python科学计算库-pandas
------------恢复内容开始------------
1、基本概念
在数据分析工作中,Pandas 的使用频率是很高的, 一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 json 的契合度很高,转换起来就很方便。 另一方面,如果我们日常的数据清理工作不是很复杂的话,你通常用几句 Pandas 代码就可以对数据进行规整。
Pandas 可以说是基于 NumPy 构建的含有更高级数据结构和分析能力的工具包。 在NumPy 中数据结构是围绕 ndarray 展开的 Pandas 中的核心数据结构Series 和 DataFrame 这两个核心数据结构,他们分别代表着一维的序列和二维的表结构。
基于这两种数据结构,Pandas 可以对数据进行导入、清洗、处理、统计和输出。
pandas是python的第三方库,提供高性能易用数据类型和分析工具
import pandas as pd
pandas给予numpy实现,常与numpy和matplotlib一同使用
2、参考EXCEL使用python分析
像Excel一样使用python进行数据分析
3、Series,定义一维数组
Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray,这也
是和字典结构最大的不同。因为在字典的结构里,元素的个数是不固定的。
Series有两个基本属性:index 和 values。在 Series 结构中,index 默认是 0,1,2,……递
增的整数序列,当然我们也可以自己来指定索引, 比如 index=[‘a’, ‘b’, ‘c’,‘d’]。
Series定义
import pandas as pd x1 = pd.Series([1,2,3,4])
x2 = pd.Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print(x1)
print(x2)

"""ndarray数组创建,必须是一维数组"""
arr = np.arange(10,0,-1)
# arr = np.arange(10,0,-1).reshape(2,5)#error
# s5 = pd.Series(arr)
s5 = pd.Series(arr,index=np.arange(10,110,10))
s5
se8 = pd.Series([10,20,30,40,50],index=list('abcde'))
"""支持切片访问"""
print(se8['a':'d'])# 左闭右闭
print(se8[0:4]) #左闭右开
"""访问最后一个元素"""
print(se8['e'])
print(se8[-1])

运算:
se9 = pd.Series([10,20,30,40,50],index=list('abcde'))
se9
"""支持矢量化运算"""
print(se9+10)
print(se9*10)

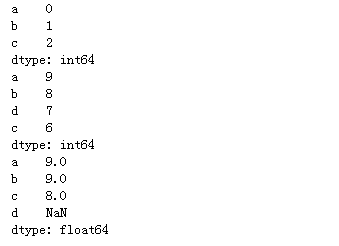
对齐
"""会根据索引进行对齐,对索引名相同的进行运算"""
se10 = pd.Series(range(0,3),index=list('abc'))
se11 = pd.Series(range(9,5,-1),index=list('abdc'))
print(se10)
print(se11)
print(se10+se11)
算术统计
s12 = pd.Series(range(0,5),index=list('abcde'))
s12

print("series的平均值:",s12.mean())
print("series的中位数:",s12.median())
print("series的和:",s12.sum())
print("series的最值:",s12.max(),s12.min())
print("series的元素个数:",s12.count())
print("series的标准差:%s,方差%s:",s12.std(),s12.var())

算术比较:
s13 = pd.Series(range(10,20))
s13
print(s13>15)
print()
print(s13[s13>15])
print(s13[(s13>12)&(s13<18)])
# np.isin(s13,[10,14,18])
print(s13[np.isin(s13,[10,14,18])])
"""本质上都是传入的bool值进行筛选"""
"""练习:拿10-13,18-20范围的数"""
print(s13[((s13>10)&(s13<13))|((s13>18)&(s13<20))])


数据的修改
s14 = pd.Series(range(0,5),index=list('abcde'))
s14
"""可以通过索引修改数据,索引存在则修改,不存在则创建"""
s14['c']=20
s14['f']=100
"""追加series"""
b = pd.Series([14,16],index=['g','h'])
s14.append(b)# 产生的是副本,元数据不变

"""数据的删除"""
# s14.drop('f')# 产生的时副本,元数据不变
s14.drop('f',inplace=True)# 直接对元数据进行修改
其他操作
"""数据类型的转换"""
s14.dtype
s14.astype(np.int8)# 产生副本
print(s14.dtype)
s14 = s14.astype(np.int8)
print(s14.dtype)# 真正改变
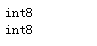
"""去重操作"""
s15 = pd.Series(['a','a','b','c','b','f','c'])
print(s15.unique())
"""元素次数统计"""
print(s15.value_counts())

"""排序"""
s16 = pd.Series([10,20,4,6,90,-1],index=list('acbfeg'))
# print(s16)print(s16.sort_values(ascending=False))# 对值进行排序
print(s16.sort_index())#对索引进行排序

"""判空"""
s17 = pd.Series([1,None,2,3,4,np.nan,5,pd.NaT])
s17
print(s17.isnull())
print(s17.notnull())
"""在计算和统计时会忽略缺失值"""
print(s17.sum())
print(s17.count())



二、DataFrame
DataFrame 类型数据结构类似数据库表。
DataFrame 一个二维表数据类型
"""二维ndarray数组创建"""
arr = np.arange(24).reshape(4,6)
df = pd.DataFrame(arr,index=['a','b','c','f'],columns=['A','B','C','D','E','F'])
"""index 行索引,columns 列索引"""
print(df)
"""也是自动索引和自定义索引并存"""

"""Series组成的字典来创建"""
s = pd.Series(np.arange(0,9),index=list('abcdefghi'))
s2 = pd.Series(np.arange(10,19),index=list('abcdefghi'))
df2 = pd.DataFrame({'S':s,'S1':s2,'S2':s+s2})
df2
#dataframe 就是个多列的series
# """练习:再增加一列,值是s,s2的和"""

"""通过等长的列表或数组组成的字典来创建"""
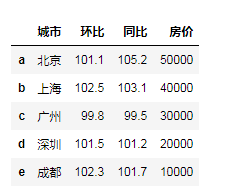
city = {'城市':['北京','上海','广州','深圳','成都'],
'环比':[101.1,102.5,99.8,101.5,102.3],
'同比':[105.2,103.1,99.5,101.2,101.7],
'房价':[50000,40000,30000,20000,10000]}
df3 = pd.DataFrame(city)# 生成了自动的行索引
df3 = pd.DataFrame(city,index=list('abcde'))
df3
"""观察属性"""
print('index',df3.index)
print('columns',df3.columns)
print('values',df3.values)# 返回的时ndarray数组
df3.values

"""转置"""
# df3.T
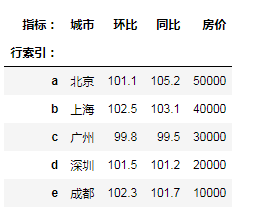
"""给索引添加名称属性"""
df3.index.name='行索引'
df3.columns.name='指标'
df3
查询数据(重点)
"""通过列索引选取数据"""
df3['城市'] # 返回的是Series
"""选取多列,传入列表"""
df3[['城市','房价']]# 返回的是dataframe
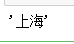
"""定位具体的值"""
df3['城市']['b']
1.loc意义:通过行标签索引行数据
例: loc[n]表示索引的是第n行(index 是整数) loc[‘d’]表示索引的是第’d’行(index 是字符) 2.iloc :通过行号(数字)获取行数据,不能是字符 3. ix——结合前两种的混合索引 三者区别: ix / loc 可以通过行号和行标签进行索引,比如 df.loc['a'] , df.loc[1], df.ix['a'] , df.ix[1] 而iloc只能通过行号索引 , df.iloc[0] 是对的, 而df.iloc['a'] 是错误的
"""通过行索引选取数据,loc[]"""
"""df.loc[行索引,列索引]"""
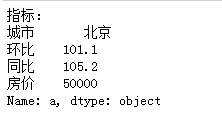
print(df3.loc['a'])
print(df3.loc[['a','b']])

print(df3.loc['a','城市'])

print(df3.loc[['a','b'],['城市','房价']])

print(df3.loc['a':'d','城市':'房价'])# 左闭右闭
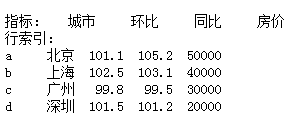
print(df3.loc['a':'d']['城市'])

"""练习:选取上海,广州,成都的房价,同比"""
df3.loc[['b','c','e'],['同比','房价']]

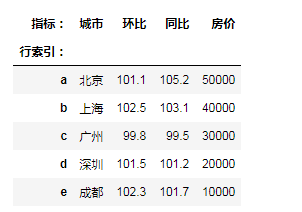
"""df.iloc[] 通过自动索引进行数据选取,只能传入自动索引的值"""
"""df.iloc[行索引,列索引]"""
print(df3.iloc[2,3])# 第三行第四列
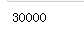
print(df3.iloc[1:3,0:3])# 左闭右开-二到三行;一到三列

print(df3.iloc[2:4,-1])

"""通过bool值进行选取,将True对应的数据返回"""
df3.loc[[True,True,False,False,True],[True,False,False,True]]
"""通过比较运算符产生bool值列表"""
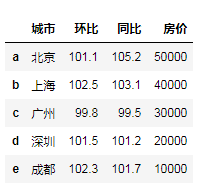
df3['房价']>30000
df3.loc[df3['房价']>30000]# 等价 df3.loc[df3['房价']>30000,:]
df3.loc[df3['房价']>30000,'城市']
df3.loc[df3['房价']>30000]['城市']
"""练习:获取同比小于102 环比大于102的数据"""
df3.loc[(df3['同比']<102)&(df3['环比']>102)]
"""练习:获取同比小于102 或 环比大于102的数据"""
df3.loc[(df3['同比']<102)|(df3['环比']>102)]
""" ~ 取反操作"""
df3.loc[~(df3['同比']<102)]
3、添加或修改数据
city = {'城市':['北京','上海','广州','深圳','成都'],
'环比':[101.1,102.5,99.8,101.5,102.3],
'同比':[105.2,103.1,99.5,101.2,101.7],
'房价':[50000,40000,30000,20000,10000]}
df4 = pd.DataFrame(city,index=list('abcde'))
df4
"""通过直接赋值进行修改或添加,索引存在则修改,不存在就创建"""
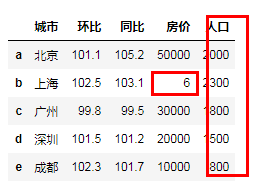
df4['人口']=[2000,2300,1800,1500,800]
# df4['房价']=[5,4,3,2,1]
# df4.loc['f']=['杭州',1032,101,1,800]# 元素的个数要匹配
"""修改指定位置的数据"""
df4.loc['b','房价']=6
4、索引的操作
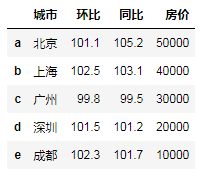
city = {'城市':['北京','上海','广州','深圳','成都'],
'环比':[101.1,102.5,99.8,101.5,102.3],
'同比':[105.2,103.1,99.5,101.2,101.7],
'房价':[50000,40000,30000,20000,10000]}
df = pd.DataFrame(city,index=list('abcde'))
df
"""reindex() 重新索引,通过指定索引列表,对其进行筛选和排序"""
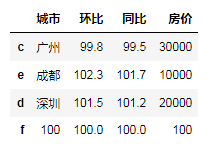
df.reindex(index=['c','e','d'])
df.reindex(columns=['城市','房价','同比'])
df.reindex(index=['c','e','d'],columns=['城市','房价','同比'])
"""当传入不存在的索引时,会被创建,但是以NaN默认填充"""
df.reindex(index=['c','e','d','f'])
df.reindex(index=['c','e','d','f'],fill_value=100)
"""索引对象可以整体修改,但不能局部修改"""
df.index
# df.index[0]='A' # error
df.index=['a1','b1','c1','d1','e1']
df.index.insert(3,'sds') #再具体位置插入值
df.index.delete(3)
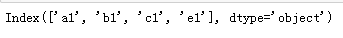
"""练习:将上面的索引改为 A_1,B_2,C_3...."""
# df.index=['A_1','B_1',.....]
# rs = []
# for i in df.index:
# # print(type(i))
# rs.append(i[0].upper()+"_"+i[-1])
# # print(i[0].upper()+"_"+i[-1])
# df.index=rs """二"""
#df.index=['a1','b1','c1','d1','e1']
df.index = df.index.map(lambda x:"%s_%s"%(x[0].upper(),x[-1]))
print(df.index[0])
"""索引的重置"""
"""set_index() 指定列作为行索引"""
# df.set_index('城市')
# df.set_index('城市',inplace=True)
"""reset_index(),会重新产生一个数据列(默认自动索引的形式)作为索引"""
df.reset_index(inplace=True)
5、排序及删除
city = {'城市':['北京','上海','广州','深圳','成都'],
'环比':[101.1,102.5,99.8,101.5,102.3],
'同比':[105.2,103.1,99.5,101.2,101.7],
'房价':[50000,40000,30000,20000,10000]}
df = pd.DataFrame(city,index=list('abcde'))
df
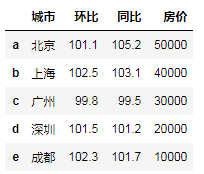
"""默认对行索引进行排序"""
# df.sort_index(ascending=False)# 默认升序
"""对列索引进行排序 axis=1"""
df.columns=[0,3,5,4]
# df
df.sort_index(axis=1)
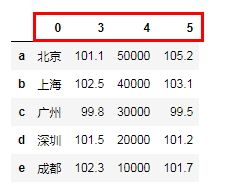
"""对值进行排序 # 默认升序"""
city = {'城市':['北京','上海','广州','深圳','成都'],
'环比':[101.1,102.5,99.8,101.5,102.3],
'同比':[105.2,103.1,99.5,101.2,101.7],
'房价':[50000,40000,30000,20000,10000]}
df = pd.DataFrame(city,index=list('abcde'))
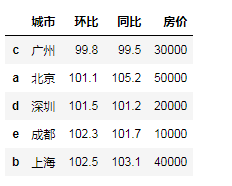
df.sort_values(by='同比') # by 指定列
df.sort_values(by=['环比','同比'])
d = pd.DataFrame({'A':[1,1,2,2],'B':[3,2,1,4],'C':[4,2,3,1]})
d
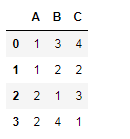
d.sort_values(by=['A','B'])# 先对A进行排序,然后再对B排序
# 对A升序,对B降序
d.sort_values(by=['A','B'],ascending=[True,False])# 可以对每个列指定排序方式
删除数据
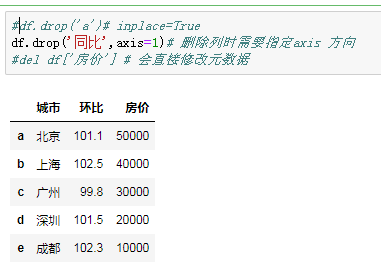
df.drop('a')# inplace=True
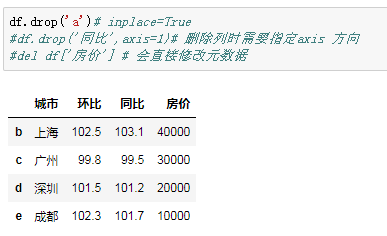
df.drop('同比',axis=1)# 删除列时需要指定axis 方向
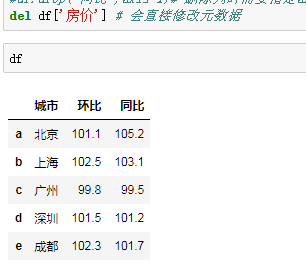
del df['房价'] # 会直接修改元数据
三、Pandas文件操作
import numpy as np
import pandas as pd #读取csv
data = pd.read_csv('student.csv')
读取excel
import pandas as pd
data = pd.read_excel('病历数据.xlsx','Sheet2')
print(data)
默认读取Sheet1表的数据,可以指定读取具体表
"""读取文本文件"""
f = open('./classfilba/城市房屋建设.csv',encoding='utf-8')
data = pd.read_csv(f,sep=',',header=0)
"""f:文件操作符,sep csv文件的数据分隔符,header=0 选取第0行作为表头/列标签"""
f.close()
"""读取出来的数据直接构造成了dataframe""" """也可以直接用read_csv()读取"""
# data2 = pd.read_csv(R'C:\Users\lx\Desktop\classfilba\城市房屋建设.csv',sep=',',header=0,encoding='utf-8') #data2 = pd.read_csv('./classfilba/城市房屋建设.csv',sep=',',header=0,encoding='utf-8')
data2 = pd.read_csv('./classfilba/城市房屋建设.csv')
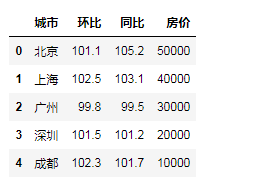
"观察数据,预览信息
描述性统计
"""观察数据,预览信息"""
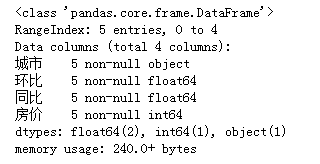
data2.info()
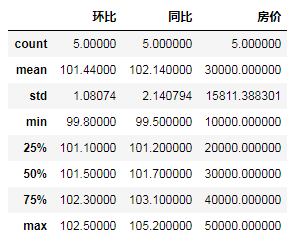
"""描述性统计"""
#data2.describe()
读取excel
"""读取excel数据"""
path = './classfilba/陕西全通账号开通申请车辆明细.xlsx'
df = pd.read_excel(path,header=0)
df.head() # 打印前5条进行预览
# df.head(10) # 指定10条
df.tail() # 打印后5条

"""读取指定的工作簿,可以通过sheet_name指定下标或者工作簿名称"""
"""读取指定的工作簿,可以通过sheet_name指定下标或者工作簿名称"""
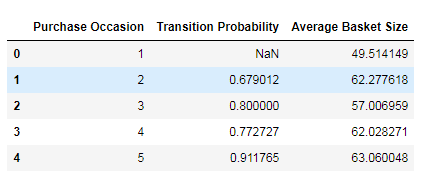
path = './classfilba/chapter-12-relay-foods.xlsx'
df = pd.read_excel(path,sheet_name=4,header=6)# 指定序号为4的工作簿,用第6行做为行索引
"""sheet_name,工作簿的序号从0开始 """
#header从0开始计数
# df = pd.read_excel(path,sheet_name='Pilot Transition Probabilities',header=6)
df.head()


"""从数据库中读取数据"""
"""从数据库中读取数据"""
import pymysql
conn = pymysql.connect(host='localhost',port=3306,user='root',password='',db='db1')
sql = 'select * from student'
"""con参数 传入数据库连接对象""" phone = pd.read_sql(sql,con=conn)
conn.close()
"""保存数据"""
"""csv"""
#phone.to_csv('./save_data/phone.csv',encoding='utf-8-sig',index=False)
phone.to_csv('./save_data/phone.csv')
# utf-8-sig, 针对表格形式数据的一种utf-8 编码方式
# index=False 不把索引写入文件 """将多个表格存入同一个excel文件的不同工作簿"""
writer = pd.ExcelWriter(R'C:\Users\lx\Desktop\classfilba\phone_info_zol.xlsx')
phone.to_excel(writer,'phone_info',index=False)
data.to_excel(writer,'city_home_info',index=False)
df.to_excel(writer,'salor_info',index=False)
writer.save()# 保存
pandas应用-字符串操作
import pandas as pd
import numpy as np
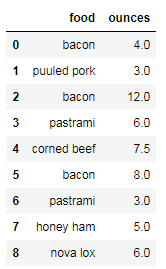
data = pd.DataFrame({'food':
['bacon','puuled pork','bacon','pastrami','corned beef',
'bacon','pastrami','honey ham','nova lox'],
'ounces':[4,3,12,6,7.5,8,3,5,6]})
data
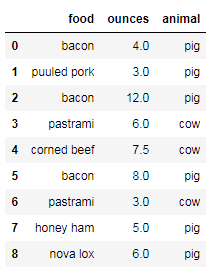
"""给食物添加来源"""
meat_to_animal={'bacon':'pig','puuled pork':'pig','pastrami':'cow','corned beef':'cow','honey ham':'pig','nova lox':'pig'}
data['animal']=data['food'].map(meat_to_animal)
data
"""replace 传入指定值,进行替换"""
data['ounces'].replace([4,8],12,inplace=True) # 第一个参数 要修改的值得列表,第二个参数,最终替换的目标值
# data.loc[(data['ounces']=='4')|(data['ounces']=='8'),'ounces']=12
# data.loc[data['food']=='bacon','ounces']=12
"""str属性,可以对字符串进行操作"""
"""# 将其首字符替换"""
data['food'].str.replace('^\w','A')
"""将其首字符改为大写"""
data['food'].str.capitalize()
data['food'].str.findall('^\w')# 返回的数据是列表
data['food'].str.split('\s')
data['food'].str.extract('(^\w)')# 返回的数据是dataframe
数据表的拼接concat()
"""concat() 可以实现数据在行或列方向上的拼接"""
se1 = pd.Series(["A",'B','C'],index=[1,2,3])
se2 = pd.Series(["D","E",'F'],index=[4,5,6])
# print(se1,se2)print(pd.concat([se1,se2]))# 默认是在纵向上进行拼接
print(pd.concat([se1,se2],axis=1))

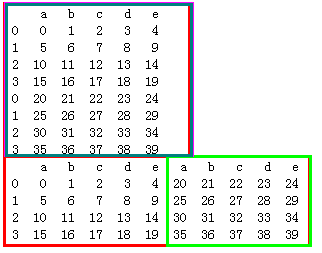
df1 = pd.DataFrame(np.arange(20).reshape(4,5),columns=list('abcde'))
df2 = pd.DataFrame(np.arange(20,40).reshape(4,5),columns=list('abcde'))
print(df1)
print(df2)

# df1,df2行索引相同
print(pd.concat([df1,df2]))# 默认是在纵向上进行拼接
print(pd.concat([df1,df2],axis=1))
当行索引不相同时
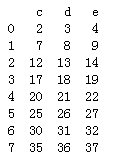
df3 = pd.DataFrame(np.arange(20).reshape(4,5),columns=list('abcde'))
df4 = pd.DataFrame(np.arange(20,40).reshape(4,5),columns=list('cdefg'))
print(df3)
print(df4)

# print(pd.concat([df3,df4],sort=False))
# print(pd.concat([df3,df4],sort=False,axis=1))
"当索引名有重叠时,可以传入join=inner获得交集,ignore_index=True,放弃原来的索引 """
print(pd.concat([df3,df4],sort=False,join='inner',ignore_index=True))
Pandas 合并 merge
"""merge() 数据库风格的连接,可以指定连接键"""
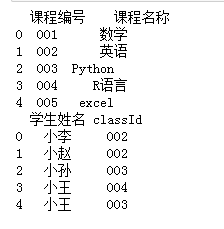
df1=pd.DataFrame({'课程编号':['','','','',''],
'课程名称':['数学','英语','Python','R语言','excel']})
df2=pd.DataFrame({'学生姓名':['小李','小赵','小孙','小王','小王'],
'classId':['','','','','']})
print(df1)
print(df2)
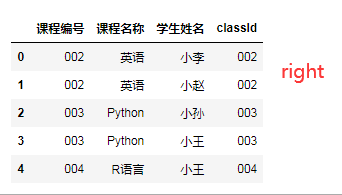
pd.merge(df1,df2,how='inner',left_on='课程编号',right_on='classId')# 内连接
pd.merge(df1,df2,how='left',left_on='课程编号',right_on='classId')# 左连接,以左表为主,显示左表的所有字段
pd.merge(df1,df2,how='right',left_on='课程编号',right_on='classId')# 右连接,以右表为主,显示右表的所有字段
"""去重"""
"""去重"""
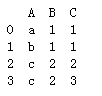
data = pd.DataFrame({'A':['a','b','c','c','c','a'],'B':[1,1,2,2,2,1],'C':[1,1,2,3,2,1]})
print(data)
"""对所有列进行重复判断,然后进行去重"""
data.drop_duplicates()
print()
print(data.drop_duplicates(keep='first')) # 从前往后找,删除后面出现的重复数据
print()
print(data.drop_duplicates(keep='last')) # 从后往前找,删除前面出现的重复数据


"""可以指定列进行去重"""
print(data.drop_duplicates(subset=['A','B']))
print()
print(data.drop_duplicates(subset=['A','B'],keep='last'))


"""处理缺失值"""
"""处理缺失值"""
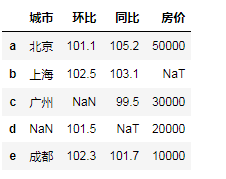
city = {'城市':['北京','上海','广州',np.nan,'成都'],
'环比':[101.1,102.5,np.nan,101.5,102.3],
'同比':[105.2,103.1,99.5,pd.NaT,101.7],
'房价':[50000,pd.NaT,30000,20000,10000]}
df = pd.DataFrame(city,index=list('abcde'))
df
"""整体观察"""
df.info()
"""如果缺失的数据很少,可以直接进行删除"""
"""如果缺失的数据量较大,超过了10%,要根据业务情况,进行删除或填充"""
"""填充数据时,可以采用均值,中位数进行填充"""
"""如果数据记录之间有明显的顺序关系,可以采用附近相邻的数据进行填充"""

"""删除缺失值"""
df.dropna()# 删除出现缺失值得行
# df.dropna(axis=1)
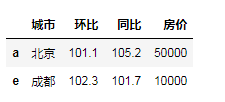
#增加f行全为空
df.loc['f']=np.nan
df
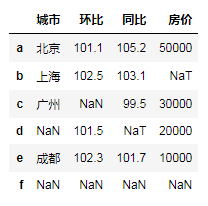
df.dropna(how='all') # 当整行数据都为nan 时才删除
df.dropna(how='any') # 只要出现缺失值就删除
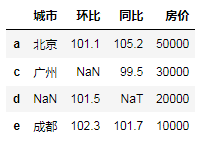
df.dropna(subset=['房价'])# 指定列出现缺失值才删除
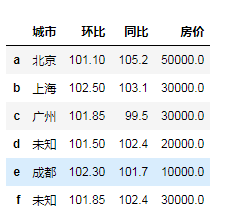
"""填充缺失值"""

"""填充缺失值"""
df.fillna(100)
# 缺失值前一个数字进行填充
df.fillna(method='bfill')# 向下取值进行填充
df.fillna(method='ffill')# 向上取值进行填充 df.fillna({'环比':df['环比'].mean(),
'房价':(df['房价'].max()+df['房价'].min())/2,
'同比':df['同比'].median(),
'城市':'未知'})
"""group by 分组 应用 聚合"""
df = pd.DataFrame({'key':list('ABCABC'),'values':range(6)})
"""分别求key=ABC时,各自的和"""

sql = 'select key,sum(*)from table group by key'
"""先对数据进行分组,然后对每一组进行聚合操作"""
"""聚合操作时调用聚合函数(将多组值转化为一个值输出)"""
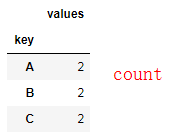
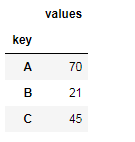
df.groupby('key').sum()
df.groupby('key').mean()
df.groupby('key').count()
"""实现自定义的聚合函数"""
"""实现自定义的聚合函数"""
df = pd.DataFrame({'key':list('ABCABCABC'),'values':range(9)})
print(df)
def mysum(data):# data 分组后的小组数据集
# print(data)
return data['values'].sum()
"""apply() 应用自定义聚合函数"""
df.groupby('key').apply(mysum)


"""练习:求上面分组中,最大值和最小值的差,自定义聚合函数来实现"""
def f(data):# 分组的数据集,dataframe
# print(data)
arr = data['values']
# print(arr)
ret = arr.max()-arr.min()
# return ret # 返回单个值时,聚合结果为Series
return pd.Series(ret,index=['values']) # 返回Series时,聚合结果为Dataframe
df.groupby('key').apply(f)

"""练习:求上面分组中,最大值和第二大值的差,自定义聚合函数来实现"""
def f2(data):
# 先对值进行排序
arr=data['values'].sort_values()
# print(arr.iloc[-1],arr.iloc[-2])
return pd.Series(arr.iloc[-1]-arr.iloc[-2],index=['values'])
df.groupby('key').apply(f2)
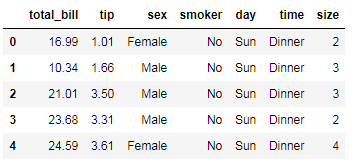
"""多字段分组"""
tips = pd.read_csv('tips.csv',sep=',',header=0)
# tips.info()
tips.head()
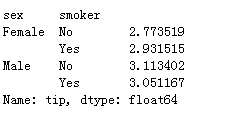
"""分别统计不同性别和是否吸烟者的人数"""
# 括号里面是分组字段,外面是你想要展示的统计结果列
tips.groupby(['sex','smoker'])['sex'].count()

tips.groupby(['sex','smoker'])['tip'].mean()
对消费数据数据集根据性别和是否吸烟,分别求消费占比的前5名
tips = pd.read_csv('tips.csv',sep=',',header=0)
# tips.info()
print(tips.head())
# 消费占比
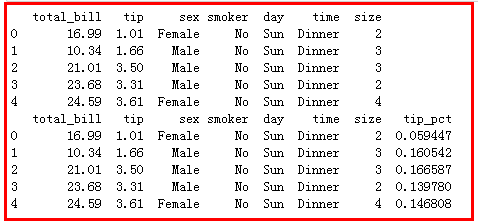
tips['tip_pct']=tips['tip']/tips['total_bill']
print(tips.head())
"""分别统计不同性别和是否吸烟者的人数"""
def opt(data):
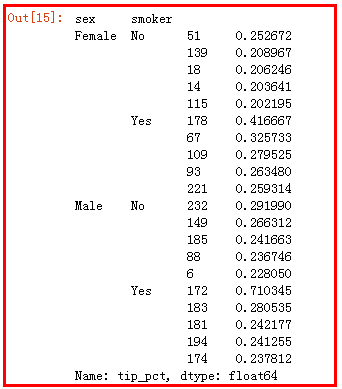
return data['tip_pct'].sort_values(ascending=False)[:5]
tips.groupby(['sex','smoker']).apply(opt)
"""透视表"""
"""透视表"""
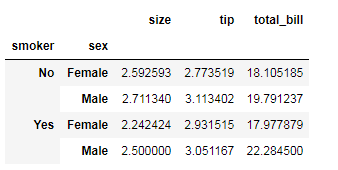
tips.groupby(['smoker','sex']).mean()
# .pivot_table 透视表
tips.pivot_table(index=['smoker','sex'])
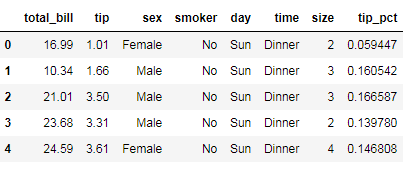
"""统计不同性别,在不同的工作日,是否吸烟,消费占比和用餐人数"""
tips['tip_pct']=tips['tip']/tips['total_bill']
tips.head()
"""统计 不同性别,在不同的工作日,是否吸烟,的消费占比和用餐人数"""
tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns='smoker')#默认聚合函数是求平均
tips.pivot_table(['tip_pct','size'],index=['sex','day'],columns='smoker',aggfunc=np.sum)# 指定聚合函数
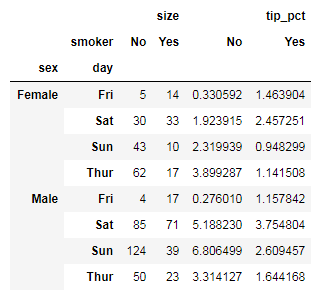
tips.pivot_table(['tip_pct'],index=['sex','smoker','time'],columns='day',fill_value=0)# 填充缺失值
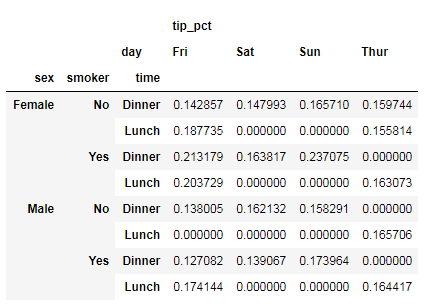
"""pivot_table(统计列,index行分组字段,columns 列分组字段,fill_value填充缺失值,aggfunc 指定聚合方法)"""
"""数据切分"""
ages = [20,30,40,18,17,15,12,16,23,34,35,39,38,48,43,25,60,120]
"""bins 自定义的划分区间"""
bins = [0,18,28,36,45,60,100,1000]
labels = ['未成年','青年','大青年','中年','中老年','老年','寿星(大于100岁)']
ret = pd.cut(ages,bins,labels=labels)
"""将数据集和标签列表对应起来,一起显示"""
ret = dict(zip(ages,ret))
ret

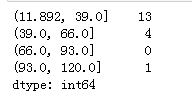
a = pd.cut(ages,4)# 排序后,均匀分成四组
print(a.value_counts())
label = ['青年','中年','老年','寿星']
d = pd.cut(ages,4,labels=label,right=False)# 排序后,均匀分成四组,right=False,改变区间的包含方式
d.value_counts()

例题:

数据清洗
# 清洗数据
import pandas as pd
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98,90,89,92]} df2 = pd.DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'])
print(df2)
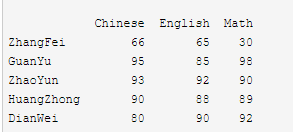
# 1. 删除 DataFrame 中的不必要的列或行
# 1. 删除 DataFrame 中的不必要的列或行
df2=df2.drop(columns='Chinese')
print(df2) df2=df2.drop(index='ZhangFei')
print(df2) Chinese English Math
ZhangFei 66 65 30
GuanYu 95 85 98
ZhaoYun 93 92 90
HuangZhong 90 88 89
DianWei 80 90 92
English Math
ZhangFei 65 30
GuanYu 85 98
ZhaoYun 92 90
HuangZhong 88 89
DianWei 90 92
English Math
GuanYu 85 98
ZhaoYun 92 90
HuangZhong 88 89
DianWei 90 92
2. 重命名列名 columns,让列表名更容易识别
df2.rename(columns={'English': '英语'}, inplace = True)
df2.rename(index={'ZhangFei': '张飞'}, inplace = True)
print(df2)
Chinese 英语 Math
张飞 66 65 30
GuanYu 95 85 98
ZhaoYun 93 92 90
HuangZhong 90 88 89
DianWei 80 90 92
3. 去重复的值
数据采集可能存在重复的行,这时只要使用 drop_duplicates() 就会自动把重复的行去掉。
date = {'a':[1,1,3,1],'b':[1,1,2,2]}
df2 = pd.DataFrame(date,index={'zhang','lili','zhao','liu'})
print(df2)
a b
liu 1 1
lili 1 1
zhang 3 2
zhao 1 2
DataFrame的duplicated方法返回一个布尔型Series,表示各行是否重复行。
print(df2.duplicated())
liu False
lili True
zhang False
zhao False
dtype: bool
而 drop_duplicates方法,它用于返回一个移除了重复行的DataFrame
同一行,相同才删除
#print(df2.drop_duplicates())
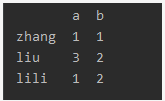
例如,希望对名字为‘a’的列进行去重,
print(df2.drop_duplicates('a'))

4. 格式问题
更改数据格式
因为很多时候数据格式不规范,我们可以使用 astype 函数来规
范数据格式,比如我们把 Chinese 字段的值改成 str 类型,或者 int64 可以这么写: date = {'a':[1,1,3,1],'b':[1,1,2,2]}
df2 = pd.DataFrame(date,index={'zhang','lili','zhao','liu'},dtype=float)
print(df2)
print(df2.dtypes) df2['a']=df2['a'].astype('int32')
print(df2.dtypes)
数据间的空格
有时候我们先把格式转成了 str 类型,是为了方便对数据进行操作,这时想要删除数据间
的空格,我们就可以使用 strip 函数: strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
不能删除中间的字符 # 删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
# 删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
# 删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
大小写转换
from pandas import Series, DataFrame
data = {'Chinese': [66]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei'])
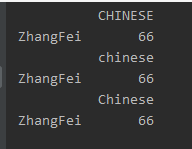
df2.columns = df2.columns.str.upper()
print(df2)
# 全部小写
df2.columns = df2.columns.str.lower()
print(df2)
# 首字母大写
df2.columns = df2.columns.str.title()
print(df2)
# 查找空值
数据量大的情况下,有些字段存在空值 NaN 的可能,这时就需要使用 Pandas 中的 isnull
函数进行查找。比如,我们输入一个数据表如下:
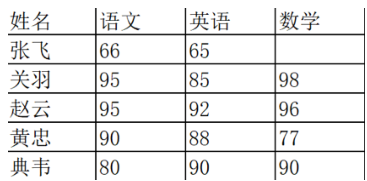
df.isnull()
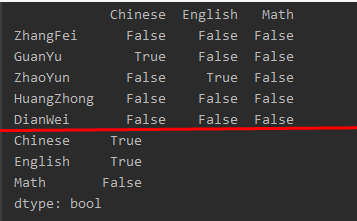
data = {'Chinese': [66,None, 93, 90,80],'English': [65, 85,None, 88, 90],'Math': [30, 98,90,89,92]}
df2 = pd.DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'])
print(df2.isnull())
print(df2.isnull().any())
使用 apply 函数对数据进行清洗
apply函数是`pandas`里面所有函数中自由度最高的函数。该函数如下:
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds) 该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。 这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据
结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数
会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
比如我们想对 Chinese列的数值都进行大写转化可以用:
import pandas as pd
data = {'Chinese': ['che']}
df1= pd.DataFrame(data)
df2 = pd.DataFrame(data, index=['ZhangFei']) df2['Chinese']=df2['Chinese'].apply(str.upper)
print(df2)
使用自定义函数
import pandas as pd
data = {'Chinese': [20],'Math':[46]} df2 = pd.DataFrame(data, index=['ZhangFei','zhao'],dtype=int) print(df2)
#
def fun(x):
return 2*x
# 对列值进行乘2处理
df2['Chinese']=df2['Chinese'].apply(fun)
print(df2) # 新增一列:
def fu(df2,n): df2['new']=(df2['Chinese']+df2['Math'])*n
return df2 df2 = df2.apply(fu,axis=1,args=(2,))
print(df2)
数据统计
Pandas 和 NumPy 一样,都有常用的统计函数,如果遇到空值 NaN,会自动排除。

两个 DataFrame 数据表的合并使用的是 merge() 函数,有下面 5 种形式
import pandas as pd
df1 = pd.DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = pd.DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
# 基于 name 这列进行连接
print(pd.merge(df1,df2,on='name'))
print()
# inner连接
print(pd.merge(df1,df2,how='inner'))
# left连接 左连接是以第一个 DataFrame 为主进行的连接
print()
print(pd.merge(df1,df2,how='left'))
#right 右连接是以第二个 DataFrame 为主进行的连接
print()
print(pd.merge(df1,df2,how='right'))
# 外连接 外连接相当于求两个 DataFrame 的并集
print()
print(pd.merge(df1,df2,how='outer')) name data1 data2
0 ZhangFei 0 0
1 GuanYu 1 1 name data1 data2
0 ZhangFei 0 0
1 GuanYu 1 1 name data1 data2
0 ZhangFei 0 0.0
1 GuanYu 1 1.0
2 a 2 NaN
3 b 3 NaN
4 c 4 NaN name data1 data2
0 ZhangFei 0.0 0
1 GuanYu 1.0 1
2 A NaN 2
3 B NaN 3
4 C NaN 4 name data1 data2
0 ZhangFei 0.0 0.0
1 GuanYu 1.0 1.0
2 a 2.0 NaN
3 b 3.0 NaN
4 c 4.0 NaN
5 A NaN 2.0
6 B NaN 3.0
7 C NaN 4.0
python科学计算库-pandas的更多相关文章
- Python科学计算库
Python科学计算库 一.numpy库和matplotlib库的学习 (1)numpy库介绍:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成 ...
- Python科学计算库Numpy
Python科学计算库Numpy NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库. 1.简 ...
- Python科学计算之Pandas
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1474979163&ver=1&signature=wnZn1UtW ...
- (转)Python科学计算之Pandas详解,pythonpandas
https://www.cnblogs.com/linux-wangkun/p/5903380.html-------pandas 学习(1): pandas 数据结构之Series https:// ...
- python科学计算库的numpy基础知识,完美抽象多维数组(原创)
#导入科学计算库 #起别名避免重名 import numpy as np #小技巧:从外往内看==从左往右看 从内往外看==从右往左看 #打印版本号 print(np.version.version) ...
- python科学计算库numpy和绘图库PIL的结合,素描图片(原创)
# 导入绘图库 from PIL import Image #导入科学计算库 import numpy as np #封装一个图像处理工具类 class TestNumpy(object): def ...
- Python科学计算库演示
号码值计算基础 NumPy至Python提供了高速的多维数组处理的能力.而SciPy则在NumPy基础上加入了众多的科学计算所需的各种工具包,有了这两个库,Python就有差点儿和Matlab一样的处 ...
- [Python学习] python 科学计算库NumPy—矩阵运算
NumPy库的核心是矩阵及其运算. 使用array()函数可以将python的array_like数据转变成数组形式,使用matrix()函数转变成矩阵形式. 基于习惯,在实际使用中较常用array而 ...
- Python科学计算库-Numpy
NumPy 是 Python 语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,也是学习 python 必学的一个库. 1. 读取文件 numpy.gen ...
随机推荐
- 移动端px自动转化为rem
注:不转换的px用大写PX代替 lib-flexible 作用:让网页根据设备dpr和宽度,利用viewport和html根元素的font-size配合rem来适配不同尺寸的移动端设备 安装:cnpm ...
- Java并发编程:Java中的锁和线程同步机制
锁的基础知识 锁的类型 锁从宏观上分类,只分为两种:悲观锁与乐观锁. 乐观锁 乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新 ...
- DirectShow 常用函数总结
本文准备总结一些 Direct Show 常用的API接口函数,方便以后查询回忆.如果这里没有你想了解的函数,你可以自行搜索MSDN + 函数名去 MSDN 查找你想要了解的函数,也可以查看百度百科相 ...
- openpyxl常用API
worksheet.cell(self, row, column, value=None)描述:给指定位置的单元格赋值参数: row&column:必须参数,单元格的坐标 value:可选参数 ...
- 07-Django模板(1)
模板介绍 作为web框架,Django提供了模板,用于编写html代码(嵌入模板代码,更快更方便的完成页面开发,在通过视图中渲染模板,将最终生成的页面返回给浏览器(客户端)).模板是关于外表的渲染的, ...
- [debug] 解决在C++编写过程中的“找到一个或多个多重定义的符号”
如下图: 其在 common.h 中定义了一个变量a ,然后在两个 cpp 文件中都是用它. 在这种情况下,链接时就会出现 “找到一个或多个多重定义的符号”. 解决方案: 在某个cpp文件中定义,然后 ...
- WCF全双工通信实例分享(wsDualHttpBinding、netTcpBinding两种实现方式)
最近在研究WCF通信,如果没有接触过的可以看我的前一篇文章:https://www.cnblogs.com/xiaomengshan/p/11159266.html 主要讲的最基础的basicHttp ...
- idea的service注入mapper报错
一.问题 idea的java项目中,service类中注入mapper报错 二.解决 方法1 在mapper类上加上 @Repository 注解即可,当然不加也行,程序也不回报错,是idea的误报 ...
- 敏捷软件开发_UML<一>
敏捷软件开发_UML 所看书籍是:敏捷软件开发_原则.模式与实践_C#版(美)马丁著,这本书写的非常棒,感谢作者.该归纳总结的过程按照我读的顺序写. UML 在建造桥梁,零件,自动化设备之前需要建 ...
- 「SAP技术」SAP 如何看序列号被包在哪些HU里?
「SAP技术」SAP 如何看序列号被包在哪些HU里? 事务代码SE16 ,表名OBJK, 输入物料号,序列号,HeadTable 输入值SER06, 查询结果如下, 根据objlist, 去表ser0 ...