Paper | Model-blind video denoising via frame-to-frame training
发表在2019年CVPR。
核心内容:基于Noise2Noise思想,这篇文章致力于无监督的视频盲去噪:是的,连噪声样本都不需要了。
这篇文章写作和概括太棒了!它的Introduction非常值得回味!它对去噪相关工作的概述、对本文启发工作的简述、对本文工作的概述都非常流畅。
故事
我们拥有的“干净”图像,往往不是干净的。理想的干净图像是从成像传感器上获取的,然而我们看到的图像还经过了相机内部的处理流程。该过程包含量化、去马赛克、伽马校正、压缩等。
因此,如果要对视频去噪,最好能知道有噪视频的生成过程,即所谓的model of processing chain。
然而,该model通常是未知且难以建模的,并且这些噪声通常是与信号相关的(signal-dependent)。
为此,本文作者提出了model-blind的逐帧去噪方法。
为了达到较好的无监督学习性能,该网络是从预训练的DnCNN上fine-tune的。
作者还提出了两种训练模式:on-line和off-line。在on-line模型下,该网络会根据输入视频的前几帧进行fine-tune;在off-line模式下,则可以用一批视频进行训练,效果更好。
本文受到了Noise2Noise思想和one-shot object video segmentation训练方法的启发。在one-shot中,作者借助一个预训练的分割网络,在第一帧中标注目标并fine-tune,以完成视频其余帧的分割任务;在Noise2Noise中,训练目标是最小化 同一张图像的两个有噪版本 之间的差异。本文类似于one-shot的去噪版本,且无需任何干净图像:将视频的相邻帧作为训练目标。
引述本文的一句话:
In this work we show that, for certain kinds of noise, in the context of video denoising one video is enough: a network can be trained from a single noisy video by considering the video itself as a dataset.
本文方法
流程
刚刚说了,我们需要从一个预训练的去噪网络出发。这是因为我们的训练集很小(线上模式只有该视频的几帧)。这也是借鉴one-shot的。
此外,我们假设视频中的相邻帧是同一自然图像的两种有噪分布。但它们仍然存在微小的运动误差。为此,我们采用TV-L1光流[46,37]。该运动补偿方法非常快。补偿后采用双线性插值。显然这里有两点假设:
相邻帧的噪声分布独立;
运动补偿后的帧 与 参考帧 的 潜在干净图像 是一致的。
还有,我们还考虑了遮挡,建立了一个遮挡膜(occlusion mask)。我们采用了[4]的简单方法:当光流散度较大时,我们就认为出现了遮挡情况,该点遮挡膜值为1,否则为0。
最后,我们计算损失时,出现遮挡的就不计入计算。即损失等于原损失乘以遮挡膜。
作者采用的是\(L_1\)损失。首先声明,选择损失函数要根据噪声的特性。但在噪声属性未知或复杂的情况下,最直接的办法就是:逐个实验,选其最佳。作者选择\(L_1\),是因为其表现比\(L_2\)更好[50],并且能处理包含泊松、JPEG压缩、低频等噪声。
训练
在线下训练时,我们会对整个视频进行迭代。训练目标是\(L_1\)损失,迭代若干次。
在线上训练时,我们逐帧训练。随着视频播放,迭代帧数会越来越多。这有点契合了life-long learning[47]的思想。
注意,我们还可以换反方向进行运动补偿,从而获得了双倍的训练数据用于迭代。
实验
实验采用的预训练网络,是在标准差25的AWGN下训练的DnCNN。
本文可能是第一篇视频盲去噪工作。因此,作者与Noise clinic、VBM3D和DnCNN进行了对比。
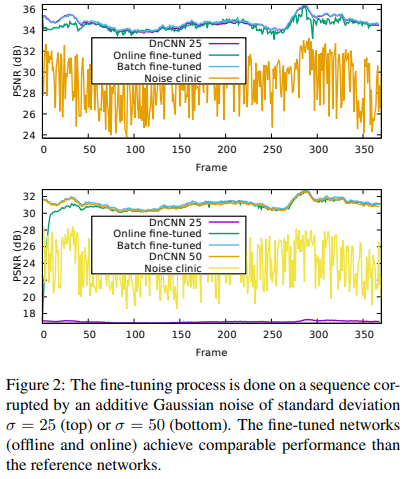
如图,首先探究的是在标准差为25的AWGN下的表现。此时DnCNN表现正常,本文方法无论何种模式,都与DnCNN不相上下。
其次,我们探究在标准差为50的AWGN下的表现。此时,DnCNN表现辣眼睛,而本文方法通过fine-tune逐渐地趋于优秀。
此外,我们还探究了其他噪声:混合高斯、相关、椒盐、JPEG噪声等。效果如图,盲去噪真香!:
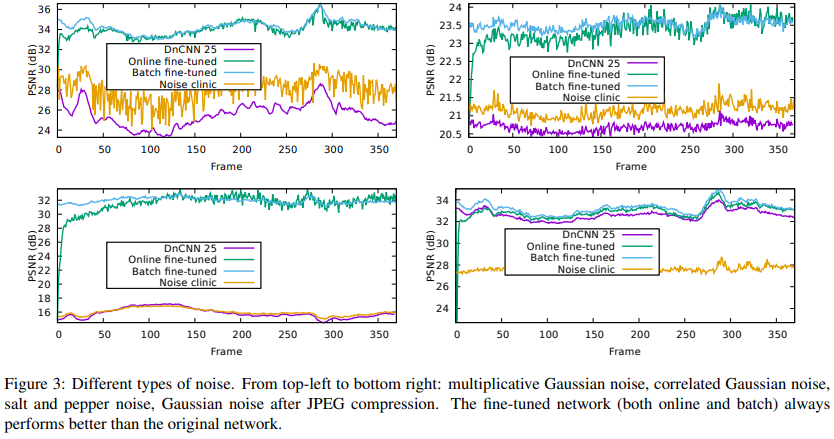
两种模式主要差异:线下模式会更稳定,方差更小。
此外还有一个发现:本文方法和DnCNN一样,都会趋于过度平滑。如果将预训练网络换成其他更保真的视频去噪方法,可能会改善这个问题。
Paper | Model-blind video denoising via frame-to-frame training的更多相关文章
- 论文笔记:Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering 2019-04-25 21: ...
- frame与frame之间怎么用jquery传值
frame与frame之间如何用jquery传值 使用jquery操作iframe 1. 内容里有两个ifame <iframe id="leftiframe"...< ...
- com.rabbitmq.client.impl.Frame.readFrom(Frame.java:95)
RabbitMQ 基于Erlang 实现, 客户端可以用Python | Java | Ruby | PHP | C# | Javascript | Go等语言来实现.这里做个java语言的测试.首先 ...
- Note for video Machine Learning and Data Mining——training vs Testing
Here is the note for lecture five. There will be several points 1. Training and Testing Both of th ...
- Paper | Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
目录 故事背景 网络结构 BN和残差学习 拓展到其他任务 发表在2017 TIP. 摘要 Discriminative model learning for image denoising has b ...
- Research Guide for Video Frame Interpolation with Deep Learning
Research Guide for Video Frame Interpolation with Deep Learning This blog is from: https://heartbeat ...
- CVPR2016 Paper list
CVPR2016 Paper list ORAL SESSIONImage Captioning and Question Answering Monday, June 27th, 9:00AM - ...
- paper 15 :整理的CV代码合集
这篇blog,原来是西弗吉利亚大学的Li xin整理的,CV代码相当的全,不知道要经过多长时间的积累才会有这么丰富的资源,在此谢谢LI Xin .我现在分享给大家,希望可以共同进步!还有,我需要说一下 ...
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
随机推荐
- Java连载41-this关键字其他注意事项、static方法
一.this关键字 1.this在多数情况下都会省略 2.this不能用在含有static的方法之中. 3.static的方法的调用是不需要对象的,直接使用格式:类名.方法名:没有当前对象,自然不能访 ...
- SpringMVC日期类型接收空值异常问题
最近遇到SpringMVC写个controller类,传一个空串的字符类型过来,正常情况是会自动转成date类型的,因为数据表对应类类型就是date的 解决方法是在controller类的后面加个注解 ...
- 使用os模块动态获取目录或文件路径
在接口自动化测试框架中,我们的代码除了能在本地运行,也能在不在修改代码的前提下在其他的环境下能够运行,这样才能达到高复用性和低维护成本,我们在接口测试的模块调用中,会定义很多相关路径,而这些路径必须使 ...
- Define the Data Model and Set the Initial Data 定义数据模型并设置初始数据
This topic describes how to define the business model and the business logic for WinForms and ASP.NE ...
- Javase之集合泛型
集合泛型知识 泛型 是一种把类型明确工作推迟到创建对象或者调用方法的时候才明确的特殊类型. 也称参数化类型,把类型当成参数传递. 在jdk1.5中出现.一般来说经常在集合中使用. 格式 <数据类 ...
- django4-模板进阶
1.模板系统的语法 引用变量数据: {{ }} 标签逻辑操作:{%...%} 2.变量 变量名由字符数字下划线组成 ,可以执行由视图函数传过来的对象的方法和属性 ,但是视图函数中如果使用 ' . ' ...
- ES6数组及对象遍历的新增方法 entries(),keys() 和 values()
ES6 提供三个新的方法——entries(),keys()和values()——用于遍历数组.它们都返回一个遍历器对象(详见<Iterator>一章),可以用for...of循环进行遍历 ...
- Window常用且通用快捷键
Ctrl系列: Ctrl +z :回撤,后退 Ctrl +a :全选 Alt系列: Alt+Tab :切换窗口 Window系列 Window+R:打开“运行”窗口 Window+D:显示桌面 其中常 ...
- ES新提案:双问号操作符
摘要: 简单实用的新特性. 原文:ES新提案:双问号操作符 译者:前端小智 本文主要讲Gabriel Isenberg撰写的ES提案"Nullish coalescing for JavaS ...
- impdp中的DISABLE_ARCHIVE_LOGGING参数测试
impdp中的DISABLE_ARCHIVE_LOGGING参数测试 发表于 2017 年 04 月 08 日 由 惜分飞 联系:手机/微信(+86 13429648788) QQ(107644445 ...