(四)REDIS-布隆过滤器及缓存
(一)布隆过滤器
布隆过滤器(英语,Bloom Filter)是1970年由布隆提出的。它实际是一个很长的二进制数组+多个随机Hash算法映射函数,主要用于判断一个元素是否在集合中。
通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,HashTable)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会线性增长,最终达到瓶颈。同时检索越来越慢,上述三种结构的检索时间复杂度分别为O(n), O(logn),O(1).这个时候,布隆过滤器应运而生。
布隆过滤器的特点:
1 高效地插入与查询,占用空间少,返回的结果是不确定性的。
2 一个元素如果判断为存在的时候不一定存在,但是如果判断为不存在时则一定不存在。
3 布隆过滤器可以添加元素,但是不能删除元素。因为删除元素会导致误判率增加。
4 误判只会发生在过滤器没有添加过的元素,对于添加过的元素不会发生误判。
布隆过滤器主要解决缓存穿透的问题:
缓存穿透:一般情况下,先查询redis是否有该条数据,缓存中没有时再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。
带来的问题:当有大量请求查询数据不存在时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题:把已经存在的数据的key存在布隆过滤器中,相当于redis前面挡着一个布隆过滤器。
当有新的请求时,先到布隆过滤器中查询是否存在。如果布隆过滤器中不存在该条数据则直接返回。如果布隆过滤器中存在(可能存在),才去查询redis,如果redis没有查询到则穿透到数据库。因此对于不存在的直接过滤,对于可能存在的,只有极小一部分会因为误判穿透到数据库。如果要穿透,要求非常严格,即这个key经过多个Hash后都有冲突,最后被误判为存在。
布隆过滤器的原理:
Java中传统hash 容易出现hash冲突。
布隆过滤器实质是一个大型为数组和几个不同的无偏(分布均匀)的hash函数。
添加key值时,使用多个hash函数对key进行hash运算得到一个整数索引值,对为数组长度进行取模运算得到一个位置。
每个hash函数会的带一个不同的位置,将这几个位置置1就完成了add操作。
查询key时,只要其中一位是0就表示这个key不存在,但如果都是1,则不一定存在对应的Key.
当有变量被加入集合时,通过N个映射函数将这个变量映射成位图中的N个点。把他们位置置为1(假定有两个变量都通过3个映射函数)
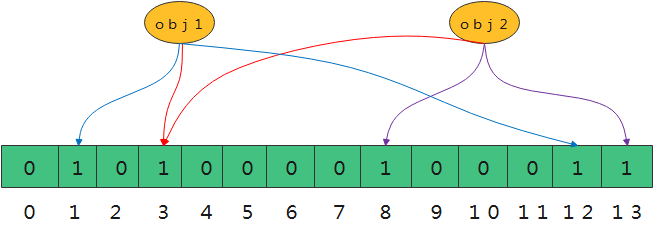
在查询某个变量的时候我们只要看看这些点是不是都是1,即可大概率知道集合中有没有这个变量了。
同时,我们布隆过滤器可以添加元素,但是不能删除元素。因为删除元素会导致误判率增加。比如图中,我们将obj1删除,则位置1 3 12都会变为0,但是Obj2共有位置3,这个时候查询obj2时发现位置3的值为0,就会判定不存在obj2,就会造成误判。
(二)缓存问题
2.1 缓存雪崩:
发生场景:1 redis主机挂了,Redis全盘崩溃。 2 比如缓存中有大量数据同时过期。3 内存达到阙值,内存淘汰机制删除了一些数据。
解决办法:
redis缓存集群实现高可用 主从+ 哨兵。 redis cluster
emcache 本地缓存 + Hystrix 或者阿里sentinel限流 + 降级
开启redis持久化机制aof/rdb, 尽快恢复缓存集群。
提前规划好缓存的到期时间
2.2 缓存穿透:
请求去查询一条记录,先redis然后mysql发现都查询不到该条记录,但是请求每次都会到数据库查询,导致后台数据库压力暴增,这种现象我们称为缓存穿透,如此redis几乎成为了摆设。
数据库没有,redis也没有。直接绕过了redis.
危害:第一次来查询后,如果我们有回写机制,第二次来查的时候就有了,偶尔出现穿透现象无关紧要。如果没有回写,下次继续穿透。
解决方案:
方案1 :一旦发生缓存穿透,我么就可以针对查询的数据,在redis中缓存一个空值或是和业务层协商确定的缺省值。紧接着,应用发送的后续请求再进行查询时,就可以直接从redis中读取空值或者缺省值,返回给业务应用了。避免了把大量请求发送给数据库处理,保持了数据库的正常运行。这种方法可以杜绝相同key的反复请求。针对于大量不同的key,还是存在缓存穿透的问题。
方案2:google guava解决缓存穿透
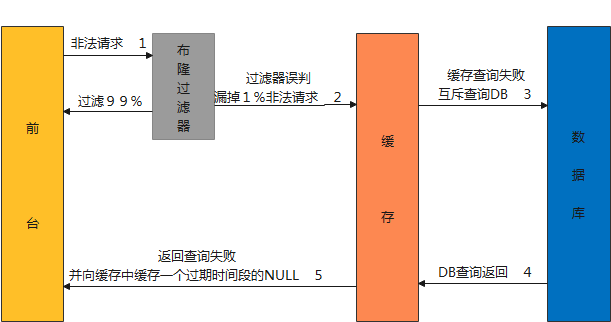
以上场景为布隆过滤器做白名单使用:白名单里有的才让通过,没有直接返回,但是存在误判由于误判率很小,mysql可以接受。使用时需注: 所有key需要往redis和布隆过滤器里面放入。
布隆过滤器做黑名单使用:
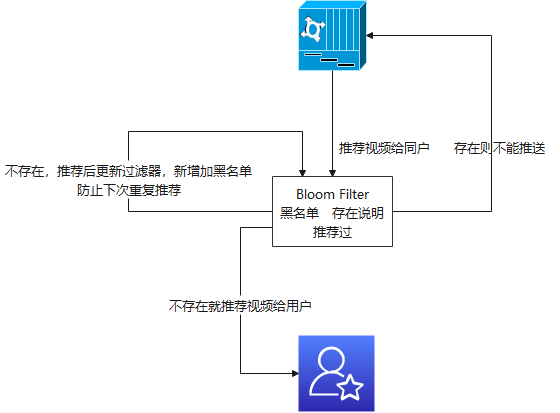
2.3 缓存击穿:
大量的请求同时请求一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库。简单来说就是热点key突然失效了,暴打mysql. 可能布隆过滤器存在,但是此时redis的key突然失效.
数据库有,redis之前有,但是突然没有。
危害:会造成某一时刻,数据库的访问点突然暴增。
解决方法:
互斥更新,随机退避,差异化失效时间。
1 新建
开辟两块内存,主A从B,先更新B,在更新A,严格按照这个顺序
2 查询
先查询主缓存A,如果A没有(消失或者失效)再查询从缓存B。
从B先删除,然后从数据库加载,时间设置20天。
主A后删除,然后从数据加载,时间设置15天。
如果主A到期,但是从B还存在。
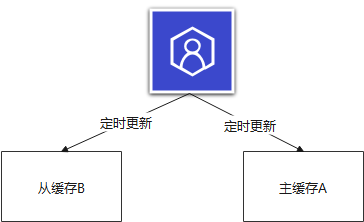
对于频繁访问的key,干脆就不设置过期时间
互斥独占锁防止击穿 (多个线程同时去查询这条数据,在第一个查询的请求上使用一个互斥锁来锁住它,其它线程只有等到第一个线程查询到数据,然后缓存。后面的线程进来后发现已经有缓存 了,就直接走缓存)
public User findUserById(Integer id)
{
User user = null;
String key = "user:"+id; //1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user != null){
return user;
}
//双重检测机制
if(user == null)
{
//2 对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
//这里让之前在外面等待的线程随后进来后可以直接走缓存,前提是前面有线程回写。
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据),
if (user == null) {
//4 查询mysql拿数据
user = userMapper.selectByPrimaryKey(id);//mysql有数据默认
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
return user;
}
}
}
}
}
关于双重检测机制:
双重检测机制可以解决Redis缓存热点key失效(缓存击穿)的问题,但是可能存在线程安全的问题。在使用双重检测机制时,针对于被检测的对象,如果是全局变量,则要考虑该变量后续操作的原子性。最好是通过valatile关键字进行修饰,当然如果是基本类型如int,bool,long,则可以用Actomicxxx来进行定义如ActomicLong。当然最笨重的方法是对整体的方法加synchronized。
(四)REDIS-布隆过滤器及缓存的更多相关文章
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- Redis 布隆过滤器
1.布隆过滤器 内容参考:https://www.jianshu.com/p/2104d11ee0a2 1.数据结构 布隆过滤器是一个BIT数组,本质上是一个数据,所以可以根据下标快速找数据 2.哈希 ...
- Redis布隆过滤器和布谷鸟过滤器
一.过滤器使用场景:比如有如下几个需求:1.原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存入数据库中,进行数据库查询,准 ...
- 使用BloomFilter布隆过滤器解决缓存击穿、垃圾邮件识别、集合判重
Bloom Filter是一个占用空间很小.效率很高的随机数据结构,它由一个bit数组和一组Hash算法构成.可用于判断一个元素是否在一个集合中,查询效率很高(1-N,最优能逼近于1). 在很多场景下 ...
- Redis详解(十三)------ Redis布隆过滤器
本篇博客我们主要介绍如何用Redis实现布隆过滤器,但是在介绍布隆过滤器之前,我们首先介绍一下,为啥要使用布隆过滤器. 1.布隆过滤器使用场景 比如有如下几个需求: ①.原本有10亿个号码,现在又来了 ...
- Redis布隆过滤器与布谷鸟过滤器
大家都知道,在计算机中,IO一直是一个瓶颈,很多框架以及技术甚至硬件都是为了降低IO操作而生,今天聊一聊过滤器,先说一个场景: 我们业务后端涉及数据库,当请求消息查询某些信息时,可能先检查缓存中是否有 ...
- 关于布隆过滤器,手写你真的知其原理吗?让我来带你手写redis布隆过滤器。
说到布隆过滤器不得不提到,redis, redis作为现在主流的nosql数据库,备受瞩目:它的丰富的value类型,以及它的偏向计算向数据移动属性减少IO的成本问题.备受开发人员的青睐.通常我们使用 ...
- Redis05——Redis高级运用(管道连接,发布订阅,布隆过滤器)
Redis高级运用 一.管道连接redis(一次发送多个命令,节省往返时间) 1.安装nc yum install nc -y 2.通过nc连接redis nc localhost 6379 3.通过 ...
- 详细解析Redis中的布隆过滤器及其应用
欢迎关注微信公众号:万猫学社,每周一分享Java技术干货. 什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告 ...
- Redis中的布隆过滤器及其应用
什么是布隆过滤器 布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在.当布隆过滤器说,某种东西 ...
随机推荐
- Python控制台输出字体颜色及背景设置
python 可以利用命令输出带有特效的控制台字体 基础语法 Python利用'\033[<style CODE>;<fore color CODE>;< back co ...
- linux 下安装django时出的错误
解决方法 找到widgets.py 之后vim widgets.py 找到出错语句: 去掉末尾那个逗号即可.
- Callback/Callable类型
自PHP5.4起可用callable类型指定回调类型callback. 一些函数如call_user_func()或usort()可以接受用户自定义的回调函数作为参数.回调函数不止可以是简单函数,还可 ...
- NRF52832中文资料+蓝牙芯片
[产品应用] Nordic Semiconductor发布采用微型封装尺寸的高性能单芯片低功耗蓝牙SoC器件,瞄准新一代可穿戴产品和空间受限的loT应用.[产品说明]nRF52832晶圆级芯片尺寸封装 ...
- JAVA JAR包注册成服务,开机启动,WINSW使用
1,下载工具 WINSW. https://www.aliyundrive.com/s/fACj3xk8R74 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画 ...
- Qt 中文编译错误和运行显示乱码
Qt 中文编译错误 Qt error: C2001: 常量中有换行符 解决方法:菜单 --> 编辑 --> 选择编码(select Encoding)--> 文本编码 --> ...
- 外卖小项目(SpringBook)
一.创建项目,配置maven 二.写配置文件application.yml 三.编写项目启动类 四.设置静态资源路径 基础环境搭建完毕
- [Swift]Swift图片显示方式设置,控件UIImageView的contentMode属性设置
contentMode属性是用来设置图片在UIImageView中的显示方式,如:拉伸.居中.填充等. 这里讨论的是UIImageView宽高固定,图片宽高不确定的情况.如社交APP的相册缩略图.手机 ...
- 前端之Vue day07 混入、插件、elementui、Router、Vuex
一.Props补充 1.父传子在子组件标签上起自定义属性 使用数组 就不演示了,太简单了 2.限制传入的数据类类型 使用对象 同样,展示过的 3.props补充 就是套对象,加以限制 props:{ ...
- 使用layui实现分页展示数据库的数据
layui是一个前端 UI 框架,内置了js代码,所以我们可以直接使用内置的分页 首先要用到layui的官网手册https://www.layui.com/ 1.进入手册页面的 "示例&qu ...