kafka源码分析(一)server启动分析
1 启动入口Kafka.scala
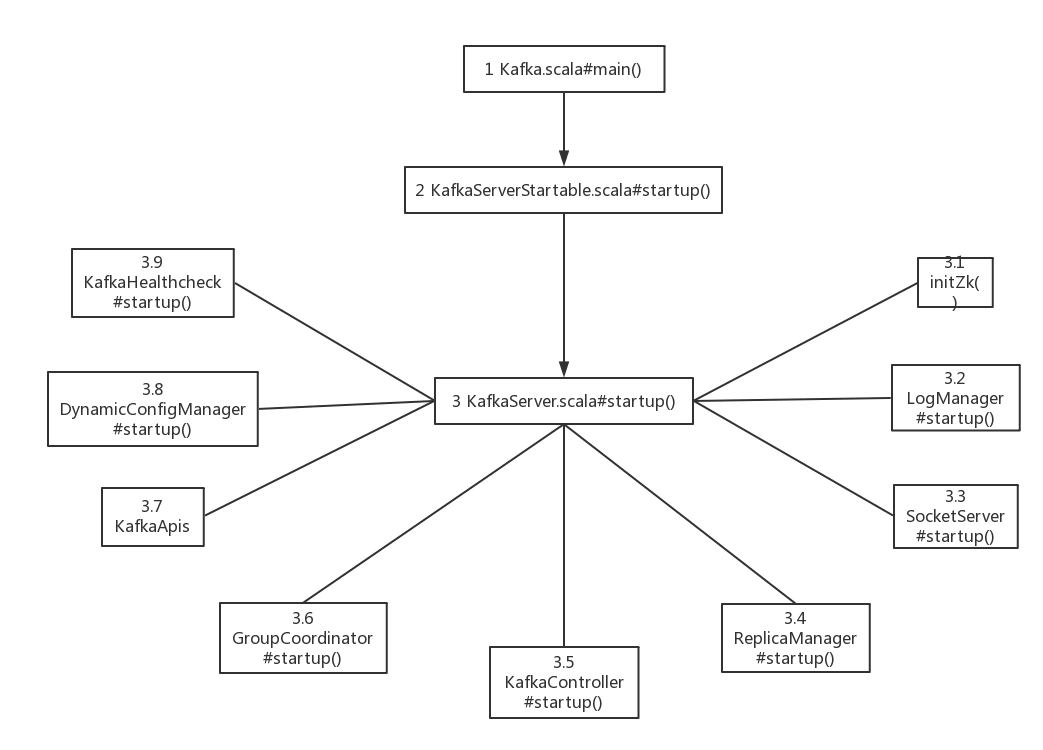
Kafka的启动入口是Kafka.scala的main()函数:
def main(args: Array[String]): Unit = {
try {
//通过args读取properties
val serverProps = getPropsFromArgs(args)
val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps)
// 增加shutdown方法
Runtime.getRuntime().addShutdownHook(new Thread() {
override def run() = {
kafkaServerStartable.shutdown
}
})
kafkaServerStartable.startup
kafkaServerStartable.awaitShutdown
}
catch {
case e: Throwable =>
fatal(e)
System.exit()
}
System.exit()
}
上面代码主要包含:
从配置文件读取kafka服务器启动参数的getPropsFromArgs()方法;
- 创建KafkaServerStartable对象;
- KafkaServerStartable对象增加shutdown函数;
- 启动KafkaServerStartable的starup()方法;
- 启动KafkaServerStartable的awaitShutdown()方法;
2 KafkaServer的包装类KafkaServerStartable
def startup() {
try {
server.startup()
}
catch {
case e: Throwable =>
fatal("Fatal error during KafkaServerStartable startup. Prepare to shutdown", e)
System.exit()
}
}
3 具体启动类KafkaServer
KafkaServer启动的代码层次比较清晰,加上注释,基本没有问题:
/**
* 启动接口
* 生成Kafka server实例
* 实例化LogManager、SocketServer和KafkaRequestHandlers
*/
def startup() {
try { if (isShuttingDown.get)
throw new IllegalStateException("Kafka server is still shutting down, cannot re-start!") if (startupComplete.get)
return val canStartup = isStartingUp.compareAndSet(false, true)
if (canStartup) {
brokerState.newState(Starting) /* start scheduler */
kafkaScheduler.startup() /* setup zookeeper */
zkUtils = initZk() /* Get or create cluster_id */
_clusterId = getOrGenerateClusterId(zkUtils)
info(s"Cluster ID = $clusterId") /* generate brokerId */
config.brokerId = getBrokerId
this.logIdent = "[Kafka Server " + config.brokerId + "], " /* create and configure metrics */
val reporters = config.getConfiguredInstances(KafkaConfig.MetricReporterClassesProp, classOf[MetricsReporter],
Map[String, AnyRef](KafkaConfig.BrokerIdProp -> (config.brokerId.toString)).asJava)
reporters.add(new JmxReporter(jmxPrefix))
val metricConfig = KafkaServer.metricConfig(config)
metrics = new Metrics(metricConfig, reporters, time, true) quotaManagers = QuotaFactory.instantiate(config, metrics, time)
notifyClusterListeners(kafkaMetricsReporters ++ reporters.asScala) /* start log manager */
logManager = createLogManager(zkUtils.zkClient, brokerState)
logManager.startup() metadataCache = new MetadataCache(config.brokerId)
credentialProvider = new CredentialProvider(config.saslEnabledMechanisms) socketServer = new SocketServer(config, metrics, time, credentialProvider)
socketServer.startup() /* start replica manager */
replicaManager = new ReplicaManager(config, metrics, time, zkUtils, kafkaScheduler, logManager,
isShuttingDown, quotaManagers.follower)
replicaManager.startup() /* start kafka controller */
kafkaController = new KafkaController(config, zkUtils, brokerState, time, metrics, threadNamePrefix)
kafkaController.startup() adminManager = new AdminManager(config, metrics, metadataCache, zkUtils) /* start group coordinator */
// Hardcode Time.SYSTEM for now as some Streams tests fail otherwise, it would be good to fix the underlying issue
groupCoordinator = GroupCoordinator(config, zkUtils, replicaManager, Time.SYSTEM)
groupCoordinator.startup() /* Get the authorizer and initialize it if one is specified.*/
authorizer = Option(config.authorizerClassName).filter(_.nonEmpty).map { authorizerClassName =>
val authZ = CoreUtils.createObject[Authorizer](authorizerClassName)
authZ.configure(config.originals())
authZ
} /* start processing requests */
apis = new KafkaApis(socketServer.requestChannel, replicaManager, adminManager, groupCoordinator,
kafkaController, zkUtils, config.brokerId, config, metadataCache, metrics, authorizer, quotaManagers,
clusterId, time) requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.requestChannel, apis, time,
config.numIoThreads) Mx4jLoader.maybeLoad() /* start dynamic config manager */
dynamicConfigHandlers = Map[String, ConfigHandler](ConfigType.Topic -> new TopicConfigHandler(logManager, config, quotaManagers),
ConfigType.Client -> new ClientIdConfigHandler(quotaManagers),
ConfigType.User -> new UserConfigHandler(quotaManagers, credentialProvider),
ConfigType.Broker -> new BrokerConfigHandler(config, quotaManagers)) // Create the config manager. start listening to notifications
dynamicConfigManager = new DynamicConfigManager(zkUtils, dynamicConfigHandlers)
dynamicConfigManager.startup() /* tell everyone we are alive */
val listeners = config.advertisedListeners.map { endpoint =>
if (endpoint.port == 0)
endpoint.copy(port = socketServer.boundPort(endpoint.listenerName))
else
endpoint
}
kafkaHealthcheck = new KafkaHealthcheck(config.brokerId, listeners, zkUtils, config.rack,
config.interBrokerProtocolVersion)
kafkaHealthcheck.startup() // Now that the broker id is successfully registered via KafkaHealthcheck, checkpoint it
checkpointBrokerId(config.brokerId) /* register broker metrics */
registerStats() brokerState.newState(RunningAsBroker)
shutdownLatch = new CountDownLatch(1)
startupComplete.set(true)
isStartingUp.set(false)
AppInfoParser.registerAppInfo(jmxPrefix, config.brokerId.toString)
info("started")
}
}
catch {
case e: Throwable =>
fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e)
isStartingUp.set(false)
shutdown()
throw e
}
}
3.1 KafkaScheduler
KafkaScheduler是一个基于java.util.concurrent.ScheduledThreadPoolExecutor的调度器,它内部是以前缀kafka-scheduler-xx(xx是线程序列号)的线程池处理真正的工作。
/**
* KafkaScheduler是一个基于java.util.concurrent.ScheduledThreadPoolExecutor的scheduler
* 它内部是以前缀kafka-scheduler-xx的线程池处理真正的工作
*
* @param threads 线程池里线程的数量
* @param threadNamePrefix 使用时的线程名称,这个前缀将有一个附加的数字
* @param daemon 如果为true,线程将是守护线程,并且不会阻塞jvm关闭
*/
@threadsafe
class KafkaScheduler(val threads: Int,
val threadNamePrefix: String = "kafka-scheduler-",
daemon: Boolean = true) extends Scheduler with Logging {
private var executor: ScheduledThreadPoolExecutor = null
private val schedulerThreadId = new AtomicInteger(0) override def startup() {
debug("Initializing task scheduler.")
this synchronized {
if (isStarted)
throw new IllegalStateException("This scheduler has already been started!")
executor = new ScheduledThreadPoolExecutor(threads)
executor.setContinueExistingPeriodicTasksAfterShutdownPolicy(false)
executor.setExecuteExistingDelayedTasksAfterShutdownPolicy(false)
executor.setThreadFactory(new ThreadFactory() {
def newThread(runnable: Runnable): Thread =
Utils.newThread(threadNamePrefix + schedulerThreadId.getAndIncrement(), runnable, daemon)
})
}
}
3.2 zk初始化
zookeeper初始化主要完成两件事情:
// 连接到zk服务器;创建通用节点
val zkUtils = ZkUtils(config.zkConnect,
sessionTimeout = config.zkSessionTimeoutMs,
connectionTimeout = config.zkConnectionTimeoutMs,
secureAclsEnabled)
zkUtils.setupCommonPaths()
通用节点包括:
// 这些是在kafka代理启动时应该存在的路径
val persistentZkPaths = Seq(ConsumersPath,
BrokerIdsPath,
BrokerTopicsPath,
ConfigChangesPath,
getEntityConfigRootPath(ConfigType.Topic),
getEntityConfigRootPath(ConfigType.Client),
DeleteTopicsPath,
BrokerSequenceIdPath,
IsrChangeNotificationPath)
3.3 日志管理器LogManager
LogManager是kafka的子系统,负责log的创建,检索及清理。所有的读写操作由单个的日志实例来代理。
/**
* 启动后台线程,负责log的创建,检索及清理
*/
def startup() {
/* Schedule the cleanup task to delete old logs */
if (scheduler != null) {
info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs))
scheduler.schedule("kafka-log-retention",
cleanupLogs,
delay = InitialTaskDelayMs,
period = retentionCheckMs,
TimeUnit.MILLISECONDS)
info("Starting log flusher with a default period of %d ms.".format(flushCheckMs))
scheduler.schedule("kafka-log-flusher",
flushDirtyLogs,
delay = InitialTaskDelayMs,
period = flushCheckMs,
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-recovery-point-checkpoint",
checkpointRecoveryPointOffsets,
delay = InitialTaskDelayMs,
period = flushCheckpointMs,
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-delete-logs",
deleteLogs,
delay = InitialTaskDelayMs,
period = defaultConfig.fileDeleteDelayMs,
TimeUnit.MILLISECONDS)
}
if (cleanerConfig.enableCleaner)
cleaner.startup()
}
3.4 SocketServer
/**
* SocketServer是socket服务器,
* 线程模型是:1个Acceptor线程处理新连接,Acceptor还有多个处理器线程,每个处理器线程拥有自己的选择器和多个读socket请求Handler线程。
* handler线程处理请求并产生响应写给处理器线程
*/
class SocketServer(val config: KafkaConfig, val metrics: Metrics, val time: Time, val credentialProvider: CredentialProvider) extends Logging with KafkaMetricsGroup {
3.5 复制管理器ReplicaManager
启动ISR线程
def startup() {
// 启动ISR过期线程
// 一个follower可以在配置上落后于leader。在它被从ISR中移除之前,复制
scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)
scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges, period = 2500L, unit = TimeUnit.MILLISECONDS)
}
3.6 kafka控制器KafkaController
当kafka 服务器的控制器模块启动时激活
def startup() = {
inLock(controllerContext.controllerLock) {
info("Controller starting up")
registerSessionExpirationListener()
isRunning = true
controllerElector.startup
info("Controller startup complete")
}
}
session过期监听器注册:
private def registerSessionExpirationListener() = {
zkUtils.zkClient.subscribeStateChanges(new SessionExpirationListener())
}
public void subscribeStateChanges(final IZkStateListener listener) {
synchronized (_stateListener) {
_stateListener.add(listener);
}
}
class SessionExpirationListener() extends IZkStateListener with Logging {
this.logIdent = "[SessionExpirationListener on " + config.brokerId + "], "
@throws(classOf[Exception])
def handleStateChanged(state: KeeperState) {
// do nothing, since zkclient will do reconnect for us.
}
选主过程:
def startup {
inLock(controllerContext.controllerLock) {
controllerContext.zkUtils.zkClient.subscribeDataChanges(electionPath, leaderChangeListener)
elect
}
}
def elect: Boolean = {
val timestamp = SystemTime.milliseconds.toString
val electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp))
leaderId = getControllerID
/*
* We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition,
* it's possible that the controller has already been elected when we get here. This check will prevent the following
* createEphemeralPath method from getting into an infinite loop if this broker is already the controller.
*/
if(leaderId != -1) {
debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId))
return amILeader
}
try {
val zkCheckedEphemeral = new ZKCheckedEphemeral(electionPath,
electString,
controllerContext.zkUtils.zkConnection.getZookeeper,
JaasUtils.isZkSecurityEnabled())
zkCheckedEphemeral.create()
info(brokerId + " successfully elected as leader")
leaderId = brokerId
onBecomingLeader()
} catch {
case e: ZkNodeExistsException =>
// If someone else has written the path, then
leaderId = getControllerID
if (leaderId != -1)
debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId))
else
warn("A leader has been elected but just resigned, this will result in another round of election")
case e2: Throwable =>
error("Error while electing or becoming leader on broker %d".format(brokerId), e2)
resign()
}
amILeader
}
def amILeader : Boolean = leaderId == brokerId
3.7 GroupCoordinator
GroupCoordinator处理组成员管理和offset管理,每个kafka服务器初始化一个协作器来负责一系列组别。每组基于它们的组名来赋予协作器。
def startup() {
info("Starting up.")
heartbeatPurgatory = new DelayedOperationPurgatory[DelayedHeartbeat]("Heartbeat", brokerId)
joinPurgatory = new DelayedOperationPurgatory[DelayedJoin]("Rebalance", brokerId)
isActive.set(true)
info("Startup complete.")
}
注意:若同时需要一个组锁和元数据锁,请务必保证先获取组锁,然后获取元数据锁来防止死锁。
3.8 KafkaApis消息处理接口
/**
* Top-level method that handles all requests and multiplexes to the right api
*/
def handle(request: RequestChannel.Request) {
try{
trace("Handling request:%s from connection %s;securityProtocol:%s,principal:%s".
format(request.requestObj, request.connectionId, request.securityProtocol, request.session.principal))
request.requestId match {
case RequestKeys.ProduceKey => handleProducerRequest(request)
case RequestKeys.FetchKey => handleFetchRequest(request)
case RequestKeys.OffsetsKey => handleOffsetRequest(request)
case RequestKeys.MetadataKey => handleTopicMetadataRequest(request)
case RequestKeys.LeaderAndIsrKey => handleLeaderAndIsrRequest(request)
case RequestKeys.StopReplicaKey => handleStopReplicaRequest(request)
case RequestKeys.UpdateMetadataKey => handleUpdateMetadataRequest(request)
case RequestKeys.ControlledShutdownKey => handleControlledShutdownRequest(request)
case RequestKeys.OffsetCommitKey => handleOffsetCommitRequest(request)
case RequestKeys.OffsetFetchKey => handleOffsetFetchRequest(request)
case RequestKeys.GroupCoordinatorKey => handleGroupCoordinatorRequest(request)
case RequestKeys.JoinGroupKey => handleJoinGroupRequest(request)
case RequestKeys.HeartbeatKey => handleHeartbeatRequest(request)
case RequestKeys.LeaveGroupKey => handleLeaveGroupRequest(request)
case RequestKeys.SyncGroupKey => handleSyncGroupRequest(request)
case RequestKeys.DescribeGroupsKey => handleDescribeGroupRequest(request)
case RequestKeys.ListGroupsKey => handleListGroupsRequest(request)
case requestId => throw new KafkaException("Unknown api code " + requestId)
}
} catch {
case e: Throwable =>
if ( request.requestObj != null)
request.requestObj.handleError(e, requestChannel, request)
else {
val response = request.body.getErrorResponse(request.header.apiVersion, e)
val respHeader = new ResponseHeader(request.header.correlationId) /* If request doesn't have a default error response, we just close the connection.
For example, when produce request has acks set to 0 */
if (response == null)
requestChannel.closeConnection(request.processor, request)
else
requestChannel.sendResponse(new Response(request, new ResponseSend(request.connectionId, respHeader, response)))
}
error("error when handling request %s".format(request.requestObj), e)
} finally
request.apiLocalCompleteTimeMs = SystemTime.milliseconds
}
我们以处理消费者请求为例:
/**
* Handle a produce request
*/
def handleProducerRequest(request: RequestChannel.Request) {
val produceRequest = request.requestObj.asInstanceOf[ProducerRequest]
val numBytesAppended = produceRequest.sizeInBytes val (authorizedRequestInfo, unauthorizedRequestInfo) = produceRequest.data.partition {
case (topicAndPartition, _) => authorize(request.session, Write, new Resource(Topic, topicAndPartition.topic))
} // the callback for sending a produce response
def sendResponseCallback(responseStatus: Map[TopicAndPartition, ProducerResponseStatus]) { val mergedResponseStatus = responseStatus ++ unauthorizedRequestInfo.mapValues(_ => ProducerResponseStatus(ErrorMapping.TopicAuthorizationCode, -1)) var errorInResponse = false mergedResponseStatus.foreach { case (topicAndPartition, status) =>
if (status.error != ErrorMapping.NoError) {
errorInResponse = true
debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format(
produceRequest.correlationId,
produceRequest.clientId,
topicAndPartition,
ErrorMapping.exceptionNameFor(status.error)))
}
} def produceResponseCallback(delayTimeMs: Int) { if (produceRequest.requiredAcks == 0) {
// no operation needed if producer request.required.acks = 0; however, if there is any error in handling
// the request, since no response is expected by the producer, the server will close socket server so that
// the producer client will know that some error has happened and will refresh its metadata
if (errorInResponse) {
val exceptionsSummary = mergedResponseStatus.map { case (topicAndPartition, status) =>
topicAndPartition -> ErrorMapping.exceptionNameFor(status.error)
}.mkString(", ")
info(
s"Closing connection due to error during produce request with correlation id ${produceRequest.correlationId} " +
s"from client id ${produceRequest.clientId} with ack=0\n" +
s"Topic and partition to exceptions: $exceptionsSummary"
)
requestChannel.closeConnection(request.processor, request)
} else {
requestChannel.noOperation(request.processor, request)
}
} else {
val response = ProducerResponse(produceRequest.correlationId,
mergedResponseStatus,
produceRequest.versionId,
delayTimeMs)
requestChannel.sendResponse(new RequestChannel.Response(request,
new RequestOrResponseSend(request.connectionId,
response)))
}
} // When this callback is triggered, the remote API call has completed
request.apiRemoteCompleteTimeMs = SystemTime.milliseconds quotaManagers(RequestKeys.ProduceKey).recordAndMaybeThrottle(produceRequest.clientId,
numBytesAppended,
produceResponseCallback)
} if (authorizedRequestInfo.isEmpty)
sendResponseCallback(Map.empty)
else {
val internalTopicsAllowed = produceRequest.clientId == AdminUtils.AdminClientId // call the replica manager to append messages to the replicas
replicaManager.appendMessages(
produceRequest.ackTimeoutMs.toLong,
produceRequest.requiredAcks,
internalTopicsAllowed,
authorizedRequestInfo,
sendResponseCallback) // if the request is put into the purgatory, it will have a held reference
// and hence cannot be garbage collected; hence we clear its data here in
// order to let GC re-claim its memory since it is already appended to log
produceRequest.emptyData()
}
}
3.9 动态配置管理DynamicConfigManager
利用zookeeper做动态配置中心
/**
* Begin watching for config changes
*/
def startup() {
zkUtils.makeSurePersistentPathExists(ZkUtils.EntityConfigChangesPath)
zkUtils.zkClient.subscribeChildChanges(ZkUtils.EntityConfigChangesPath, ConfigChangeListener)
processAllConfigChanges()
} /**
* Process all config changes
*/
private def processAllConfigChanges() {
val configChanges = zkUtils.zkClient.getChildren(ZkUtils.EntityConfigChangesPath)
import JavaConversions._
processConfigChanges((configChanges: mutable.Buffer[String]).sorted)
} /**
* Process the given list of config changes
*/
private def processConfigChanges(notifications: Seq[String]) {
if (notifications.size > 0) {
info("Processing config change notification(s)...")
val now = time.milliseconds
for (notification <- notifications) {
val changeId = changeNumber(notification) if (changeId > lastExecutedChange) {
val changeZnode = ZkUtils.EntityConfigChangesPath + "/" + notification val (jsonOpt, stat) = zkUtils.readDataMaybeNull(changeZnode)
processNotification(jsonOpt)
}
lastExecutedChange = changeId
}
purgeObsoleteNotifications(now, notifications)
}
}
3.10 心跳检测KafkaHealthcheck
心跳检测也使用zookeeper维持:
def startup() {
zkUtils.zkClient.subscribeStateChanges(sessionExpireListener)
register()
}
/**
* Register this broker as "alive" in zookeeper
*/
def register() {
val jmxPort = System.getProperty("com.sun.management.jmxremote.port", "-1").toInt
val updatedEndpoints = advertisedEndpoints.mapValues(endpoint =>
if (endpoint.host == null || endpoint.host.trim.isEmpty)
EndPoint(InetAddress.getLocalHost.getCanonicalHostName, endpoint.port, endpoint.protocolType)
else
endpoint
)
// the default host and port are here for compatibility with older client
// only PLAINTEXT is supported as default
// if the broker doesn't listen on PLAINTEXT protocol, an empty endpoint will be registered and older clients will be unable to connect
val plaintextEndpoint = updatedEndpoints.getOrElse(SecurityProtocol.PLAINTEXT, new EndPoint(null,-1,null))
zkUtils.registerBrokerInZk(brokerId, plaintextEndpoint.host, plaintextEndpoint.port, updatedEndpoints, jmxPort)
}
4 小结
kafka中KafkaServer类,是网络处理,io处理等的入口.
ReplicaManager 副本管理
KafkaApis 处理所有request的Proxy类,根据requestKey决定调用具体的handler
KafkaRequestHandlerPool 处理request的线程池,请求处理池
LogManager kafka文件存储系统管理,负责处理和存储所有Kafka的topic的partiton数据
TopicConfigManager 监听此zk节点的⼦子节点/config/changes/,通过LogManager更新topic的配置信息,topic粒度配置管理
KafkaHealthcheck 监听zk session expire,在zk上创建broker信息,便于其他broker和consumer获取其信息
KafkaController kafka集群中央控制器选举,leader选举,副本分配。
KafkaScheduler 负责副本管理和日志管理调度等等
ZkClient 负责注册zk相关信息.
BrokerTopicStats topic信息统计和监控
ControllerStats 中央控制器统计和监控
kafka源码分析(一)server启动分析的更多相关文章
- Netty源码—一、server启动(1)
Netty作为一个Java生态中的网络组件有着举足轻重的位置,各种开源中间件都使用Netty进行网络通信,比如Dubbo.RocketMQ.可以说Netty是对Java NIO的封装,比如ByteBu ...
- kafka源码分析之一server启动分析
0. 关键概念 关键概念 Concepts Function Topic 用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上. Partition 是Kafka中横向扩展和一 ...
- 一起读源码之zookeeper(1) -- 启动分析
从本文开始,不定期分析一个开源项目源代码,起篇从大名鼎鼎的zookeeper开始. 为什么是zk,因为用到zk的场景实在太多了,大部分耳熟能详的分布式系统都有zookeeper的影子,比如hbase, ...
- SpringBoot源码解析:tomcat启动分析
>> spring与tomcat的启动分析:war包形式 tomcat:xml加载规范 1.contex-param: 初始化参数 2.listener-class: contextloa ...
- Netty源码—二、server启动(2)
我们在使用Netty的时候的初始化代码一般如下 EventLoopGroup bossGroup = new NioEventLoopGroup(); EventLoopGroup workerGro ...
- 【源码】Redis Server启动过程
本文基于社区版Redis 4.0.8 1. 初始化参数配置 由函数initServerConfig()实现,具体操作就是给配置参数赋初始化值: //设置时区 setlocale(LC_CO ...
- Apache Kafka源码分析 – Broker Server
1. Kafka.scala 在Kafka的main入口中startup KafkaServerStartable, 而KafkaServerStartable这是对KafkaServer的封装 1: ...
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- Kafka源码分析(一) - 概述
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 实际问题 二. 什么是Kafka, 如何解决这些问题的 三. 基本原理 1. 基本 ...
- Kafka源码分析(二) - 生产者
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 使用方式 step 1: 设置必要参数 step 2: 创建KafkaProduc ...
随机推荐
- 【C#】WPF的xaml中定义的Trigger为什么有时候会不管用,如Border的MouseOver之类的
原文:[C#]WPF的xaml中定义的Trigger为什么有时候会不管用,如Border的MouseOver之类的 初学WPF,知道一些控件可以通过定义Style的Trigger改变要显示的样式,但是 ...
- wpf的webbrowser与javascript交互
JS调用C#代码 HTML代码: <button onclick="window.external.Test('called from script code')"> ...
- 使用tratto进行CISCO网络设备的管理
测试环境: CSR1000V CentOS7.4 X64 Step 1:在CentOS7上安装python 3.0环境 [root@docker ~]# python3 -VPython 3.7.0[ ...
- Win8 Metro(C#)数字图像处理--3.1图像均值计算
原文:Win8 Metro(C#)数字图像处理--3.1图像均值计算 /// <summary> /// Mean value computing. /// </summary> ...
- 了解 XML 数字签名
http://www.cnblogs.com/flyxing/articles/91734.html http://www.cnblogs.com/wuhong/archive/2010/12/20/ ...
- 程序定义了多个入口点。使用 /main (指定包含入口点的类型)进行编译
原文:请使用/main进行编译,以指定包含入口点类型 在使用VS工具初学C#的时候需要不停的写小程序,觉得每次都新建项目太过麻烦,所以试着把程序写在一个项目下面,结果编译的时候出错了,因为我每个小程序 ...
- C# 查农历 阴历 阳历 公历 节假日
原文:C# 查农历 阴历 阳历 公历 节假日 using System;using System.Collections.Generic;using System.Text; namespace ca ...
- Java8 的一些新特性总结
目前Java8已经发布很多个版本了,对于Java8中的新特性虽然有各位大神进行jdk8的英文特性文档翻译,但都太官方化语言,对照几篇翻译本人对新特性文档做一下总结,以帮助我和各位不了解Java8新特性 ...
- Linux目录结构及文件操作
Linux文件目录遵循FHS标准 绝对路径:从根目录开始的路径:相对目录:从当前路径开始的路径 .表示当前目录,..表示上级目录,~表示当前用户的home目录,pwd获得当前绝对路径 新建文件 tou ...
- git如何merge github forked repository里的代码更新
git如何merge github forked repository里的代码更新? 问题是这样的,github里有个项目ruby-gmail,我需要从fork自同一个项目的另一个repository ...