mybatis数据源与连接池
1.概念介绍
1.1 数据源:顾名思义,数据的来源,它包含了数据库类型信息,位置和数据等信息,一个数据源对应一个数据库。
1.2 连接池:在做持久化操作时,需要通过数据库连接对象来连接数据库,而连接池就是数据库连接对象的缓冲池,需要的时候可以从这个缓冲池中直接取出。
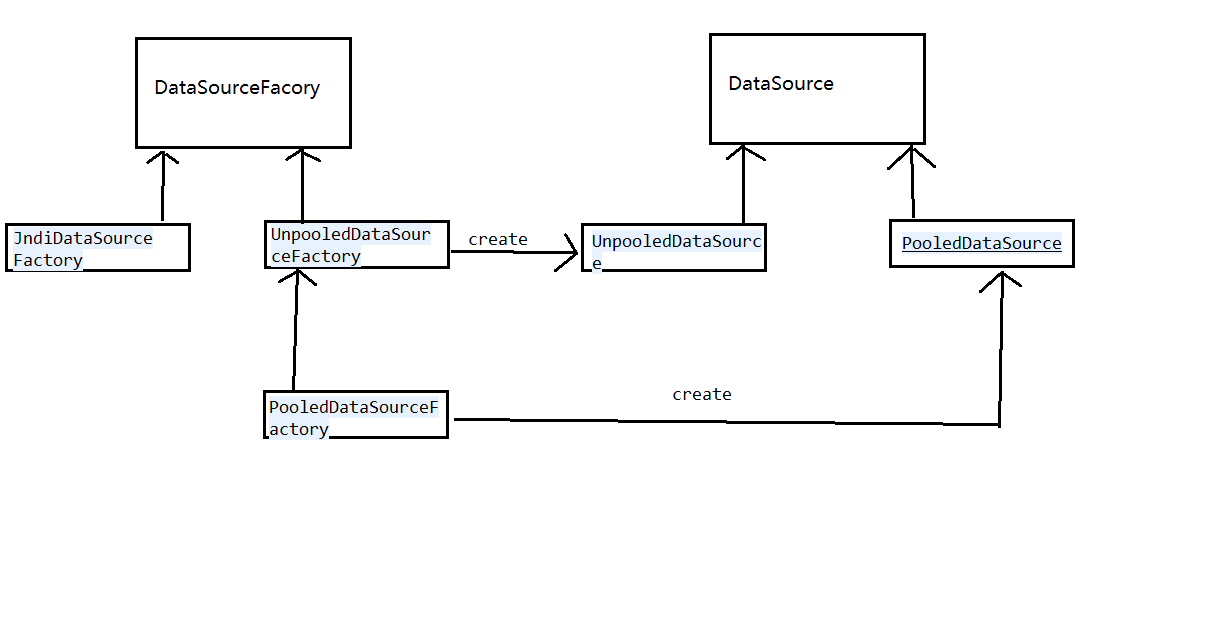
1.3 数据源的分类:UnpooledDataSource,PooledDataSource和JndiDataSourceFactory,采用的是工厂模式来生成这些对象的,如下如所示:
2.DataSource的创建过程
数据源DataSource是在mybatis初始化加载配置文件的时候进行创建的,配置文件信息如下:
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
// type="POOLED" 表示创建有连接池的数据源 PooledDataSource对象
// type="UNPOOLED" 表示创建没有连接池的数据源 UnpooledDataSource对象
// type="JNDI" 表示会从JNDI服务器上查找数据源
<dataSource type="POOLED">
<property name="driver" value="${driver}" />
<property name="url" value="${url}" />
<property name="username" value="${username}" />
<property name="password" value="${password}" />
</dataSource>
</environment>
</environments>
创建过程,看源码,进入XMLConfigBuilder类的dataSourceElement方法:
private DataSourceFactory dataSourceElement(XNode context) throws Exception {
if (context != null) {
// 获取type的属性值
String type = context.getStringAttribute("type");
Properties props = context.getChildrenAsProperties();
// 根据type的属性值,获取DataSourceFactory的class对象,然后根据DataSourceFactory的class对象创建一个DataSourceFactory实例对象。
DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();
// 设置DataSource的相关属性 进入该方法
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a DataSourceFactory.");
}
当DataSourceFactory实例对象创建完成以后,此时对应的DataSource也就创建完成了,通过源码可知,DataSource的创建是在DataSourceFactory的构造器中执行的。比如,看下UnpooledDataSourceFactory的构造方法:
public UnpooledDataSourceFactory() {
this.dataSource = new UnpooledDataSource();
}
进入 factory.setProperties(props);方法:
public void setProperties(Properties properties) {
Properties driverProperties = new Properties();
// 创建DataSource对应的MetaObject对象
MetaObject metaDataSource = SystemMetaObject.forObject(dataSource);
// 遍历Properties集合,该集合中配置了数据源需要的信息
for (Object key : properties.keySet()) {
String propertyName = (String) key;
if (propertyName.startsWith(DRIVER_PROPERTY_PREFIX)) {
String value = properties.getProperty(propertyName);
driverProperties.setProperty(propertyName.substring(DRIVER_PROPERTY_PREFIX_LENGTH), value);
} else if (metaDataSource.hasSetter(propertyName)) {
String value = (String) properties.get(propertyName);
// 进入该方法可知:对属性类型进行类型转换,主要是Integer,Long,Boolean的类型转换
Object convertedValue = convertValue(metaDataSource, propertyName, value);
// 设置DataSource的相关属性
metaDataSource.setValue(propertyName, convertedValue);
} else {
throw new DataSourceException("Unknown DataSource property: " + propertyName);
}
}
if (driverProperties.size() > 0) {
metaDataSource.setValue("driverProperties", driverProperties);
}
}
这就是DataSouece对象的创建及其属性配置的过程。
3.UnpooledDataSource的解析
UnpooledDataSource实现了DataSource接口,每次调用它的getConnection方法时,都会创建一个新的连接。接下来对这个类进行分析:
在该类中有一个静态代码块如下所示,就是在加载UnpooledDataSource类时,会加载该静态代码块,将已经在DriverManager中注册的JDBC Driver复制一份到UnpooledDataSource.registeredDrivers集合中。
static {
Enumeration<Driver> drivers = DriverManager.getDrivers();
while (drivers.hasMoreElements()) {
Driver driver = drivers.nextElement();
registeredDrivers.put(driver.getClass().getName(), driver);
}
}
3.1 属性:
private ClassLoader driverClassLoader; // 加载Driver类的类加载器
private Properties driverProperties; // 数据库连接驱动的相关配置
// 缓存所有已经注册的数据库连接驱动
private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap<String, Driver>(); private String driver; //数据库连接的驱动名称
private String url;
private String username;
private String password; private Boolean autoCommit; // 是否自动提交
private Integer defaultTransactionIsolationLevel; //事务的隔离级别
3.2 获取连接对象Connection的过程:
private Connection doGetConnection(Properties properties) throws SQLException {
// 初始化数据库驱动
initializeDriver();
// 创建数据库连接对象
Connection connection = DriverManager.getConnection(url, properties);
// 配置连接对象的隔离级别和是否自动提交
configureConnection(connection);
return connection;
}
进入initializeDriver方法:
private synchronized void initializeDriver() throws SQLException {
// 判断数据库驱动是否已经被加载,如果没有则动态加载
if (!registeredDrivers.containsKey(driver)) {
Class<?> driverType;
try {
if (driverClassLoader != null) {
driverType = Class.forName(driver, true, driverClassLoader);
} else {
driverType = Resources.classForName(driver);
}
// DriverManager requires the driver to be loaded via the system ClassLoader.
// http://www.kfu.com/~nsayer/Java/dyn-jdbc.html
// 获取Driver类的实例对象,然后注册到DriverManager中
Driver driverInstance = (Driver)driverType.newInstance();
DriverManager.registerDriver(new DriverProxy(driverInstance));
// 将driver添加到registeredDriver集合中
registeredDrivers.put(driver, driverInstance);
} catch (Exception e) {
throw new SQLException("Error setting driver on UnpooledDataSource. Cause: " + e);
}
}
}
每调用一次getConnection方法,上面的流程都会重新走一次,所以每次都是获取的新的Connection连接对象。
4.PooledDataSource的解析
在进行PooledDataSource的讲解前,先分析PooledConnection和PoolState这两个类,因为它们两个对PooledDataSource而言很重要。
4.1 PooledConnection
PooledDataSource并不会直接管理java.sql.Connection对象,而是管理PooledConnection对象,该对象封装了真正的数据库连接对象java.sql.Connection和它自己的代理对象。
// 实现了InvocationHandler接口,所以连接对象的代理对象proxyConnection调用某个方法时,真正执行的逻辑是在invoke方法
class PooledConnection implements InvocationHandler { private static final String CLOSE = "close";
private static final Class<?>[] IFACES = new Class<?>[] { Connection.class }; private int hashCode = 0;
private PooledDataSource dataSource;
private Connection realConnection; //真正的数据库连接
private Connection proxyConnection; // 数据库连接的代理对象
private long checkoutTimestamp; // 从连接池中取出该连接的时间戳
private long createdTimestamp; // 创建该连接的时间戳
private long lastUsedTimestamp; //最后一次被使用的时间戳
private int connectionTypeCode; // 根据数据库连接的URL,用户名和密码生成的hash值,用于标识该连接所在的连接池
private boolean valid; //检测当前连接是否有效 /*
* Required for InvocationHandler implementation.
*
* @param proxy - not used
* @param method - the method to be executed
* @param args - the parameters to be passed to the method
* @see java.lang.reflect.InvocationHandler#invoke(Object, java.lang.reflect.Method, Object[])
*/
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
// 如果调用的是close方法,那么把该连接对象放到连接池中
if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) {
dataSource.pushConnection(this);
return null;
} else {
try {
if (!Object.class.equals(method.getDeclaringClass())) {
// issue #579 toString() should never fail
// throw an SQLException instead of a Runtime
checkConnection();
}
// 调用真正的连接对象对应的方法
return method.invoke(realConnection, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
} }
4.2 PoolState
PoolState是用于管理PooledConnection对象状态的组件,它有两个属性集合,来管理空闲状态的连接和活跃状态的连接,看源码:
protected final List<PooledConnection> idleConnections = new ArrayList<PooledConnection>(); // 空闲的PooledConnection集合
protected final List<PooledConnection> activeConnections = new ArrayList<PooledConnection>(); // 活跃的PooledConnection集合
protected long requestCount = 0; // 请求数据库连接的次数
protected long accumulatedRequestTime = 0; // 获取连接的积累时间
protected long accumulatedCheckoutTime = 0; // 所有连接积累的checkoutTime时长 CheckoutTime 是指从连接池中取出连接到归还连接着段时长
protected long claimedOverdueConnectionCount = 0; // 当连接长时间未归还给连接池时,会被认为连接超时,这个字段就是表示连接超时的个数
protected long accumulatedCheckoutTimeOfOverdueConnections = 0;// 累计超时时间
protected long accumulatedWaitTime = 0;// 累计等待时间
protected long hadToWaitCount = 0;// 累计等待次数
protected long badConnectionCount = 0;// 无效的连接数
4.3 PooledDataSource 是一个实现了简单连接池的数据源,我们通过源码来对它进行学习:
4.3.1 属性
// 用于管理连接池的状态并记录统计信息 稍后会对它进行分析
private final PoolState state = new PoolState(this);
// 用于生成真实的数据库连接对象,在构造函数中初始化该字段
private final UnpooledDataSource dataSource; // OPTIONAL CONFIGURATION FIELDS
protected int poolMaximumActiveConnections = 10; // 最大活跃连接数
protected int poolMaximumIdleConnections = 5; // 最大空闲连接数
protected int poolMaximumCheckoutTime = 20000; // 从连接池中取出该连接的最大时长
protected int poolTimeToWait = 20000; // 在无法获取连接时,线程需要等待的时间
protected String poolPingQuery = "NO PING QUERY SET"; // 在检测一个数据库连接是否可用时,会给数据库发送一个测试SQL语句
protected boolean poolPingEnabled = false; // 是否允许发送测试SQL语句
protected int poolPingConnectionsNotUsedFor = 0;
// 根据数据库的URL,用户名和密码生成的一个hash值,标识着当前的连接池,在构造函数中初始化
private int expectedConnectionTypeCode;
4.2 获取连接的过程:
先思考一个问题:下面这个方法什么时候执行呢?其实在调用查询语句goodsMapper.selectGoodsById("1");时,才会去获取连接的。
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while (conn == null) {
// 获取连接的过程要同步
synchronized (state) {
// 判断是否还有空闲的连接对象,如果有则直接取出
if (state.idleConnections.size() > 0) {
// Pool has available connection
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
// 如果没有,那么判断活跃的连接对象的个数是否超过允许的最大值
// Pool does not have available connection
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection
// 如果没有,则创建一个PooledConnection,它是对真实的Connection对象的包装,后面会介绍这个类
conn = new PooledConnection(dataSource.getConnection(), this);
@SuppressWarnings("unused")
//used in logging, if enabled
// 获取真实的连接对象
Connection realConn = conn.getRealConnection();
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection
// 活跃连接数已经达到最大值,则不能创建新的连接
// 获取最先创建的活跃连接
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
if (longestCheckoutTime > poolMaximumCheckoutTime) { //检测该连接是否超时
// Can claim overdue connection 对超时的连接信息进行统计
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
// 将超时连接移除activeCollections集合
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
oldestActiveConnection.getRealConnection().rollback();
}
// 创建新的PooledCOnnection,但是真实的连接对象并未创建新的,是刚才移除的那个真实的连接对象
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
oldestActiveConnection.invalidate();// 将超时的连接对象设置为无效
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
// 无空闲连接,无法创建新的连接对象,并且没有超时的连接,就只能阻塞等待
try {
if (!countedWait) {
state.hadToWaitCount++; //统计等待次数
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
// 阻塞等待
state.wait(poolTimeToWait);
// 统计累计的等待时间
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
// 如果获取到了PooledConnection对象
if (conn != null) {
if (conn.isValid()) { // 判断PooledCOnnection是否有效
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 设置PooledConnection的相关属性
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
// 将该PooledCollection放到activeConnections集合中
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
if (localBadConnectionCount > (poolMaximumIdleConnections + 3)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
return conn;
}
4.3.3 把连接放回到连接池的过程:
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized (state) { //同步
state.activeConnections.remove(conn); // 从activeConnections中移除该连接对象
if (conn.isValid()) { // 验证该连接是否有效
// 判断空闲连接数是否达到上限,以及该连接是否属于该连接池
if (state.idleConnections.size() < poolMaximumIdleConnections && conn.getConnectionTypeCode() == expectedConnectionTypeCode) {
state.accumulatedCheckoutTime += conn.getCheckoutTime(); // 累计连接时长
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 创建一个连接对象,真正的连接不是新建的
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
// 把新建的连接放到空闲连接集合中
state.idleConnections.add(newConn);
// 给新建的连接设置属性
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
// 将原来的连接设置无效
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
state.notifyAll();// 唤醒阻塞等待的线程
} else {
// 如果空闲连接数达到上限,或者 该连接对象不属于该连接池
state.accumulatedCheckoutTime += conn.getCheckoutTime(); // 增加累计连接时长
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
// 关闭真正的连接
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
// 将该连接对象设置为无效
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
state.badConnectionCount++;
}
}
}
mybatis数据源与连接池的更多相关文章
- Mybatis原理之数据源和连接池
在Java工程项目中,我们常会用到Mybatis框架对数据库中的数据进行增删查改,其原理就是对 JDBC 做了一层封装,并优化数据源的连接. 我们先来回顾下 JDBC 操作数据库的过程. JDBC 操 ...
- 《深入理解mybatis原理3》 Mybatis数据源与连接池
<深入理解mybatis原理> Mybatis数据源与连接池 对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构 ...
- 深入理解Spring Boot数据源与连接池原理
Create by yster@foxmail.com 2018-8-2 一:开始 在使用Spring Boot数据源之前,我们一般会导入相关依赖.其中数据源核心依赖就是spring‐boot‐s ...
- eclipse下jdbc数据源与连接池的配置及功能简介
今天在做四则运算网页版的时候遇到了一个困惑,由于需要把每个产生的式子存进 数据库,所以就需要很多次重复的加载驱动,建立连接等操作,这样一方面写程序不方便,加大了程序量,另一方面,还有导致数据库的性能急 ...
- Spring(Bean)4 配置数据源、连接池
<!-- 配置数据源 Mysql c3p0: 连接池. <bean id="dataSource" class="com.mchange.v2.c3p0.Co ...
- 《深入理解mybatis原理》 Mybatis数据源与连接池
对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构进行详尽的分析,并且深入解析MyBatis的连接池. 本文首先会讲述MyB ...
- mybatis深入理解(二)-----Mybatis数据源与连接池
对于ORM框架而言,数据源的组织是一个非常重要的一部分,这直接影响到框架的性能问题.本文将通过对MyBatis框架的数据源结构进行详尽的分析,并且深入解析MyBatis的连接池.本文首先会讲述MyBa ...
- 阶段3 1.Mybatis_07.Mybatis的连接池及事务_4 mybatis中使用unpooled配置连接池的原理分析
把之前的CRUD的代码src下的代码都复制过来 依赖项也都复制过来, 配置文件 整理一番 执行findAll方法的测试 查看日志的输出部分 修改程序池 再来执行findAll方法 Plooled从连接 ...
- springboot整合mybatis使用阿里(阿里连接池)和xml方式
源码地址:https://github.com/wuhongpu/springboot-mybatis.git 1.在pom文件中引入相关依赖包 <?xml version="1.0& ...
随机推荐
- 《JAVA程序设计》_第一周学习总结
20175217吴一凡 <java程序设计> 第一周学习总结 虽然已经做好了心理准备,但第一周的学习任务着实让我忙了整整三天,还是挺充实的吧.寒假已经在自己的电脑上安装好了虚拟机,我就在我 ...
- ECO开放平台对接文档说明
应用集成: http://open.teewon.net:1000/static/index.html#/docs/flow/integrate统一认证集成文档: http://open.teewon ...
- jupyter notebook安装纪要
本次教程使用python工具pip安装.更多安装方式请参考官网. 1.升级pip工具到最新 2.运行安装执行 pip install jupyter 3.安装中 4.更改工作目录 4.1获取配置文件路 ...
- 深入理解 Node.js 中 EventEmitter源码分析(3.0.0版本)
events模块对外提供了一个 EventEmitter 对象,即:events.EventEmitter. EventEmitter 是NodeJS的核心模块events中的类,用于对NodeJS中 ...
- Java多线程(四)—— synchronized关键字续
1.synchronized原理 在java中,每一个对象有且仅有一个同步锁.这也意味着,同步锁是依赖于对象而存在.当我们调用某对象的synchronized方法时,就获取了该对象的同步锁.例如,sy ...
- Java hashCode() equals()总结
1.hashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,hashCode是用来在散列存储结构中确定对象的存储地址的: 2.如果两个对象相同,就是适用于equals(j ...
- day96
在服务器上部署上线项目 Linux数据库处理 首先我们需要在mysql中创建bbs库,并导入数据库SQL脚本(就是原本运行在我们项目中的数据库) 前提:需要进入mysql中 mysql> cre ...
- Java调用FFmpeg进行视频处理及Builder设计模式的应用
1.FFmpeg是什么 FFmpeg(https://www.ffmpeg.org)是一套可以用来记录.转换数字音频.视频,并能将其转化为流的开源计算机程序.它用来干吗呢?视频采集.视频格式转化.视频 ...
- [LOJ#2386]. 「USACO 2018.01 Platinum」Cow at Large[点分治]
题意 题目链接 分析 假设当前的根为 rt ,我们能够在奶牛到达 \(u\) 之时拦住它,当且仅当到叶子节点到 \(u\) 的最短距离 \(mn_u \le dis_u\) .容易发现,合法的区域是许 ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...