python模块详情与开发规范
循环导入
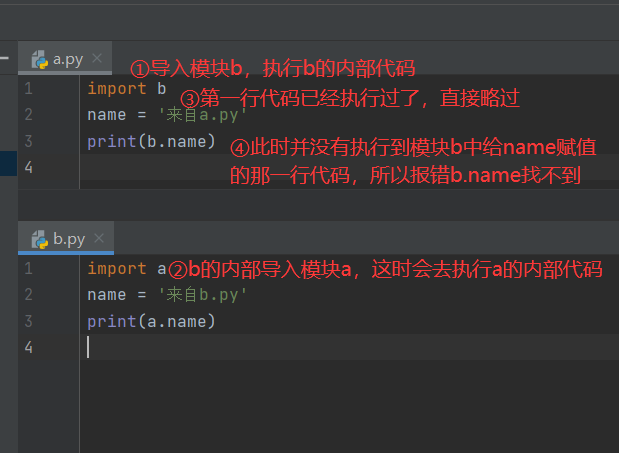
在初学模块时,我们有些时候会出现两个文件彼此导入,这时候可能会有报错。
比如有以下两个py文件
a.py
import b
name = '来自a.py'
print(b.name)
b.py
import a
name = '来自b.py'
print(a.name)
此时无论是执行a.py或是b.py都会报错,这是因为某个名字还没有被创建就被使用了。
解决办法
- 将导入模块的句式写在定义名字的下面
# 修改b.py文件为
name = '来自b.py'
import a # 放在定义名字的下面
print(a.name)
"""此时运行a.py文件就不会报错了,想要运行b.py文件就要修改a.py里的代码"""
- 将导入模块的句式写在函数体代码内
# 修改b.py文件为
# 修改b.py文件为
def index():
import a
print(a.name)
name = '来自b.py'
"""此时a.py中想要使用b.py里的名称就不会报错了"""
所以在编程过程中,循环导入问题我们一定要尽量去避免出现。

py文件类型
python文件可以被分为两种类型
- 执行文件
- 被导入文件
我们可以让py文件输出内置变量__name__来查看此时的文件是执行文件还是被导入文件。
创建a.py文件
print(__name__)
创建b.py文件
import a
执行a.py,执行结果:
__main__
执行b.py,执行结果:
a
可以看出,如果是执行文件时,输出__name__变量的值为__main__,而如果是被导入文件时,输出__name__变量的值为被导入文件的名称。
所以我们一般会利用这一结果用于区分被导入的代码和测试代码
if __name__ == '__main__':
代码块
"""
如果此文件是执行文件的时候才会执行if里面的代码
被别的文件导入的时候不会执行if里面的代码
"""

模块的查找顺序
模块查找顺序:内存空间-->内置模块-->sys.path中(类似于环境变量)。
在导入一个模块时,如果该模块已加载到内存空间中,就可以直接引用;在内存空间找不到该模块时,就会去内置模块中寻找,还是找不到的话就会去sys.path中查找,都找不到时就会报错。
sys.path的内容
# 导入模块sys
import sys
print(sys.path) # 输出sys.path
sys.path里的内容是一个列表,列表里面存放了很多路径。当内存中和内置中都没有要查找的模块时,就会去sys.path里的路径中挨个查找。
案例
创建如下文件和文件夹
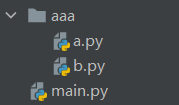
a.py
import b
name = '来自a.py'
print(b.name)
b.py
name = '来自b.py'
main.py
import a
print(a.name)
此时运行main.py会报错说找不到a,因为导模块时没有在内存、内置和sys.path中找到a。
解决办法一:使用sys.path.append添加路径
修改main.py
import sys
sys.path.append(r'.\aaa') # 添加文件夹aaa的路径即可
import a
print(a.name)
解决办法二:使用from...import...句式查找
修改main.py
from aaa import a
print(a.name)
但是此时运行main.py文件还是会报错,说模块b找不到啦,这是因为a.py执行代码导入模块b,查找模块b是按照main.py的sys.path路径查找的,所以会找不到b,所以还要修改a.py文件代码
修改a.py
from aaa import b
name = '来自a.py'
print(b.name)
这时候就没有问题啦!

相对导入与绝对导入
在导入模块的时候一切查找模块的句式都是以执行文件的路径为准,无论导入的句式是在执行文件中还是在被导入文件中。
绝对导入
永远按照执行文件所在的路径一层层往下查找。
如下图:
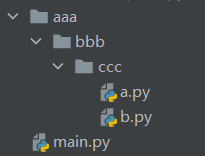
如果main.py想要导入a.py,并使用绝对导入
# main.py代码
from aaa.bbb.ccc import a
相对导入
相当导入打破了必须参照执行文件的所在路径的要求,只需要考虑当前模块所在的路径然后使用特殊符号"."去查找其他模块即可。
.表示当前路径
..表示上一层路径
../..表示上上一层路径
如下图:
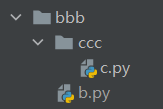
如果我想让在ccc文件夹中的c.py中想要导入b.py
# c.py代码
from .. import b
注意:相对导入只能在被导入文件中使用,不能在执行文件中使用。
包
从专业角度讲:包就是内部含有__init__.py的文件夹。
从实际角度讲:包就是多个模块的结合体(内部存放了多个模块文件)。
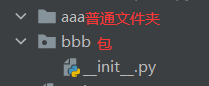
在导入普通文件夹里面的模块时,需要用绝对导入或者是给sys.path添加路径,但是导入包里面的模块时,是不需要这么做的,设计好__init__.py文件后,只要用import + 包名就可以了。
创建如下目录结构
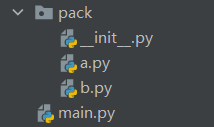
a.py
name = '来自a.py'
b.py
name = '来自b.py'
__init__.py
from . import a
from . import b
name_from_a = a.name
name_from_b = b.name
main.py
import pack
print(pack.name_from_a)
print(pack.name_from_b)
执行main.py结果
来自a.py
来自b.py
以上是包的使用方法,当然了,你也可以把包当成普通文件夹使用。
软件开发目录规范
其实软件开发的过程中,都是有规范的,哪个文件该放哪些文件夹都是需要注意的,这样才方便管理项目。

规范:
bin文件夹
存放程序的启动文件,如run.py之类的
conf文件夹
存放程序的配置文件,如settings.py之类的
core文件夹
存放程序的核心业务,实现具体需求的代码都放在里面
lib文件夹
存放程序公共的功能,如自定义模块之类的
db文件夹
存放程序的数据,比如用户信息之类数据会存放在这
log文件夹
存放程序的日志记录,如程序的报错信息、运行时间的信息存放在这
reademe文本文件
存放程序的说明、使用方法等额外的信息
requirements.txt文本文件
存放程序需要使用的第三方模块及对应的版本
特殊说明
目录的名字可以不一致,但是主要的思想是一致的,就是为了方便管理项目。

python模块详情与开发规范的更多相关文章
- Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型)
Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型) 一丶软件开发规范 六个目录: #### 对某 ...
- Python 入门之 软件开发规范
Python 入门之 软件开发规范 1.软件开发规范 -- 分文件 (1)为什么使用软件开发规范: 当几百行--大几万行代码存在于一个py文件中时存在的问题: 不便于管理 修改 可读性差 加载速度慢 ...
- import模块/包--软件开发规范
一. 模块 模块:就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. import加载的模块分为四个通用类别: 1 使用python编写的代码(.py文件) 2 已被编译 ...
- 扩展Python模块系列(一)----开发环境配置
本系列将介绍如何用C/C++扩展Python模块,使用C语言编写Python模块,添加到Python中作为一个built-in模块.Python与C之间的交互目前有几种方案: 1. 原生的Python ...
- python模块导入-软件开发目录规范-01
模块 模块的基本概念 模块: # 一系列功能的结合体 模块的三种来源 """ 模块的三种来源 1.python解释器内置的模块(os.sys....) 2.第三方的别人写 ...
- python基础-软件目录开发规范
为什么要设计好目录结构? "设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题.对于这种风格上的规范,一直都存在两种态度: 一类同学认为,这种个人风 ...
- python基础学习笔记——开发规范
> 编码 1 2 3 4 5 所有的 Python 脚本文件都应在文件头标上 # -*- coding:utf-8 -*- 用于设置编辑器,默认保存为 utf-8 格式. > 注释 ...
- CSIC_716_20191115【内置函数、递归、模块、软件开发规范】
内置函数 map map映射:语法结构(函数对象,可迭代对象) 依次从可迭代对象中取值,然后给函数做运算,再依次返回运算的结果. ss = map(lambda x: x + x, [1, 2, 3] ...
- python之模块、包的导入过程和开发规范
摘要:导入模块.导入包.编程规范 以My_module为例,My_module的代码如下: __all__ = ['name','read'] print('in mymodule') name = ...
随机推荐
- led指示灯电路图大全(八款led指示灯电路设计原理图详解)
led指示灯电路图大全(八款led指示灯电路设计原理图详解) led指示灯电路图(一) 图1所示电路中只有两个元件,R选用1/6--1/8W碳膜电阻或金属膜电阻,阻值在1--300K之间. Ne为氖泡 ...
- 【静态页面架构】CSS之链接和图像
CSS架构 一.链接: 链接元素:通过使用a元素的href属性设置跳转到指定页面地址 <style> a{ color: blue; text-decoration: none; } a: ...
- 推荐一款强大的轻量级模块化WEB前端快速开发框架--UIkit
前言 今天给大家分享一款强大的轻量级模块化WEB前端快速开发框架--UIkit 到目前(2016-06-20)为止,UIkit在github上的Forks已达到了1350个,而Stars更是达到了69 ...
- SphinxJS——把字符串编码成png图片的超轻量级开源库
体验地址:https://jrainlau.github.io/sp...项目地址:https://github.com/jrainlau/s... SphinxJS 一个能够把字符串编码成png图片 ...
- 用纯CSS实现优雅的tab页
说明 又是一个练手的小玩意儿,本身没什么技术含量,就是几个不常用的CSS3特性的结合而已. 要点 Label标签的for属性 单选框的:checked伪类 CSS的加号[+]选择器 效果图 原理 通常 ...
- oracle数据库存储过程中的select语句的位置
导读:在oracle数据库存储过程中如果用了select语句,要么使用"select into 变量"语句要么使用游标,oracle不支持单独的select语句. 先看下这个存储过 ...
- [ Terminal ] 在 Windows Terminal 中使用 Git Bash
https://www.cnblogs.com/yeungchie/ Git 自带的 git-bash 太简陋了,ConEmu 又太卡了,还是这个 Windows Terminal 最好用. 安装 W ...
- Struts2-day2总结
一.结果页面配置 1.全局结果页面 2.局部结果页面 ****注:如果同时配置了全局页面和局部页面配置,那么最终将以局部为准 result标签当中的type属性 默认值:dispatcher做转发 r ...
- Markdown基础语法规则
你好,世界.粗体,斜体,测试,弟弟,H2O 论文题目 一级标题 二级标题 三级标题 1 2 3 点击此链接打开网址 公式 \(y = \sin x\) \[ y = \frac{1}{x} \] dd ...
- Codeforces Round #742 (Div. 2) B. MEXor Mixup
题目链接 Problem - B - Codeforces 题意: 给出MEX 和 XOR(分别表示1. 本串数不存在的最小非负数 2. 本串数所有数异或后的结果) 求出这串数最少有几个数, 1 ≤ ...