go-zero微服务实战系列(五、缓存代码怎么写)
缓存是高并发服务的基础,毫不夸张的说没有缓存高并发服务就无从谈起。本项目缓存使用Redis,Redis是目前主流的缓存数据库,支持丰富的数据类型,其中集合类型的底层主要依赖:整数数组、双向链表、哈希表、压缩列表和跳表五种数据结构。由于底层依赖的数据结构的高效性以及基于多路复用的高性能I/O模型,所以Redis也提供了非常强悍的性能。下图展示了Redis数据类型对应的底层数据结构。
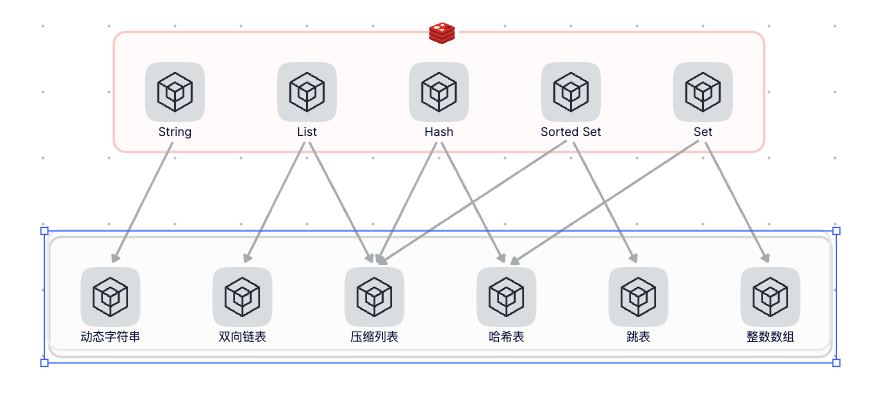
基本使用
在go-zero中默认集成了缓存model数据的功能,我们在使用goctl自动生成model代码的时候加上 -c 参数即可生成集成缓存的model代码
goctl model mysql datasource -url="root:123456@tcp(127.0.0.1:3306)/product" -table="*" -dir="./model" -c
通过简单的配置我们就可以使用model层的缓存啦,model层缓存默认过期时间为7天,如果没有查到数据会设置一个空缓存,空缓存的过期时间为1分钟,model层cache配置和初始化如下:
CacheRedis:
- Host: 127.0.0.1:6379
Type: node
CategoryModel: model.NewCategoryModel(conn, c.CacheRedis)
这次演示的代码主要会基于product-rpc服务,为了简单我们直接使用grpcurl来进行调试,注意启动的时候主要注册反射服务,通过goctl自动生成的rpc服务在dev或test环境下已经帮我们注册好了,我们需要把我们的mode设置为dev,默认的mode为pro,如下代码所示:
s := zrpc.MustNewServer(c.RpcServerConf, func(grpcServer *grpc.Server) {
product.RegisterProductServer(grpcServer, svr)
if c.Mode == service.DevMode || c.Mode == service.TestMode {
reflection.Register(grpcServer)
}
})
直接使用go install安装grpcurl工具,so easy !!!妈妈再也不用担心我不会调试gRPC了
go install github.com/fullstorydev/grpcurl/cmd/grpcurl
启动服务,通过如下命令查询服务,服务提供的方法,可以看到当前提供了Product获取商品详情接口和Products批量获取商品详情接口
~ grpcurl -plaintext 127.0.0.1:8081 list
grpc.health.v1.Health
grpc.reflection.v1alpha.ServerReflection
product.Product
~ grpcurl -plaintext 127.0.0.1:8081 list product.Product
product.Product.Product
product.Product.Products
我们先往product表里插入一些测试数据,测试数据放在lebron/sql/data.sql文件中,此时我们查看id为1的商品数据,这时候缓存中是没有id为1这条数据的
127.0.0.1:6379> EXISTS cache:product:product:id:1
(integer) 0
通过grpcurl工具来调用Product接口查询id为1的商品数据,可以看到已经返回了数据
~ grpcurl -plaintext -d '{"product_id": 1}' 127.0.0.1:8081 product.Product.Product
{
"productId": "1",
"name": "夹克1"
}
再看redis中已经存在了id为1的这条数据的缓存,这就是框架给我们自动生成的缓存
127.0.0.1:6379> get cache:product:product:id:1
{\"Id\":1,\"Cateid\":2,\"Name\":\"\xe5\xa4\xb9\xe5\x85\x8b1\",\"Subtitle\":\"\xe5\xa4\xb9\xe5\x85\x8b1\",\"Images\":\"1.jpg,2.jpg,3.jpg\",\"Detail\":\"\xe8\xaf\xa6\xe6\x83\x85\",\"Price\":100,\"Stock\":10,\"Status\":1,\"CreateTime\":\"2022-06-17T17:51:23Z\",\"UpdateTime\":\"2022-06-17T17:51:23Z\"}
我们再请求id为666的商品,因为我们表里没有id为666的商品,框架会帮我们缓存一个空值,这个空值的过期时间为1分钟
127.0.0.1:6379> get cache:product:product:id:666
"*"
当我们删除数据或者更新数据的时候,以id为key的行记录缓存会被删除
缓存索引
我们的分类商品列表是需要支持分页的,通过往上滑动可以不断地加载下一页,商品按照创建时间倒序返回列表,使用游标的方式进行分页。
怎么在缓存中存储分类的商品呢?我们使用Sorted Set来存储,member为商品的id,即我们只在Sorted Set中存储缓存索引,查出缓存索引后,因为我们自动生成了以主键id索引为key的缓存,所以查出索引列表后我们再查询行记录缓存即可获取商品的详情,Sorted Set的score为商品的创建时间。
下面我们一起来分析分类商品列表的逻辑该怎么写,首先先从缓存中读取当前页的商品id索引,调用cacheProductList方法,注意,这里调用查询缓存方法忽略了error,为什么要忽略这个error呢,因为我们期望的是尽最大可能的给用户返回数据,也就是redis挂掉了的话那我们就会从数据库查询数据返回给用户,而不会因为redis挂掉而返回错误。
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
cacheProductList方法实现如下,通过ZrevrangebyscoreWithScoresAndLimitCtx倒序从缓存中读数据,并限制读条数为分页大小
func (l *ProductListLogic) cacheProductList(ctx context.Context, cid int32, cursor, ps int64) ([]int64, error) {
pairs, err := l.svcCtx.BizRedis.ZrevrangebyscoreWithScoresAndLimitCtx(ctx, categoryKey(cid), cursor, 0, 0, int(ps))
if err != nil {
return nil, err
}
var ids []int64
for _, pair := range pairs {
id, _ := strconv.ParseInt(pair.Key, 10, 64)
ids = append(ids, id)
}
return ids, nil
}
为了表示列表的结束,我们会在Sorted Set中设置一个结束标志符,该标志符的member为-1,score为0,所以我们在从缓存中查出数据后,需要判断数据的最后一条是否为-1,如果为-1的话说明列表已经加载到最后一页了,用户再滑动屏幕的话前端就不会再继续请求后端的接口了,逻辑如下,从缓存中查出数据后再根据主键id查询商品的详情即可
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
if len(pids) == int(in.Ps) {
isCache = true
if pids[len(pids)-1] == -1 {
isEnd = true
}
}
如果从缓存中查出的数据为0条,那么我们就从数据库中查询该分类下的数据,这里要注意从数据库查询数据的时候我们要限制查询的条数,我们默认一次查询300条,因为我们每页大小为10,300条可以让用户下翻30页,大多数情况下用户根本不会翻那么多页,所以我们不会全部加载以降低我们的缓存资源,当用户真的翻页超过30页后,我们再按需加载到缓存中
func (m *defaultProductModel) CategoryProducts(ctx context.Context, cateid, ctime, limit int64) ([]*Product, error) {
var products []*Product
err := m.QueryRowsNoCacheCtx(ctx, &products, fmt.Sprintf("select %s from %s where cateid=? and status=1 and create_time<? order by create_time desc limit ?", productRows, m.table), cateid, ctime, limit)
if err != nil {
return nil, err
}
return products, nil
}
获取到当前页的数据后,我们还需要做去重,因为如果我们只以createTime作为游标的话,很可能数据会重复,所以我们还需要加上id作为去重条件,去重逻辑如下
for k, p := range firstPage {
if p.CreateTime == in.Cursor && p.ProductId == in.ProductId {
firstPage = firstPage[k:]
break
}
}
最后,如果没有命中缓存的话,我们需要把从数据库查出的数据写入缓存,这里需要注意的是如果数据已经到了末尾需要加上数据结束的标识符,即val为-1,score为0,这里我们异步的写会缓存,因为写缓存并不是主逻辑,不需要等待完成,写失败也没有影响呢,通过异步方式降低接口耗时,处处都有小优化呢
if !isCache {
threading.GoSafe(func() {
if len(products) < defaultLimit && len(products) > 0 {
endTime, _ := time.Parse("2006-01-02 15:04:05", "0000-00-00 00:00:00")
products = append(products, &model.Product{Id: -1, CreateTime: endTime})
}
_ = l.addCacheProductList(context.Background(), products)
})
}
可以看出想要写一个完整的基于游标分页的逻辑还是比较复杂的,有很多细节需要考虑,大家平时在写类似代码时一定要细心,该方法的整体代码如下:
func (l *ProductListLogic) ProductList(in *product.ProductListRequest) (*product.ProductListResponse, error) {
_, err := l.svcCtx.CategoryModel.FindOne(l.ctx, int64(in.CategoryId))
if err == model.ErrNotFound {
return nil, status.Error(codes.NotFound, "category not found")
}
if in.Cursor == 0 {
in.Cursor = time.Now().Unix()
}
if in.Ps == 0 {
in.Ps = defaultPageSize
}
var (
isCache, isEnd bool
lastID, lastTime int64
firstPage []*product.ProductItem
products []*model.Product
)
pids, _ := l.cacheProductList(l.ctx, in.CategoryId, in.Cursor, int64(in.Ps))
if len(pids) == int(in.Ps) {
isCache = true
if pids[len(pids)-1] == -1 {
isEnd = true
}
products, err := l.productsByIds(l.ctx, pids)
if err != nil {
return nil, err
}
for _, p := range products {
firstPage = append(firstPage, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
CreateTime: p.CreateTime.Unix(),
})
}
} else {
var (
err error
ctime = time.Unix(in.Cursor, 0).Format("2006-01-02 15:04:05")
)
products, err = l.svcCtx.ProductModel.CategoryProducts(l.ctx, ctime, int64(in.CategoryId), defaultLimit)
if err != nil {
return nil, err
}
var firstPageProducts []*model.Product
if len(products) > int(in.Ps) {
firstPageProducts = products[:int(in.Ps)]
} else {
firstPageProducts = products
isEnd = true
}
for _, p := range firstPageProducts {
firstPage = append(firstPage, &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
CreateTime: p.CreateTime.Unix(),
})
}
}
if len(firstPage) > 0 {
pageLast := firstPage[len(firstPage)-1]
lastID = pageLast.ProductId
lastTime = pageLast.CreateTime
if lastTime < 0 {
lastTime = 0
}
for k, p := range firstPage {
if p.CreateTime == in.Cursor && p.ProductId == in.ProductId {
firstPage = firstPage[k:]
break
}
}
}
ret := &product.ProductListResponse{
IsEnd: isEnd,
Timestamp: lastTime,
ProductId: lastID,
Products: firstPage,
}
if !isCache {
threading.GoSafe(func() {
if len(products) < defaultLimit && len(products) > 0 {
endTime, _ := time.Parse("2006-01-02 15:04:05", "0000-00-00 00:00:00")
products = append(products, &model.Product{Id: -1, CreateTime: endTime})
}
_ = l.addCacheProductList(context.Background(), products)
})
}
return ret, nil
}
我们通过grpcurl工具请求ProductList接口后返回数据的同时也写进了缓存索引中,当下次再请求的时候就直接从缓存中读取
grpcurl -plaintext -d '{"category_id": 8}' 127.0.0.1:8081 product.Product.ProductList
缓存击穿
缓存击穿是指访问某个非常热的数据,缓存不存在,导致大量的请求发送到了数据库,这会导致数据库压力陡增,缓存击穿经常发生在热点数据过期失效时,如下图所示:
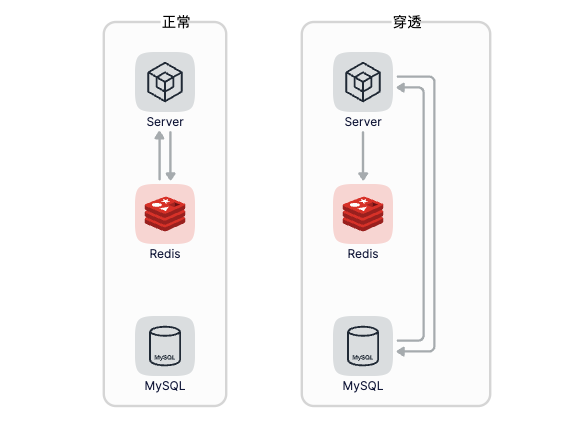
既然缓存击穿经常发生在热点数据过期失效的时候,那么我们不让缓存失效不就好了,每次查询缓存的时候不要使用Exists来判断key是否存在,而是使用Expire给缓存续期,通过Expire返回结果判断key是否存在,既然是热点数据通过不断地续期也就不会过期了
还有一种简单有效的方法就是通过singleflight来控制,singleflight的原理是当同时有很多请求同时到来时,最终只有一个请求会最终访问到资源,其他请求都会等待结果然后返回。获取商品详情使用singleflight进行保护示例如下:
func (l *ProductLogic) Product(in *product.ProductItemRequest) (*product.ProductItem, error) {
v, err, _ := l.svcCtx.SingleGroup.Do(fmt.Sprintf("product:%d", in.ProductId), func() (interface{}, error) {
return l.svcCtx.ProductModel.FindOne(l.ctx, in.ProductId)
})
if err != nil {
return nil, err
}
p := v.(*model.Product)
return &product.ProductItem{
ProductId: p.Id,
Name: p.Name,
}, nil
}
缓存穿透
缓存穿透是指要访问的数据既不在缓存中,也不在数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。此时也就没办法从数据库中读出数据再写入缓存来服务后续的请求,类似的请求如果多的话就会给缓存和数据库带来巨大的压力。
针对缓存穿透问题,解决办法其实很简单,就是缓存一个空值,避免每次都透传到数据库,缓存的时间可以设置短一点,比如1分钟,其实上文已经有提到了,当我们访问不存在的数据的时候,go-zero框架会帮我们自动加上空缓存,比如我们访问id为999的商品,该商品在数据库中是不存在的。
grpcurl -plaintext -d '{"product_id": 999}' 127.0.0.1:8081 product.Product.Product
此时查看缓存,已经帮我添加好了空缓存
127.0.0.1:6379> get cache:product:product:id:999
"*"
缓存雪崩
缓存雪崩时指大量的的应用请求无法在Redis缓存中进行处理,紧接着应用将大量的请求发送到数据库,导致数据库被打挂,好惨呐!!缓存雪崩一般是由两个原因导致的,应对方案也不太一样。
第一个原因是:缓存中有大量的数据同时过期,导致大量的请求无法得到正常处理。
针对大量数据同时失效带来的缓存雪崩问题,一般的解决方案是要避免大量的数据设置相同的过期时间,如果业务上的确有要求数据要同时失效,那么可以在过期时间上加一个较小的随机数,这样不同的数据过期时间不同,但差别也不大,避免大量数据同时过期,也基本能满足业务的需求。
第二个原因是:Redis出现了宕机,没办法正常响应请求了,这就会导致大量请求直接打到数据库,从而发生雪崩
针对这类原因一般我们需要让我们的数据库支持熔断,让数据库压力比较大的时候就触发熔断,丢弃掉部分请求,当然熔断是对业务有损的。
在go-zero的数据库客户端是支持熔断的,如下在ExecCtx方法中使用熔断进行保护
func (db *commonSqlConn) ExecCtx(ctx context.Context, q string, args ...interface{}) (
result sql.Result, err error) {
ctx, span := startSpan(ctx, "Exec")
defer func() {
endSpan(span, err)
}()
err = db.brk.DoWithAcceptable(func() error {
var conn *sql.DB
conn, err = db.connProv()
if err != nil {
db.onError(err)
return err
}
result, err = exec(ctx, conn, q, args...)
return err
}, db.acceptable)
return
}
结束语
本篇文章先介绍了go-zero中缓存使用的基本姿势,接着详细介绍了使游标通过缓存索引来实现分页功能,紧接着介绍了缓存击穿、缓存穿透、缓存雪崩的概念和应对方案。缓存对于高并发系统来说是重中之重,但是缓存的使用坑还是挺多的,大家在平时项目开发中一定要非常仔细,如果使用不当的话不但不能带来性能的提升,反而会让业务代码变得复杂。
在这里要非常感谢go-zero社区中的@group和@寻找,最美的心灵两位同学,他们积极地参与到该项目的开发中,并提了许多改进意见。
希望本篇文章对你有所帮助,谢谢。
每周一、周四更新
代码仓库: https://github.com/zhoushuguang/lebron
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!
微信交流群
关注『微服务实践』公众号并点击 交流群 获取社区群二维码。
go-zero微服务实战系列(五、缓存代码怎么写)的更多相关文章
- go-zero微服务实战系列(十一、大结局)
本篇是整个系列的最后一篇了,本来打算在系列的最后一两篇写一下关于k8s部署相关的内容,在构思的过程中觉得自己对k8s知识的掌握还很不足,在自己没有理解掌握的前提下我觉得也很难写出自己满意的文章,大家看 ...
- go-zero微服务实战系列(三、API定义和表结构设计)
前两篇文章分别介绍了本系列文章的背景以及根据业务职能对商城系统做了服务的拆分,其中每个服务又可分为如下三类: api服务 - BFF层,对外提供HTTP接口 rpc服务 - 内部依赖的微服务,实现单一 ...
- 微服务实战系列--Nginx官网发布(转)
这是Nginx官网写的一个系列,共七篇文章,如下 Introduction to Microservices (this article) Building Microservices: Using ...
- ASP.NET Core微服务实战系列
希望给你3-5分钟的碎片化学习,可能是坐地铁.等公交,积少成多,水滴石穿,码字辛苦,如果你吃了蛋觉得味道不错,希望点个赞,谢谢关注. 前言 这里记录的是个人奋斗和成长的地方,该篇只是一个系列目录和构想 ...
- Chris Richardson微服务实战系列
微服务实战(一):微服务架构的优势与不足 微服务实战(二):使用API Gateway 微服务实战(三):深入微服务架构的进程间通信 微服务实战(四):服务发现的可行方案以及实践案例 微服务实践(五) ...
- go-zero微服务实战系列(七、请求量这么高该如何优化)
前两篇文章我们介绍了缓存使用的各种最佳实践,首先介绍了缓存使用的基本姿势,分别是如何利用go-zero自动生成的缓存和逻辑代码中缓存代码如何写,接着讲解了在面对缓存的穿透.击穿.雪崩等常见问题时的解决 ...
- go-zero 微服务实战系列(一、开篇)
前言 在社区中经常看到有人问有没有基于 go-zero 的比较完整的项目参考,该类问题本质上是想知道基于 go-zero 的项目的最佳实践.完整的项目应该是一个完整的产品功能,包含产品需求.架构设计. ...
- 微服务实战系列(五)-注册中心Eureka与nacos区别
1. 场景描述 nacos最近用的比较多,介绍下nacos及部署吧,刚看了下以前写过类似的,不过没写如何部署及与eureka区别,只展示了效果,补补吧. 2.解决方案 2.1 nacos与eureka ...
- Go + gRPC-Gateway(V2) 构建微服务实战系列,小程序登录鉴权服务:第一篇(内附开发 demo)
简介 小程序可以通过微信官方提供的登录能力方便地获取微信提供的用户身份标识,快速建立小程序内的用户体系. 系列 云原生 API 网关,gRPC-Gateway V2 初探 业务流程 官方开发接入文档 ...
随机推荐
- LC-844
给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true .# 代表退格字符. 注意:如果对空文本输入退格字符,文本继续为空. 示例 1: 输入:s = &qu ...
- QGIS 安装
QGIS 安装 官网 https://www.qgis.org/ 下载地址 https://www.qgis.org/en/site/forusers/download.html 参考文档 https ...
- JS将某个数组分割为N个对象一组(如,两两一组,三三一组等)
方法一: var result = []; var data = [ {name:'chen',age:'25'}, {name:'chen',age:'25'}, {name:'chen',age: ...
- python黑帽子(第五章)
对开源CMS进行扫描 import os import queue import requests # 原书编写时间过于久远 现在有requests库对已经对原来的库进行封装 更容易调用 import ...
- 简单了解AndroidManifest.xml文件
AndroidManifest.xml:资源清单文件 <?xml version="1.0" encoding="utf-8"?> <mani ...
- [ Perl ] 多线程并发编程
https://www.cnblogs.com/yeungchie/ 记录一些常用的 模块 / 方法 . 多线程 使用模块 threads use 5.010; use threads; sub fu ...
- 关于LVS中默认的DR模型图
虽然常用,但是关于DR模型最大的一个缺点就是Director和RS必须在同一个网络中,通过交换机连接,中间不能有路由
- 获取iframe的window对象
在父窗口中获取iframe中的元素 // JS // 方法1: var iframeWindow = window.frames["iframe的name或id"]; iframe ...
- es篇-es基础
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. es基础知识 es和solr一样,都是基于Lucene的全文检索数据库 ...
- 同时将代码备份到Gitee和GitHub
同时将代码备份到Gitee和GitHub 如何将GitHub项目一步导入Gitee 如何保持Gitee和GitHub同步更新 如何将GitHub项目一步导入Gitee 方法一: 登陆 Gitee 账号 ...