城区"
}
{
"_id" : ObjectId("5d04ba96db2a129b3228b395"),
"name" : "孙七",
"sex" : "男",
"age" : 19,
"score" : 20,
"address" : "海淀区"
}
{
"_id" : ObjectId("5d04ba96db2a129b3228b396"),
"name" : "王八",
"sex" : "女",
"age" : 21,
"score" : 0,
"address" : "海淀区"
}
{
"_id" : ObjectId("5d04ba96db2a129b3228b397"),
"name" : "刘九",
"sex" : "男",
"age" : 19,
"score" : 70,
"address" : "朝阳区"
}
{
"_id" : ObjectId("5d04ba9fdb2a129b3228b398"),
"name" : "钱十",
"sex" : "女",
"age" : 21,
"score" : 56,
"address" : "西城区"
}
范例:查询姓名是张三的学生信息
db.students.find({"name":"张三"}).pretty();
范例:查询性别是男的学生信息
db.students.find({"sex":"男"}).pretty();
范例:查询年龄大于19岁的学生信息
db.students.find({"age":{"$gt":19}}).pretty();
范例:查询成绩大于等于60分的学生信息
db.students.find({"score":{"$gte":60}}).pretty();
范例:查询姓名不是王五的学生信息
db.students.find({"name":{"$ne":"王五"}}).pretty();
此时与之前最大的区别就在于,在一个 JSON 结构里面需要定义其它的 JSON 结构,并且这种风格在日后通过程序操作的时候依然如此。
4.2.2 逻辑运算
逻辑运算主要就是三种类型:与($and)、或($or)、非($not、$nor)。
范例:查询年龄在 19 ~ 20 岁的学生信息
db.students.find({"age":{"$gte":19,"$lte":20}}).pretty();
在进行逻辑运算的时候,“and” 的连接是最容易的,因为只需要理由 “,”分隔若干个条件就可以了。
范例:查询年龄不是19岁的学生
db.students.find({"age":{"$ne":19}}).pretty();
范例:查询年龄大于 19 岁,或者成绩大于 90 分的学生信息
db.students.find({"$or":[
{"age":{"$gt":19}},
{"score":{"$gt":90}}
]}).pretty();
范例:也可以进行或的求反操作
db.students.find({"$nor":[
{"age":{"$gt":19}},
{"score":{"$gt":90}}
]}).pretty();
针对于或的操作可以实现一个求反的功能。
在这几个逻辑运算之中,与的连接最简单,而或的连接需要为数据设置数组的过滤条件。
4.2.3 求模
模的运算使用 “$mod” 来完成,语法 “ {$mod:[数字 , 余数]} ”
db.students.find({"age":{"$mod":[20,1]}}).pretty();
// 如果 pretty 后没写 () 就会显示如下报错:
function () {
this._prettyShell = true;
return this;
利用求模计算可以编写一些数学的计算公式。
4.2.4 范围查询
只要是数据库,必须存在有 “ $in ”(在范围之中)、“ $nin ”(不在范围之中)。
范例:查询姓名是 “张三”、“李四”、“王五”的学生信息。
db.students.find({"name":{"$in":["张三","李四","王五"]}}).pretty();
范例:不在范围
db.students.find({"name":{"$nin":["张三","李四","王五"]}}).pretty();
在实际的工作之中,范围的查询很重要。
4.2.5 数组查询
首先在 MongoDB 里面是支持数组保存的,一旦支持了数组保存,就需要针对于数组的数据进行匹配。
范例:保存一部分数组内容
db.students.insert({"name":"谷大神 - A","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学","英语","音乐","政治"]});
db.students.insert({"name":"谷大神 - B","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学"]});
db.students.insert({"name":"谷大神 - C","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学","英语"]});
db.students.insert({"name":"谷大神 - D","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["英语","音乐","政治"]});
db.students.insert({"name":"谷大神 - E","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","政治"]});
此时的数据包含有数组内容,而后需要针对于数组数据进行判断,可以使用几个运算符: $all、$size、$slice、$elemMatch 。
范例:先查看全部信息
db.students.find().pretty();
{
"_id" : ObjectId("5d086129785b4dafd169aafa"),
"name" : "谷大神 - A",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区",
"course" : [
"语文",
"数学",
"英语",
"音乐",
"政治"
]
}
{
"_id" : ObjectId("5d08688a785b4dafd169aafb"),
"name" : "谷大神 - B",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区",
"course" : [
"语文",
"数学"
]
}
{
"_id" : ObjectId("5d086896785b4dafd169aafc"),
"name" : "谷大神 - C",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区",
"course" : [
"语文",
"数学",
"英语"
]
}
{
"_id" : ObjectId("5d086896785b4dafd169aafd"),
"name" : "谷大神 - D",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区",
"course" : [
"英语",
"音乐",
"政治"
]
}
{
"_id" : ObjectId("5d086898785b4dafd169aafe"),
"name" : "谷大神 - E",
"sex" : "男",
"age" : 19,
"score" : 89,
"address" : "海淀区",
"course" : [
"语文",
"政治"
]
}
范例:查询同时参加语文和数学课程的学生
- 现在两个数组内容都需要保存,所以使用 “{"$all",[内容1,内容2,...]}”
db.students.find({"course":{"$all":["语文","数学"]}}).pretty();
现在所有显示的学生信息里面包含语文和数学的内容,而如果差一个内容的不会显示。
虽然 “$all” 计算可以用于数组上,但是也可以用于一个数据的匹配上。
范例:查询学生地址是 “海淀区” 的学生信息
db.students.find({"address":{"$all":["海淀区"]}}).pretty();
既然在集合里面现在保存的是数组信息,那么数组就可以利用索引操作,使用 “key.index” 的方式来定义索引。
范例:查询数组中第二个内容(index = 1,索引下标从0)为数学的信息
db.students.find({"course.1":"数学"}).pretty();
范例:要求查询出只参加两门课程的学生
使用 “ $size ” 来进行数量的控制
db.students.find({"course":{"$size":2}}).pretty();
发现在进行数据查询的时候只要是内容符合条件,数组的内容就全部显示出来了,但是现在希望可以控制数组返回的数量,那么可以使用 “ $slice ” 进行控制。
范例:返回年龄为 19 岁所有的学生信息,但是要求只显示两门参加课程
db.students.find({"age":19},{"course":{"$slice":2}}).pretty();
现在只取得了前两门的信息,那么也可以设置负数表示取出后两门的信息。
db.students.find({"age":19},{"course":{"$slice":-2}}).pretty();
或者只是取出中间部分的信息
db.students.find({"age":19},{"course":{"$slice":[1,2]}}).pretty();
在此时设置的两个数据里面第一个数据表示跳过的数据量,而第二个数据表示返回的数量。
4.2.6 嵌套集合运算
在 MongoDB 数据库里面每一个集合数据可以继续保存其它的集合数据,例如:有些学生需要保存家长信息。
范例:增加信息
db.students.insert({"name":"高大拿 - A","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学","英语","音乐","政治"],
"parents":[
{"name":"高大拿 - A(父亲)","age":50,"job":"工人"},
{"name":"高大拿 - A(母亲)","age":46,"job":"职员"}]});
db.students.insert({"name":"高大拿 - B","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学"],
"parents":[
{"name":"高大拿 - B(父亲)","age":50,"job":"处长"},
{"name":"高大拿 - B(母亲)","age":46,"job":"局长"}]});
db.students.insert({"name":"高大拿 - C","sex":"男","age":19,"score":89,"address":"海淀区",
"course":["语文","数学","英语"],
"parents":[
{"name":"高大拿 - C(父亲)","age":50,"job":"工人"},
{"name":"高大拿 - C(母亲)","age":46,"job":"局长"}]});
此时给出的内容是嵌套的集合,而这种集合的数据的判断只能够通过 “ $elemMatch ” 来完成。
范例:查询出父母有人是局长的学生信息
db.students.find({"$and":[
{"age":{"$gte":19}},
{"parents":{"$elemMatch":{"job":"局长"}}}
]}).pretty();
由于这种查询的时候条件比较麻烦,所以如果可能,尽量别搞这么复杂的数据结构组成。
4.2.7 判断某个字段是否存在
使用 “ $exists ” 可以判断某个字段是否存在,如果设置为 true 表示存在,如果设置为 false 就表示不存在。
范例:查询具有 parents 成员的数据
db.students.find({"parents":{"$exists":true}}).pretty();
范例:查询不具有 course 成员的数据
db.students.find({"course":{"$exists":false}}).pretty();
可以利用此类查询来进行一些不需要的数据的过滤。
4.2.8 条件过滤
实际上习惯于传统关系型数据库开发的我们对于数据的筛选,可能首先想到的一定是 where 子句,所以在 MongoDB 里面也提供有 “ $where ” 。
范例:使用 where 进行数据查询
db.students.find({"$where":"this.age>20"}).pretty();
或者:
db.students.find("this.age>20").pretty();
对于 “ $where ” 是可以简化的,但是这类的操作是属于进行每一行的信息判断,实际上对于数据量较大的情况并不方便使用。
实际上以上的代码严格来讲是属于编写一个操作的函数,如下所示:
db.students.find(function(){
return this.age>20;
}).pretty();
或者:
db.students.find({"$where":function(){
return this.age>20;
}}).pretty();
以上只是查询了一个判断,如果要想实现多个条件的判断,那么就需要使用 and 连接。
db.students.find({"$and":[
{"$where":"this.age>19"},
{"$where":"this.age<21"}
]}).pretty();
虽然这种形式的操作可以实现数据查询,但是最大的缺点是将在 MongoDB 里面保存的 BSON 数据变为了 JavaScript 的语法结构,这样的方式不方便使用数据库的索引机制,所以不建议使用。
面试题:请说明 MongoDB 中 where 的过滤有什么使用限制。
回答:where 能够利用 JavaScript 查询,但是,它会把 BSON 重新变为 JavaScript 进行循环验证,这样索引是不能起作用的。
4.2.9 正则运算
如果要想实现模糊查询,那么必须使用正则表达式,而且正则表达式使用的是语言 Perl 兼容的正则表达式的形式。如果要想实现正则使用,则按照如下的定义格式:
- 基础语法:{key : 正则标记}
- 完整语法:{key : {"$regex" : 正则标记 , "$options" : 选项}}
- 对于 options 主要是设置正则的信息查询的标记:
- " i ":忽略字母大小写;
- " m ":多行查找;
- " x ":空白字符串除了被转义的或在字符类中以外的完全被忽略;
- " s ":匹配所有的字符(原点 “ . ”),包括换行内容.
- 需要注意的是,如果是直接使用(javascript)那么只能够使用 i 和 m ,而 “ x ” 和 “ s ” 必须使用 “$regex”
- 对于 options 主要是设置正则的信息查询的标记:
范例:查询以 “谷” 开头的姓名
db.students.find({"name":/谷/}).pretty();
范例:查询以字母 A 开头的姓名
db.students.find({"name":/a/i}).pretty();
完整写法:
db.students.find({"name":{"$regex":/a/i}}).pretty();
如果要执行模糊查询的操作,严格来讲只需要编写一个关键字就够了。
正则操作之中除了可以查询出单个字段的内容之外,也可以进行数组数据的查询。
db.students.find({"course":/语?/}).pretty();
db.students.find({"course":/语/}).pretty();
MongoDB 中的正则符号和之前 Java 正则是有一些小小差别,不建议使用以前的一些标记,正则就将其应用在模糊数据查询上。
4.2.10 数据排序
在 MongoDB 里面数据的排序操作使用 “ sort() ” 函数,在进行排序的时候可以有两个顺序:升序(1)、降序(-1)。
范例:数据排序
db.students.find().sort({"score":-1}).pretty();
但是在进行排序的过程里面有一种方式称为自然排序,就是按照数据保存的先后顺序排序,使用 “ $natural ” 表示。
范例:自然排序
db.students.find().sort({"$natural":-1}).pretty();
在 MongoDB 数据库里面排序的操作相比较传统关系型数据库的设置要简单。
4.2.11 数据分页显示
在 MongoDB 里面的数据分页显示也是符合于大数据要求的操作函数:
- skip(n):表示跨过多少数据行;
- limit(n):取出的数据行的个数限制。
范例:分页显示(第一页,skip(0)、limit(5))
db.students.find().skip(0).limit(5).sort({"age":-1}).pretty();
范例:分页显示(第二页,skip(5)、limit(5))
db.students.find().skip(5).limit(5).sort({"age":-1}).pretty();
这两个分页的控制操作,就是在以后只要是存在有大数据的信息情况下都会使用它。
4.3 数据更新操作
对于 MongoDB 而言,数据的更新基本上是一件很麻烦的事情,如果在实际的工作之中,真的具有此类的操作支持,那么最好的做法,在 MongoDB 里面对于数据的更新操作提供了两类函数:save()、update() 。
4.3.1 函数的基本使用
如果要修改数据最直接的使用函数就是 update() 函数,但是这个函数的语法要求很麻烦。
语法:db.集合.update(更新条件 , 新的对象数据(更新操作符) , upsert , multi);
- upsert:如果要更新的数据不存在,则增加一条新的内容(true 为增加,false 为不增加)
- multi:表示是否只更新满足条件的第一行记录,如果设置为 false ,只更新第一条,如果是 true ,全更新。
现以下面代码的数据作为待更新数据:
db.students.find().skip(0).limit(5).sort({"$natural":1}).pretty();
范例:更新存在的数据 —— 将年龄是 19 岁的人的成绩都更新为 100 分(此时会返回多条数据)
- 只更新第一条数据
db.students.update({"age":19},{"$set":{"score":100}},false,false);
结果显示:数据匹配 1 行,修改 1 行
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
"$set" 在 MongoDB 中叫修改器,现在只是修改数据用,但是严格来讲,不光内容可以修改,连集合结构也可以修改,因为它是无模式的。
- 所有满足条件的都更新
db.students.update({"age":19},{"$set":{"score":100}},false,true);
结果显示:数据匹配 12 行,修改 11 行
WriteResult({ "nMatched" : 12, "nUpserted" : 0, "nModified" : 11 })
范例:更新不存在的数据
db.students.update({"age":30},{"$set":{"name":"不存在"}},true,false);
结果显示:数据匹配 0 ,修改 0,更新了 1
WriteResult({
"nMatched" : 0,
"nUpserted" : 1,
"nModified" : 0,
"_id" : ObjectId("5d0c893d9d63a752d1fa5c73")
由于没有年龄是 30 岁的学生信息,所以此时相当于进行了数据的创建。
那么除了 update() 函数之外,还提供有一个 save() 函数,这个函数的功能与更新不存在的内容相似。
范例:使用 save() 操作(尽量不用)
db.students.save({"age":33},{"$set":{"name":"不存在2"}});
查询后结果中会显示下面一行数据:
{ "_id" : ObjectId("5d0c8e6a1e3c6c42896bac47"), "age" : 33 }
db.students.save({"_id" : ObjectId("5d0c8e6a1e3c6c42896bac47"),"age":50});
结果显示:匹配 1 行,修改 1 行
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
由于此时对应的 id 数据存在了,所以就变为了更新操作,但是如果要保存的数据不存在(不能保存有 “ _id ” 的内容),那么就变为了增加操作。
4.3.2 修改器
对 MongoDB 数据库而言,数据的修改会牵扯到内容的变更、结构的变更(包含有数组),所以在进行 MOngoDB 设计的时候就提供有一系列的修改器的应用,那么像之前使用的 “ $set ” 就是一个修改器。
1、$inc:主要针对于一个数字字段,增加某个数字字段的数据内容:
- 语法:{"$inc" : {"成员" : 内容}}
范例:将所有年龄为 19 岁的学生成绩一律减少 30 分,年龄增加 1 岁。
db.students.update({"age":19},{"$inc":{"score":-30,"age":1}});
以上代码是默认修改一条数据,下面代码是修改全部数据:
db.students.update({"age":19},{"$inc":{"score":-30,"age":1}},false,true);
2、$set:进行内容的重新设置:
- 语法:{"$set" : {"成员" : "新内容"}}
范例:将年龄是 20 岁的人的成绩修改为 89 分
db.students.update({"age":20},{"$set":{"score":89}});
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
3、$unset:删除某个成员的内容:
- 语法:{"$unset" : {"成员" : 1}}
范例:删除 “张三” 的年龄与成绩信息
db.students.update({"name":"张三"},{"$unset":{"age":1,"score":1}});
执行之后指定的成员的内容就消失了。
4、$push:相当于将内容追加到指定的成员之中(基本上是数组)
- 语法:{"$push" : {成员 : value}}
范例:向 “李四” 添加课程信息
db.students.update({"name":"李四"},{"$push":{"course":"语文"}});
db.students.find({"name":"李四"}).skip(0).limit(5).sort({"$natural":1}).pretty();
范例:向 “张三” 添加课程信息(此时张三信息下没有 course 信息)
db.students.update({"name":"张三"},{"$push":{"course":["语文","数学"]}});
db.students.find({"name":"张三"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d0ca0a01e3c6c42896bac49"),
"name" : "张三",
"sex" : "男",
"address" : "海淀区",
"score" : [
[
"语文",
"数学"
]
]
}
范例:向 "谷大神 - E" 里面的课程追加一个 “美术”
db.students.update({"name":"谷大神 - E"},{"$push":{"course":"美术"}});
db.students.find({"name":"谷大神 - E"}).skip(0).limit(5).sort({"$natural":1}).pretty();
查询结果显示添加成功,所以,"$push" 就是进行数组数据的添加操作使用的,如果没有数组则进行一个新的数组的创建,如果有则进行内容的追加。
5、$pushAll :与 “$push” 是类似的,可以一次追加多个内容到数组里面
语法:{"$pushAll" : {成员 : 数组内容}}
MongoDB 早期的版本就合并了 $push 和 $pushAll ,在 3.6 版本中取消了 $pushAll ,所以要么mongodb降级到3.4, 或者直接使用 $push 就行。
范例:向 “王五” 是信息里面添加多个课程内容
# 先添加此内容
db.students.update({"name":"王五"},{"$push":{"course":"美术"}});
db.students.update({"name":"王五"},{"$push":{"course":"音乐"}});
db.students.update({"name":"王五"},{"$push":{"course":"素描"}});
db.students.find({"name":"王五"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d1090e9f102d221d5e06526"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区",
"course" : [
"美术",
"音乐",
"素描"
]
}
# 完整代码是下面一行,但在 3.6 版本中会报错:"errmsg" : "Unknown modifier: $pushAll"
db.students.update({"name":"王五"},{"$pushAll":{"course":["美术","音乐","素描"]}});
# 直接使用 $push 添加多个课程内容
db.students.update({"name":"王五"},{"$push":{"course":["美术","音乐","素描"]}});
# 使用此种代码后的结果和上面的结果就显示不一样,数组里面又有一个数组了,相当于又加了一个数组
db.students.find({"name":"王五"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d108ff4f102d221d5e06525"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区",
"course" : [
[
"美术",
"音乐",
"素描"
]
]
}
6、$addToSet :向数组里面增加一个新的内容,只有在这个内容不存在的时候才会增加
- 语法:{"$addToSet":{成员 : 内容}}
范例:向 王五 的信息增加新的内容
db.students.update({"name":"王五"},{"$addToSet":{"course":"舞蹈"}});
此时会判断要增加的内容在数组里面是否已经存在了,如果不存在则向数组之中追加内容,如果存在则不做任何的修改操作。
# 两种添加数据的代码都执行后重新查询
> db.students.find({"name":"王五"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d1090e9f102d221d5e06526"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区",
"course" : [
"美术",
"音乐",
"素描",
"舞蹈",
[
"美术",
"音乐",
"素描"
]
]
}
7、$pop:删除数组内的数据
- 语法:{"$pop":{成员 : 内容}} ,内容如果设置为 -1 表示删除第一个,如果是 1 表示删除最后一个。
范例:删除王五的第一个课程
db.students.update({"name":"王五"},{"$pop":{"course":-1}});
范例:删除王五的最后一个课程
db.students.update({"name":"王五"},{"$pop":{"course":1}});
db.students.find({"name":"王五"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d1090e9f102d221d5e06526"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区",
"course" : [
"音乐",
"素描",
"舞蹈"
]
}
结果显示就把最后一个数组给删掉了。
8、$pull:从数组内删除一个指定内容的数据
- 语法:{"$pull":{成员 : 数据}},这里的数据是进行数据比对的,如果是此数据则删除
范例:删除王五的美术(不存在的)课程
db.students.update({"name":"王五"},{"$pull":{"course":"美术"}});
// 查询结果不会有变化
范例:删除王五的音乐(存在的)课程
db.students.update({"name":"王五"},{"$pull":{"course":"音乐"}});
db.students.find({"name":"王五"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d1090e9f102d221d5e06526"),
"name" : "王五",
"sex" : "女",
"age" : 19,
"score" : 99,
"address" : "西城区",
"course" : [
"素描",
"舞蹈"
]
}
9、$pullAll:一次性删除多个内容
- 语法:{"$pullAll":{成员 : [数据 , 数据 , 数据 , ...]}}
范例:删除 "谷大神 - A" 中三门课程
db.students.update({"name":"谷大神 - A"},{"$pullAll":{"course":["语文","数学","英语"]}});
db.students.find({"name":"谷大神 - A"}).skip(0).limit(5).sort({"$natural":1}).pretty();
{
"_id" : ObjectId("5d10885bf102d221d5e0651b"),
"name" : "谷大神 - A",
"sex" : "男",
"age" : 20,
"score" : 70,
"address" : "海淀区",
"course" : [
"音乐",
"政治"
]
}
10、$rename:为成员名称重命名
- 语法:{"$rename":{旧的成员名称 : 新的成员名称}}
范例:将 “张三” 的 name 成员名称修改为 “姓名”
db.students.update({"name":"张三"},{"$rename":{"name":"姓名"}});
db.students.find().skip(0).limit().sort({"$natural":-1}).pretty();
// 最后一条结果显示如下:
{
"_id" : ObjectId("5d1087caf102d221d5e06513"),
"sex" : "男",
"address" : "海淀区",
"course" : [
[
"语文",
"数学"
]
],
"姓名" : "张三"
}
在整个 MongoDB 数据库里面,提供的修改器的支持很到位。
4.4、删除操作
在 MOngoDB 里面数据的删除实际上并不复杂,只需要使用 “remove()” 函数就可以了。
但是在这个函数中有两个可选项:
1、删除条件:满足条件的数据被删除;
2、是否只删除一个数据,如果设置为 true 或者是 1 表示只删除一个。
范例:清空 infos 集合中的内容
db.infos.remove();
// 此类操作在 2.x 版本可以使用,在 3.x 版本会报错:Error: remove needs a query :
db.infos.remove({});
// 3.x 版本使用
范例:删除所有姓名里面带有 “谷” 的信息,默认情况下全部删除。
db.students.remove({"name":/谷/});
范例:删除姓名带有 “高” 的信息,要求只删除一个
db.students.remove({"name":/高/},true);
删除操作里面依然需要使用限定查询的相关操作内容。
4.5、游标(重点)
所谓的游标就是指的数据可以一行行的进行操作,非常类似于 ResultSet 数据处理。在 MongoDB 数据库里面对游标的控制非常的简单,只需要使用 find() 函数就可以返回游标了。对于返回的游标如果要想进行操作,使用两个函数:
- 判断是否有下一行数据:hasNext();
- 取出当前数据:next();
var cursor = db.students.find();
cursor.hasNext();
cursor.next();
以上是游标的操作形式,但是实际上不可能这么去用,因为必须利用循环才能够输出内容。
范例:编写具体的操作代码
var cursor = db.students.find();
while (cursor.hasNext()){
var doc = cursor.next();
print(doc.name);
}
相当于每一个数据都单独拿出来进行逐行的控制。
var cursor = db.students.find();
while (cursor.hasNext()){
var doc = cursor.next();
print(doc);
}
结果显示:
[object BSON]
[object BSON]
[object BSON]
当游标数据取出来之后,实际上每行数据返回的都是一个 Object 型的内容,那么如果需要将数据按照 json 的形式出现,则可以使用 printjson() 函数完成。
var cursor = db.students.find();
while (cursor.hasNext()){
var doc = cursor.next();
printjson(doc);
}
在所有已知的数据库里,只有 MongoDB 的游标操作是最简单、最直观的。
4.6、索引(重点)
在任何的数据库之中,索引都是一种提升数据库检索性能的手段,这一点在 MOngoDB 数据库之中是同样存在的,在 MongoDB 数据库里面依然会存在有两种索引创建:一种是自动创建,另外一种是手工创建。
范例:重新准备一个新的简单集合
db.students.drop()
db.students.insert({"name":"张三","sex":"男","age":19,"score":89,"address":"海淀区"});
db.students.insert({"name":"李四","sex":"女","age":20,"score":59,"address":"朝阳区"});
db.students.insert({"name":"王五","sex":"女","age":19,"score":99,"address":"西城区"});
db.students.insert({"name":"赵六","sex":"男","age":20,"score":100,"address":"东城区"});
db.students.insert({"name":"孙七","sex":"男","age":19,"score":20,"address":"海淀区"});
db.students.insert({"name":"王八","sex":"女","age":21,"score":0,"address":"海淀区"});
db.students.insert({"name":"刘九","sex":"男","age":19,"score":70,"address":"朝阳区"});
db.students.insert({"name":"钱十","sex":"女","age":21,"score":56,"address":"西城区"});
此时在 students 集合上并没有去设置任何的索引,那么下面通过 getIndexes() 函数来观察在 students 集合里面已经存在的索引内容。
范例:查询默认状态下的 students 集合的索引内容
db.students.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "mldn.students"
}
]
现在发现会存在有一个 “_id” 列的索引内容。但是如果要想创建自己的索引,则可以使用下面的语法完成:
- 索引创建:db.集合名称.ensureIndex{列 : 1}
- 设置的 1 表示索引将按照升序的方式进行排列,如果使用降序设置 “-1”。
范例:创建一个索引,在 age 字段上设置一个降序索引
db.students.ensureIndex({"age":-1});
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
db.students.getIndexes();
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "mldn.students"
},
{
"v" : 2,
"key" : {
"age" : -1
},
"name" : "age_-1",
"ns" : "mldn.students"
}
]
此时并没有设置索引的名字,所以名字是自动命名的。命名规范:“字段名称_索引的排序模式”,如:"age_-1"。
范例:针对于当前的 age 字段上的索引做一个分析
db.students.find({"age":19}).explain();
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "mldn.students",
"indexFilterSet" : false,
"parsedQuery" : {
"age" : {
"$eq" : 19
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : -1
},
"indexName" : "age_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[19.0, 19.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "ZYH6YRZXTCLMFEQ",
"port" : 27017,
"version" : "3.6.3",
"gitVersion" : "9586e557d54ef70f9ca4b43c26892cd55257e1a5"
},
"ok" : 1
}
此时的查询使用了索引的技术,但是下面再来观察一个查询,不使用索引字段。
范例:针对于 score 字段上设置查询
db.students.find({"score":{"$gt":60}}).explain();
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "mldn.students",
"indexFilterSet" : false,
"parsedQuery" : {
"score" : {
"$gt" : 60
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"score" : {
"$gt" : 60
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "ZYH6YRZXTCLMFEQ",
"port" : 27017,
"version" : "3.6.3",
"gitVersion" : "9586e557d54ef70f9ca4b43c26892cd55257e1a5"
},
"ok" : 1
}
此时在 score 字段上并没有设置索引,所以当前的索引形式就变成了全集合扫描的模式。
但是如果说,现在换一种形式,年龄和成绩一起执行判断查询会出现什么样的结果?
db.students.find({"$or":[
{"age":{"$gt":19}},
{"score":{"$gt":60}}
]}).explain();
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "mldn.students",
"indexFilterSet" : false,
"parsedQuery" : {
"$or" : [
{
"age" : {
"$gt" : 19
}
},
{
"score" : {
"$gt" : 60
}
}
]
},
"winningPlan" : {
"stage" : "SUBPLAN",
"inputStage" : {
"stage" : "COLLSCAN",
"filter" : {
"$or" : [
{
"age" : {
"$gt" : 19
}
},
{
"score" : {
"$gt" : 60
}
}
]
},
"direction" : "forward"
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "ZYH6YRZXTCLMFEQ",
"port" : 27017,
"version" : "3.6.3",
"gitVersion" : "9586e557d54ef70f9ca4b43c26892cd55257e1a5"
},
"ok" : 1
}
这个时候虽然 age 字段上存在有索引,但是一个明显的问题是,由于 score 字段上没有索引,所以依然是使用的是全表扫描操作,那么为了解决此时的问题,可以使用一个复合索引。
db.students.ensureIndex({"age":-1,"score":-1},{name:"age_-1_score_-1_index"});
范例:默认使用索引
db.students.find({"age":19,"score":89}).explain();
但是如果换到了条件之中:
db.students.find({"$or":[
{"age":{"$gt":19}},
{"score":{"$gt":60}}
]}).explain();
现在发现并没有使用索引,所以这个时候看能否强制使用一次索引。hint() 函数为强制使用索引操作。
范例:强制使用索引
db.students.find({"$or":[
{"age":{"$gt":19}},
{"score":{"$gt":60}}]}).hint({"age":-1,"score":-1}).explain();
部分结果显示:
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"age" : -1,
"score" : -1
},
"indexName" : "age_-1_score_-1_index",
"isMultiKey" : false,
"multiKeyPaths" : {
"age" : [ ],
"score" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"age" : [
"[MaxKey, MinKey]"
],
"score" : [
"[MaxKey, MinKey]"
]
}
如果正常来讲,这个代码根本就不可能调用默认的索引执行,但是我们觉得不好,所以需要使用 hint() 函数来强制 MongoDB ,告诉你必须使用一次索引,由于此时在 age 和 score 两个字段上已经设置了复合索引,那么现在使用的就是默认的复合索引。
但是如果在一个集合里面设置了过多的索引,实际上会导致性能下降,那么就可以删除索引。
范例:删除一个索引
db.students.dropIndex({"age":-1,"score":-1});
可是如果只是一个一个删除索引也会很麻烦,所以提供有删除全部索引的操作。
范例:删除全部索引
db.students.dropIndexes();
所谓的删除全部索引指的就是非 “_id” 的索引,也就是所有的自定义索引。
索引不应该太多,而且不应该在频繁更新的数据上设置索引,这样反而会降低性能。所以索引的操作一般要经过测试和分析之后才能决定是否去使用索引。
数据量大概在几万几十万条使用意义不大,在几百万几千万条数据中使用索引意义更明显。
4.6.1 唯一索引
唯一索引的主要目的是用在某一个字段上,使该字段的内容不重复。
范例:创建唯一索引
db.students.ensureIndex({"name":1},{"unique":true});
表示在 name 字段上的内容绝对不允许重复。
添加只有 name 一样的数据:
db.students.insert({"name":"张三","sex":"女","age":22,"score":100,"address":"房山区"});
此时除了 name 字段上的内容之外,发现所有的数据都不一样,但是由于在 name 字段上设置了唯一索引,所以整个的程序里面如果增加了重复内容,那么会出现以下的错误提示信息:
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 11000,
"errmsg" : "E11000 duplicate key error collection: test.students index: name_1 dup key: { : \"寮犱笁\" }"
}
})
唯一索引能够保证指定字段上的数据不重复。
4.6.2 过期索引
在一些程序站点会出现若干秒之后信息被删除的情况,例如:手机信息验证码,那么在 MongoDB 里面就可以轻松的实现过期索引,但是这个时间往往不怎么准确。
范例:设置过期索引
db.phones.ensureIndex({"time":1},{expireAfterSeconds:10});
设置索引在10秒后过期
范例:在一个 phones 集合里面设置过期索引
如果要想实现过期索引,需要保存一个时间信息:
db.phones.insert({"tel":"110","code":"110","time":new Date()});
db.phones.insert({"tel":"111","code":"111","time":new Date()});
db.phones.insert({"tel":"112","code":"112","time":new Date()});
db.phones.insert({"tel":"113","code":"113","time":new Date()});
db.phones.insert({"tel":"114","code":"114","time":new Date()});
等到10秒以后(永远不会那么准确)所保存的数据就会消失。这样的特性在进行一些临时数据保存的时候非常有帮助,最早如果没有 MongoDB 这种特性,而只是使用最简单的关系型数据库开发,那么是非常麻烦的。
4.6.3 全文索引
在一些信息管理平台上经常需要进行信息模糊查询,最早的时候是利用了某个字段上实现的模糊查询,但是这个时候返回的信息并不会很准确,因为只能够查 A 字段或者是 B 字段,而在 MongoDB 里面实现了非常简单的全文检索。
范例:定义一个新的集合
db.news.insert({"title":"mldn mldnjava lxh gyh","content":"gyh"});
db.news.insert({"title":"gyh","content":"sfq"});
db.news.insert({"title":"gyh","content":"gry"});
db.news.insert({"title":"sfq","content":"gry"});
范例:设置全文检索
db.news.ensureIndex({"title":"text","content":"text"});
范例:实现数据的模糊查询
如果要想表示出全文检索,则使用 “$text” 判断符,而要想进行数据的查询则使用 “$search” 运算符:
|- 查询指定关键字:{"$search" : "查询关键字"};
|- 查询多个关键字(或关系):{"$search" : "查询关键字 查询关键字 查询关键字 ..."}
|- 查询多个关键字(与关系):{"$search" : ""查询关键字\ "" 查询关键字\ "..."}
|- 查询多个关键字(排除某一个):{"$search" : "查询关键字 查询关键字 查询关键字 ... -排除关键字"}
范例:查询单个内容
db.news.find({"$text":{"$search":"gry"}});
范例:查询包含有 “gry” 和 “sfq” 的信息
db.news.find({"$text":{"$search":"gry gyh"}});
范例:查询同时包含有 “mldn” 与 “lxh” 的内容
db.news.find({"$text":{"$search":"\"mldn\" \"lxh\""}});
范例:查询包含有 “mldn” 但是没有 “gyh” 的内容
db.news.find({"$text":{"$search":"\"mldn\" \"lxh\" -gyh"}});
但是在进行全文检索操作的时候还可以使用相似度的打分来判断检索成果。
范例:为结果打分
db.news.find({"$text":{"$search":"gyh"}},{"score":{"$meta":"textScore"}});
db.news.find({"$text":{"$search":"gyh"}},{"score":{"$meta":"textScore"}}).sort({"score":{"$meta":"textScore"}});
按照打分的成绩进行排列,实际上就可以实现更加准确的信息检索。
但是在这里面还有一个小问题,如果一个集合的字段太多了,那么每一个字段都分别设置全文检索麻烦点,简单一些,可以为所有的字段设置全文检索。
范例:为所有字段设置全文检索
// 删除索引
db.news.dropIndexes();
// 设置全文检索
db.news.ensureIndex({"$**":"text"});
// 执行索引操作
db.news.find({"$text":{"$search":"gyh"}},{"score":{"$meta":"textScore"}}).sort({"score":{"$meta":"textScore"}});
这是一种最简单的设置全文索引的方式,但是尽可能别用,一个字:慢!
4.6.4 地理信息索引
地理信息索引分为两类:2D 平面索引,另外就是 2DSphere 球面索引。在 2D 索引里面基本上能够保存的信息都是坐标,而且坐标保存的就是经纬度坐标。
范例:定义一个商铺的集合
db.shop.insert({loc:[10,10]});
db.shop.insert({loc:[11,10]});
db.shop.insert({loc:[10,11]});
db.shop.insert({loc:[12,15]});
db.shop.insert({loc:[16,17]});
db.shop.insert({loc:[90,90]});
db.shop.insert({loc:[120,130]});
范例:为 shop 集合定义 2D 索引
db.shop.ensureIndex({"loc":"2d"});
这个时候 shop 集合就可以实现坐标位置的查询了,而要进行查询有两种方式:
- “$near” 查询:查询距离某个点最近的坐标点
- “$geoWithin” 查询:查询某个形状内的点
范例:假设我的现在的坐标是:[11,11]
db.shop.find({loc:{"$near":[11,11]}});
但是如果执行了以上的查询,实际上会将数据集合里面的前 100 个点的信息都都返回来了,可是太远了,设置一个距离范围 —— 5 个点内的。
范例:设置查询距离范围
db.shop.find({loc:{"$near":[11,11],"$maxDistance":5}});
但是需要注意一点,在 2D 索引里面虽然支持最大距离,但是不支持最小距离。
但是也可以设置一个查询的范围,使用 “$geoWithin” 查询,而可以设置的范围:
- 矩形范围($box):{"$box":[[x1,y1],[x2,y2]]}
- 圆形范围($center):{"$center":[[x1,y1],r]}
- 多边形($polygon):{"$polygon":[[x1,y1],[x2,y2],[x3,y3],...]}
范例:查询矩形
db.shop.find({loc:{"$geoWithin":{"$box":[[9,9],[11,11]]}}});
范例:查询圆形
db.shop.find({loc:{"$geoWithin":{"$center":[[10,10],2]}}});
在 MongoDB 数据库里面,除了一些支持的操作函数之外,还有一个重要的命令:runCommand(),这个函数可以执行所有的特定的 MongoDB 命令。
范例:利用 runCommand() 实现信息查询
db.runCommand({"geoNear":"shop",near:[10,10],maxDistance:5,num:2});
这类的命令可以说是 MongoDB 之中最为基础的命令。
4.7、聚合(重点)
MongoDB 的产生背景是在大数据环境,所谓的大数据实际上也就是进行的信息收集汇总。那么就必须存在有信息的统计操作,而这样的统计操作就称为聚合(直白:分组统计就是一种聚合操作)。
4.7.1 取得集合的数据量
对于集合的数据量而言,在 MongoDB 里面直接使用 count() 函数就可以完成。
范例:统计 students 表中的数据量
db.students.count();
范例:模糊查询
db.students.count({"name":/张/i});
在进行信息查询的时候,不设置条件永远要比设置条件的查询快很多,也就是说在之前的代码编写里面不管是查询全部还是模糊查询,实际上最终都使用的是模糊查询一种(没有关键字)
4.7.2 消除重复数据
在学习 SQL 的时候对于重复的数据可以使用 “DISTINCT” ,那么这一操作在 MongoDB 之中依然支持。
范例:查询所有 name 的信息
- 本次的操作没有直接的函数支持,只能够利用 runCommand() 函数。
// 先添加一条姓名相同的数据
db.students.insert({"name":"张三","sex":"女","age":22,"score":100,"address":"房山区"});
db.runCommand({"distinct":"students","key":"name"});
此时实现了对于 name 数据的重复值的筛选。
4.7.3 group 操作
使用 “group” 操作可以实现数据的分组操作,在 MongoDB 里面会将集合依据指定的 key 的不同进行分组操作,并且每一个组都会产生一个处理的文档结果。
范例:查询所有年龄大于等于 19 岁的学生信息,并且按照年龄分组
db.runCommand({"group":{
"ns":"students",
"key":{"age":true},
"initial":{"count":0},
"condition":{"age":{"$gte":19}},
"$reduce":function(doc,prev){
prev.count ++; // 表示数量加一
}
}});
以上的操作代码里面实现的就属于一种 MapReduce ,但是这样只是根据传统的数据库的设计思路,实现了一个所谓的分组操作,但是这个分组的最终结果是有限的。
4.7.4 MapReduce
MapReduce 是整个大数据的精髓所在(实际中别用),所谓的 MapReduce 就是分为两步处理数据:
Map:将数据分别取出
Reduce:负责数据的最后的处理
可是要想在 MongoDB 里面实现 MapReduce 处理,那么复杂度是相当高的。
范例:建立一组雇员数据
db.emps.insert({"name":"张三","age":30,"sex":"男","job":"CLERK","salary":1000});
db.emps.insert({"name":"李四","age":28,"sex":"女","job":"CLERK","salary":5000});
db.emps.insert({"name":"王五","age":26,"sex":"男","job":"MANAGER","salary":6000});
db.emps.insert({"name":"赵六","age":32,"sex":"女","job":"MANAGER","salary":7000});
db.emps.insert({"name":"孙七","age":31,"sex":"男","job":"CLERK","salary":2000});
db.emps.insert({"name":"王八","age":35,"sex":"女","job":"PRESIDENT","salary":9000});
使用 MapReduce 操作最终会将处理结果保存在一个单独的集合里面,而最终的处理效果如下:
范例:按照职位分组,取得每个职位的人名
- 第一步:编写分组定义:
var jobMapFun = function(){
emit(this.job,this.name); // 按照 job 分组,取出 name
};
第一组:{key:"CLERK",values:[姓名,姓名,...]}
- 第二步:编写 reduce 操作:
var jobReduceFun = function(key,values){
return{age:key, names:values};
}
- 第三步:针对于 MapReduce 处理完成的数据实际上也可以执行一个最后处理。
var jobFinalzeFun = function(key,values){
if (key == "PRESIDENT"){
return{"job":key, "names":values,"info":"公司的老大"};
}
return{"job":key, "names":values};
}
- 第四步:进行操作的整合:
db.runCommand({
"mapreduce":"emp",
"map":jobMapFun,
"reduce":jobReduceFun
});
{
"ok" : 0,
"errmsg" : "'out' has to be a string or an object",
"code" : 13606,
"codeName" : "Location13606"
}
显示错误信息,表示缺少 “out”,“out” 指的是最终的保存结果的集合。
db.runCommand({
"mapreduce":"emps",
"map":jobMapFun,
"reduce":jobReduceFun,
"out":"t_job_emp",
"finalize":jobFinalzeFun
});
{
"result" : "t_job_emp",
"timeMillis" : 282,
"counts" : {
"input" : 6,
"emit" : 6,
"reduce" : 2,
"output" : 3
},
"ok" : 1
}
现在执行之后,所有的处理结果都保存在了 “ t_job_emp ” 集合里面。
db.t_job_emp.find().pretty();
{
"_id" : "CLERK",
"value" : {
"job" : "CLERK",
"names" : {
"job" : "CLERK",
"names" : [
"张三",
"李四",
"孙七"
]
}
}
}
{
"_id" : "MANAGER",
"value" : {
"job" : "MANAGER",
"names" : {
"job" : "MANAGER",
"names" : [
"王五",
"赵六"
]
}
}
}
{
"_id" : "PRESIDENT",
"value" : {
"job" : "PRESIDENT",
"names" : "王八",
"info" : "公司的老大"
}
}
范例:统计出各性别的人数、平均工资、最低工资、雇员姓名
var sexMapFun = function(){
// 定义好了分组的条件,以及每个集合要取出的内容
emit(this.sex,{"ccount":1,"csal":this.salary,"cmax":this.salary,"cmin":this.salary,"cname":this.name});
};
var sexReduceFun = function(key,values){
var total = 0; // 统计
var sum = 0; // 计算总工资
var max = values[0].cmax; // 假设第一个数据是最高工资
var min = values[0].cmin; // 假设第一个数据是最低工资
var names = new Array(); // 定义数组内容
for (var x in values){ //表示循环取出里面的数据
total += values[x].ccount; // 人数增加
sum += values[x].csal; // 就可以循环取出所有的工资,并且累加
if (max < values[x].cmax){ // 不是最高工资
max = values[x].cmax;
}
if (min > values[x].cmin){ // 不是最低工资
min = values[x].cmin;
}
names[x] = values[x].cname; // 保存姓名
}
var avg = (sum / total).toFixed(2);
// 返回数据的处理结果
return {"count":total,"avg":avg,"sum":sum,"max":max,"min":min,"names":names};
};
db.runCommand({
"mapreduce":"emps",
"map":sexMapFun,
"reduce":sexReduceFun,
"out":"t_sex_emp"
});
db.t_sex_emp.find().pretty();
{
"_id" : "女",
"value" : {
"count" : 3,
"avg" : "7000.00",
"sum" : 21000,
"max" : 9000,
"min" : 5000,
"names" : [
"李四",
"赵六",
"王八"
]
}
}
{
"_id" : "男",
"value" : {
"count" : 3,
"avg" : "3000.00",
"sum" : 9000,
"max" : 6000,
"min" : 1000,
"names" : [
"张三",
"王五",
"孙七"
]
}
}
虽然大数据的时代提供有最强悍的 MapReduce 支持,但是从现实的开发来讲,真的不可能使用起来。
4.7.5 聚合框架(核心)
MapReduce 功能强大,但是它的复杂度和功能一样强大,那么很多时候我们需要 MapReduce 的功能,可是又不想把代码写的太复杂,所以从 Mongo 2.x 版本之后开始引入了聚合框架并且提供了聚合函数:aggregate() 。
4.7.5.1、 $group
“ $group ” 主要进行分组的数据操作。
范例:实现聚合查询的功能 —— 求出每个职位的雇员人数
db.emps.aggregate([{"$group":{"_id":"$job", job_count:{"$sum":1}}}]);
{ "_id" : "MANAGER", "job_count" : 2 }
{ "_id" : "PRESIDENT", "job_count" : 1 }
{ "_id" : "CLERK", "job_count" : 3 }
这样的操作更加符合于传统的 group by 子句的操作使用。
范例:求出每个职位的总工资
db.emps.aggregate([{"$group":{"_id":"$job", "job_sal":{"$sum":"$salary"}}}]);
{ "_id" : "MANAGER", "job_sal" : 13000 }
{ "_id" : "PRESIDENT", "job_sal" : 9000 }
{ "_id" : "CLERK", "job_sal" : 8000 }
在整个聚合框架里面如果要引用每行的数据使用:“ $字段名称 ” 。
范例:继续计算出每个职位的平均工资
db.emps.aggregate([{"$group":{
"_id":"$job",
"job_sal":{"$sum":"$salary"},
"job_avg":{"$avg":"$salary"}
}}]);
范例:求出最高与最低工资
db.emps.aggregate([{"$group":{
"_id":"$job",
"max_sal":{"$max":"$salary"},
"min_sal":{"$min":"$salary"}
}}]);
以上的几个与 SQL 类似的操作计算就成功实现了。
范例:计算出每个职位的工资数据(数组显示)
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$push":"$salary"}
}}]);
范例:求出每个职位的人员
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$push":"$name"}
}}]);
// 添加重复数据
db.emps.insert({"name":"赵六","age":32,"sex":"女","job":"MANAGER","salary":7000});
db.emps.insert({"name":"孙七","age":31,"sex":"男","job":"CLERK","salary":2000});
db.emps.insert({"name":"王八","age":35,"sex":"女","job":"PRESIDENT","salary":9000});
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$push":"$name"}
}}]);
使用 “ $push ” 的确可以将数据变为数组进行保存,但是有一个问题出现了,重复的内容也会进行保存,那么在 MongoDB 里面提供有取消重复的设置。
范例:取消重复的数据
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$addToSet":"$name"}
}}]);
默认情况下是将所有数据都保存进去了,但是现在只希望可以保留第一个或者是最后一个。
范例:保存第一个内容(无序的)
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$first":"$name"}
}}]);
范例:保存最后一个内容
db.emps.aggregate([{"$group":{
"_id":"$job",
"sal_data":{"$last":"$name"}
}}]);
虽然可以方便的实现分组处理,但是有一点需要注意,所有的分组数据是无序的,并且都是在内存之中完成的,所以不可能支持大数据量。
4.7.5.2、 $project
可以利用 “ $project ” 来控制数据列的显示规则,那么可以执行的规则如下:
|- 普通列({成员 : 1 | true}):表示要显示的内容
|- “ _id ” 列({"_id" : 0 | false}):表示 “ _id ” 列是否显示
|-条件过滤列({成员 : 表达式}):满足表达式之后的数据可以进行显示
范例:只显示 name 列,不显示 “ _id ” 列
db.emps.aggregate([{"$project":{
"_id":0,
"name":1
}}]);
此时只有设置进去的列才可以被显示出来,而其它的列不能够被显示出来。实际上这就属于数据库的投影机制。
实际上在进行数据投影的过程里面也支持四则运算:加法(“$add”)、减法(“$subtract”)、乘法(“$multiply”)、除法(“$divide”)、求模(“$mod”)。
范例:观察四则运算
// 起别名
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"职位":"$job",
"salary":1
}}]);
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"job":1,
"salary":1
}}]);
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"job":1,
"salary":{"年薪":{"$multiply":["$salary",12]}}
}}]);
除了四则运算之外也支持如下的各种运算符:
- 关系运算:大小比较(“$cmp”)、等于(“$eq”)、大于(“$gt”)、大于等于(“$gte”)、小于(“$lt”)、小于等于(“$lte”)、不等于(“$ne”)、判断 NULL (“$ifNull”),这些返回的结果都是布尔型数据。
- 逻辑运算:与(“$and”)、或(“$or”)、非(“$not”);
- 字符串操作:连接(“$concat”)、截取(“$substr”)、转小写(“$toLower”)、转大写(“$toUpper”)、不区分大小写比较(“$strcasecmp”)。
范例:找出所有工资大于等于 2000 的雇员姓名、年龄、工资。
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"age":1,
"job":1,
"工资":"$salary",
"salary":{"$gte":["$salary",2000]}
}}]);
范例:查询职位是 manager 的信息
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"职位":"$job",
"job":{"$eq":["$job","MANAGER"]}
}}]);
MongoDB 中的数据是区分大小写的,如果上面的 “MANAGER” 改为 “manager” 查到的数据就会都返回 false ,使用 "$toUpper" 转大写后显示正确信息了。
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"职位":"$job",
"job":{"$eq":["$job",{"$toUpper":"manager"}]}
}}]);
还可以不区分大小写
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"职位":"$job",
"job":{"$strcasecmp":["$job","manager"]}
}}]);
范例:使用字符串截取
db.emps.aggregate([{"$project":{
"_id":0,
"name":1,
"职位":"$job",
"job":{"前面三位":{"$substr":["$job",0,3]}}
}}]);
利用 “$project” 实现的投影操作功能相当强大,所有可以出现的操作几乎都能够使用。
更多聚合操作可以查看文档:https://docs.mongodb.com/manual/aggregation/
4.7.5.3、 $match
“ $match ” 是一个过滤操作,就是进行 WHERE 的过滤。
范例:查询工资在 2000~5000 的雇员
db.emps.aggregate([{"$match":{
"salary":{"$gte":2000,"$lte":5000}
}}]);
这个时候实现的代码严格来讲只是相当于 “ SELECT * FROM 表 WHERE 条件 ”
范例:控制投影操作
db.emps.aggregate([
{"$match":{
"salary":{"$gte":2000,"$lte":5000}}},
{"$project":{"_id":0,name:1,salary:1}}
]);
此时相当于实现了 “ SELECT 字段 FROM ... WHERE ... ” 语句结构。
范例:继续分组
db.emps.aggregate([
{"$match":{
"salary":{"$gte":2000,"$lte":5000}}},
{"$project":{"_id":0,name:1,salary:1,"job":1}},
{"$group":{"_id":"$job","count":{"$sum":1},"avg":{"$avg":"$salary"}}}
]);
通过一系列的演示可以总结一点:
- “ $project ” :相当于 SELECT 子句;
- “ $match ”:相当于 WHERE 子句;
- “ $group ”:相当于 GROUP BY 子句。
4.7.5.4、 $sort
使用 “ $sort ” 可以实现排序,设置 1 表示升序,设置 -1 表示降序
范例:实现排序
db.emps.aggregate([{"$sort":{"age":-1,"salary":1}}]);
范例:将所有的操作一起使用
db.emps.aggregate([
{"$match":{
"salary":{"$gte":1000,"$lte":10000}}},
{"$project":{"_id":0,name:1,salary:1,"job":1}},
{"$group":{"_id":"$job","count":{"$sum":1},"avg":{"$avg":"$salary"}}},
{"$sort":{"count":-1}}
]);
此时实现了降序排序,使用的是生成定义的别名。
4.7.5.5、 分页处理:$limit、$skip
“$limit”:负责数据的取出个数
“$skip”:数据的跨过个数
范例:使用 “$limit” 设置取出的个数
db.emps.aggregate([
{"$project":{"_id":0,"name":1,"salary":1,"job":1}},
{"$limit":2}
]);
范例:跨过三行数据
db.emps.aggregate([
{"$project":{"_id":0,"name":1,"salary":1,"job":1}},
{"$skip":3},
{"$limit":2}
]);
范例:综合应用
db.emps.aggregate([
{"$match":{
"salary":{"$gte":1000,"$lte":10000}}},
{"$project":{"_id":0,name:1,salary:1,"job":1}},
{"$group":{"_id":"$job","count":{"$sum":1},"avg":{"$avg":"$salary"}}},
{"$sort":{"count":-1}},
{"$skip":1},
{"$limit":1}
]);
只能够说现在的查询可以在实际的开发之中使用了。
4.7.5.6、 $unwind
在查询数据的时候经常会返回数组信息,但是数组并不方便信息的浏览,所以提供有 “ $unwind” 可以将数组数据变为独立的字符串内容。
范例 :添加一些信息
db.depts.insert({"title":"技术部","bus":["研发","生产","培训"]});
db.depts.insert({"title":"财务部","bus":["工资","税收"]});
范例 :将信息进行转化
db.depts.aggregate([
{"$project":{"_id":0,"title":true,"bus":true}},
{"$unwind":"$bus"}]);
此时相当于将数组中的数据变为单行的数据
4.7.5.7、$geoNear
使用 “$geoNear” 可以得到附件的坐标点。
范例 :准备测试数据
db.shop.drop()
db.shop.insert({loc:[10,10]});
db.shop.insert({loc:[11,10]});
db.shop.insert({loc:[10,11]});
db.shop.insert({loc:[12,15]});
db.shop.insert({loc:[16,17]});
db.shop.insert({loc:[90,90]});
db.shop.insert({loc:[120,130]});
db.shop.ensureIndex({"loc":"2d"});
范例 :设置查询
db.shop.aggregate([
{"$geoNear":{
"near":[11,12],
"distanceField":"loc",
"maxDistance":1,
"num":2,
"spherical":true}}]);
地理信息的检索必须存在有索引的支持。
4.7.5.8、$out
“$out”:利用此操作可以将查询结果输出到指定的集合里面。
范例 :将投影的结果输出到集合里
db.emps.aggregate([
{"$project":{"_id":0,"name":1,"salary":1,"job":1}},
{"$out":"emp_infos"}]);
这类的操作就相当于实现了最早的数据库的复制工作
4.8、深入操作
4.8.1 固定集合
所谓的固定集合指的是规定集合大小,如果要保存的内容已经超过了集合的长度,那么会采用 LRU 的算法(最近最少使用原则)将最早的数据移除,从而保存新的数据。
默认情况下一个集合可以使用 createCollection() 函数创建,或者使用增加数据后自动创建,但是如果想使用固定的集合,就必须明确的创建一个空集合。
范例 :创建一个空集合(固定集合)
db.createCollection("depts",{"capped":true,"size":1024,"max":5});
其中,“capped:true” 表示为一个固定的集合,而 “size:1024” 指的是集合所占的空间容量(字节),“max:5” 表示最多只能够有 5 条记录。
范例 :向集合里保存5条数据
db.depts.insert({"deptno":10,"dname":"财务部 - A","loc":"北京"});
db.depts.insert({"deptno":11,"dname":"财务部 - B","loc":"北京"});
db.depts.insert({"deptno":12,"dname":"财务部 - C","loc":"北京"});
db.depts.insert({"deptno":13,"dname":"财务部 - D","loc":"北京"});
db.depts.insert({"deptno":14,"dname":"财务部 - E","loc":"北京"});
此时已经达到了集合的上限,那么继续保存新的内容。
db.depts.insert({"deptno":15,"dname":"财务部 - F","loc":"北京"});
db.depts.find();
此时最早保留的数据已经消失了,实际上这种操作跟缓存机制是非常相似的,例如:在百度上经常会出现一些搜索的关键词(热门),这些词都是会被不断替换的。
4.8.2 GridFS
在 MOngoDB 里面支持大数据的存储(例如:图片、音乐、各种二进制数据),但是这个做法需要用户自己进行处理了,就是使用 “mongofiles” 命令完成。
1、利用命令行进入到所在的路径下;
2、将文件保存到文件库之中;
mongofiles put photo.jpg
mongofiles --port=27001 put photo.jpg
此时会向数据库里面写入要保存的二进制数据
3、查看保存的文件
mongofiles --port=27001 list
4、在 MongoDB 里面有一个 fs 系统集合,这个 集合默认保存在了 test 数据库下
use test;
shoe collections;
db.fs.files.find();
{ "_id" : ObjectId("5d196be0ac14ce095c93249a"), "chunkSize" : 261120, "uploadDate" : ISODate("2019-07-01T02:11:45.100Z"), "length" : 2785199, "md5" : "7234c038e7b5fcff213b92f8860da4f3", "filename" : "photo.jpg" }
5、删除文件
mongofiles --port=27001 delete photo.jpg
等于在 MongoDB 里面支持二进制数据的保存,但是存在的意义不大。
4.9、用户管理
在 MongoDB 里面默认情况下只要是进行连接都可以不使用用户名与密码,因为要想让其起作用,则必须具备以下两个条件:
条件一:服务器启动的时候打开授权认证
条件二:需要配置用户名密码
但是需要明确的是,如果要想配置用户名和密码,一定是针对于一个数据库的,例如现在要创建的是 mldn 数
据库的用户,那么就必须先切换到 mldn 数据库上。
use mldn;
范例 :执行用户的创建( hello 、java)、
任何的用户都必须具备有一个自己的操作角色,对于角色最基础的角色:read 、readWrite
db.createUser({
"user":"hello",
"pwd":"java",
"roles":[{"role":"readWrite","db":"mldn"}]});
那么现在就表示成功的创建了 hello 用户。那么如果要想让此用户名起作用,则必须以授权的方式打开 MongoDB 的服务,修改 MongoDB 的启动文件。
范例 :新的启动配置文件
// 设置数据目录的路径
dbpath = D:\MongoDB\db
// 设置日志信息的文件路径
logpath = D:\MongoDB\log\mongodb.log
// 打开日志输出操作
logappend = true
// 在以后进行用户管理的时候使用它
auth = true
port = 27001
此时增加了一个验证的启动模式,发现依然可以在不输入用户名和密码的前提下进行登录,并且也可以直接进行数据库的切换操作,但是在使用数据库集合的时候出现了错误提示。
范例 :登录数据库的时候使用用户名与密码
mongo localhost:27001/mldn -u hello -p java
此时就表示成功的实现了用户的登录操作。
范例 :修改密码
db.changeUserPassword("hello","happy");
如果要修改密码,那么请关闭授权登录。
4.10、Java 执行 Mongo 操作
既然已经强调了 Mongo 作为辅助数据库,那么就必须清楚如何利用程序来进行 MongoDB 的操作。
4.10.1、Mongo-Java-2.x
下面通过几个程序代码来演示 Mongo 的数据库操作。
范例 :连接数据库
package cn.mldn.demo;
import com.gongodb.MOngoClient;
public class MongoDemoA{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
for (String name:db.getCollectionNames()) {
System.out.println("集合名字:" + name);
}
}
client.close(); // 关闭数据库连接
}
}
此时数据库已经可以正常的进行连接操作了,当取得了 MongoDB 数据库的连接之后,那么就意味着可以进行集合操作了,例如:现在要保存一个 deptcol 的集合信息。
范例 :保存数据
package cn.mldn.demo;
import com.mongodb.BasicDBObject;
import com.mongodb.DB;
import com.mongodb.DBCollection;
import com.gongodb.MOngoClient;
public class MongoDemoB{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
for (int x = 0; x < 100; x ++) {
BasicDBObject obj = new BasicDBObject();
obj.append("deptno", 1000 + x); // 设置部门编号
obj.append("dname", "技术部 - " + x);
obj.append("loc", "北京 - " + x);
col.insert(obj); // 保存数据
}
}
client.close(); // 关闭数据库连接
}
}
// 数据库中
show collections;
db.deptcol.find();
此时已经可以向集合里面成功的进行了数据的保存操作。
范例:读取数据
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoC{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBCursor cursor = col.find(); // 得到全部内容
while (cursor.hasNext()) {
DBObject obj = cursor.next(); // 得到每一个内容
System.out.println("部门编号:" + obj.get("deptno") + ",名称:" + obj.get("dname"));
}
}
client.close(); // 关闭数据库连接
}
}
以上列出的操作有一些遗憾,就是要进行全部数据的显示,这样的做法明显是不好的,可以使用分页。
范例:使用分页处理
DBCursor cursor = col.find().skip(0).limit(10); // 得到全部内容
但是针对于查询,往往都需要设置一些查询条件,所有的查询条件可以通过 BasicDBObject 类设置。
范例:设置查询条件
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoE{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBObject cond = new BasicDBObject(); // 准备设置查询过滤条件
// 设置deptno 的数据范围在 1000~1020 之间
cond.put("deptno",new BasicDBObject("$gte",1000).append("$lte,1020"));
// 设置之前所定义的查询条件
DBCursor cursor = col.find(cond).skip(0).limit(50); // 得到全部内容
while (cursor.hasNext()) {
DBObject obj = cursor.next(); // 得到每一个内容
System.out.println("部门编号:" + obj.get("deptno") + ",名称:" + obj.get("dname"));
}
}
client.close(); // 关闭数据库连接
}
}
范例:设置范围查询 —— in
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoF{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBObject cond = new BasicDBObject(); // 准备设置查询过滤条件
// 设置deptno 的数据范围在 1000~1020 之间
cond.put("deptno",new BasicDBObject("$in",new int[]{1001,1003,1005}));
// 设置之前所定义的查询条件
DBCursor cursor = col.find(cond).skip(0).limit(50); // 得到全部内容
while (cursor.hasNext()) {
DBObject obj = cursor.next(); // 得到每一个内容
System.out.println("部门编号:" + obj.get("deptno") + ",名称:" + obj.get("dname"));
}
}
client.close(); // 关闭数据库连接
}
}
范例:执行模糊查询
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoG{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
Pattern pattern = Pattern.compile("5"); // 设置过滤条件
DBObject cond = new BasicDBObject(); // 准备设置查询过滤条件
// 设置deptno 的数据范围在 1000~1020 之间
cond.put("dename",new BasicDBObject("$regex",pattern));
// 设置之前所定义的查询条件
DBCursor cursor = col.find(cond).skip(0).limit(50); // 得到全部内容
while (cursor.hasNext()) {
DBObject obj = cursor.next(); // 得到每一个内容
System.out.println("部门编号:" + obj.get("deptno") + ",名称:" + obj.get("dname"));
}
}
client.close(); // 关闭数据库连接
}
}
到此为止已经实现了数据的增加、查询等操作功能。
范例:数据一行修改
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoH{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBObject condA = new BasicDBObject(); // 准备设置要修改的过滤条件
condA.put("deptno",1000); // 设置修改的内容
DBObject condB = new BasicDBObject; // 修改器的设置
condB.put("$set",new BasicDBObject("dname","修改后的部门名称"));
WriteResult result = col.update(condA,condB);
System.out.println(result.getN());
}
client.close(); // 关闭数据库连接
}
}
db.deptcol.find();
范例:修改多行数据
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoI{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBObject condA = new BasicDBObject(); // 准备设置要修改的过滤条件
condA.put("deptno",new BasicDBObject("$gte",1000).append("$lte,1020")); // 设置修改的内容
DBObject condB = new BasicDBObject; // 修改器的设置
condB.put("$set",new BasicDBObject("dname","修改后的部门名称"));
WriteResult result = col.updateMulti(condA,condB);
System.out.println(result.getN());
}
client.close(); // 关闭数据库连接
}
}
db.deptcol.find();
范例:删除数据
package cn.mldn.demo;
import com.mongodb.*;
public class MongoDemoJ{
public static void main(String[] args) throws Exception{
// 设置要连接的数据库的主机名与端口号
MongoClient client = new MongoClient("localhost",27001);
DB db = client.getDB("mldn"); // 连接数据库
// 进行数据库的用户名与密码验证
if (db.authehticate("hello","happy".toCharArray())) {
DBCollection col = db.getCollection("deptcol"); // 要操作的集合名字
DBObject cond = new BasicDBObject(); // 准备设置要修改的过滤条件
cond.put("deptno",new BasicDBObject("$gte",1000).append("$lte,1020"));
WriteResult result = col.remove(cond);
System.out.println(result.getN());
}
client.close(); // 关闭数据库连接
}
}
db.deptcol.find();
这个时候基本的 CRUD 就完成了,强烈要求记住:只做这些功能。
4.10.2、Mongo-Java-3.x
Mongo 2.x 的操作基本上流程都是固定的,但是在 Mongo 3.x 里面这个类几乎就跟重写没什么区别。
在 Mongo 2.x 开发包里面只需要使用 MongoClient 就可以定义连接地址与端口号。
范例:连接数据库
import com.mongodb.MongoClientURI;
public class Mongo3DemoA {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
System.out.println(db.getCollection("deptcol").count());
client.close()
}
}
范例:数据增加
package cn.mldn;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
public class Mongo3DemoB {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
list<Document> all = new ArrayList<Document>();
for (int x = 0; x < 100; x ++) {
Document doc = new Document();
doc.append("sid", x);
doc.append("name","姓名 - " + x);
doc.append("sex", "男");
all.add(doc);
}
col.insertMany(all);
client.close()
}
}
db.stucol.find();
范例:查询全部数据
package cn.mldn;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
public class Mongo3DemoC {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
MongoCursor<Document> cursor = col.find().iterator();
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
client.close()
}
}
范例:设置范围查询
package cn.mldn;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
public class Mongo3DemoC {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
MongoCursor<Document> cursor = col.find().iterator();
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
client.close()
}
}
package cn.mldn;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import java.util.ArrayList;
import java.util.List;
public class Mongo3DemoD {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
BasicDBObject cond = new BasicDBObject();
cond.put("sid", new BasicDBObject("$gt",5).append("$lt", 10));
MongoCursor<Document> cursor = col.find(cond).iterator();
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
client.close()
}
}
范例:模糊查询
package cn.mldn;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
public class Mongo3DemoE {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
Pattern pattern = Pattern.compile("10");
BasicDBObject cond = new BasicDBObject();
cond.put("name", new BasicDBObject("$regex",pattern));
//cond.put("name", new BasicDBObject("$regex",pattern).append("$options","i")); // 不区分大小写
MongoCursor<Document> cursor = col.find(cond).iterator();
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
client.close()
}
}
范例:分页显示
package cn.mldn;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
public class Mongo3DemoF {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
Pattern pattern = Pattern.compile("1");
BasicDBObject cond = new BasicDBObject();
cond.put("name", new BasicDBObject("$regex",pattern));
//cond.put("name", new BasicDBObject("$regex",pattern).append("$options","i")); // 不区分大小写
MongoCursor<Document> cursor = col.find(cond).skip(5).limit(5).iterator();
while (cursor.hasNext()) {
System.out.println(cursor.next());
}
client.close()
}
}
范例:数据修改
package cn.mldn;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
public class Mongo3DemoG {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
BasicDBObject condA = new BasicDBObject("sid",0); // 数据的查询条件
BasicDBObject condB = new BasicDBObject("$set",new BasicDBObject("name","SuperMan));
UpdateResult result = col.updateMany(condA,condB);
System.out.println(result.getMatchedCount());
client.close()
}
}
db.stucol.find();
范例:删除数据
package cn.mldn;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
public class Mongo3DemoH {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
MongoCollection col = db.getCollection("stucol");
BasicDBObject cond = new BasicDBObject("sid",0); // 数据的查询条件
DeleteResult result = col.deleteOne(cond)
System.out.println(result.getDeleteCount());
client.close()
}
}
范例:统计查询
package cn.mldn;
import com.mongodb.BasicDBObject;
import com.mongodb.MongoClient;
import com.mongodb.MongoClientURI;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoCursor;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.result.DeleteResult;
import org.bson.Document;
public class Mongo3DemoI {
public static void main(String[] args){
MongoClientURI uri = new MongoClientURI("mongodb://hello:happy@localhost:27001/mldn");
MongoClient client = new MOngoClient(uri);
MongoDatabase db = client.getDatabase("mldn");
List<BasicDBObject> all = new ArrayList<BasicDBObject>();
MongoCollection col = db.getCollection("emps"); // 这个集合有数据
BasicDBObject cond = new BasicDBObject("$group",new BasicDBObject("_id","sex").append("count",new BasicDBObject("$sum",1)).append("avg",new BasicDBObject("$avg","$salary")));
all.add(cond); // 保存条件
MongoCursor<Document> cursor = col.aggregate(all).iterator();
while(cursor.hasNext()) {
Document doc = cursor.next();
System.out.println(doc.getString("_id") + "," + doc.getInteger("count") + "," + doc.getDouble("avg"));
}
client.close()
}
}
综述:
MongoDB 实际上是作为一个附属数据库存在,只有 Node.JS 把它作为正室,但是除了 Node.JS 之外,MongoDB 就是一个不能够单独使用的数据库,都需要与传统的关系型数据库匹配在一起使用。
说明:本资料根据 《李兴华 Java 培训 - MongoDB 数据库》整理,不足之处欢迎各位大神评论或给出建议!
MongoDB 数据库的学习与使用的更多相关文章
- 对于Mongodb数据库的学习
数据库主要分为两种 1.关系型数据库(RDBS) 2.非关系性数据库(NoSQL) 而MongoDB就是非关系型数据库里的一种 文档型数据库(BSON) 文档型数据库(BSON)顾名思义就是以文档的形 ...
- Mongodb数据库学习系列————(一)Mongodb数据库主从复制的搭建
Mongodb数据库主从复制的搭建 Writeby:lipeng date:2014-10-22 最近项目上用到了位置查询,在网上 ...
- MongoDB索引(一) --- 入门篇:学习使用MongoDB数据库索引
这个系列文章会分为两篇来写: 第一篇:入门篇,学习使用MongoDB数据库索引 第二篇:进阶篇,研究数据库索引原理--B/B+树的基本原理 1. 准备工作 在学习使用MongoDB数据库索引之前,有一 ...
- mongodb数据库学习【安装及简单增删改查】
//@desn:mongodb数据库学习 //@desn:码字不宜,转载请注明出处 //@author:张慧源 <turing_zhy@163.com> //@date:2018/08/ ...
- MongoDB学习笔记:MongoDB 数据库的命名、设计规范
MongoDB学习笔记:MongoDB 数据库的命名.设计规范 第一部分,我们先说命名规范. 文档 设计约束 UTF-8 字符 不能包含 \0 字符(空字符),这个字符标识建的结尾 . 和 $ ...
- Mongodb数据库学习
数据库 MongoDB (芒果数据库) 数据存储阶段 文件管理阶段 (.txt .doc .xls)优点 : 数据可以长期保存 可以存储大量的数据 使用简单 缺点 : 数据一致性差 数据查找修改不方便 ...
- python学习笔记——mongodb数据库
1 概述 1.1 文件管理阶段 优点:可以长期保存 能存储大量数据 缺点:没有结构化的组织 查找不方便 数据容易冗余 1.2 数据库管理阶段 有文件存储的优点,同时解决了文件存储的问题 缺点 : 操作 ...
- 【MongoDB学习之二】MongoDB数据库、文档、集合、元数据
环境 MongoDB 4.0 CentOS6.5_x64 一.连接语法格式: mongodb://[username:password@]host1[:port1][,host2[:port2],.. ...
- MongoDB学习【四】—pymongo操作mongodb数据库
一.pymongodb的安装 Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接. pip安装 pip 是一个通用的 Python 包管理工具, ...
随机推荐
- jenkins +Jmeter 完成分布式性能测试
1.Jmeter 压测机器配置. 下载Jmeter 版本:https://jmeter.apache.org/download_jmeter.cgi 我下的是5.1.1 将下载后的版本进行解压. ...
- 快速java环境变量配置记录
配置java环境变量就是将java.exe和javac.exe的路径告诉系统,让系统能够找到这两个exe文件,废话不多说,直接开始如何配置环境变量,安装jdk时记住你的安装位置.(配置时必须要的) ...
- 带新手玩转MVC——不讲道理就是干(上)
带新手玩转MVC——不讲道理就是干(上) 前言:这几天更新了几篇博客,都是关于Servlet.JSP的理解,后来又写了两种Web开发模式,发现阅读量还可以,说明JSP还是受关注的,之前有朋友评论说JS ...
- 第三章 jsp数据交互(二)
Application:当前服务器(可以包含多个会话):当服务器启动后就会创建一个application对象,被所有用户共享page.request.session.application四个作用域对 ...
- JDBC教程
JDBC代表Java与数据库的连接,这对Java编程语言和广泛的数据库之间独立于数据库的连接标准的Java API. JDBC库包含的API为每个通常与数据库的使用相关联的任务: 使得连接到数据库 创 ...
- Soso(嗖嗖)移动 java 项目
1.接口 通话服务 package Soso; // 接口 通话服务 public interface CallService { public abstract int call(int minCo ...
- string的学习
原:https://blog.csdn.net/qq_37941471/article/details/82107077 一. string的构造函数的形式: string str:生成空字符串 st ...
- Promise异步编程解决方案
Promise是ES6中新增的异步编程解决方案,体现在代码中它是一个对象,可以通过 Promise 构造函数来实例化. 其最基本的使用 new Promise(function(resolve,rej ...
- 微服务之springboot 自定义配置(一)Application配置文件
配置的文件的格式 springboot可以识别两种格式的配置文件,分别是yml和properties 文件.我们可以将application.properties文件换成application.yml ...
- 自定义仿 IPhone 开关控件
极力推荐文章:欢迎收藏 Android 干货分享 阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android 本篇文章主要介绍 Android 开发中的部分知识点,通过阅读本篇文章,您将收获以 ...