Hadoop MapReduce的Shuffle过程
一、概述
理解Hadoop的Shuffle过程是一个大数据工程师必须的,笔者自己将学习笔记记录下来,以便以后方便复习查看。
二、
MapReduce确保每个reducer的输入都是按键排序的。系统执行排序、将map输出作为输入传给reducer的过程称为Shuffle。
2.1 map端
map函数开始产生输出时,利用缓冲的方式写到内存并排序具体分一下几个步骤。
1.map数据分片:把输入数据源进行分片,根据分片来决定有多少个map,每个map任务都有一个环形内存缓冲区用于存储任务输出,默认情况下缓冲区大小为100MB,可通过mapreduce.task.io.sort.mb来调整。
2.map排序:当map缓冲区大小达到阈值时(mapreduce.map.sort.spill.percent),就会将内存的数据溢写到磁盘,根据reducer的来划分成相应的partition,在内存中按键值进行排序,如果有combiner函数,在排序后就会应用,排序后写入分区磁盘文件中。溢写的过程中,map会阻塞直到写磁盘过程完成。每次内存缓冲区到达溢出阈值,就会新建一个溢出文件件,在map写完最后一个输出记录之后,会有几个溢出文件,在任务完成之前溢出文件会被合并成一个已分区且已经排序的输出文件。mapreduce.task.io.sort.factor控制着一次最多能合并多少溜,默认10。mapreduce.map.output.compress进行压缩,提高写磁盘速度。
2.2reduce端
1.reduce复制:reducer通过http得到输出文件的分区,用于文件分区的工作线程数量由任务的mapreduce.shuffle.max.threads属性控制。每个map任务的完成时间不同,在每个任务完成时,reduce任务就开始复制其输出,这就是reduce任务的复制阶段,reduce的复制线程数量mapreduce.reduce.shuffle.parallelcopies决定。
复制详解:如果map输出很小,会被复制到reduce任务JVM的内存,否则输出被复制到磁盘。如果内存缓冲区达到阈值大小(mapreduce.reduce.shuffle.merge.percent)或达到map输出阈值(mapreduce.reduce.merge.inmem.threshold),则合并溢出写到磁盘中,如果指定combiner,则在合并期间运行它。随着磁盘上副本增多,后台线程会将他们合并为更大的,排序的文件。
2.reduce合并排序:这个阶段合并map输出,维持其顺序排序,这是循环进行的,如果有50个map输出,合并因子是10(mapreduce.task.io.sort.factor),合并将进行5次,最后有5个中间文件。
3.reduce:直接把数据输入reduce函数,从而省略了一次磁盘的往返行程。
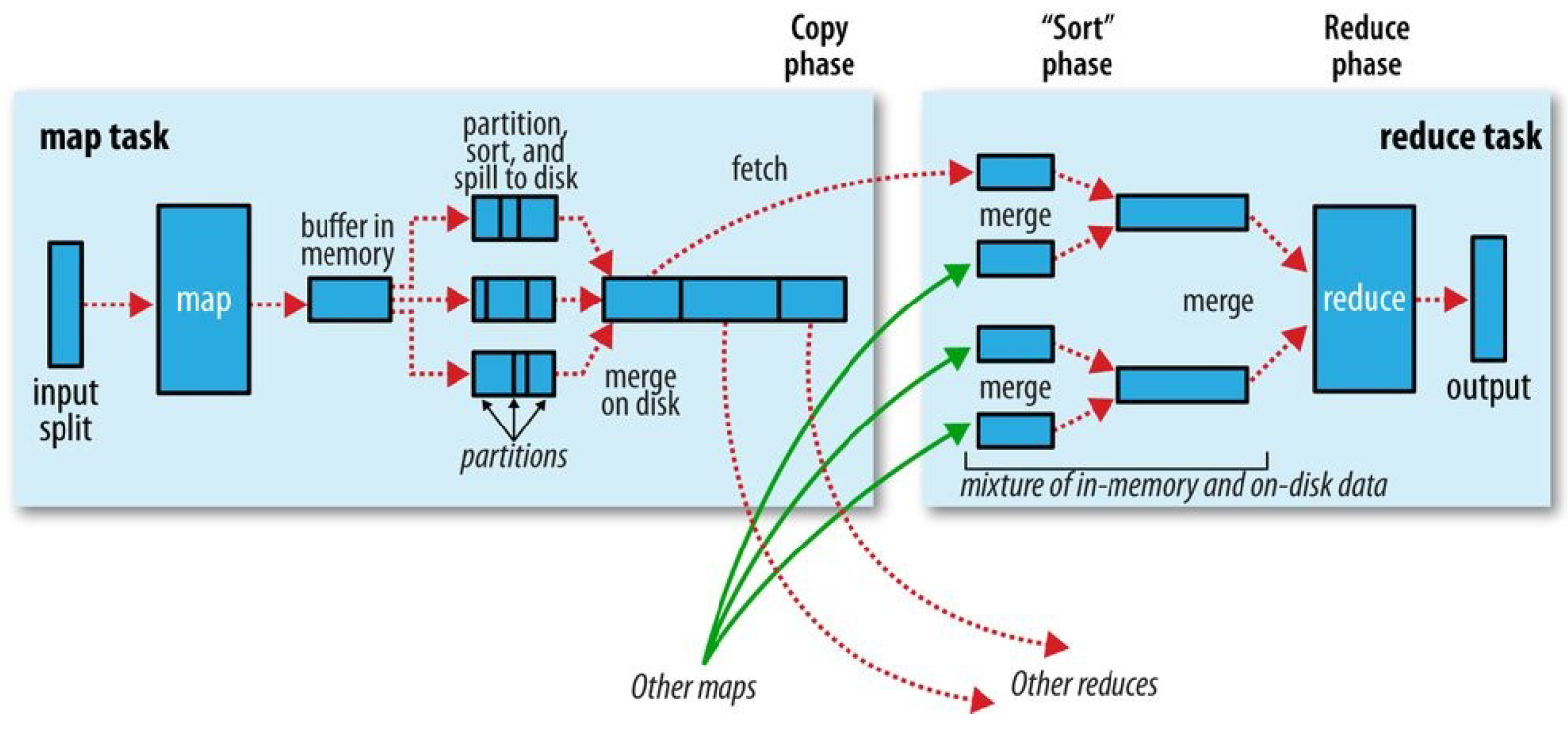
至此mapreduce过程完毕,具体参考Hadoop权威指南第四版。
Hadoop MapReduce的Shuffle过程的更多相关文章
- Hadoop Mapreduce的shuffle过程详解
1.map task读取数据时默认调用TextInputFormat的成员RecoreReader,RecoreReader调用自己的read()方法,进行逐行读取,返回一个key.value; 2. ...
- MapReduce的Shuffle过程介绍
MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapReduce中的Shuffle更像是洗牌的逆过程,把一 ...
- Hadoop学习之shuffle过程
转自:http://langyu.iteye.com/blog/992916,多谢分享,学习Hadopp性能调优的可以多关注一下 Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方, ...
- MapReduce:Shuffle过程详解
1.Map任务处理 1.1 读取HDFS中的文件.每一行解析成一个<k,v>.每一个键值对调用一次map函数. <0,hello you> & ...
- Hadoop Mapreduce中shuffle 详解
MapReduce 里面的shuffle:描述者数据从map task 输出到reduce task 输入的这段过程 Shuffle 过程: 首先,map 输出的<key,value > ...
- mapReduce的shuffle过程
http://www.jianshu.com/p/c97ff0ab5f49 总结shuffle 过程: map端的shuffle: (1)map端产生数据,放入内存buffer中: (2)buffer ...
- MapReduce 的 shuffle 过程中经历了几次 sort ?
shuffle 是从map产生输出到reduce的消化输入的整个过程. 排序贯穿于Map任务和Reduce任务,是MapReduce非常重要的一环,排序操作属于MapReduce计算框架的默认行为,不 ...
- Hadoop Mapreduce中wordcount 过程解析
将文件split 文件1: 分割结果: hello world ...
- MapReduce的shuffle过程详解
[学习笔记] 结果分析:shuffle的英文是洗牌,混洗的意思,洗牌就是越乱越好的意思.当在集群的情况下是这样的,假如有三个map节点和三个reduce节点,一号reduce节点的数据会来自于三个ma ...
随机推荐
- iOS开发系列之性能优化(上)
本篇主要记录一下我对界面优化上的一些探索.关于时间优化的探索将会在中篇里进行介绍.下篇将主要介绍一些耗电优化.安装包瘦身的探索. ### 1.卡顿原理 要了解卡顿原理,需要对帧缓冲区.垂直同步.CPU ...
- 08、MySQL—字符串型
字符串型 1.Char 定长字符:指定长度之后,系统一定会分配指定的空间用于存储数据 基本语法: char(L),L代表字符数(中文与英文字母一样),L长度为0到255 2.Varchar 变长字符: ...
- 【疑难杂症】windows下如何有效重装印象笔记
重装这么简单的操作还用得着写篇文章吗??emmmm,言之有理,简单的重装就是卸载后重新下载最新的安装包然后安装就完事了,这里说的肯定是不简单的重装[滑稽]. 背景是这样的,之前在mac上对印象笔记的笔 ...
- TCP/IP 第四、五章
1, 2, 整个arp请求的过程. 3,arp -a 获取arp高速缓存.一般arp高速缓存存活时间20分钟,不完整的表项设置为3分钟.因为机器的ip地址可能发生改变. 4, 5,arp一般是操作系统 ...
- git常用总结
git 基本配置 安装git yum -y install git git全局配置 git config --global user.name "lsc" #配置git使用用户 g ...
- shell遍历文件
取文件每行的数据,需要按列取 可以 sed 加管道 使用 awk 取列 platform="list.txt" line=`grep -vc '^$' $platform` ; ...
- client-go中的golang技巧
client-go中有很多比较有意思的实现,如定时器,同步机制等,可以作为移植使用.下面就遇到的一些技术讲解,首先看第一个: sets.String(k8s.io/apimachinery/pkg/u ...
- Vue技术点整理-Vue CLI
Vue CLI 是一个基于 Vue.js 进行项目快速开发的脚手架 注:具体安装步骤可参考Vue CLI,默认安装的脚手架,是没有service.util等工具类的,以下主要描述如何在脚手架的基础上进 ...
- django基础知识之自连接:
自连接 对于地区信息,属于一对多关系,使用一张表,存储所有的信息 类似的表结构还应用于分类信息,可以实现无限级分类 新建模型AreaInfo,生成迁移 class AreaInfo(models.Mo ...
- 关于 https的SNI问题
遇到的问题,服务器多站点配置HTTPS 后遇到的问题,服务器报警告错误. 随后网上搜索了下 SNI的意义. 这句话很经典: SNI(Server Name Indication)是为了解决一个服务器使 ...