STL空间分配器源码分析(三)pool_allocator
一、摘要
pool_allocator是一种基于单锁内存池的空间分配器,其内部采用内存池思想,通过构建16个空闲内存块队列,来进行内存的申请和回收处理。每个空闲队列管理的内存块大小固定,且均为8的倍数,范围从8到128字节,按8的倍数递增。该空间分配器最小分配单位为8字节,低于128字节(含128)的内存块申请,采用内存池分配策略,高于128字节的内存块申请,直接从操作系统new申请。
内存池示意图:
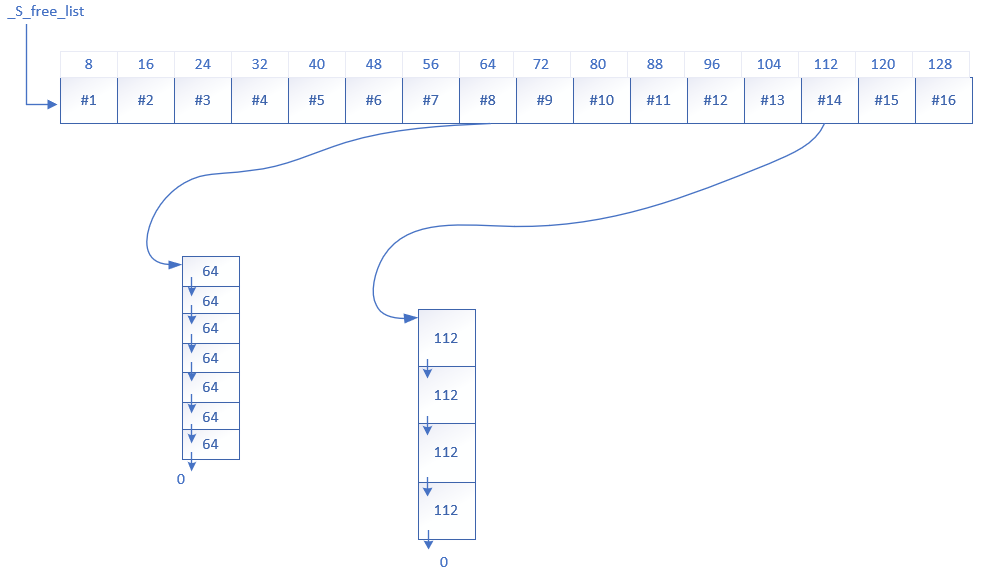
二、内存池实现
class __pool_alloc_base
{
typedef std::size_t size_t; protected:
enum { _S_align = 8 };
enum { _S_max_bytes = 128 };
enum { _S_free_list_size = (size_t)_S_max_bytes / (size_t)_S_align }; union _Obj
{
union _Obj* _M_free_list_link; // 指向下一个内存块
char _M_client_data[1]; // 表示该Obj也即是内存块.
}; static _Obj* volatile _S_free_list[_S_free_list_size]; // 指针数组,指向16个空闲队列链表起始地址, static char* _S_start_free; // 未归空闲队列的堆内存起始地址
static char* _S_end_free; // 未归空闲队列的堆内存末端地址
static size_t _S_heap_size; // 总共申请的堆内存大小 // 向上取整至8的倍数,_S_align等于8
size_t _M_round_up(size_t __bytes)
{ return ((__bytes + (size_t)_S_align - 1) & ~((size_t)_S_align - 1)); } // 根据内存块大小定位空闲链表下标
_GLIBCXX_CONST _Obj* volatile* _M_get_free_list(size_t __bytes) throw (); __mutex& _M_get_mutex() throw (); // 申请n字节大小的内存块,n需为8的倍数,内部可能会填充空闲队列
void* _M_refill(size_t __n); // 尝试申请nobjs个n字节大小的内存块。不一定能申请到nobjs个,最终申请的内存块个数通过nobjs引用出参
char* _M_allocate_chunk(size_t __n, int& __nobjs);
};
内存池的基类__pool_alloc_base主要实现内存池内存管理的细节,包含空闲链表的建立、查找、内存块的申请。其重点在于_M_refill()和_M_allocate_chunk()接口。各成员含义见如上注释。
_M_get_free_list()
__pool_alloc_base::_Obj* volatile* __pool_alloc_base::_M_get_free_list(size_t __bytes) throw ()
{
size_t __i = ((__bytes + (size_t)_S_align - 1) / (size_t)_S_align - 1);
return _S_free_list + __i;
}
内存池通过_M_get_free_list()接口从16个空闲链表中定位到指定空闲链表。因为16个空闲链表管理的内存从8到128字节,按8的倍数按序递增,故可以根据申请的内存大小,定位到链表数组下标。链表数组首地址加上相应的偏移(即下标),即可取到对应的空闲链表。函数内部对申请字节做了向上往8的倍数取整的处理,非8倍数的内存大小申请,最终也是由向上一级的链表管理。
_M_refill()
void* __pool_alloc_base::_M_refill(size_t __n)
{
int __nobjs = 20; // 尝试从堆内存中取出__nobjs个__n字节大小的内存块
char* __chunk = _M_allocate_chunk(__n, __nobjs);
_Obj* volatile* __free_list;
_Obj* __result;
_Obj* __current_obj;
_Obj* __next_obj; // 如果只取出了一个,就返回给上一级,如果取出有剩余,将剩余的内存块存入链表
if (__nobjs == 1)
return __chunk; __free_list = _M_get_free_list(__n); // 第一个内存块返回给上一级
__result = (_Obj*)(void*)__chunk; // 空闲链表指向第二个空闲块
*__free_list = __next_obj = (_Obj*)(void*)(__chunk + __n);
for (int __i = 1; ; __i++)
{
// 这里循环构建空闲链表,每个节点指向一块__n大小的内存块,最后一个节点指向null
__current_obj = __next_obj;
__next_obj = (_Obj*)(void*)((char*)__next_obj + __n);
if (__nobjs - 1 == __i)
{
__current_obj->_M_free_list_link = 0;
break;
}
else
__current_obj->_M_free_list_link = __next_obj;
}
return __result;
}
__M_refill()函数在空闲链表为空情况下会调用(详见下面allocate介绍),它会尝试从堆内存(这里有可能是已经从堆中申请出来的未归入空闲链表管理的大块内存,也可能是直接new,向操作系统申请内存)申请__nobjs个__n大小的内存块,也可能会申请不到__nobjs个。如果申请成功,返回第一个内存块给上层应用,如果申请有剩余,会将剩下的__nobjs-1个内存块用来构建空闲链表。
下列为refill()的操作图示,_M_allocate_chunk(32,4)申请4个32字节的内存块,从内存大块取出4个,一个返回给用户,3个归入链表
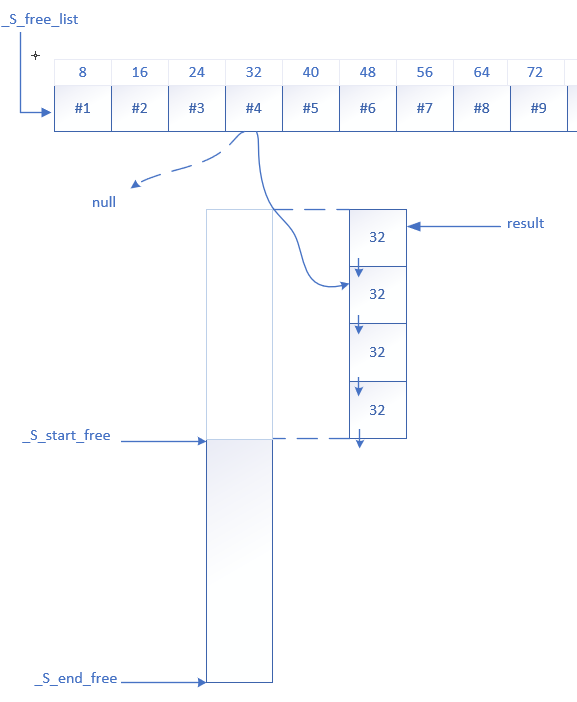
具体的内存申请细节见_M_allocate_chunk()
_M_allocate_chunk()
char* __pool_alloc_base::_M_allocate_chunk(size_t __n, int& __nobjs)
{
// __total_bytes为总申请内存大小,__bytes_left为大块内存剩余的内存大小
char* __result;
size_t __total_bytes = __n * __nobjs;
size_t __bytes_left = _S_end_free - _S_start_free; // 情况1,如果剩余空间充足,返回内存块,_S_start_free向后偏移
if (__bytes_left >= __total_bytes)
{
__result = _S_start_free;
_S_start_free += __total_bytes;
return __result ;
}
// 情况2,如果剩余空间不足分配__nobjs个内存块,但仍能分配至少一块,此时能分配多少就给多少,_S_start_free向后偏移
else if (__bytes_left >= __n)
{
__nobjs = (int)(__bytes_left / __n);
__total_bytes = __n * __nobjs;
__result = _S_start_free;
_S_start_free += __total_bytes;
return __result;
}
// 情况3,如果一块也分配不了
else
{
// 剩余内存不足分配一块,将其全部归入其他链表,不存在无法归入的情况,因为申请的都是8字节倍数的内存,最终剩余的也是8的倍数
if (__bytes_left > 0)
{
_Obj* volatile* __free_list = _M_get_free_list(__bytes_left);
((_Obj*)(void*)_S_start_free)->_M_free_list_link = *__free_list;
*__free_list = (_Obj*)(void*)_S_start_free;
} // 尝试申请2倍多的内存
size_t __bytes_to_get = (2 * __total_bytes + _M_round_up(_S_heap_size >> 4));
__try
{
_S_start_free = static_cast<char*>(::operator new(__bytes_to_get));
}
__catch(const std::bad_alloc&)
{
// 如果operator new都失败,操作系统堆内存不足了,此时只能想办法从上一级的链表拿内存块
size_t __i = __n;
for (; __i <= (size_t) _S_max_bytes; __i += (size_t) _S_align)
{
// 向上逐级找,找到有空闲内存块的链表,找到后,该内存块作为新的大块内存,
// start和end指针分别指向首端和末端,递归调用_M_allocate_chunk,直至找到满足大小的内存块,并更新__nobjs
_Obj* volatile* __free_list = _M_get_free_list(__i);
_Obj* __p = *__free_list;
if (__p != 0)
{
*__free_list = __p->_M_free_list_link;
_S_start_free = (char*)__p;
_S_end_free = _S_start_free + __i;
return _M_allocate_chunk(__n, __nobjs);
}
}
// 如果所有链表都没有空闲块,此时也没办法了,只能再次抛出异常了
_S_start_free = _S_end_free = 0;
__throw_exception_again;
} // 如果operator new成功,start和end指针分别指向新内存块的首端和末端,递归调用_M_allocate_chunk,
// 直至找到满足大小的内存块,并更新__nobjs
_S_heap_size += __bytes_to_get;
_S_end_free = _S_start_free + __bytes_to_get;
return _M_allocate_chunk(__n, __nobjs);
}
}
了解_M_allocate_chunk()的实现,得先明确如下三个变量的用途
char* __pool_alloc_base::_S_start_free = 0;
char* __pool_alloc_base::_S_end_free = 0;
size_t __pool_alloc_base::_S_heap_size = 0;
指针_S_start_free指向内存块的首部,指针_S_end_free指向内存块的尾端,变量_S_heap_size 记录内存池运行以来从堆空间申请的总内存大小。_S_start_free指向的内存块,初始由operator new向操作系统申请,在整个内存分配的过程中,这个内存大块的空间逐渐减少,但_S_start_free始终都会指向其剩余可用部分的起始地址,而_S_end_free始终指向内存块的尾端。
_M_allocate_chunk()内部分多种情况,进行内存分配:
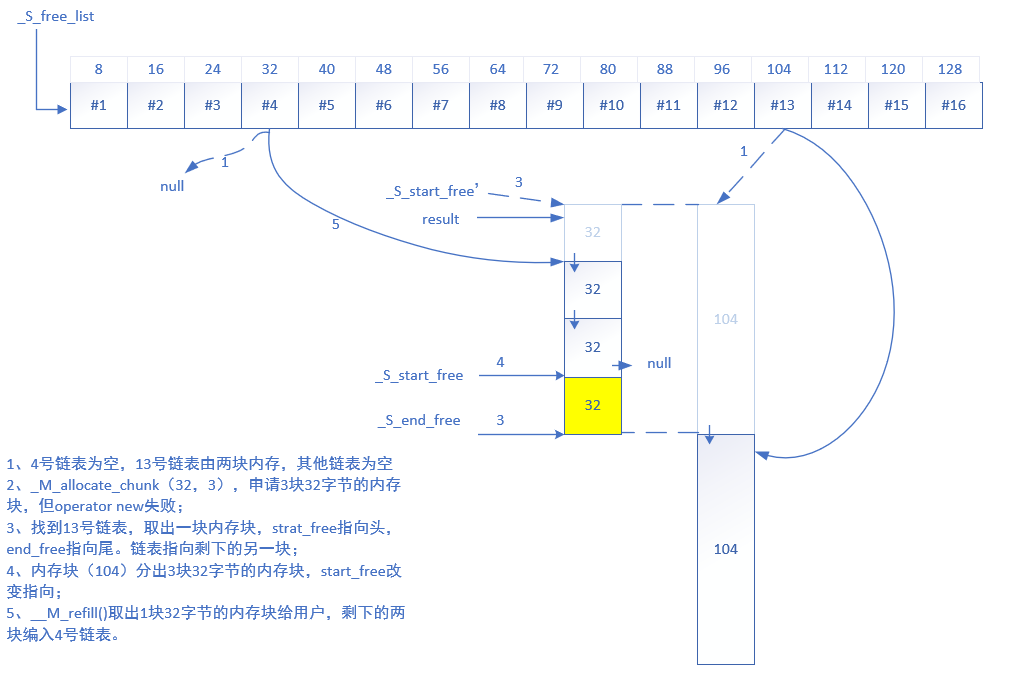
1、初始分配时,即_S_start_free = 0; _S_end_free = 0; _S_heap_size = 0;内存池暂未向系统申请内存。此时无内存可用,进入上述代码情况3的分支,先向操作系统申请内存,申请的大小为需求大小的两倍加_S_heap_size的1/16(每次内存大块没了的时候都会申请这么多)。若申请成功,将申请的内存大块分出需求部分给用户,_S_start_free和_S_end_free调整偏移,记录剩余部分,这时通过递归调用分配用户内存。
2、1场景下递归调用,此时已有内存大块,内存大块充足,进入代码情况1分支,分配内存,同时_S_start_free做好偏移。
3、用户多次申请内存,此时内存大块已不足用户需求,但仍能提供部分内存块。此时进入代码情况2分支,能分多少就给分多少,同时_S_start_free做好偏移。
4、用户再次申请内存,此时内存大块已不能提供一个内存块给用户,此时进入代码情况3分支,先将剩下的内存块归入空闲队列(如果此刻剩内存,那么归入的队列的级别一定是低于当前申请的内存级别的),此时再次回到初始分配,也就是我们上面的步骤1,调用operator new申请内存。
5、假设步骤1operator new申请失败,此时系统已经没内存了,此时还有办法,向上级空闲链表拿内存块出来。如果有的话,_S_start_free指向拿出的内存块,_S_end_free 指向尾端,递归调用,回到上面几个步骤,申请内存。
6、如果步骤5向上级空闲链表拿内存块,但拿不到,都空了,那么这会就毫无办法了,只能抛出异常了。
下图图示为operator new失败的场景
看下__pool_alloc 子类实现
template<typename _Tp>
class __pool_alloc : private __pool_alloc_base
{
private:
static _Atomic_word _S_force_new; public:
typedef std::size_t size_type;
typedef std::ptrdiff_t difference_type;
typedef _Tp* pointer;
typedef const _Tp* const_pointer;
typedef _Tp& reference;
typedef const _Tp& const_reference;
typedef _Tp value_type; template<typename _Tp1>
struct rebind
{ typedef __pool_alloc<_Tp1> other; }; #if __cplusplus >= 201103L
// _GLIBCXX_RESOLVE_LIB_DEFECTS
// 2103. propagate_on_container_move_assignment
typedef std::true_type propagate_on_container_move_assignment;
#endif __pool_alloc() _GLIBCXX_USE_NOEXCEPT { }
__pool_alloc(const __pool_alloc&) _GLIBCXX_USE_NOEXCEPT { } template<typename _Tp1>
__pool_alloc(const __pool_alloc<_Tp1>&) _GLIBCXX_USE_NOEXCEPT { } ~__pool_alloc() _GLIBCXX_USE_NOEXCEPT { } pointer
address(reference __x) const _GLIBCXX_NOEXCEPT
{ return std::__addressof(__x); } const_pointer
address(const_reference __x) const _GLIBCXX_NOEXCEPT
{ return std::__addressof(__x); } size_type
max_size() const _GLIBCXX_USE_NOEXCEPT
{ return std::size_t(-1) / sizeof(_Tp); } #if __cplusplus >= 201103L
template<typename _Up, typename... _Args>
void
construct(_Up* __p, _Args&&... __args)
{ ::new((void *)__p) _Up(std::forward<_Args>(__args)...); } template<typename _Up>
void
destroy(_Up* __p) { __p->~_Up(); }
#else
// _GLIBCXX_RESOLVE_LIB_DEFECTS
// 402. wrong new expression in [some_] allocator::construct
void
construct(pointer __p, const _Tp& __val)
{ ::new((void *)__p) _Tp(__val); } void
destroy(pointer __p) { __p->~_Tp(); }
#endif _GLIBCXX_NODISCARD pointer
allocate(size_type __n, const void* = 0); void
deallocate(pointer __p, size_type __n);
};
其重点在于allocate()和deallocate()的实现
allocate()
template<typename _Tp>
_GLIBCXX_NODISCARD _Tp*
__pool_alloc<_Tp>::allocate(size_type __n, const void*)
{
using std::size_t;
pointer __ret = 0;
if (__builtin_expect(__n != 0, true))
{
// __n超限,抛出异常
if (__n > this->max_size())
std::__throw_bad_alloc(); const size_t __bytes = __n * sizeof(_Tp); #if __cpp_aligned_new
// 内存对齐处理
if (alignof(_Tp) > __STDCPP_DEFAULT_NEW_ALIGNMENT__)
{
std::align_val_t __al = std::align_val_t(alignof(_Tp));
return static_cast<_Tp*>(::operator new(__bytes, __al));
}
#endif if (_S_force_new == 0)
{
if (std::getenv("GLIBCXX_FORCE_NEW"))
__atomic_add_dispatch(&_S_force_new, 1);
else
__atomic_add_dispatch(&_S_force_new, -1);
}
// 申请字节超过128,或指定强制new,则采用operator new方式申请内存
if (__bytes > size_t(_S_max_bytes) || _S_force_new > 0)
__ret = static_cast<_Tp*>(::operator new(__bytes));
else
{
// 根据申请的字节定位到所属空闲链表,后续涉及空闲链表操作,加锁处理
_Obj* volatile* __free_list = _M_get_free_list(__bytes); __scoped_lock sentry(_M_get_mutex());
_Obj* __restrict__ __result = *__free_list;
// 空闲链表为空,调用refill,申请内存并填充空闲链表
if (__builtin_expect(__result == 0, 0))
__ret = static_cast<_Tp*>(_M_refill(_M_round_up(__bytes)));
else
{
// 从该空闲链表取出内存块返回给上层
*__free_list = __result->_M_free_list_link;
__ret = reinterpret_cast<_Tp*>(__result);
}
if (__ret == 0)
std::__throw_bad_alloc();
}
}
return __ret;
}
allocate()先判断申请的内存是否超过内存池限制,或者是否启用强制new,如果是的话,就调用operator new申请内存,否则从内存池取内存块。先根据申请大小定位到对应的空闲链表,如果链表非空,就从链表取内存块,否则,调用_M_refill()申请并填充链表。
deallocate()
template<typename _Tp>
void
__pool_alloc<_Tp>::deallocate(pointer __p, size_type __n)
{
using std::size_t;
if (__builtin_expect(__n != 0 && __p != 0, true))
{
#if __cpp_aligned_new
// 内存对齐处理
if (alignof(_Tp) > __STDCPP_DEFAULT_NEW_ALIGNMENT__)
{
::operator delete(__p, std::align_val_t(alignof(_Tp)));
return;
}
#endif
const size_t __bytes = __n * sizeof(_Tp);
// 同步allocate处理,若申请字节超过128,或指定强制new,采用operator delete释放内存
if (__bytes > static_cast<size_t>(_S_max_bytes) || _S_force_new > 0)
::operator delete(__p);
else
{
// 将内存块回收到对应链表
_Obj* volatile* __free_list = _M_get_free_list(__bytes);
_Obj* __q = reinterpret_cast<_Obj*>(__p); __scoped_lock sentry(_M_get_mutex());
__q ->_M_free_list_link = *__free_list;
*__free_list = __q;
}
}
}
STL空间分配器源码分析(三)pool_allocator的更多相关文章
- STL空间分配器源码分析(二)mt_allocator
一.简介 mt allocator 是一种以2的幂次方字节大小为分配单位的空间配置器,支持多线程和单线程.该配置器灵活可调,性能高. 分配器有三个通用组件:一个描述内存池特性的数据,一个包含该池的策略 ...
- STL空间分配器源码分析(一)
一.摘要 STL的空间分配器(allocator)定义于命名空间std内,主要为STL容器提供内存的分配和释放.对象的构造和析构的统一管理.空间分配器的实现细节,对于容器来说完全透明,容器不需关注内存 ...
- tomcat源码分析(三)一次http请求的旅行-从Socket说起
p { margin-bottom: 0.25cm; line-height: 120% } tomcat源码分析(三)一次http请求的旅行 在http请求旅行之前,我们先来准备下我们所需要的工具. ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
- Duilib源码分析(三)XML解析器—CMarkup
上一节介绍了控件构造器CDialogBuilder,接下来将分析其XML解析器CMarkup: CMarkup:xml解析器,目前内置支持三种编码格式:UTF8.UNICODE.ASNI,默认为UTF ...
- Kafka源码分析(三) - Server端 - 消息存储
系列文章目录 https://zhuanlan.zhihu.com/p/367683572 目录 系列文章目录 一. 业务模型 1.1 概念梳理 1.2 文件分析 1.2.1 数据目录 1.2.2 . ...
- ABP源码分析三:ABP Module
Abp是一种基于模块化设计的思想构建的.开发人员可以将自定义的功能以模块(module)的形式集成到ABP中.具体的功能都可以设计成一个单独的Module.Abp底层框架提供便捷的方法集成每个Modu ...
- ABP源码分析三十一:ABP.AutoMapper
这个模块封装了Automapper,使其更易于使用. 下图描述了改模块涉及的所有类之间的关系. AutoMapAttribute,AutoMapFromAttribute和AutoMapToAttri ...
- ABP源码分析三十三:ABP.Web
ABP.Web模块并不复杂,主要完成ABP系统的初始化和一些基础功能的实现. AbpWebApplication : 继承自ASP.Net的HttpApplication类,主要完成下面三件事一,在A ...
随机推荐
- Linux指令_入门基础
一.基础指令语法 1.ls指令: 用法1:#ls 含义:列出当前工作目录下的所有文件/文件夹的名称. 用法2:#ls 路径 含义:列出指定路径下的所有文件/文件夹的名称 用法3:#ls 选项 路径 含 ...
- jdbc action 接口示例
package com.gylhaut.action; import java.sql.SQLException;import java.util.ArrayList;import java.util ...
- 【算法】两个list合并
转载博客地址 http://blog.sina.com.cn/s/blog_5da93c8f0101fdrp.html 有两个ArrayList,分别为list1和list2,分析这两个list后生成 ...
- java动态代理--代理接口无实现类
转载:https://blog.csdn.net/weixin_45674354/article/details/103246715 1.接口定义: package cn.proxy; public ...
- NO Oracle database,JUST USE Oracle client。远程导入导出dmp
序言: 你会发现,exp.exe 和imp.exe均存在于Oracle数据库的安装bin目录下.而很多情况下,我们不想安装庞大的Oracle数据库,但想使用imp和exp等工具命令,在我们本地机对Or ...
- 深入理解Java虚拟机-HotSpot虚拟机对象探秘
一.对象的创建过程 虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那就先执行相应的类 ...
- Hadoop全分布式
1.安装jdk Linux下安装jdk-7u67-linux-x64.rpm 2.免密登录 ssl免密登录(centos6) 3.同步时间:date -s "2020-04-0 ...
- it-术语
QPS:每秒查询率QPS是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准. 因特网上,经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS. 对应fetches/sec,即每秒的 ...
- 学习RabbitMQ(三)
1 用户注册后(会立即提示注册成功),过一会发送短信和邮件通知 发布/订阅模型 以上模式一般是用户注册成功后,写入一条数据到mysql,在发送一条消息到MQ! 如果不用消息中间件(或者简单的做成异步发 ...
- 学习Squid(一)
第1章 Squid介绍 1.1 缓存服务器介绍 缓存服务器(英文意思cache server),即用来存储(介质为内存及硬盘)用户访问的网页,图片,文件等等信息的专用服务器.这种服务器不仅可以使用户可 ...