Java--集合框架详解
前言
Java集合框架的知识在Java基础阶段是极其重要的,我平时使用List、Set和Map集合时经常出错,常用方法还记不牢,
于是就编写这篇博客来完整的学习一下Java集合框架的知识,如有遗漏和错误,欢迎大家指出。
以下是我整理的大致Java集合框架内容,本篇博客就是围绕以下内容展开
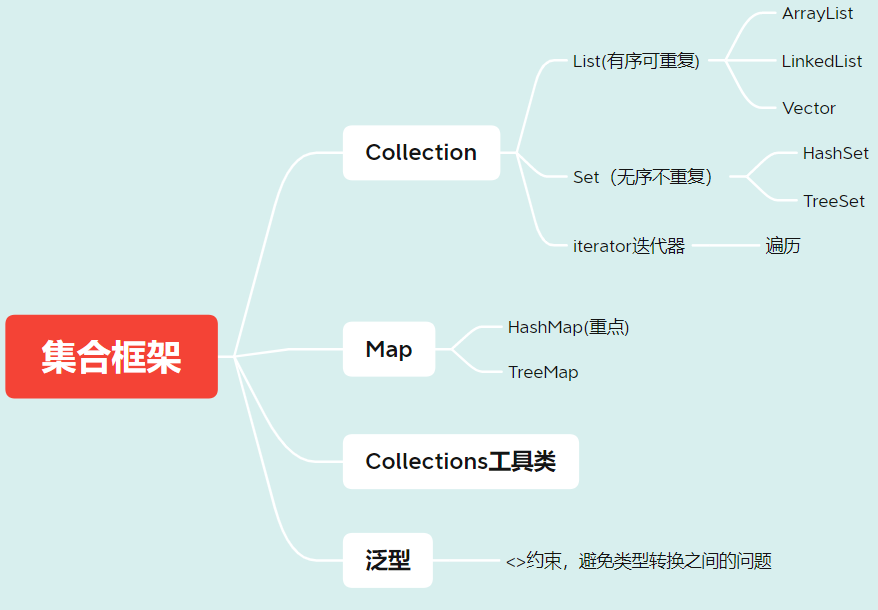
注:本篇博客是根据B站Java集合框架的视频进行编写,视频原地址:【千锋】最新版 Java集合框架详解 通俗易懂
下面我们开始正式学习!!!
1、集合概念
1.1、概念:对象的容器,定义了对多个对象进行操作的常用方法。可实现数组的功能
1.2、集合与数组区别:
数组长度固定,集合长度不固定
数组可以存储基本类型和引用类型,集合只能存储引用类型
1.3、位置:java.util*
2、Collection接口
Collection体系集合
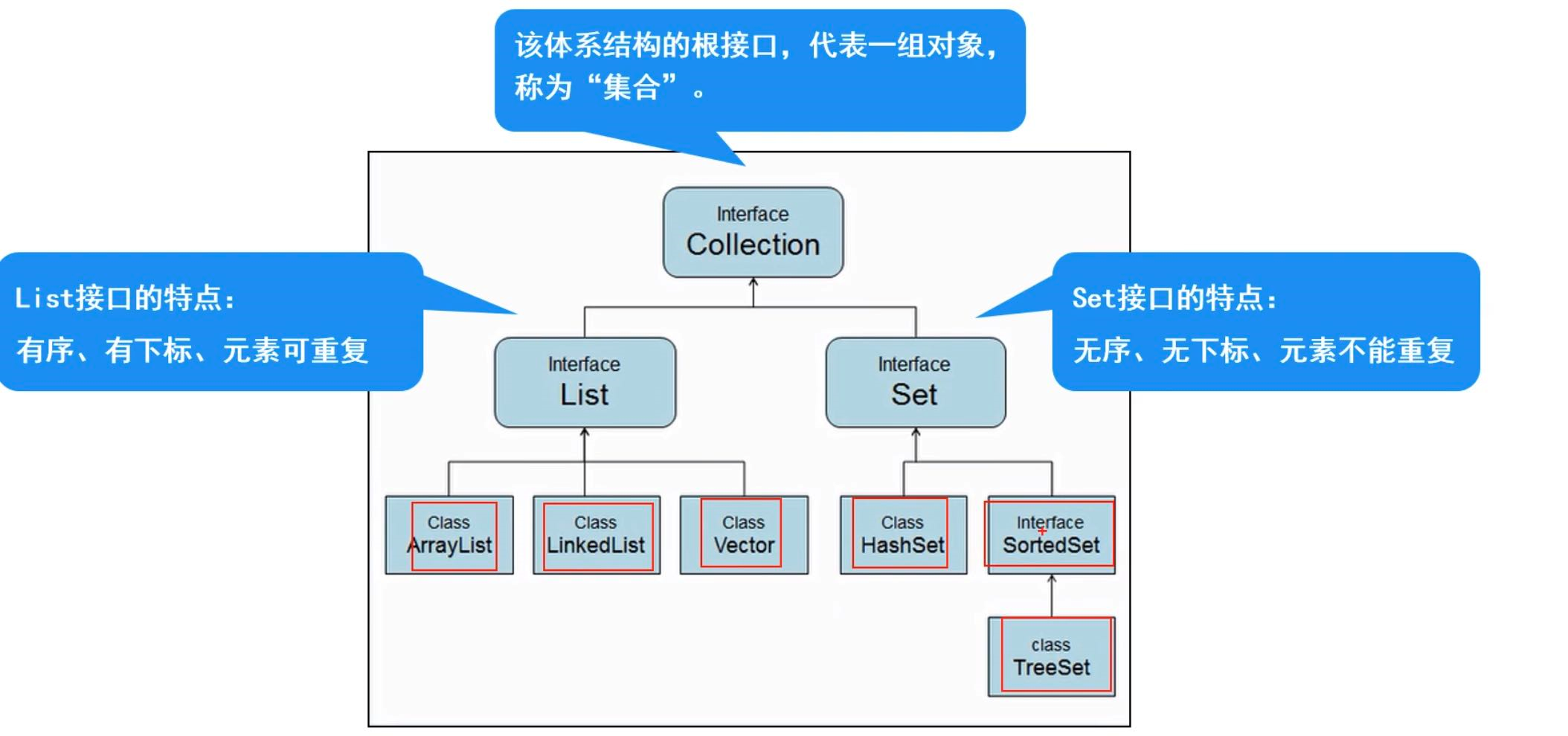
2.1、Collection父接口
特点:代表一组任意类型的对象,无序、无下标、不能重复
方法:

2.2、Collection的使用
(1)Demo1保存字符串(重点关注迭代器iterator的使用)
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Demo1 {
public static void main(String[] args) {
//创建集合
Collection collection = new ArrayList();
//1.添加元素
collection.add("香蕉");
collection.add("苹果");
collection.add("西瓜");
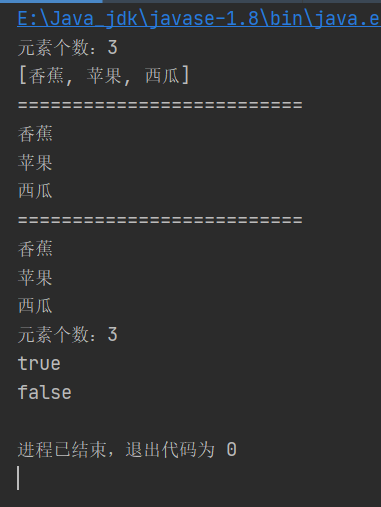
System.out.println("元素个数:"+collection.size());
System.out.println(collection);
//2.删除元素
//collection.remove("香蕉");
//collection.clear();//清除
//System.out.println("删除之后:"+collection.size());
//3.遍历元素(重点)
System.out.println("==========================");
//方法一:增强for
for (Object object:collection) {
System.out.println(object);
}
//方法二:使用迭代器(迭代器专门用来遍历集合的一种方式)
//iterator3个方法
//hasNext();有没有下一个元素
//next();l获取下一个元素
//remove();删除当前元素
System.out.println("==========================");
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
String s = (String) iterator.next();
System.out.println(s);
// collection.remove(s);//不允许使用collection删除会引发并发修改错误,只能使用以下方法移除
//iterator.remove();
}
System.out.println("元素个数:"+collection.size());
//4.判断
System.out.println(collection.contains("香蕉"));
System.out.println(collection.isEmpty());
}
}
结果
(2)Demo2 保存学生信息
学生类
//学生类
public class Student {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
// 保存学生信息
public class Demo2 {
public static void main(String[] args) {
//新建Collection对象
Collection collection = new ArrayList();
Student s1 = new Student("张三",18);
Student s2 = new Student("李四",19);
Student s3 = new Student("王五",21);
//1.添加数据
collection.add(s1);
collection.add(s2);
collection.add(s3);
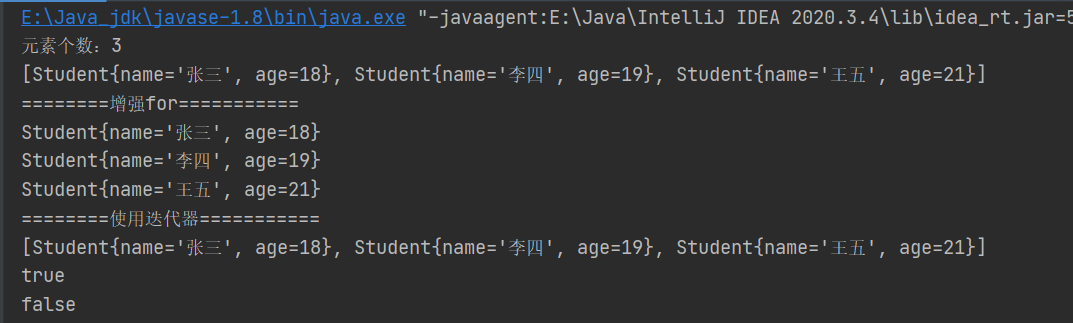
System.out.println("元素个数:"+collection.size());
System.out.println(collection.toString());
//2.删除
//collection.remove(s1);
//System.out.println("删除之后:"+collection.size());
//3.遍历
//方法一:增强for
System.out.println("========增强for===========");
for (Object object:collection) {
Student s = (Student) object;
System.out.println(s.toString());
}
//方法二:使用迭代器(迭代器专门用来遍历集合的一种方式)
System.out.println("========使用迭代器===========");
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
Student s =(Student) iterator.next();
}
System.out.println(collection.toString());
//4.判断
System.out.println(collection.contains(s1));
System.out.println(collection.isEmpty());
}
}
结果
3、List接口与实现类
3.1、List子接口
特点:有序,有下标,元素可以重复
方法:

3.2、List子接口的使用
(1)Demo3
public class Demo3 {
public static void main(String[] args) {
//先创建一个集合对象
List list = new ArrayList();
//1.添加元素
list.add("唱");
list.add("跳");
list.add(0,"打篮球");//下标为0,放在第一位
System.out.println("元素个数:"+list.size());
System.out.println(list.toString());
//2.删除元素
// list.remove("唱");
// list.remove(1);
// System.out.println("元素个数:"+list.size());
// System.out.println(list.toString());
//3.遍历
//方法一:使用for遍历
System.out.println("===========for遍历===============");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//方法二:使用增强for
System.out.println("===========增强for===============");
for (Object o:list) {
System.out.println(o);
}
//方法三:使用迭代器
System.out.println("===========迭代器===============");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//方法四:使用列表迭代器
//和迭代器的区别:可以向前或向后遍历,添加、删除、修改元素
System.out.println("===========列表迭代器===============");
ListIterator lit = list.listIterator();
System.out.println("===========列表迭代器从前往后===============");
while (lit.hasNext()) {
System.out.println(lit.nextIndex()+":"+lit.next());
}
System.out.println("===========列表迭代器从后往前===============");
while (lit.hasPrevious()) {
System.out.println(lit.previousIndex()+":"+lit.previous());
}
System.out.println("==========================");
//4.判断
System.out.println(list.contains("rap"));
System.out.println(list.isEmpty());
//5.获取位置
System.out.println(list.indexOf(2));
}
}
结果
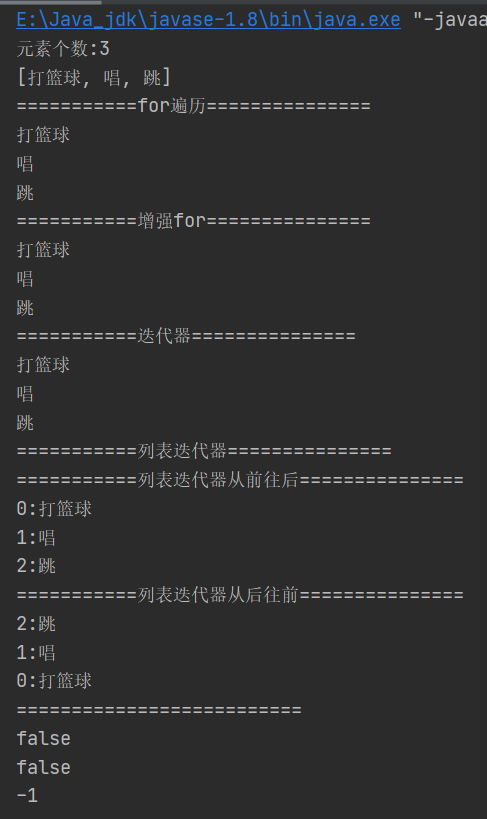
(2)Demo4
public class Demo4 {
public static void main(String[] args) {
//先创建一个集合对象
List list = new ArrayList();
//1.添加数字数据(自动装箱)
list.add(17);
list.add(27);
list.add(37);
list.add(47);
list.add(57);
System.out.println("元素个数:"+list.size());
System.out.println(list.toString());
//2.删除
//注意这里是用脚标删除的,如果要用数字需要转成Object
list.remove(0);
//list.remove((Object) 17);
//list.remove(new Integer(20));
System.out.println("元素个数:"+list.size());
System.out.println(list.toString());
//3.补充方法subList:返回子集合,包含头不包含尾
List subList = list.subList(1, 3);
System.out.println(subList.toString());
}
}
结果:

3.3、List实现类
ArrayList(重点):
- 数组结构实现,查询快,增删慢
- jdk1.2版本后加入,运行效率快,线程不安全
Vector:
- 数组结构实现,查询快,增删慢
- jdk1.0版本后加入,运行效率慢,线程安全
LinkedList:
- 链表结构实现,增删快,查询慢
3.3.1、ArrayList
/**
* ArrayList的使用
* 特点:有序,有下标,可以重复
* 存储结构:数组,查找遍历速度快,增删慢
*/
public class Demo5 {
public static void main(String[] args) {
//创建结合
ArrayList arrayList = new ArrayList();
//1.添加元素
Student s1 = new Student("张三",20);
Student s2 = new Student("李四",23);
Student s3 = new Student("王五",19);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
System.out.println("元素个数:"+arrayList.size());
System.out.println(arrayList.toString());
//2.删除元素
// arrayList.remove(0);
// arrayList.remove(s2);
arrayList.remove(new Student("ooof",12));//这样删除需要在Student中重写 equals(this == obj) 方法
//3.遍历元素【重点】
//使用迭代器
System.out.println("========= 使用迭代器=========");
Iterator it = arrayList.iterator();
while (it.hasNext()) {
Student s =(Student) it.next();
System.out.println(s.toString());
}
//列表迭代器
System.out.println("========= 列表迭代器=========");
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()) {
Student s =(Student) lit.next();
System.out.println(s.toString());
}
System.out.println("========= 列表迭代器逆序=========");
while (lit.hasPrevious()) {
Student s =(Student) lit.previous();
System.out.println(s.toString());
}
//4.判断
System.out.println(arrayList.contains(new Student("王五",19)));
System.out.println(arrayList.isEmpty());
//5.查找
System.out.println(arrayList.indexOf(new Student("王五",19)));
}
}
结果
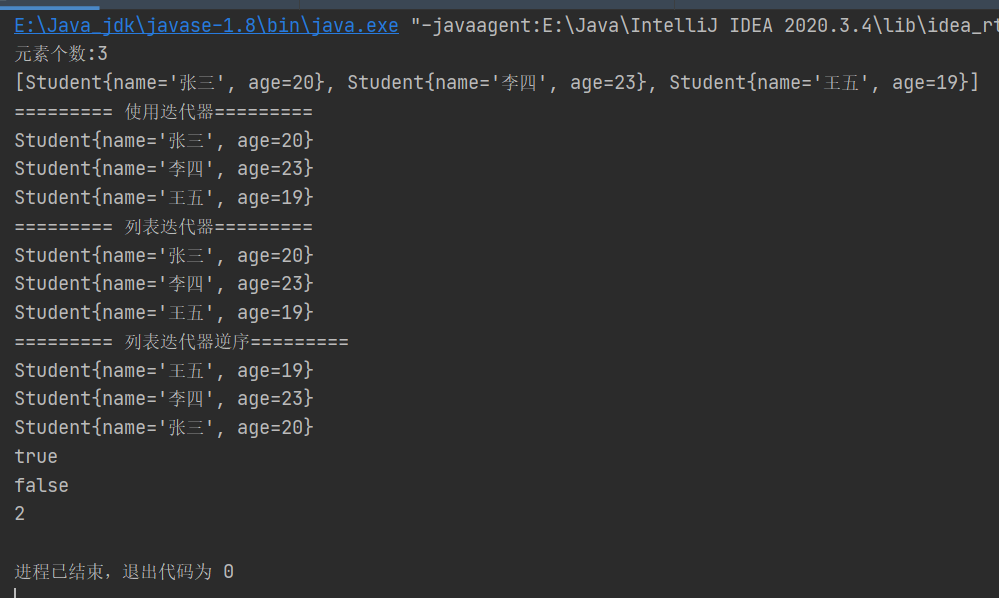
源码分析
默认容量:DEFAULT_CAPACITY = 10;
- 注:如果没有向集合中添加任何元素,容量为0,添加一个元素之后,容量为10,每次扩容大小为原来的1.5 倍
存放元素的数组:elementData
实际元素个数:size
添加元素:add()方法
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
} public void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length
&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
&& minCapacity <= DEFAULT_CAPACITY)) {
modCount++;
grow(minCapacity);
}
} //grow为核心
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
3.3.2、Vector
存储结构:数组
创建集合
Vector vector = new Vector<>();增加(vector.add())、删除(vector.remove)、判断(vector.contains())同上
遍历--枚举器遍历
Enumeration en = vector.elements();
while(en.hasMoreElements()){
String s = (String)en.nextElement();
sout(s);
}
3.3.3、LinkedList
/**
*LinkedList的使用
* 存储结构:双向链表
* 可以重复添加
*/
public class LinkedListTest1 {
public static void main(String[] args) {
//创建集合
LinkedList linkedList = new LinkedList<>();
//1.添加元素
Student s1 = new Student("张三",20);
Student s2 = new Student("李四",23);
Student s3 = new Student("王五",19);
linkedList.add(s1);
linkedList.add(s2);
linkedList.add(s3);
System.out.println("元素个数:"+linkedList.size());
System.out.println(linkedList.toString());
//2.删除
// linkedList.remove(s1);
// System.out.println("删除之后:"+linkedList.size());
//3.遍历
//for遍历
System.out.println("========for=====");
for (int i = 0; i < linkedList.size(); i++) {
System.out.println(linkedList.get(i));
}
System.out.println("========增强for=====");
for (Object object:linkedList) {
Student s = (Student) object;
System.out.println(s.toString());
}
//迭代器
System.out.println("========迭代器=====");
Iterator it = linkedList.iterator();
while (it.hasNext()) {
Student s =(Student) it.next();
System.out.println(s.toString());
}
System.out.println("========列表迭代器=====");
ListIterator lit = linkedList.listIterator();
while (lit.hasNext()) {
Student s =(Student) lit.next();
System.out.println(s.toString());
}
//4.判断
System.out.println(linkedList.contains(s1));
System.out.println(linkedList.isEmpty());
//5.获取
System.out.println(linkedList.indexOf(s1));
}
}
结果
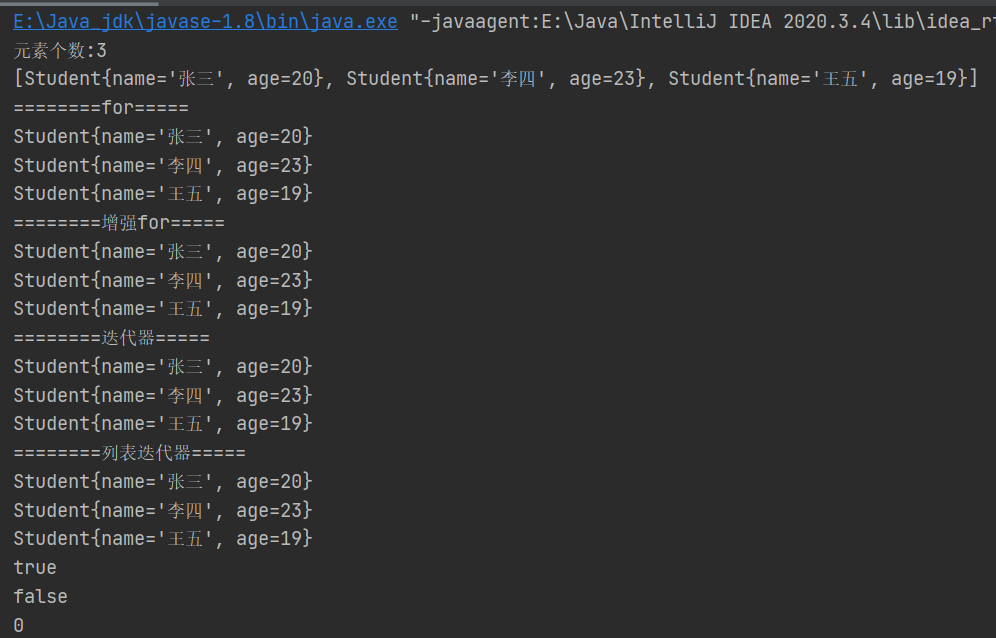
源码分析
transient int size = 0;//集合大小
transient Node<E> first;//头结点
transient Node<E> last;//尾节点
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
3.4、ArrayList与LinkedList的区别
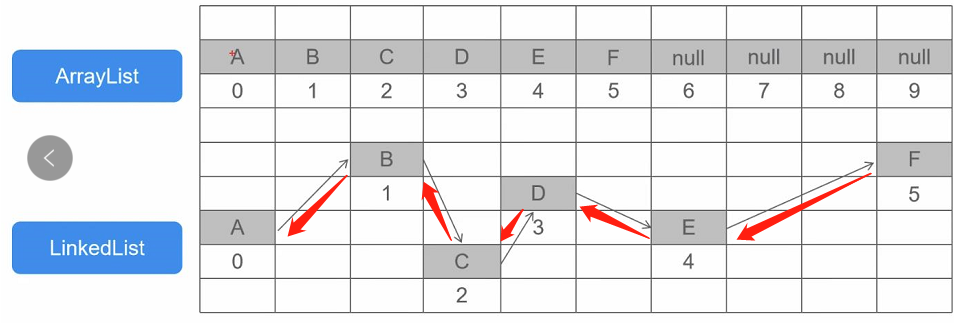
ArrayList:数组,必须开辟连续空间,查询快,增删慢
LinkedList:双向链表,无需开辟连续空间,查询慢,增删快
4、泛型和工具类
泛型
- Java泛型是JDK1.5中引入的一个新特性,其本质是參数化类型,把类型作为参数传递
- 常见形式有泛型类、泛型接口、泛型方法
- 语法:
- <T,...>T称为类型占位符,表示一种引用类型。
- 好处:
- (1)提高代码的重用性
- (2)防止类型转换异常,提高代码的安全性
泛型类
/**
* 泛型类
* 语法:<T>
* T表示类型占位符,表示一种引用类型,如果编写多个用逗号隔开
* */
public class MyGeneric<T> {
//使用泛型T
//1.创建变量,不能new T()因为T数据类型不确定
T t;
//2.创建一个方法,作为方法的参数
public void show(T t){
System.out.println(t);
}
//3.使用泛型作为方法的返回值
public T getT(){
return t;
}
}
public class TestGeneric {
public static void main(String[] args) {
//使用泛型类创建对象
//注意:1.泛型只能使用引用类型,2.不同泛型类型对象之间不能相互赋值
MyGeneric<String> myGeneric = new MyGeneric<String>();
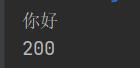
myGeneric.t = "hello";
myGeneric.show("你好");
String t1 = myGeneric.getT();
MyGeneric<Integer> myGeneric2 = new MyGeneric<Integer>();
myGeneric2.t = 100;
myGeneric2.show(200);
Integer t2 = myGeneric2.getT();
}
}
结果:
泛型接口
/**
*泛型接口
* 语法:接口名<T>
* 注意:不能使用泛型来创建静态常量
*/
public interface MyInterface<T> {
String name = "张三";
T server(T t);
}
泛型接口实现有两种方法:
1、指定数据类型
public class MyInterfaceImpl implements MyInterface<String>{
@Override
public String server(String t) {
System.out.println(t);
return t;
}
}
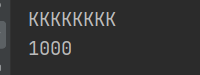
测试
MyInterfaceImpl impl = new MyInterfaceImpl();
impl.server("KKKKKKKK");
2、不指定数据类型
public class MyInterfaceImpl2<T> implements MyInterface<T>{
@Override
public T server(T t) {
System.out.println(t);
return t;
}
测试
MyInterfaceImpl2 impl2 = new MyInterfaceImpl2();
impl2.server(1000);
结果:
泛型方法
/**
*泛型方法
* 语法:<T>返回值类型
*/
public class MyGenericMethod {
//泛型方法
public <T> void show(T t){
System.out.println("泛型方法"+t);
}
}
测试
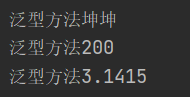
//泛型方法
//不需要指定类型
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.show("坤坤");
myGenericMethod.show(200);
myGenericMethod.show(3.1415);
结果:
泛型集合
- 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
- 特点:
- 编译时即可检查,而非逐行时抛出异常。
- 访问时,不必类型转换(拆箱)。
- 不同泛型之间引用不能相互赋值,泛型不存在多态。
public class DemoCollect {
public static void main(String[] args) {
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("xxx");
arrayList.add("yyy");
//指定String类型一下两条数据就不能添加进去
// arrayList.add(10);
// arrayList.add(20);
for (String str:arrayList) {
System.out.println(str);
}
ArrayList<Student> arrayList2 = new ArrayList<Student>();
Student s1 = new Student("张三",18);
Student s2 = new Student("李四",19);
Student s3 = new Student("王五",21);
arrayList2.add(s1);
arrayList2.add(s2);
arrayList2.add(s3);
Iterator<Student> iterator = arrayList2.iterator();
while (iterator.hasNext()) {
Student s = iterator.next();
System.out.println(s.toString());
}
}
}
测试

5、Set接口与实现类
5.1、Set子接口
特点:无序,无下标,元素不可重复
方法:全部继承自Collecton中的方法
5.2、Set子接口的使用
/**
* 测试Set接口的使用
* 特点:无序,无下标,元素不可重复
*/
public class Demo1 {
public static void main(String[] args) {
//创建集合
HashSet<String> set = new HashSet<>();
//1.添加数据
set.add("唱");
set.add("跳");
set.add("rap");
//set.add("rap");重复添加不进去
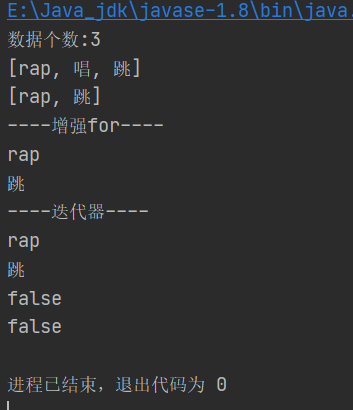
System.out.println("数据个数:"+set.size());
System.out.println(set.toString());
//2.删除
set.remove("唱");
System.out.println(set.toString());
//3.遍历【重点】
System.out.println("----增强for----");
for (String str:set) {
System.out.println(str);
}
System.out.println("----迭代器----");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.println(s);
}
//4.判断
System.out.println(set.contains("打篮球"));
System.out.println(set.isEmpty());
}
}
测试:(注意这里添加的顺序与显示的顺序不同,因为无序)
5.3、Set实现类
- HashSet【重点】:
- 基于HashCode实现元素不重复。
- 当存入元素的哈希码相同时,会调用equalsi进行确认,如结果为true,则拒绝后者存入。
- TreeSet:
- 基于排列顺序实现元素不重复。
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
5.3.1、HashSet
HashSet的使用
(1)Demo2
/***
* HashSet集合的使用
* 存储结构:哈希表(数组+链表+红黑树)
*/
public class Demo2 {
public static void main(String[] args) {
//新建集合
HashSet<String> hashSet = new HashSet<>();
//1.添加元素
hashSet.add("张三");
hashSet.add("李四");
hashSet.add("王五");
hashSet.add("赵六");
System.out.println("数据个数:"+hashSet.size());
System.out.println(hashSet.toString());
//2.删除
hashSet.remove("张三");
System.out.println("删除后数据个数:"+hashSet.size());
System.out.println(hashSet.toString());
//3.遍历
System.out.println("----增强for----");
for (String str:hashSet) {
System.out.println(str);
}
System.out.println("----迭代器----");
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.println(s);
}
//4.判断
System.out.println(hashSet.contains("打篮球"));
System.out.println(hashSet.isEmpty());
}
}
测试
(2)Demo3
person类
public class Person {
private String name;
private int age;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
int n1 = this.name.hashCode();
int n2 = this.age;
return n1+n2;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
if(o instanceof Person){
Person person = (Person) o;
if(this.name.equals(person.getName())&&this.age == person.getAge()){
return true;
}
}
return false;
}
}
Demo3
/***
* HashSet集合的使用
* 存储结构:哈希表(数组+链表+红黑树)
* 存储过程:
* (1)根据hashcode计算保存位置,如果位置为空,则直接保存,如果不为空,执行第二步
* (2)再执行equals方法,如果equals方法为true,则认为是重复,否则形成链表
*/
public class Demo3 {
public static void main(String[] args) {
//新建集合
HashSet<Person> persons = new HashSet<>();
//1.添加元素
Person p1 = new Person("乔纳森-乔斯达",20);
Person p2 = new Person("乔瑟夫-乔斯达",19);
Person p3 = new Person("空条承太郎",16);
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(new Person("空条承太郎",16));//重写hashCode()形成链表,再重写equals()就不能添加进来了
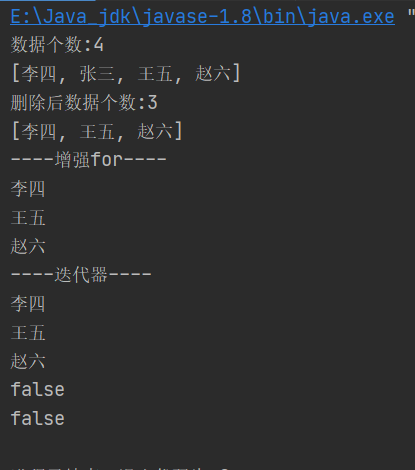
System.out.println("元素个数:"+persons.size());
System.out.println(persons.toString());
//2.删除
// persons.remove(p1);
// persons.remove( new Person("乔纳森-乔斯达",20));//这时可以删除
// System.out.println("删除之后:"+persons.toString());
//3.遍历
System.out.println("------for----");
for (Person person:persons) {
System.out.println(person.toString());
}
System.out.println("------迭代器----");
Iterator<Person> iterator = persons.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//4.判断
System.out.println(persons.contains(p1));
System.out.println(persons.isEmpty());
}
}
测试
5.3.2、TreeSet
(1)简单使用
/**
* TreeSet的使用
* 存储结构:红黑树
*/
public class Demo4 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeSet = new TreeSet<>();
//1.添加元素
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("wer");
treeSet.add("opq");
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet.toString());
//2.删除
treeSet.remove("wer");
System.out.println("删除后元素个数:"+treeSet.size());
//3.遍历
for (String str:treeSet) {
System.out.println(str);
}
//4.判断
System.out.println(treeSet.contains("opq"));
}
}
(2)保存Person类的数据
/**
* 使用TreeSet保存数据
* 存储结构:红黑树
* 要求:元素必须要实现Comparable接口,compareTo方法返回值为0,认为是重复元素
*/
public class Demo5 {
public static void main(String[] args) {
//创建集合
TreeSet<Person> persons = new TreeSet<>();
//1.添加元素
Person p1 = new Person("7乔纳森-乔斯达",20);
Person p2 = new Person("5乔瑟夫-乔斯达",19);
Person p3 = new Person("3东方仗助",16);
Person p4 = new Person("3东方仗助",17);
//直接添加不能添加进去,因为没有比较规则,即没有实现Comparable接口,需要在Person类中实现
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(p4);
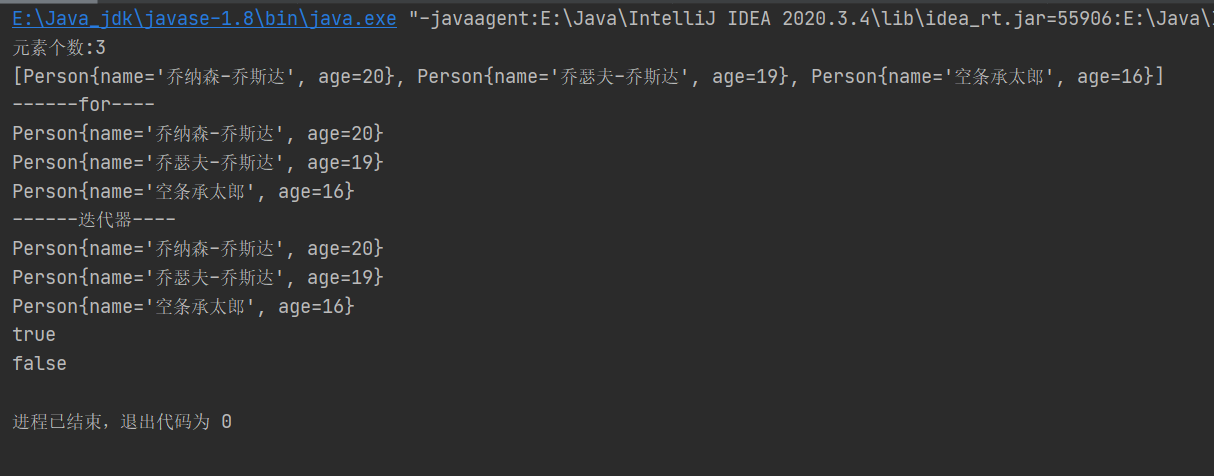
System.out.println("元素个数:"+persons.size());
System.out.println(persons.toString());
//2.删除
persons.remove(p4);
System.out.println("元素个数:"+persons.size());
//3.遍历
Iterator<Person> iterator = persons.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
//4.判断
System.out.println(persons.contains(p1));
}
}
person类没有实现Comparable接口

person类实现Comparable接口
public class Person implements Comparable<Person>{
private String name;
private int age;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
int n1 = this.name.hashCode();
int n2 = this.age;
return n1+n2;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
if(o instanceof Person){
Person person = (Person) o;
if(this.name.equals(person.getName())&&this.age == person.getAge()){
return true;
}
}
return false;
}
//先按姓名比再按年龄比
@Override
public int compareTo(Person o) {
int n1 = this.getName().compareTo(o.getName());
int n2 = this.age - o.getAge();
return n1==0?n2:n1;
}
}
测试

Comparator接口实现定制比较(不需要元素实现Comparable接口)
/**
* 使用TreeSet保存数据
* 存储结构:红黑树
* Comparator:实现定制比较(比较器)
*/
public class Demo6 {
public static void main(String[] args) {
//创建集合,并指定比较规则(匿名内部类)
TreeSet<Person> persons = new TreeSet<>(new Comparator<Person>() {
@Override
//先比较年龄再比较姓名
public int compare(Person o1, Person o2) {
int n1 = o1.getAge() - o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1==0?n2:n1;
}
});
//1.添加元素
Person p1 = new Person("7乔纳森-乔斯达",20);
Person p2 = new Person("5乔瑟夫-乔斯达",19);
Person p3 = new Person("3东方仗助",16);
Person p4 = new Person("4东方仗助",16);
persons.add(p1);
persons.add(p2);
persons.add(p3);
persons.add(p4);
System.out.println(persons.toString());
}
}
测试

TreeSet案例
/**
* 要求:使用TreeSet集合实现字符串按照长度进行排序
* Comparator实现定制比较
*
*/
public class Demo7 {
public static void main(String[] args) {
//创建集合并指定比较规则
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int n1 = o1.length() - o2.length();
int n2 = o1.compareTo(o2);
return n1==0?n2:n1;
}
});
//添加数据
treeSet.add("hello");
treeSet.add("hello,world");
treeSet.add("dalian");
treeSet.add("kunkun");
treeSet.add("ikun");
treeSet.add("cat");
treeSet.add("beijing");
System.out.println(treeSet.toString());
}
}
测试

6、Map接口与实现类
Map体系集合
Map接口的特点:
用于存储任意键值对(Key-Value)
键:无序、无下标、不允许重复(唯一)
值:无序、无下标、允许重复
6.1、Map父接口与简单使用
Map父接口
特点:存储一对数据(Key-Value),无序、无下标,键不可重复,值可重复。
方法:
- V put(K key,V value) //将对象存入到集合中,关联键值。key重复则覆盖原值。
- Object get(Object key)//根据键获取对应的值。
- Set keySet() //返回所有key。
- Collectionvalues()//返回包含所有值的Collection集合。
- Set<Map.Entry<K,V>>//键值匹配的Set集合。
Map接口使用
/**
* Map接口的使用
* 特点:(1)存储键值对(2)键不能重复,值可以重复(3)无序
*/
public class Demo1 {
public static void main(String[] args) {
//创建Map集合
Map<String, String> map = new HashMap<>();
//1.添加元素
map.put("tom","汤姆");
map.put("jack","杰克");
map.put("rose","露丝");
//map.put("rose","ooo");value会被替换
System.out.println("元素个数:"+map.size());
System.out.println(map.toString());
//2.删除
// map.remove("tom");
// System.out.println("删除后元素个数:"+map.size());
//3.遍历
//3.1使用keySet()
System.out.println("-------keySet()遍历---------");
//Set<String> keySet = map.keySet();
for(String key:map.keySet()){
System.out.println(key+"---"+map.get(key));
}
//3.2使用entrySet()
System.out.println("-------entrySet()遍历---------");
//Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry: map.entrySet()) {
System.out.println(entry.getKey()+"---"+entry.getValue());
}
//4.判断
System.out.println(map.containsKey("jack"));
System.out.println(map.containsValue("杰克"));
}
}
测试
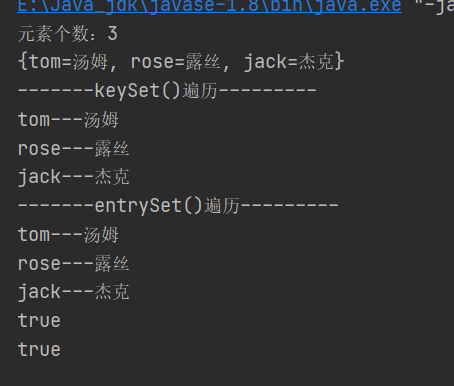
keySet()与entrySet()
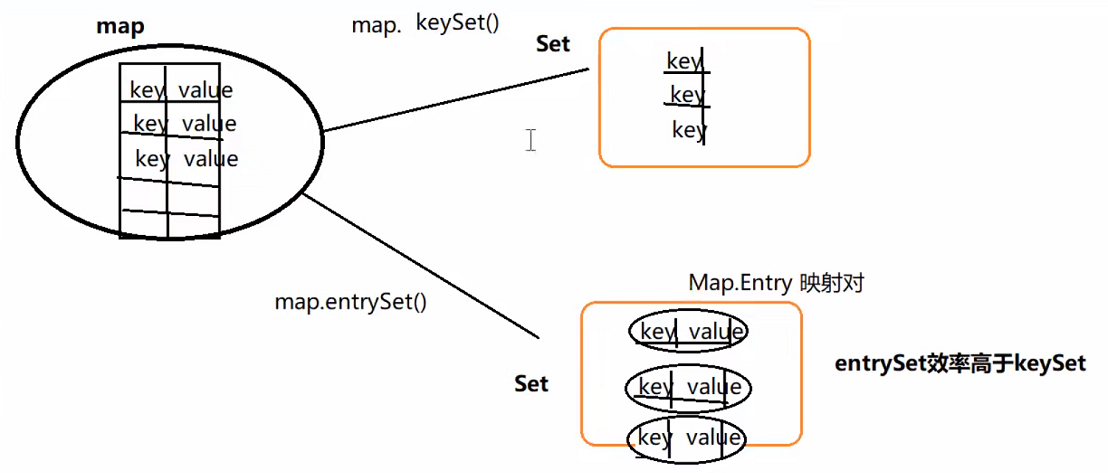
6.2、Map集合的实现类
HashMap【重点】
- jdk1.2版本,线程不安全,运行效率快
- 允许使用null作为key或value
Hashtable【了解】
- jdk1.0版本,线程安全,运行效率慢
- 不允许使用null作为key或value
Properties
- Hashtable的子类
- 要求key和value都是String
- 通常用于配置文件的读取
TreeMap
- 实现了SortedMap接口(是Map的子接口),可以对key自动排序
6.2.1、HashMap
Student类:
public class Student {
private String name;
private int stuNo;
public Student(String name, int stuNo) {
this.name = name;
this.stuNo = stuNo;
}
public Student() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getStuNo() {
return stuNo;
}
public void setStuNo(int stuNo) {
this.stuNo = stuNo;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", stuNo=" + stuNo +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return stuNo == student.stuNo && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, stuNo);
}
}
/**
* HashMap集合的使用
* 存储结构:哈希表(数组+链表+红黑树)
* 存储过程:
* (1)根据hashcode计算保存位置,如果位置为空,则直接保存,如果不为空,执行第二步
* (2)再执行equals方法,如果equals方法为true,则认为是重复,否则形成链表
*/
public class Demo2 {
public static void main(String[] args) {
//创建集合
HashMap<Student,String> students = new HashMap<>();
//1.添加元素
Student s1 = new Student("张三",503);
Student s2 = new Student("李四",509);
Student s3 = new Student("王五",505);
students.put(s1,"3班");
students.put(s2,"7班");
students.put(s3,"8班");
//students.put(s3,"9班");键重复不能添加进去,但是值会覆盖
students.put(new Student("张三",503),"3班");
//会添加进去,new会在堆中新创建一个对象,如果要让它添加不进去,要在Student中重写hashcode和equals方法
System.out.println("元素个数:"+students.size());
System.out.println(students.toString());
//2.删除
// students.remove(s1);
// System.out.println("删除之后:"+students.size());
//3.遍历
//keySet()
System.out.println("-------keySet()遍历---------");
for (Student key: students.keySet()) {
System.out.println(key.toString()+"========="+students.get(key));
}
System.out.println("-------entrySet()遍历---------");
for (Map.Entry<Student,String> entry: students.entrySet()) {
System.out.println(entry.getKey()+"========="+entry.getValue());
}
//4.判断
System.out.println(students.containsKey(s1));
}
}
测试

6.2.2、HashMap源码分析
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 HashMap初始容量大小
static final int MAXIMUM_CAPACITY = 1 << 30; // HashMap数组的最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子为0.75(到75%时扩容)
static final int TREEIFY_THRESHOLD = 8; //链表长度大于8时,调整成红黑树
static final int UNTREEIFY_THRESHOLD = 6; //链表长度小于6时,调整成链表
static final int MIN_TREEIFY_CAPACITY = 64; //链表长度大于8,并且集合元素个数大于等于64时,调整成红黑树
transient Node<K,V>[] table; //哈希表中的数组
transient int size; //元素个数
构造函数
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//刚创建HashMap之后没有添加元素 table=null,size=0 目的是节省空间
put方法(这个源码不太容易理解,大家尝试理解前每个方法的前几行就可以,有能力的可以深入研究)
//put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// resize()方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap源码简单总结
- HashMap刚创建时,table是null,为了节省空间,当添加第一个元素时,table容量调整为16
- 当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后大小为原来的2倍,目的是减少调整元素的个数
- jdk1.8,当每个链表长度大于8,并且数组元素个数大于等于64时,会调整为红黑树,日的提高执行效率
- jdk1.8当链表长度小于6时,调整成链表
- jdk1.8以前,链表是头插入,jdk1.8以后是尾插入
7、Collections工具类
概念:集合工具类,定义了除存取以外的集合常用方法
方法:

代码实现
/**
* Collections工具类的使用
*
*/
public class Demo4 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(77);
list.add(23);
list.add(89);
list.add(12);
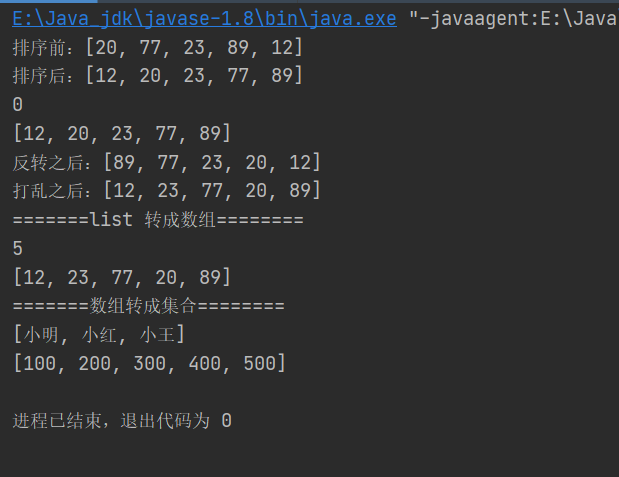
//sort排序
System.out.println("排序前:"+list.toString());
Collections.sort(list);//升默认序
System.out.println("排序后:"+list.toString());
//binarySearch二分查找, 找到为下标,没找到为负数
int i = Collections.binarySearch(list, 12);
System.out.println(i);
//copy复制
List<Integer> dest = new ArrayList<>();
for (int j = 0; j < list.size(); j++) {
dest.add(0);
}
Collections.copy(dest,list);
System.out.println(dest.toString());
//reverse反转
Collections.reverse(list);
System.out.println("反转之后:"+list);
//shuffle 打乱
Collections.shuffle(list);
System.out.println("打乱之后:"+list);
//补充:list 转成数组
System.out.println("=======list 转成数组========");
Integer[] integers = list.toArray(new Integer[0]);
System.out.println(integers.length);
System.out.println(Arrays.toString(integers));
//数组转成集合
System.out.println("=======数组转成集合========");
String[] names = {"小明","小红","小王"};
//集合是一个受限集合,不能添加和删除
List<String> list1 = Arrays.asList(names);
System.out.println(list1);
//把基本类型数组转成集合时,需要修改为包装类
Integer[] nums = {100,200,300,400,500};
List<Integer> integerList = Arrays.asList(nums);
System.out.println(integerList);
}
}
测试
8、集合总结
最后,我们再看一下这张图回顾一下Java集合框架的重点和常用知识
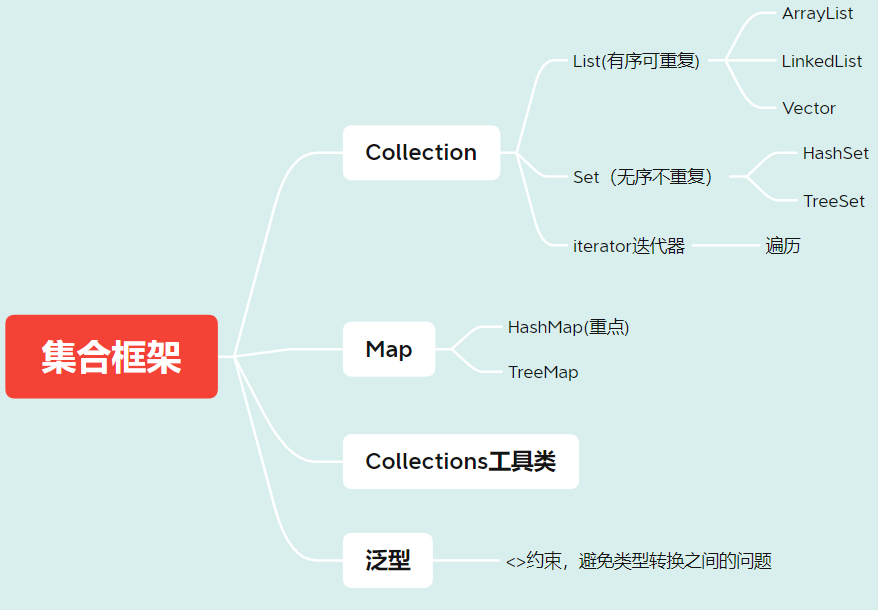
- 集合的概念:
- 对象的容器,和数组类似,定义了对多个对象进行操作的常用方法。
- List集合:
- 有序、有下标、元素可以重复。(ArrayList、LinkedList、Vector)
- Set集合:
- 无序、无下标、元素不可重复。(HashSet、TreeSet)
- Map集合:
- 存储一对数据,无序、无下标,键不可重复,值可重复。(HashMap、HashTable、TreeMap)
- Collections:
- 集合工具类,定义了除了存取以外的集合常用方法。
到这里关于Java集合框架的知识就结束啦°꒰๑'ꀾ'๑꒱°,希望大家都有所收获,觉得文章还可以的话可以点个推荐支持博主啊

Java--集合框架详解的更多相关文章
- java集合框架详解
java集合框架详解 一.Collection和Collections直接的区别 Collection是在java.util包下面的接口,是集合框架层次的父接口.常用的继承该接口的有list和set. ...
- Java集合框架详解(全)
一.Java集合框架概述 集合可以看作是一种容器,用来存储对象信息.所有集合类都位于java.util包下,但支持多线程的集合类位于java.util.concurrent包下. 数组与集合的区别如下 ...
- Java—集合框架详解
一.描述Java集合框架 集合,在Java语言中,将一系类的对象看成一个整体. 首先查看jdk中的Collection类的源码后会发现Collection是一个接口类,其继承了java迭代接口Iter ...
- java的集合框架详解
前言:数据结构对程序设计有着深远的影响,在面向过程的C语言中,数据库结构用struct来描述,而在面向对象的编程中,数据结构是用类来描述的,并且包含有对该数据结构操作的方法. 在Java语言中,Jav ...
- Collection集合框架详解
[Java的集合框架] 接口: collection map list set 实现类: ArryList HashSet HashMap LinkList LinkHash ...
- Java集合框架全解
Collection 集合 集合接口有2个基本方法: public interface Collection<E> { //向集合中添加元素.如果添加元素确实改变了集合就返回 true, ...
- java SSH框架详解(面试和学习都是最好的收藏资料)
Java—SSH(MVC)1. 谈谈你mvc的理解MVC是Model—View—Controler的简称.即模型—视图—控制器.MVC是一种设计模式,它强制性的把应用程序的输入.处理和输出分开.MVC ...
- JAVA集合类型详解
一.前言 作为java面试的常客[集合类型]是永恒的话题:在开发中,主要了解具体的使用,没有太多的去关注具体的理论说明,掌握那几种常用的集合类型貌似也就够使用了:导致这一些集合类型的理论有可能经常的忘 ...
- Java Collection框架详解
引用自:http://blog.sina.com.cn/s/blog_6d6f5d7d0100s9nu.html 经常会看到程序中使用了记录集,常用的有Collection.HashMap.HashS ...
- Java集合-----Set详解
Set是没有重复元素的集合,是无序的 1.HashSet HashSet它是线程不安全的 HashSet常用方法: add(E element) 将指定的元素添加到此集合(如果尚未存 ...
随机推荐
- 基于.NetCore开发博客项目 StarBlog - (6) 页面开发之博客文章列表
系列文章 基于.NetCore开发博客项目 StarBlog - (1) 为什么需要自己写一个博客? 基于.NetCore开发博客项目 StarBlog - (2) 环境准备和创建项目 基于.NetC ...
- 运维:DevSecOps
什么是DevSecOps DevSecOps 是一场关于 DevOps 概念实践或艺术形式的变革.DevOps之父Patrick Debios 强调:"DevOps2.0时代应首先解决人的问 ...
- MASA Auth - 权限设计
权限术语 Subject:用户,用户组 Action:对Object的操作,如增删改查等 Object:权限作用的对象,也可以理解为资源 Effect:规则的作用,如允许,拒绝 Condition:生 ...
- Spring中的Bean作用域
概述 scope用来声明容器中的对象所应该处的限定场景或者说该对象的存活时间,即容器在对象进入其 相应的scope之前,生成并装配这些对象,在该对象不再处于这些scope的限定之后,容器通常会销毁这些 ...
- python-将print内容保存到文件
通过sys.stdout得到print输出的内容,再进行保存 import sys class Logger(object): def __init__(self, file_path: str = ...
- 【图解源码】Zookeeper3.7源码分析,包含服务启动流程源码、网络通信源码、RequestProcessor处理请求源码
Zookeeper3.7源码剖析 能力目标 能基于Maven导入最新版Zookeeper源码 能说出Zookeeper单机启动流程 理解Zookeeper默认通信中4个线程的作用 掌握Zookeepe ...
- UiPath文本操作Get Text的介绍和使用
一.Get Text操作的介绍 从指定的UI元素提取文本值 二.Get Text在UiPath中的使用 1. 打开设计器,在设计库中新建一个Sequence,为序列命名及设置Sequence存放的路径 ...
- Linux 文件权限相关知识
文件权限说明 Linux中的文件能否被访问和工具(程序)无关,和访问的用户身份有关(谁去运行这个程序) 进程的发起者(谁去运行这个程序). 进程的发起者若是文件的所有者: 拥有文件的属主权限 进程的发 ...
- 《HelloGitHub》第 75 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. https://github.com/521xueweiha ...
- Python selenium 实现大麦网自动购票过程
一些无关紧要的哔哔: 大麦网是中国综合类现场娱乐票务营销平台,业务覆盖演唱会. 话剧.音乐剧.体育赛事等领域今天,我们要用代码来实现他的购票过程 开搞! 先来看看完成后的效果是怎么样的 开发环境 版 ...