深度学习之logistics回归
在开始之前,事先声明本文参考【中文】【吴恩达课后编程作业】Course 1 - 神经网络和深度学习 - 第二周作业_何宽的博客-CSDN博客_吴恩达课后编程作业
加上自己的理解,希望可以不用重复看吴恩达老师的视频,哈哈
我用的是Jupyter,python3.7
本文所使用的资料已上传到百度网盘【点击下载】,提取码:2u3w ,请在开始之前下载好所需资料,然后将文件解压到你的代码文件同一级目录下,请确保你的代码那里有lr_utils.py和datasets文件夹。
当时花费了我好长时间去加载文件,一定要注意我标红的文字,那我们开始吧!
首先导入我们所需要的库
import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset
lr_utils.py代码如下,你也可以自行打开它查看:
import numpy as np
import h5py def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels classes = np.array(test_dataset["list_classes"][:]) # the list of classes train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0])) return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
解释一下上面的load_dataset() 返回的值的含义:
train_set_x_orig:是训练集的数据 train_set_y_orig:输出的[0|1],若训练的是猫,则猫(1)非猫(0) test_set_x_orig:是测试集的数据 test_set_y_orig:输出的[0|1],若训练的是猫,则猫(1)非猫(0) classes:保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’](开始时确实不知道)
现在我们就要把这些数据加载到主程序里面:
train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset()
我们可以看一下我们加载的文件里面的图片都是些什么样子的,比如我就查看一下训练集里面的第26张图片,当然你也可以改变index的值查看一下其他的图片。
index = 25 #26
plt.imshow(train_set_x_orig[index])
plt.show()


现在我们可以结合一下训练集里面的数据来看一下我到底都加载了一些什么东西。
#打印出当前的训练标签值
#使用np.squeeze的目的是压缩维度,【未压缩】train_set_y[:,index]的值为[1] , 【压缩后】np.squeeze(train_set_y[:,index])的值为1
#print("【使用np.squeeze:" + str(np.squeeze(train_set_y[:,index])) + ",不使用np.squeeze: " + str(train_set_y[:,index]) + "】")
#只有压缩后的值才能进行解码操作
print("y=" + str(train_set_y[:,index]) + ", it's a " + classes[np.squeeze(train_set_y[:,index])].decode("utf-8") + "' picture")
y=[1], it's a cat' picture
- m_train :训练集里图片的数量。
- m_test :测试集里图片的数量。
- num_px : 训练、测试集里面的图片的宽度和高度(均为64x64)。
- x.shape[1]是取的列,而x.shape[0]取的是行
- 请记住,train_set_x_orig 是一个维度为(m_train,num_px,num_px,3)的数组。
m_train = train_set_y.shape[1] #训练集里图片的数量。
m_test = test_set_y.shape[1] #测试集里图片的数量。
num_px = train_set_x_orig.shape[1] #训练、测试集里面的图片的宽度和高度(均为64x64)。 #现在看一看我们加载的东西的具体情况
print ("训练集的数量: m_train = " + str(m_train))
print ("测试集的数量 : m_test = " + str(m_test))
print ("每张图片的宽/高 : num_px = " + str(num_px))
print ("每张图片的大小 : (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("训练集_图片的维数 : " + str(train_set_x_orig.shape))
print ("训练集_标签的维数 : " + str(train_set_y.shape))
print ("测试集_图片的维数: " + str(test_set_x_orig.shape))
print ("测试集_标签的维数: " + str(test_set_y.shape))训练集的数量: m_train = 209
测试集的数量 : m_test = 50
每张图片的宽/高 : num_px = 64
每张图片的大小 : (64, 64, 3)
训练集_图片的维数 : (209, 64, 64, 3)
训练集_标签的维数 : (1, 209)
测试集_图片的维数: (50, 64, 64, 3)
测试集_标签的维数: (1, 50) - 为了方便,我们需要将高维度的矩阵降阶,比如说(64,64,3)降阶成为(64*64*3,1),这里为什么要乘以3,我们知道像素(R,G,B)是由红绿蓝三种颜色组成,。在此之后,我们的训练和测试数据集是一个numpy数组,【每列代表一个平坦的图像】 ,应该有m_train和m_test列。
- 当你想将形状(a,b,c,d)的矩阵X平铺成形状(b * c * d,a)的矩阵X_flatten时,可以使用以下代码:
#X_flatten = X.reshape(X.shape [0],-1).T #X.T是X的转置
#将训练集的维度降低并转置。 #参数-1就是不知道行数或者列数多少的情况下使用的参数,所以先确定除了参数-1之外的其他参数,
#然后通过(总参数的计算) / (确定除了参数-1之外的其他参数) = 该位置应该是多少的参数。
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T
#将测试集的维度降低并转置。
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T程序算出来时12288列,我再最后用一个T表示转置,这就变成了12288行,209列。测试集亦如此。
然后我们看看降维之后的情况是怎么样的:
print ("训练集降维最后的维度: " + str(train_set_x_flatten.shape))
print ("训练集_标签的维数 : " + str(train_set_y.shape))
print ("测试集降维之后的维度: " + str(test_set_x_flatten.shape))
print ("测试集_标签的维数 : " + str(test_set_y.shape))训练集降维最后的维度: (12288, 209)
训练集_标签的维数 : (1, 209)
测试集降维之后的维度: (12288, 50)
测试集_标签的维数 : (1, 50)- 为了表示彩色图像,我们可以将数据集的每一行除以255(像素通道的最大值),因为在RGB中不存在比255大的数据,所以我们可以放心的除以255,让标准化的数据位于[0,1]之间,现在标准化我们的数据集:
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255这张图拿CAD画,还不是太熟练,哈哈

现在总算是把我们加载的数据弄完了,我们现在开始构建神经网络。
这里拿math type写的,由于模糊我直接截的图片

建立神经网络的主要步骤是:
定义模型结构(例如输入特征的数量)
初始化模型的参数
循环:
3.1 计算当前损失(正向传播)
3.2 计算当前梯度(反向传播)
3.3 更新参数(梯度下降)
首先创建激活函数,其实激活函数也是为了将结果限制在(0,1)之间,激活函数也不只一个,我们改变一下激活函数,可以会有意想不到的事情。
def sigmoid(z):
return 1 / (1 + np.exp(-z))
初始化我们需要的参数w和b
def initialize_with_zeros(dim):
"""
此函数为w创建一个维度为(dim,1)的0向量,并将b初始化为0。 参数:
dim - 我们想要的w矢量的大小(或者这种情况下的参数数量) 返回:
w - 维度为(dim,1)的初始化向量。
b - 初始化的标量(对应于偏差)
"""
w = np.zeros(shape = (dim,1))
b = 0
#使用断言来确保我要的数据是正确的
assert(w.shape == (dim, 1)) #w的维度是(dim,1)
assert(isinstance(b, float) or isinstance(b, int)) #b的类型是float或者是int return (w , b)
初始化参数的函数已经构建好了,现在就可以执行“前向”和“后向”传播步骤来学习参数。
我们现在要实现一个计算成本函数及其渐变的函数propagate()。
def propagate(w, b, X, Y):
"""
实现前向和后向传播的成本函数及其梯度。
参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 矩阵类型为(num_px * num_px * 3,训练数量)
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据数量) 返回:
cost- 逻辑回归的负对数似然成本
dw - 相对于w的损失梯度,因此与w相同的形状
db - 相对于b的损失梯度,因此与b的形状相同
"""
m = X.shape[1] #正向传播
A = sigmoid(np.dot(w.T,X) + b) #计算激活值,请参考公式2。
cost = (- 1 / m) * np.sum(Y * np.log(A) + (1 - Y) * (np.log(1 - A))) #计算成本,请参考公式3和4。 #反向传播
dw = (1 / m) * np.dot(X, (A - Y).T) #请参考视频中的偏导公式。
db = (1 / m) * np.sum(A - Y) #请参考视频中的偏导公式。 #使用断言确保我的数据是正确的
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ()) #创建一个字典,把dw和db保存起来。
grads = {
"dw": dw,
"db": db
}
return (grads , cost)
接下来测试一下
#测试一下propagate
print("====================测试propagate====================")
#初始化一些参数
w, b, X, Y = np.array([[1], [2]]), 2, np.array([[1,2], [3,4]]), np.array([[1, 0]])
grads, cost = propagate(w, b, X, Y)
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print ("cost = " + str(cost))
====================测试propagate====================
dw = [[0.99993216]
[1.99980262]]
db = 0.49993523062470574
cost = 6.000064773192205
现在,我要使用渐变下降更新参数。
目标是通过最小化成本函数 J 来学习 w和b。
def optimize(w , b , X , Y , num_iterations , learning_rate , print_cost = False):
"""
此函数通过运行梯度下降算法来优化w和b 参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 维度为(num_px * num_px * 3,训练数据的数量)的数组。
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据的数量)
num_iterations - 优化循环的迭代次数
learning_rate - 梯度下降更新规则的学习率
print_cost - 每100步打印一次损失值 返回:
params - 包含权重w和偏差b的字典
grads - 包含权重和偏差相对于成本函数的梯度的字典
成本 - 优化期间计算的所有成本列表,将用于绘制学习曲线。 提示:
我们需要写下两个步骤并遍历它们:
1)计算当前参数的成本和梯度,使用propagate()。
2)使用w和b的梯度下降法则更新参数。
""" costs = [] for i in range(num_iterations): grads, cost = propagate(w, b, X, Y) dw = grads["dw"]
db = grads["db"] w = w - learning_rate * dw
b = b - learning_rate * db #记录成本
if i % 100 == 0:
costs.append(cost)
#打印成本数据
if (print_cost) and (i % 100 == 0):
print("迭代的次数: %i , 误差值: %f" % (i,cost)) params = {
"w" : w,
"b" : b }
grads = {
"dw": dw,
"db": db }
return (params , grads , costs)
现在就让我们来测试一下优化函数:
#测试optimize
print("====================测试optimize====================")
w, b, X, Y = np.array([[1], [2]]), 2, np.array([[1,2], [3,4]]), np.array([[1, 0]])
params , grads , costs = optimize(w , b , X , Y , num_iterations=100 , learning_rate = 0.009 , print_cost = False)
print ("w = " + str(params["w"]))
print ("b = " + str(params["b"]))
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
====================测试optimize====================
w = [[0.1124579 ]
[0.23106775]]
b = 1.5593049248448891
dw = [[0.90158428]
[1.76250842]]
db = 0.4304620716786828
然后将预测值存储在向量Y_prediction中。
def predict(w , b , X ):
"""
使用学习逻辑回归参数logistic (w,b)预测标签是0还是1, 参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 维度为(num_px * num_px * 3,训练数据的数量)的数据 返回:
Y_prediction - 包含X中所有图片的所有预测【0 | 1】的一个numpy数组(向量) """ m = X.shape[1] #图片的数量
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0],1) #计预测猫在图片中出现的概率
A = sigmoid(np.dot(w.T , X) + b)
for i in range(A.shape[1]):
#将概率a [0,i]转换为实际预测p [0,i]
Y_prediction[0,i] = 1 if A[0,i] > 0.5 else 0
#使用断言
assert(Y_prediction.shape == (1,m)) return Y_prediction
接着测试
#测试predict
print("====================测试predict====================")
w, b, X, Y = np.array([[1], [2]]), 2, np.array([[1,2], [3,4]]), np.array([[1, 0]])
print("predictions = " + str(predict(w, b, X)))
====================测试predict====================
predictions = [[1. 1.]]
我们基本上把所有的东西都做完了,现在我们要把这些函数统统整合到一个model()函数中,届时只需要调用一个model()就基本上完成所有的事了。
def model(X_train , Y_train , X_test , Y_test , num_iterations = 2000 , learning_rate = 0.5 , print_cost = False):
"""
通过调用之前实现的函数来构建逻辑回归模型 参数:
X_train - numpy的数组,维度为(num_px * num_px * 3,m_train)的训练集
Y_train - numpy的数组,维度为(1,m_train)(矢量)的训练标签集
X_test - numpy的数组,维度为(num_px * num_px * 3,m_test)的测试集
Y_test - numpy的数组,维度为(1,m_test)的(向量)的测试标签集
num_iterations - 表示用于优化参数的迭代次数的超参数
learning_rate - 表示optimize()更新规则中使用的学习速率的超参数
print_cost - 设置为true以每100次迭代打印成本 返回:
d - 包含有关模型信息的字典。
"""
w , b = initialize_with_zeros(X_train.shape[0]) parameters , grads , costs = optimize(w , b , X_train , Y_train,num_iterations , learning_rate , print_cost) #从字典“参数”中检索参数w和b
w , b = parameters["w"] , parameters["b"] #预测测试/训练集的例子
Y_prediction_test = predict(w , b, X_test)
Y_prediction_train = predict(w , b, X_train) #打印训练后的准确性
print("训练集准确性:" , format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100) ,"%")
print("测试集准确性:" , format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100) ,"%") d = {
"costs" : costs,
"Y_prediction_test" : Y_prediction_test,
"Y_prediciton_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations" : num_iterations }
return d
我们来跑一下
print("====================测试model====================")
#这里加载的是真实的数据,请参见上面的代码部分。
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = 2000, learning_rate = 0.005, print_cost = True)
====================测试model====================
迭代的次数: 0 , 误差值: 0.693147
迭代的次数: 100 , 误差值: 0.584508
迭代的次数: 200 , 误差值: 0.466949
迭代的次数: 300 , 误差值: 0.376007
迭代的次数: 400 , 误差值: 0.331463
迭代的次数: 500 , 误差值: 0.303273
迭代的次数: 600 , 误差值: 0.279880
迭代的次数: 700 , 误差值: 0.260042
迭代的次数: 800 , 误差值: 0.242941
迭代的次数: 900 , 误差值: 0.228004
迭代的次数: 1000 , 误差值: 0.214820
迭代的次数: 1100 , 误差值: 0.203078
迭代的次数: 1200 , 误差值: 0.192544
迭代的次数: 1300 , 误差值: 0.183033
迭代的次数: 1400 , 误差值: 0.174399
迭代的次数: 1500 , 误差值: 0.166521
迭代的次数: 1600 , 误差值: 0.159305
迭代的次数: 1700 , 误差值: 0.152667
迭代的次数: 1800 , 误差值: 0.146542
迭代的次数: 1900 , 误差值: 0.140872
训练集准确性: 99.04306220095694 %
测试集准确性: 70.0 %
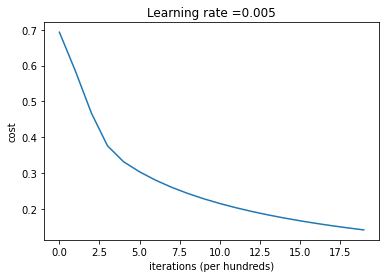
没有图片太突兀了,让我们来画张图片
#绘制图
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
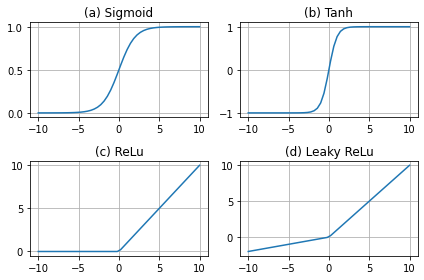
补充一下四个激活函数
import matplotlib.pyplot as plt
import numpy as np x = np.linspace(-10,10)
y_sigmoid = 1/(1+np.exp(-x))
y_tanh = (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x)) fig = plt.figure()
#plot sigmoid
ax = fig.add_subplot(221)
ax.plot(x,y_sigmoid)
ax.grid()
ax.set_title('(a) Sigmoid') # plot tanh
ax = fig.add_subplot(222)
ax.plot(x,y_tanh)
ax.grid()
ax.set_title('(b) Tanh') # plot relu
ax = fig.add_subplot(223)
y_relu = np.array([0*item if item<0 else item for item in x ])
ax.plot(x,y_relu)
ax.grid()
ax.set_title('(c) ReLu') #plot leaky relu
ax = fig.add_subplot(224)
y_relu = np.array([0.2*item if item<0 else item for item in x ])
ax.plot(x,y_relu)
ax.grid()
ax.set_title('(d) Leaky ReLu') plt.tight_layout()
到此为止,作业就做完了,尽管好多地方都是copy的但是也将自己的理解附了上去,继续学习吧!不过那位博主写的非常好
深度学习之logistics回归的更多相关文章
- 深度学习之逻辑回归的实现 -- sigmoid
1 什么是逻辑回归 1.1逻辑回归与线性回归的区别: 线性回归预测的是一个连续的值,不论是单变量还是多变量(比如多层感知器),他都返回的是一个连续的值,放在图中就是条连续的曲线,他常用来表示的数学方法 ...
- TensorFlow 深度学习笔记 逻辑回归 实践篇
Practical Aspects of Learning 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎star,有 ...
- 深度学习之softmax回归
前言 以下内容是个人学习之后的感悟,转载请注明出处~ softmax回归 首先,我们看一下sigmod激活函数,如下图,它经常用于逻辑回归,将一个real value映射到(0, ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 动手学深度学习4-线性回归的pytorch简洁实现
导入同样导入之前的包或者模块 生成数据集 通过pytorch读取数据 定义模型 初始化模型 定义损失函数 定义优化算法 训练模型 小结 本节利用pytorch中的模块,生成一个更加简洁的代码来实现同样 ...
- 深度学习在美团点评推荐平台排序中的应用&& wide&&deep推荐系统模型--学习笔记
写在前面:据说下周就要xxxxxxxx, 吓得本宝宝赶紧找些广告的东西看看 gbdt+lr的模型之前是知道怎么搞的,dnn+lr的模型也是知道的,但是都没有试验过 深度学习在美团点评推荐平台排序中的运 ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
- 深度学习实践系列(1)- 从零搭建notMNIST逻辑回归模型
MNIST 被喻为深度学习中的Hello World示例,由Yann LeCun等大神组织收集的一个手写数字的数据集,有60000个训练集和10000个验证集,是个非常适合初学者入门的训练集.这个网站 ...
- 《动手学深度学习》系列笔记—— 1.2 Softmax回归与分类模型
目录 softmax的基本概念 交叉熵损失函数 模型训练和预测 获取Fashion-MNIST训练集和读取数据 get dataset softmax从零开始的实现 获取训练集数据和测试集数据 模型参 ...
- 深度学习中常见的 Normlization 及权重初始化相关知识(原理及公式推导)
Batch Normlization(BN) 为什么要进行 BN 防止深度神经网络,每一层得参数更新会导致上层的输入数据发生变化,通过层层叠加,高层的输入分布变化会十分剧烈,这就使得高层需要不断去重新 ...
随机推荐
- KingbaseES timestamp 和 timestamptz 差异比较
KingbaseES 提供两种存储时间戳的数据类型: 不带时区的 TIMESTAMP 和带时区的 TIMESTAMPTZ. TIMESTAMP 数据类型可以同时存储日期和时间,但它不存储时区.这意味着 ...
- 采云链SRM SaaS供应商管理系统,发展型中小企业的福音
采购业务的发展遵循一些规律:采购从一开始围绕"供应商"开展,逐渐发展成围绕"货物"进行,如今围绕"供应商协同"和"采购流程管理&q ...
- 容器化|自建 MySQL 集群迁移到 Kubernetes
背景 如果你有自建的 MySQL 集群,并且已经感受到了云原生的春风拂面,想将数据迁移到 Kubernetes 上,那么这篇文章可以给你一些思路. 文中将自建 MySQL 集群数据,在线迁移到 Kub ...
- golang 实现笛卡尔积(泛型)
背景 input: [[a,b],[c],[d,e]] output: [[a,c,d],[a,c,e],[b,c,d],[b,c,e]] 思路:分治 预处理第一项:[a,b] -> [[a], ...
- Docker 部署 RocketMQ Dledger 集群模式( 版本v4.7.0)
文章转载自:http://www.mydlq.club/article/97/ 系统环境: 系统版本:CentOS 7.8 RocketMQ 版本:4.7.0 Docker 版本:19.03.13 一 ...
- Docker Compose配置文件详解(V3)
Docker Compose配置文件是Docker Compose的核心,用于定义服务.网络和数据卷.格式为YAML,默认路径为./docker-compose.yml,可以使用.yml或.yaml扩 ...
- 详解JS中 call 方法的实现
摘要:本文将全面的,详细解析call方法的实现原理 本文分享自华为云社区<关于 JavaScript 中 call 方法的实现,附带详细解析!>,作者:CoderBin. 本文将全面的,详 ...
- 如何理解「数字化是 IT 公司在给传统企业贩卖焦虑」?
焦虑,不是IT公司贩卖给传统企业的!这个论断本身就不成立!数字化的动因是企业内部,生产中的七大浪费还不够么?数据不畅导致的决策失败还少吗?去问下企业业主,诸如此类的问题多了去了,数字化服务商只是来帮着 ...
- C++面向对象编程之C++11语法糖
1.variadic template(模板参数可变化) template... type就是说有可变模板参数,作为参数使用时类型就是 类型后 + ... ,例如type... / type& ...
- Dropout----Dropout来源
目录 一.简单介绍及公式 二.为什么dropout有效-原因定性分析 2.1 ensemble论 2.1.1 ensemble 2.1.2 动机:联合适应(co-adapting) 思考: 2.1.3 ...