logistic回归 python代码实现
1. 读取数据集
def load_data(filename,dataType):
return np.loadtxt(filename,delimiter=",",dtype = dataType) def read_data():
data = load_data("data2.txt",np.float64)
X = data[:,0:-1]
y = data[:,-1]
return X,y
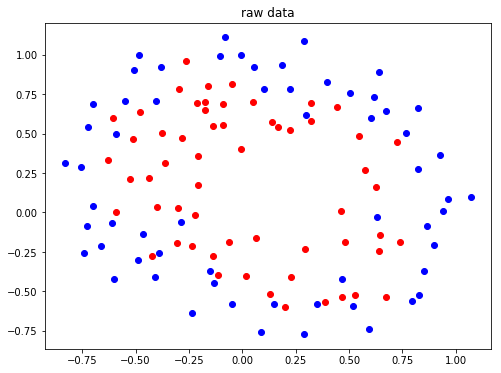
2. 查看原始数据的分布
def plot_data(x,y):
pos = np.where(y==1) # 找到标签为1的位置
neg = np.where(y==0) #找到标签为0的位置 plt.figure(figsize=(8,6))
plt.plot(x[pos,0],x[pos,1],'ro')
plt.plot(x[neg,0],x[neg,1],'bo')
plt.title("raw data")
plt.show() X,y = read_data()
plot_data(X,y)
结果:
3. 将数据映射为多项式
由原图数据分布可知,数据的分布是非线性的,这里将数据变为多项式的形式,使其变得可分类。
映射为二次方的形式: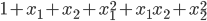
def mapFeature(x1,x2):
degree = 2; #映射的最高次方
out = np.ones((x1.shape[0],1)) # 映射后的结果数组(取代X) for i in np.arange(1,degree+1):
for j in range(i+1):
temp = x1 ** (i-j) * (x2**j)
out = np.hstack((out,temp.reshape(-1,1)))
return out
4. 定义交叉熵损失函数
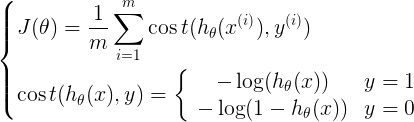
可以综合起来为: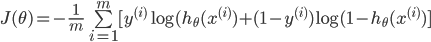
其中: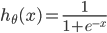
为了防止过拟合,加入正则化技术: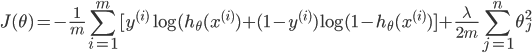
注意j是重1开始的,因为theta(0)为一个常数项,X中最前面一列会加上1列1,所以乘积还是theta(0),feature没有关系,没有必要正则化
def sigmoid(x):
return 1.0 / (1.0+np.exp(-x)) def CrossEntropy_loss(initial_theta,X,y,inital_lambda): #定义交叉熵损失函数
m = len(y)
h = sigmoid(np.dot(X,initial_theta))
theta1 = initial_theta.copy() # 因为正则化j=1从1开始,不包含0,所以复制一份,前theta(0)值为0
theta1[0] = 0 temp = np.dot(np.transpose(theta1),theta1)
loss = (-np.dot(np.transpose(y),np.log(h)) - np.dot(np.transpose(1-y),np.log(1-h)) + temp*inital_lambda/2) / m
return loss
5. 计算梯度
对上述的交叉熵损失函数求偏导:
利用梯度下降法进行优化:
def gradientDescent(initial_theta,X,y,initial_lambda,lr,num_iters):
m = len(y) theta1 = initial_theta.copy()
theta1[0] = 0
J_history = np.zeros((num_iters,1)) for i in range(num_iters):
h = sigmoid(np.dot(X,theta1))
grad = np.dot(np.transpose(X),h-y)/m + initial_lambda * theta1/m
theta1 = theta1 - lr*grad
#print(theta1)
J_history[i] = CrossEntropy_loss(theta1,X,y,initial_lambda)
return theta1,J_history
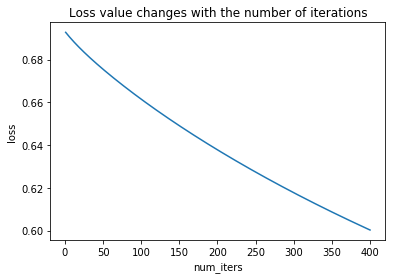
6. 绘制损失值随迭代次数的变化曲线
def plotLoss(J_history,num_iters):
x = np.arange(1,num_iters+1)
plt.plot(x,J_history)
plt.xlabel("num_iters")
plt.ylabel("loss")
plt.title("Loss value changes with the number of iterations")
plt.show()
7. 绘制决策边界
def plotDecisionBoundary(theta,x,y):
pos = np.where(y==1) #找到标签为1的位置
neg = np.where(y==0) #找到标签为2的位置 plt.figure(figsize=(8,6))
plt.plot(x[pos,0],x[pos,1],'ro')
plt.plot(x[neg,0],x[neg,1],'bo')
plt.title("Decision Boundary") #生成和原数据类似的数据
u = np.linspace(-1,1.5,50)
v = np.linspace(-1,1.5,50)
z = np.zeros((len(u),len(v)))
#利用训练好的参数做预测
for i in range(len(u)):
for j in range(len(v)):
z[i,j] = np.dot(mapFeature(u[i].reshape(1,-1),v[j].reshape(1,-1)),theta) z = np.transpose(z)
plt.contour(u,v,z,[0,0.01],linewidth=2.0) # 画等高线,范围在[0,0.01],即近似为决策边界
plt.legend()
plt.show()
8.主函数
if __name__ == "__main__":
#数据的加载
x,y = read_data()
X = mapFeature(x[:,0],x[:,1])
Y = y.reshape((-1,1))
#参数的初始化
num_iters = 400
lr = 0.1
initial_theta = np.zeros((X.shape[1],1)) #初始化参数theta
initial_lambda = 0.1 #初始化正则化系数
#迭代优化
theta,loss = gradientDescent(initial_theta,X,Y,initial_lambda,lr,num_iters)
plotLoss(loss,num_iters)
plotDecisionBoundary(theta,x,y)
9.结果

logistic回归 python代码实现的更多相关文章
- 机器学习实战 logistic回归 python代码
# -*- coding: utf-8 -*- """ Created on Sun Aug 06 15:57:18 2017 @author: mdz "&q ...
- Logistic回归 python实现
Logistic回归 算法优缺点: 1.计算代价不高,易于理解和实现2.容易欠拟合,分类精度可能不高3.适用数据类型:数值型和标称型 算法思想: 其实就我的理解来说,logistic回归实际上就是加了 ...
- Logistic回归python实现
2017-08-12 Logistic 回归,作为分类器: 分别用了梯度上升,牛顿法来最优化损失函数: # -*- coding: utf-8 -*- ''' function: 实现Logistic ...
- Logistic回归python实现小样例
假设现在有一些点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,依次进行分类.Lo ...
- logistic 回归Matlab代码
function a alpha = 0.0001; [m,n] = size(q1x); max_iters = 500; X = [ones(size(q1x,1),1), q1x]; % app ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 机器学习/逻辑回归(logistic regression)/--附python代码
个人分类: 机器学习 本文为吴恩达<机器学习>课程的读书笔记,并用python实现. 前一篇讲了线性回归,这一篇讲逻辑回归,有了上一篇的基础,这一篇的内容会显得比较简单. 逻辑回归(log ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
- Logistic回归模型和Python实现
回归分析是研究变量之间定量关系的一种统计学方法,具有广泛的应用. Logistic回归模型 线性回归 先从线性回归模型开始,线性回归是最基本的回归模型,它使用线性函数描述两个变量之间的关系,将连续或离 ...
随机推荐
- JDBC的批处理学习rewriteBatchedStatements=true
如果在不添加批处理指令的情况下,mysql默认是不使用批处理操作,如果在url尾部添加rewriteBatchedStatements=true 可以使当前连接 使用批处理操作 创建数据库表结构 cr ...
- setInterval、setTimeout之遗忘的第三个参数
今天看阮一峰老师的ES6入门,在一个关于promise的小demo里,老师用到了setTimeout的第三个参数,惊了有没有,定时器还有第三个参数? 喏就是下面这个demo: function tim ...
- 一个selenium简单案例自动添加数据
//本来想着用execl来录入数据的,但是为了尽快完成所以直接搞了个数组 package aldtest; import org.openqa.selenium.*; import org.openq ...
- WPF中资源的引用方法
一.引用同一个程序中的资源 1.使用相对Uri来引用资源,如下所示 img.Source=new BitmapImage(new Uri(@"d"\iamges\Backgroun ...
- python学习笔记之zipfile模块
为什么学习: 在做自动化测试平台的apk上传功能部分时候,涉及到apk上传后提取apk的icon图标,通过aapt解析apk,获取对应icon在apk中的地址,通过python的zipfile模块来解 ...
- Linux之修改系统密码
目录 Linux之修改系统密码 参考 RHEL6修改系统密码 RHEL7修改系统密码 Linux之修改系统密码
- xpath语法分享
# xpath语法: ## 使用方式: 使用//获取整个页面当中的元素,然后写标签名,然后再写谓词进行提取.比如: ``` //div[@class='abc'] ``` ## 需要注意的知识点: 1 ...
- HashMap 取数算法
Map,百度翻译给我的解释是映射,在Java编程中,它是存储键值对(key-value)的一种容器,也是Java程序员常用的对象.这篇博客介绍下HashMap的实现:java是面向对象编程语言,jdk ...
- 50个实用的jq代码段整理
个人博客: http://mcchen.club 1. 如何创建嵌套的过滤器: //允许你减少集合中的匹配元素的过滤器, //只剩下那些与给定的选择器匹配的部分.在这种情况下, //查 ...
- 超详细的FreeRTOS移植全教程——基于srm32
### 准备 在移植之前,我们首先要获取到FreeRTOS的官方的源码包.这里我们提供两个下载链接: > 一个是官网:http://www.freertos.org/ > 另外一个是代码托 ...