selenium环境配置和八大元素定位
一.环境配置
1.selenium下载安装
安装一:pip install selenium(多数会超时安装失败)
安装二:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium(使用清华园镜像下载)
2.webdriver下载
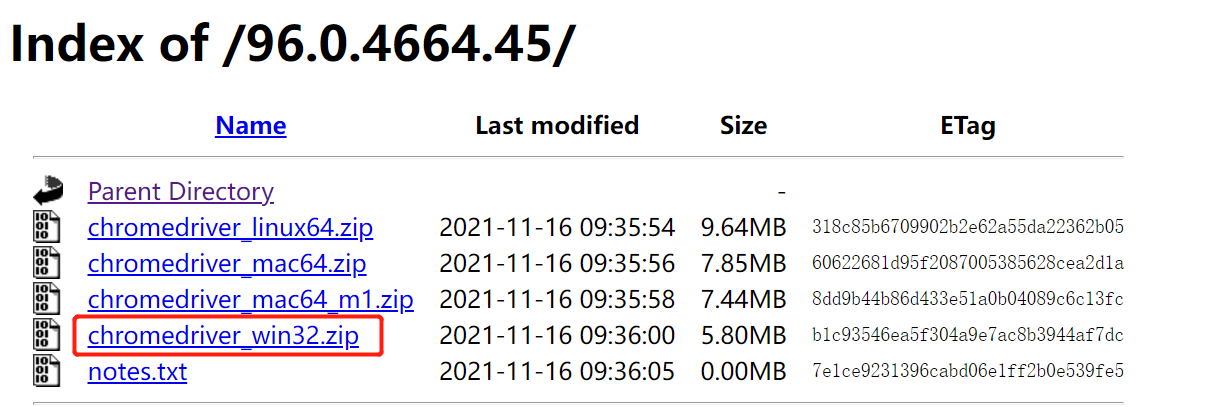
下载地址:http://chromedriver.storage.googleapis.com/index.html(谷歌为例)
下载时选择与当前谷歌浏览器版本一致或相近的版本去下载,下载完成后解压到python解释器目录下
二.八大元素
1.ID
ID具有唯一性,若是当前标签含有id属性,可以优先使用id定位。
from selenium import webdriver
from time import sleep from selenium.webdriver.common.by import By driver = webdriver.Chrome() # 实例化浏览器对象
driver.get('https://www.bing.com') # 设置跳转网页
driver.find_element(by=By.ID, value='sb_form_q').send_keys('我是好人') # id定位
sleep(3) # 等待3s
driver.quit() # 关闭网页
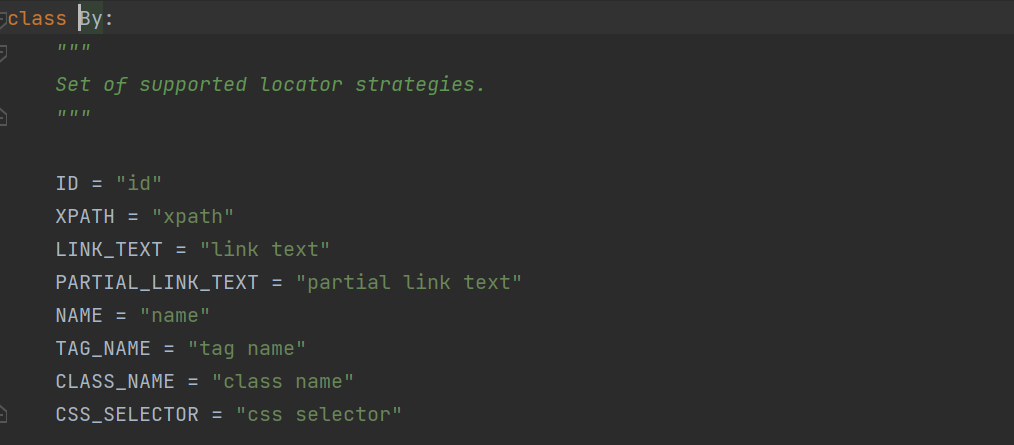
by表示当前使用什么元素定位,我们可以进入By模块里可以看到By类下的八种属性,value表示当前
属性的值,send_keys赋值。
2.NAME
name属性不唯一,一个页面可能有多个相同的name值,所以使用时要确保该属性值是唯一的
driver_name = driver.find_element(by=By.NAME, value='q')
driver_name.send_keys("作者是帅哥")
3.CLASS_NAME
driver_name = driver.find_element(by=By.CLASS_NAME, value='sb_form_q')
driver_name.send_keys("作者是帅哥")
4.LINK_TEXT
用于<a>标签定位
driver_name = driver.find_element(by=By.LINK_TEXT, value='文案')
driver_name.click() # click点击事件
value的值要和<a>文案</a>的值相等,click()点击超链接
5.PARTIAL_LINK_TEXT
PARTIAL_LINK_TEXT与LINK_TEXT相似,都是用于超链接,区别在于前置value为模糊查询,后者匹配相等
driver_name = driver.find_element(by=By.LINK_TEXT, value='案')
driver_name.click() # click点击事件
6.TAG_NAME
用于标签定位(<a>,<p>,<input>....),该元素定位不常用,效率低
driver_name = driver.find_element(by=By.TAG_NAME, value='input')
driver_name.send_keys("作者是帅哥")
7.XPATH
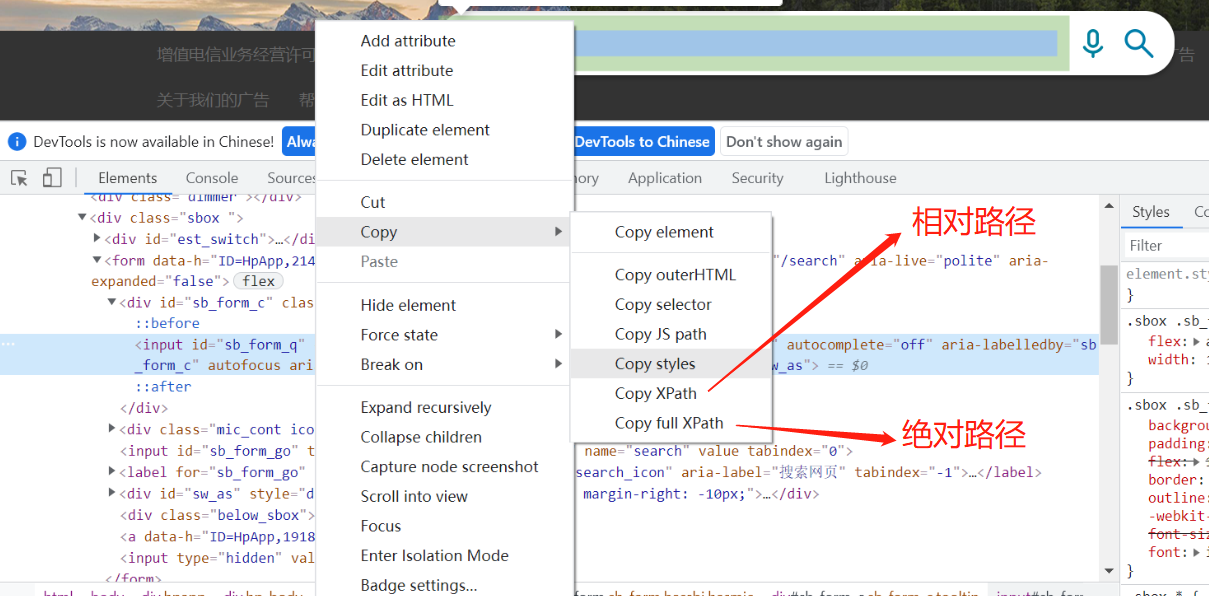
(1)可理解为元素路径定位,内含两种定位,绝对路径和相对路径
- 绝对路径:以/html开头
- 相对路径:以//*开头
driver.find_element(by=By.XPATH, value="//*[@id='sb_form_q' and @name='q']").send_keys("作者是帅哥") #相对路径
driver.find_element(by=By.XPATH, value="/html/body/div[2]/div/div[3]/div[2]/form/div[1]/input").send_keys("作者是帅哥") #相对路径
相对路径下[]内可连接多个and条件。这就可以解决因为name值相等元素定位错误的问题,前提需保证你定
位的标签中有这些属性。层级结构非常复杂时,手动输入路径可能会出错,这个时候我们可直接复制即可
(2)XPATH用法拓展(适用于相对路径)
- contains用法
driver.find_element(by=By.XPATH, value="//*[contains(@name,'na') and (@id,'sb_form_q')]").send_keys("作者说帅哥")
[contains(@属性,"属性值")]:模糊匹配
- starts-with用法
driver.find_element(by=By.XPATH, value="//*[starts-with(@name,'2') and contains(@id,'2')]").send_keys("12")
[starts-with(@属性,"属性值")]:匹配以XXX开头
8.CSS_SELECTOR
(1)层级语法定位
driver.find_element(by=By.CSS_SELECTOR, value="copy selector").click()
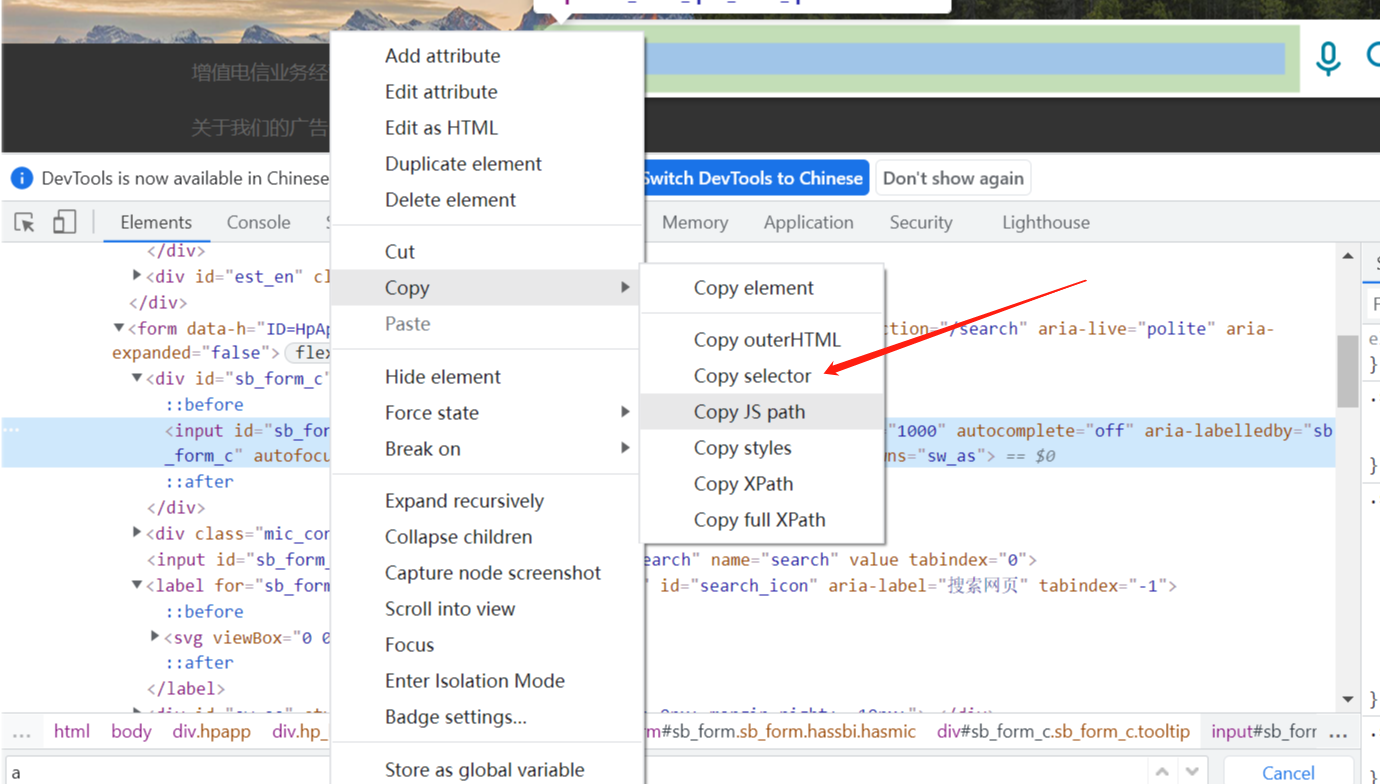
层级定位可直接copy selector即可
(2)选择器定位
- id选择器
driver.find_element(by=By.CSS_SELECTOR, value="#sb_form_q").click()
这里需要在value值前加个#
- class选择器
driver.find_element(by=By.CSS_SELECTOR, value="[class='sb_form_q']").send_keys("class选择器") #精准匹配
- 属性选择器
语法一:value="[属性='属性值']"
driver.find_element(by=By.CSS_SELECTOR, value="[name='q']").send_keys("属性选择器")
driver.find_element(by=By.CSS_SELECTOR, value="[id='sb_form_q']").send_keys("属性选择器")
语法二:value="标签[属性=‘属性值’]"
driver.find_element(by=By.CSS_SELECTOR, value="a[id='halou']").click()
(3)CSS_SELECTOR拓展
- 匹配以XX开头:value="[id^='head']")
- 匹配以XX结尾:value="[id$='tail']"
- 模糊匹配:valur="[name*='like']"
三.find_element与find_elements区别
我们在使用find_element和find_elements获取定位元素时,后者返回的是list集合类型的,
前者返回的是<class 'selenium.webdriver.remote.webelement.WebElement'> 类型。
- find_element:适用于获取唯一的定位元素值(默认返回第一个)
- find_elements:适用于获取多个值相同的元素定位(默认返回第一个,我们可用对应的下标来获取)
selenium环境配置和八大元素定位的更多相关文章
- Java + Selenium + WebDriver八大元素定位方式
UI自动化测试的第一步就是进行元素定位,下面给大家介绍一下Selenium + WebDriver的八大元素定位方式.现在我们就以百度搜索框为例进行元素定位,如下图: 一.By.name() Java ...
- selenium八大元素定位方法
1.ID定位 可以根据元素的id来定位属性,id是当前整个HTML页面中唯一的,所以可以通过id属性来唯一定位一个元素,是首选的元素定位方式.(动态ID不做考虑) # 导入webdriver和By f ...
- C# selenium环境配置
1.下载C#selenium selenium官网: http://www.seleniumhq.org/download/ 下载后解压: 打开net35后,将里面的dll文件添 ...
- Selenium:WebDriver简介及元素定位
参考内容:官方API文档,下载链接:http://download.csdn.net/detail/kwgkwg001/4004500 虫师:<selenium2自动化测试实战-基于python ...
- Python3+Selenium环境配置
一.所需工具 1.Python3.6安装包 2.Selenium安装包(selenium-server-standalone-3.8),如果是Python3的话可以不用下载selenium压缩包,Py ...
- python+selenium环境配置及浏览器调用
最近在学习python自动化,从项目角度和技术基础角度出发,我选择了python+selenium+appium的模式开始我的自动化测试之旅: 一.python安装 二.python IDE使用简介 ...
- 跟浩哥学自动化测试Selenium -- 浏览器的基本操作与元素定位(3)
浏览器的基本操作与元素定位 通过上一章学习,我们已经学会了如何设置驱动路径,如何创建浏览器对象,如何打开一个网站,接下来我们要进行一些复杂的操作比如先打开百度首页,在打开博客园,网页后退,前进等等,甚 ...
- 【转】【selenium+Python WebDriver】之元素定位不到解决办法
感谢: 煜妃的<Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)> ClassName定位报错问题:<[Python] ...
- 【转载】【selenium+Python WebDriver】之元素定位
总结: 感谢: “煜妃”<Selenuim+Python之元素定位总结及实例说明> “Huilaojia123”<selenium WebDriver定位元素学习总结> “上海 ...
随机推荐
- Kubernetes 从入门到进阶实战教程 (2021 最新万字干货版)
作者:oonamao 毛江云,腾讯 CSIG 应用开发工程师原文:来源腾讯技术工程,https://tinyurl.com/ya3ennxf 写在前面 笔者今年 9 月从端侧开发转到后台开发,第一个系 ...
- 使用 HDFS 协议访问对象存储服务
背景介绍 原生对象存储服务的索引是扁平化的组织形式,在传统文件语义下的 List 和 Rename 操作性能表现上存在短板.腾讯云对象存储服务 COS 通过元数据加速功能,为上层计算业务提供了等效于 ...
- v82.01 鸿蒙内核源码分析 (协处理器篇) | CPU 的好帮手 | 百篇博客分析 OpenHarmony 源码
本篇关键词:CP15 .MCR.MRC.ASID.MMU 硬件架构相关篇为: v65.01 鸿蒙内核源码分析(芯片模式) | 回顾芯片行业各位大佬 v66.03 鸿蒙内核源码分析(ARM架构) | A ...
- 用js给闺女做了一个加减乘除的html
下班回家用二十分钟给闺女做了一个加减乘除的页面,顺便记录下代码,时间仓促,后期再来修改吧 目录结构 -yq --menu.html --yq.html --yq50.html --yq70.html ...
- Apache ShenYu:分析、实现一个 Node.js 语言的 HTTP 服务注册客户端(HTTP Registry)
这块没空写文章了,先贴出实现代码吧 yuque.com/myesn
- 通过Swagger接口导出模板文件时报错:URL.createObjectURL: Argument 1 is not valid for any of the 1-argument overloads.
问题描述:通过Swagger接口导出Excel模板文件时,报错:URL.createObjectURL: Argument 1 is not valid for any of the 1-argume ...
- Python技法:用argparse模块解析命令行选项
1. 用argparse模块解析命令行选项 我们在上一篇博客<Linux:可执行程序的Shell传参格式规范>中介绍了Linux系统Shell命令行下可执行程序应该遵守的传参规范(包括了各 ...
- Docker 与 K8S学习笔记(二十三)—— Kubernetes集群搭建
小伙伴们,好久不见,这几个月实在太忙,所以一直没有更新,今天刚好有空,咱们继续k8s的学习,由于我们后面需要深入学习Pod的调度,所以我们原先使用MiniKube搭建的实验环境就不能满足我们的需求了, ...
- Java_循环结构
目录 while循环 do...while循环 for循环 for循环嵌套 增强for循环 打印三角形 Debug 视频 while循环 while(布尔表达式){ //循环内容 } //死循环 wh ...
- 本地创建的jupyter notebook 无法连接本地环境(即不能运行代码)
参考:https://www.cnblogs.com/damin1909/p/12691147.html 本人所用的python是anaconda下的,由于需求不同,创建了好多个python用于不同的 ...