Storm集群的安装配置
Storm集群的安装分为以下几步:
1、首先保证Zookeeper集群服务的正常运行以及必要组件的正确安装
2、释放压缩包
3、修改storm.yaml添加集群配置信息
4、使用storm脚本启动相应服务并查看服务状态
5、通过web查看storm集群的状态
安装Storm之前首先保证之前安装的Zookeeper服务正常运行,包括配置hosts映射,主机名修改,防火墙都已经设置完好
Storm是由java编写,因此必须依赖JDK运行,系统首先应正确安装JDK
部分需要依赖Python,红帽系列Linux默认Python版本是2.6.6,可以满足要求;Linux可以安装多个版本Python共存,生产过程中建议Python版本为2.7.x
这里测试使用的三台虚拟机主机名分别是:hadoopha,hadoop1,hadoop2
首先去Apache Storm官网下载安装包,网址是:http://storm.apache.org/,进入后点击上方DOWNLOAD按钮,进入下载列表
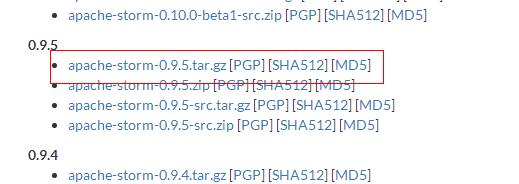
这里下载的是storm 0.9.5的版本,下载之后上传到服务器目录下,释放并且放到指定的目录:
$ tar -xvzf apache-storm-0.9..tar.gz
$ mv apache-storm-0.9. /usr/
$ cd /usr/apache-storm-0.9.
接下来需要修改配置文件storm.yaml,执行vim conf/storm.yaml打开文件:
去掉storm.zookeeper.servers:前面的注释,修改为集群中所有部署zookeeper的主机,当然都可以自己手动添加,具体配置如下:

增加storm.local.dir选项,指定nimbus,supervisor进程用于存储少量的状态数据,比如jar包,配置文件等
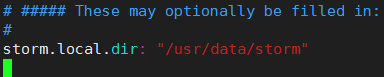
待会写好配置文件我们需要手动建立这个目录
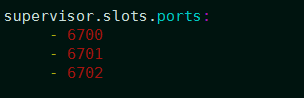
下面指定supervisor工作节点,需要配置该节点可以运行的worker数量,每个worker占用一个端口用于接收消息,最多分配5个;默认情况下每个节点可以运行4个worker,分别在6700、6701、6702、6703端口,这里定义3个端口,代表最多运行3个worker:
下面设置集群主机,让集群中所有的节点可以从主机下载拓扑以及配置文件,主机上运行的就是nimbus,而其他节点就是supervisor进程,这里hadoopha为nimbus,而hadoop1和hadoop2为supervisor,所以配置如下:

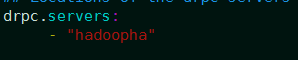
下面配置storm集群的drpc地址,这里就是hadoopha,实际中可以自己定义:
最后配置storm进程的分配内存,默认情况下Storm启动worker进程时,JVM的最大内存是768M,由于在使用过程中,Bolt中加载大量数据,768M内存无法满足要求,会导致内存溢出,应该根据实际情况进行修改,这里设置为2G

以上设置没问题,保存配置文件并退出
然后在3台主机分别创建上面设置的数据目录,必须都要创建:
mkdir -p /usr/data/storm
上面的配置是在hadoopha上配置的,接下来要把storm目录发送到hadoop1和hadoop2:
$ scp -r apache-storm-0.9. hadoop1:/usr/
$ scp -r apache-storm-0.9. hadoop2:/usr/
发送之后,进入storm安装目录,开始启动相应服务
首先启动Nimbus服务,只在hadoopha上执行:
nohup bin/storm nimbus >> /dev/null &
上面命令的意思是丢弃输出信息并且放到后台执行,稍微等一下,执行jps查看nimbus进程是否启动:
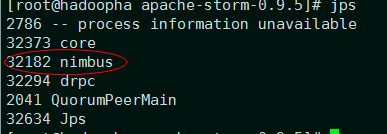
然后在hadoop1,hadoop2节点都启动Supervisor服务:
nohup bin/storm supervisor >> /dev/null &
稍等一下,也可以用jps查看到supervisor进程,
然后在配置drpc的主机hadoopha,drpc是一种后台服务,用于执行和storm相同的计算,但是比较节省资源,一般和nimbus使用同一台主机即可;执行以下命令启动drpc服务:
nohup bin/storm drpc >> /dev/null &
稍等一下可以分别通过jps命令查看到drpc进程,
最后在nimbus节点也就是hadoopha执行以下命令,启动UI服务:
nohup bin/storm ui >> /dev/null &
通过jps可以查看core进程是否启动,启动之后通过访问hadoopha的ip即可进入web管理界面:http://192.168.1.42:8080
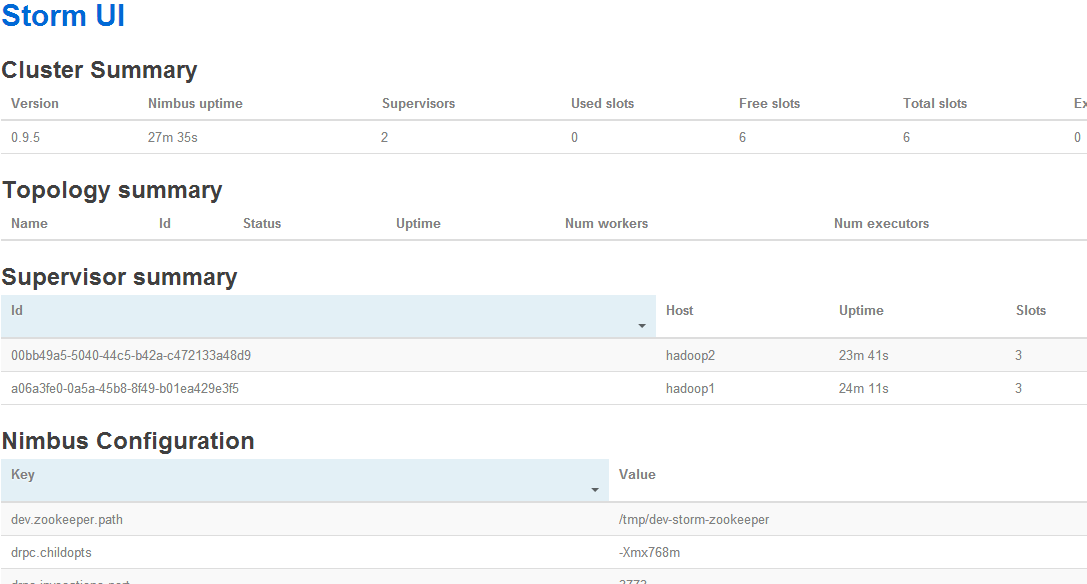
到这里基本的storm集群就配置完毕了
Storm集群的安装配置的更多相关文章
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
- Storm系列(一)集群的安装配置
安装前说明: 必须先安装zookeeper集群 该Storm集群由三台机器构成,主机名分别为chenx01,chenx02,chenx03,对应的IP分别为192.168.1.110,192.168. ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
- Storm集群的安装与测试
首先安装zookeeper集群,然后安装storm集群. 我使用的是centos 32bit的三台虚拟机. MachineName ip namenode 192.168.99.110 datanod ...
- storm集群的安装
storm图解 storm的基本概念 Topologies:拓扑,也俗称一个任务 Spoults:拓扑的消息源 Bolts:拓扑的处理逻辑单元 tuple:消息元组,在Spoults和Bolts传递数 ...
- Hadoop实战4:MapR分布式集群的安装配置及shell自动化脚本
MapR的分布式集群安装过程还是很艰难的,远远没有计划中的简单.本人总结安装配置,由于集群有很多机器,手动每台配置是很累的,编写了一个自动化配置脚本,下面以脚本为主线叙述(脚本并不完善,后续继续完善中 ...
- zookeeper集群环境安装配置
众所周知,Zookeeper有三种不同的运行环境,包括:单机环境.集群环境和集群伪分布式环境 在此介绍的是集群环境的安装配置 一.下载: http://apache.fayea.com/zookeep ...
- 第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点.每台计算机都运行一个收集和发送度量数据(如处理器速度.内存使用量等)的名为 gm ...
- kafka_2.11-0.10.1.1集群搭建安装配置
在搭建kafka集群之前,请保证zookeeper已安装. 1.下载 官网下载链接:http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/0.10.1.1/ ...
随机推荐
- 正确运用synchronized和二次判断 实现多线程安全
正确运用synchronized和二次判断 实现多线程安全,做出高效二符合预期的程序,特别是多个线程跑一个对象的时候,如下图所示: 测试代码如下: 特别注意if(shutdownRequested) ...
- golang笔记——环境搭建
1.下载安装 从 https://golang.org/dl/ 这里下载最新版本的 golang 安装包,分别有 Windows\Linux\Apple OSX\源码包. golang的官方网站是 h ...
- iOS:项目中疑难Crash问题集锦
项目中疑难Crash问题集锦 iOS App运行中遇到Crash的情况相信大家都遇到过,开发和者测试中遇到了可能很方便的办法就是直接拿着设备连接一下,然后使用Xcode自带的工具就可以解析出Crash ...
- PHP简单封装MysqlHelper类
MysqlHelper.class.php 1: <?php 2: 3: /** 4: * Mysql数据帮助类 5: */ 6: class MysqlHelper 7: { 8: func ...
- php正则预查
php正则预查 // 把ing结尾的单词词根部分(即不含ing部分)找出来$str = 'hello ,when i am working , don not coming';零宽度:站在原地往前看, ...
- php导入导出cvs文件格式
1.导入 <?php header("Content-type: text/html; charset=gb2312"); $fname = $_FILES['myfile' ...
- 最牛X的GCC 内联汇编
导读 正如大家知道的,在C语言中插入汇编语言,其是Linux中使用的基本汇编程序语法.本文将讲解 GCC 提供的内联汇编特性的用途和用法.对于阅读这篇文章,这里只有两个前提要求,很明显,就是 x86 ...
- 我要阻止做java开发的男朋友去创业型公司工作吗?
命这样的标题,我没有瞧不起创业型公司,我只是有点急了,因为男朋友今天晚上就要回复招聘公司了.我先来说说来由吧. 前段时间男朋友离职了,从毕业到现在在公司呆了2年多,因为资金不足导致他做的项目被迫停止了 ...
- java78_c
import java.util.*; public class Main { public static void main(String args[]){ Scanner cin=new Scan ...
- 【工具】【版本控制】TortoiseSVN过滤文件与文件夹
这些网上搜一大把,就直接截图过来了.