大家都在用MySQL count(*)统计总数,到底有什么问题?
在日常开发工作中,我经常会遇到需要统计总数的场景,比如:统计订单总数、统计用户总数等。一般我们会使用MySQL 的count函数进行统计,但是随着数据量逐渐增大,统计耗时也越来越长,最后竟然出现慢查询的情况,这究竟是什么原因呢?本篇文章带你一下学习一下。
1. MyISAM存储引擎计数为什么这么快?
我们总有个错觉,就是感觉MyISAM引擎的count计数要比InnoDB引擎更快,实际这不是错觉。
MyISAM引擎把表的总行数单独记录在磁盘上,查询的时候可以直接返回,不需要再累加统计。
但是当SQL查询中有where条件的时候,就无法再使用表的总行数了,还是需要乖乖的进行累加统计,查询性能也就跟InnoDB相差无几了。
为什么MyISAM引擎能够记录表的总行数,InnoDB引擎却不行?
因为MyISAM引擎不支持事务,只有表锁,所以记录的总行数是准确的。
而InnoDB引擎支持事务和行锁,存在并发修改的情况。又由于事务的隔离性,会出现不可重复读和幻读,记录的总行数无法保证是准确的。
2. 能不能手动实现统计总行数
既然InnoDB引擎没有帮我们记录总行数,我们能不能手动记录总行数,比如使用Redis。
其实也是不行的,使用Redis记录总行数,至少有下面3个问题:
- 无法实现事务之间的隔离
- 更新丢失,因为i++不是原子操作,当然可以使用Lua脚本实现原子操作,更复杂。
- Redis是非关系型缓存数据库,不能当作关系型持久化数据库使用,一般需要设置过期时间。

由上图中得知,虽然Redis计数加1操作放在了事务里面,但是不受事务控制的,在事务没有提交前,其他查询依然读到了最新的总行数,这就是脏读的情况。
3. InnoDB引擎能否实现快速计数
有一种办法,可以粗略估计表的总行数,就是使用MySQL命令:
show table status like 'user';

真实的总行数有100万行,预估有99万多行,误差在可接受的范围内。
部分场景适用,比如粗略估计网站的总用户数。
4. 四种计数方式的性能差别
常见的统计总行数的方式有以下四种:
count(*) 、 count(常量) 、 count(id) 、 count(字段)
InnoDB引擎对count计数做了优化,会选用数据量较小的非聚簇索引进行统计。
比如用户表中有三个索引,分别是主键索引、name索引和age索引,使用执行计划查看计数的时候用到了哪个索引?
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) DEFAULT NULL COMMENT '姓名',
`age` tinyint NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB COMMENT='用户表';
explain select count(*) from user;
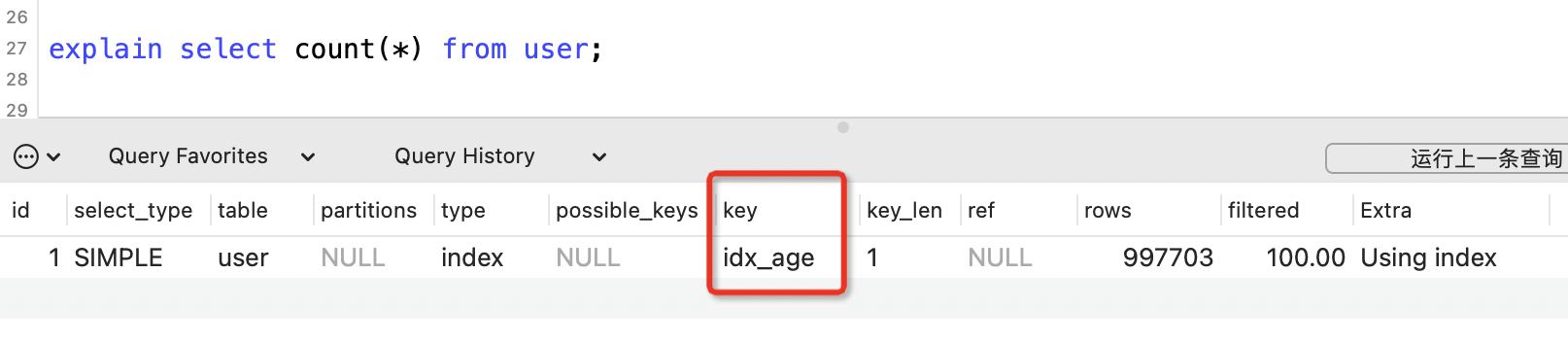
用到了数据量较小的age索引。
count(*) 、 count(常量) 是直接统计表中的总行数,效率较高。
而 count(id) 还需要把数据返回给MySQL Server端进行累加计数。
最后 count(字段)需要筛选不为null字段,效率最差。
四种计数的查询性能从高到低,依次是:
count(*) ≈ count(常量) > count(id) > count(字段)
对于大多数情况,得到计数结果,还是老老实实使用count(*)
所以推荐使用select count(*),别跟**select *搞混了,不推荐使用select ***的。

大家都在用MySQL count(*)统计总数,到底有什么问题?的更多相关文章
- MySQL的统计总数count(*)与count(id)或count(字段)的之间的各自效率性能对比
执行效果: 1. count(1) and count(*) 当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count(*)用时多了! 从执行计划来看,count(1)和cou ...
- MySQL统计总数就用count(*),别花里胡哨的《死磕MySQL系列 十》
有一个问题是这样的统计数据总数用count(*).count(主键ID).count(字段).count(1)那个效率高. 先说结论,不用那么花里胡哨遇到统计总数全部使用count(*). 但是有很多 ...
- 【mysql】 mybatis实现 主从表 left join 1:n 一对多 分页查询 主表从表都有查询条件 【mybatis】count 统计+JSON查询
mybatis实现 主从表 left join 1:n 一对多 分页查询 主表从表都有查询条件+count 需求: ======================================= ...
- MySql的count统计结果
起因:最近在学习mysql的数据库,发现在innodb表中大数据量下count(*)的统计结果实在是太慢,所以想找个办法替代这种查询,下面分享一下我查找的过程. 实践:在给出具体的结论之前,我们先看看 ...
- sql中奇怪的sum(1),sum(2),count(1),count(6),count(*):统计总数
sql的统计函数 sql统计函数有 count 统计条数,配合group用 sum 累加指定字段数值 但注意sum(1)就特殊 sum(1)等同于count(*) sum(1)统计个数,功能和coun ...
- mysql count group by统计条数方法
mysql count group by统计条数方法 mysql 分组之后如何统计记录条数? gourp by 之后的 count,把group by查询结果当成一个表再count一次select c ...
- MySQL查询统计,统计唯一值并分组
做个笔记 SQLyog客户端访问MySQL服务器 统计数据:次数总数, 次数成功率,对象(obj)总数,对象(obj)成功率 要求:按时间排序和分组 sql语句如下: SELECT a.date AS ...
- mysql数据统计技巧备忘录
mysql 作为常用数据库,操作贼六是必须的,对于数字操作相关的东西,那是相当方便,本节就来拎几个统计案例出来供参考! order订单表,样例如下: CREATE TABLE `t_order` ( ...
- Mysql count+if 函数结合使用
Mysql count+if 函数结合使用 果林椰子 关注 2017.05.18 13:48* 字数 508 阅读 148评论 0喜欢 1 涉及函数 count函数 mysql中count函数用于统计 ...
随机推荐
- VS Code 调教日记(2022.6.26更新)
VS Code 调教日记(2022.6.26更新) 基于msys2的MinGW-w64 GCC的环境配置 下载并安装msys2 到路径...msys2安装路径...\msys64\etc\pacman ...
- 【转载】vscode配置C/C++环境
VScode中配置 C/C++ 环境 Tip:请在电脑端查看 @零流@火星动力猿 2022.4.12 1. 下载编辑器VScode 官网:https://code.visualstudio.com/( ...
- 泛型容器类和ArrayList操作
泛型 比如ArrayList<E> E就是泛型 在没有泛型之前,从集合读取到的每一个对象都必须进行转换,如果有人不小心插入了类型错误的对象,在运行时的转换处理就会出错 有了泛型之后,可以告 ...
- 分布式事务(Seata)原理 详解篇,建议收藏
前言 在之前的系列中,我们讲解了关于Seata基本介绍和实际应用,今天带来的这篇,就给大家分析一下Seata的源码是如何一步一步实现的.读源码的时候我们需要俯瞰起全貌,不要去扣一个一个的细节,这样我们 ...
- 一题多解,ASP.NET Core应用启动初始化的N种方案[下篇]
[接上篇]"天下大势,分久必合,合久必分",ASP.NET应用通过GenericWebHostService这个承载服务被整合到基于IHostBuilder/IHost的服务承载系 ...
- docker多段构建nessus镜像
1.构建基础镜像,主要做安装和获取注册号: FROM ubuntu:16.04 ADD Nessus-8.11.0-debian6_amd64.deb /tmp/Nessus-8.11.0-debia ...
- 索尼笔记本Linux系统唤醒后,键盘无法使用
1.编辑grub文件 sudo gedit /etc/default/grub 2.修改成以下参数 GRUB_CMDLINE_LINUX_DEFAULT="quiet splash i804 ...
- 近期碰到的一些面试题--WPF、C#、数据库
最近想换工作的念头特别强烈,面了几家公司没有拿到满意的offer,心仪的公司面完锁HC,有点无奈,感觉今年有点卷,把碰到过的面试题总结下. WPF相关: 1.定义依赖属性需要注意哪些地方? (1)依赖 ...
- 002面试题_Switch...case的数据
1.byte 2.short 3.int 4.char 5.String 6.枚举
- 通过jmeter压测surging
前言 surging是异构微服务引擎,提供了模块化RPC请求通道,引擎在RPC服务治理基础之上还提供了各种协议,并且还提供了stage组件,以便针对于网关的访问, 相对于功能,可能大家更想知道能承受多 ...