SQL一文入门助记
什么是SQL
SQL(Structured Query Language)是用于操作数据库的语言。一个博客有许多网站,一个游戏要储存许多游戏的账号密码,这些都离不开数据库操作。
关系型数据库与NoSQL
关系型数据库就是一个表格,每一个横行就是每一条数据,每一个纵列就是每条数据有哪些信息:
| id | name | score | gender |
|---|---|---|---|
| 1 | Alice | 90 | F |
| 2 | Bob | 92 | M |
| 3 | Carol | 90 | F |
| 4 | David | 98 | M |
常见的关系型数据库: Oracle、MySql、Microsoft SQL Server、SQLite
非关系型数据库就是没有这些限制的数据库,他们结构更自由,通常数据自身就以对象的方式存储,NoSQL 往往为某些特别数据量身打造,在许多场合效率更高。
常见的 NoSQL 数据库:MongoDB、Redis、Memcached、HBase
但总体而言,SQL 的使用场合多得多,NoSQL 意为"Not Only SQL",用于辅助 SQL 数据库,而非取而代之。
MySQL, SQL 与 InnoDB
SQL 是一种结构化查询语言,是一门 ANSI 标准的计算机语言,但是仍然存在着多种不同版本的 SQL 语言。在不同的软件里,每款数据库的 SQL 语法通常有区别。但在基本的增删改查功能上他们是一样的,但某个特型数据库提供的 SQL 语句可能就不能在其他地方执行了。
SQL语句通常不区分大小写,但一般关键字用大写;SQL语句末尾要打分号。SQL以--comment为单行注释,/* comment */为多行注释。
MySQL 是一款优秀的 SQL 软件,是目前应用最广泛的开源关系数据库之一。MySQL最早是由瑞典的 MySQL AB 公司开发,该公司在2008年被 SUN 公司收购,紧接着,SUN 公司在 2009 年被 Oracle 公司收购,所以 MySQL 最终就变成了 Oracle 旗下的产品。这篇文章以 MySQL 为载体,介绍最简单的 SQL 语句。
而 MySQL 本身也只是一个接口,内部的引擎(真正做增删改查的)被分离出来了,称作数据库引擎,常用的引擎之一是 InnoDB。
MySQL 分免费版和付费版,他们的代码功能是一样的,付费版多出来的功能是一些管理功能。
免费版下载:https://dev.mysql.com/downloads/mysql/
Mysql 和 mysqld
安装完成后通常服务会自己启动,这个服务是运行在后台的,此时我们可以用 python,node 等连接,也可以用mysql控制台连接:
mysql -u root -p
-u代表用户名,-p代表接下来输入密码,默认密码应该是root。见到提示符mysql>后,就可以手动操作了。
如果重启了电脑,后台SQL服务就关闭了,输入mysqld即可再次启动。
创建数据库和数据表
一个软件里有几个数据库,一个数据库里有几个数据表;SHOW databases;查看数据库;USE ***;选中一个数据库;SHOW tables;查看这个数据库里面的数据表。
CREATE DATABASE test; --创建数据库
USE test;
CREATE TABLE students(
id INT,
name varchar(100),
score INT,
gender varchar(100)
); --创建表
SHOW CREATE TABLE students; --查看刚刚创建students的语句
DESC students; --查看表的字段信息
TRUNCATE TABLE students; --清空表数据,但表还在
DROP TABLE students; --删除表
DROP DATABASE test; --删除数据库
DESC 将输出字段信息:
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(100) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
SELECT 查询
SELECT用于选取数据。
SELECT * FROM table1; --从table1中选取所有数据
SELECT id,score FROM students; --从students中选取id列和score列(name列不会返回,返回的数据是两列)
SELECT score/2 FROM students; -- 输出score除以2的值,列名就叫score/2
SELECT DISTINCT score FROM students; --列出score列其中所有不同的值,返回的score列里同分的只保留一个
AS 选取别名
你可以为每个列名选取一个别名,直接附在列名的后面就可以了
SELECT id AS stunumber,score AS point FROM students;
输出列表头的id会变成stunumber。AS通常可以省略
WHERE 条件
WHERE 子句用于提取那些参数满足指定条件的记录。
WHERE后的条件是布尔判断值可以使用关系运算符,不等号用<>表示,不能连等,字符串按字典序;也可以用NOT AND OR逻辑运算符,优先级从前往后,可以加上括号改变优先级。
SELECT * FROM students WHERE score>=95; --只返回score值大于等于95的横行记录
SELECT * FROM students WHERE 85<=score AND score<=90 AND gender = 'M';
--返回score在85到90且gender是M的行
BETWEEN、LIKE 和 IN
BETWEEN表示“在……之间”,如85<=score AND score<=90等价于BETWEEN 85 AND 90(左闭右闭);IN表示“在这……其中”,可在多个之中选择,如gender='M' OR gener='F'等价于gender IN ('M', 'F');LIKE用于字符串通配,如WHERE name LIKE '%a'表示“以a结尾的”。在SQL中,%代表0,1或多个任意字符,_代表一个任意字符;[a-z]和[^123]等则代表选定的字符集之一,规则同正则表达式
ORDER BY 排序
这个用于排序,排序输出的数据。
SELECT id,score FROM students ORDER BY score; --按score从小到大
SELECT id,score FROM students ORDER BY score DESC; --按score从大到小
SELECT id,score FROM students ORDER BY score DESC, id; --按score从大到小,同分再按id从小到大
语句是串联起来的,ORDER BY放到WHERE之后,先筛选,再排序。
LIMIT 只返回部分数据
如果返回的数据太多了,我们可以使用LIMIT只返回一部分数据
SELECT * from table1 LIMIT 3; --只取前三个数据
SELECT * from table1 ORDER BY score LIMIT 3; --排序后取前三个
SELECT * from table1 LIMIT 3 OFFSET 4; --从第四个数据开始(0based)只取前三个数据,即4, 5, 6行。超出下标的忽略
并非所有数据库都支持LIMIT - OFFSET语法,但每款软件都有自己的选取数据语法。
INDEX 索引
如果经常根据某一列进行查询,可以根据这一列创建索引:
CREATE INDEX indexofscore ON students (score);
ALTER TABLE students ADD INDEX indexofscore (score, id); --都可以创建索引
CREATE UNIQUE INDEX indexofscore ON students (score);--创建一个唯一索引,保证 score 唯一
ALTER TABLE students DROP INDEX indexofscore; --删除索引
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,例如gender 列,大约一半的记录值是 M,另一半是 F,因此,对该列创建索引就没有意义。
索引将加入额外信息维护数据,使查询更快;但在增删改时也要更新索引,所以修改数据会变慢。
增删改
INSERT INTO 插入
插入几行数据
INSERT INTO table1 VALUES (value1,value2,value3);
--插入一列(value1,value2,value3)到table1表,按顺序对应原来的列
INSERT INTO students (score,id,gender)
VALUES (89,5,'M'), (90,6,'M'); --可以指定每个数据对应的列,可以插入多个数据
修改完成后会返回信息,有多少行被修改
Query OK, 6 rows affected (0.02 sec)
Rows matched: 6 Changed: 6 Warnings: 0
UPDATE 更新
修几行的数据
UPDATE table1
SET column1 = value1, column2 = value2, ...
WHERE condition;
对于每个符合 WHERE 条件的行,修改 SET 里指定的数据列,如果没有WHERE条件,就修改全部的数据
UPDATE students SET score=100 WHERE gender='M'; --gender为M的全部修改为100分
UPDATE students SET score=score+id WHERE gender='M'; --gender为M的全部加上id。(不能用+=)
DELETE 删除
删除一些行的数据
DELETE FROM table1 WHERE condition;
DELETE FROM students WHERE score>100;
每个符合 WHERE 条件的行都会被删除,如果没有WHERE条件,整个表的行都被删除。
JOIN 连接查询
现在每个学生还有一个班,为了表示每个学生的班,再加一列 class:
| id | name | score | gender | class |
|---|---|---|---|---|
| 1 | Alice | 90 | F | 1 |
| 2 | Bob | 92 | M | 2 |
| 3 | Carol | 90 | F | 3 |
| 4 | David | 98 | M | 2 |
在另一个表 classes 里,是每一个班的名字:
| id | name |
|---|---|
| 1 | 火箭班 |
| 2 | 自动化 |
| 3 | 编程班 |
| 4 | 战神班 |
现在要查询全体学生所在的班,也就是查询 student 表的同时根据 student.class 再到 classes 表中附上一列 class.name,这就要用到连接查询。
SELECT * FROM students /*选取 students 里的数据*/
INNER JOIN classes /*并和 classes 取积*/
ON students.class=classes.id; /* 保留 students.class=classes.id 的值*/
我们得到的两个表拼起来后的输出:
+----+-------+-------+--------+-------+----+-----------+
| id | class | name | gender | score | id | name |
+----+-------+-------+--------+-------+----+-----------+
| 1 | 1 | Alice | F | 90 | 1 | 火箭班 |
| 2 | 1 | Bob | M | 92 | 1 | 火箭班 |
| 3 | 1 | Carol | F | 90 | 1 | 火箭班 |
| 4 | 2 | David | M | 98 | 2 | 自动化 |
+----+-------+-------+--------+-------+----+-----------+
如果没有 ON,那么就不会筛选数据,直接取两个表的直积(16个数据)
AS 给表取别名
上面表中 id 和 name 都重复出现了,如果不用 SELECT *,而是只取部分列,要用“表名.列名”的方式区分开(students.id 和 classes.id),而表的名字多次出现 太长了,可以为他设置别名(AS 可以省略)。
SELECT s.id, c.name AS classname, s.name, s.gender, s.score FROM students AS s
INNER JOIN classes AS c
ON s.class=c.id;
这样就符合我们的阅读习惯了:
+----+-----------+-------+--------+-------+
| id | classname | name | gender | score |
+----+-----------+-------+--------+-------+
| 1 | 火箭班 | Alice | F | 90 |
| 2 | 火箭班 | Bob | M | 92 |
| 3 | 火箭班 | Carol | F | 90 |
| 4 | 自动化 | David | M | 98 |
+----+-----------+-------+--------+-------+
各种形式的 JOIN
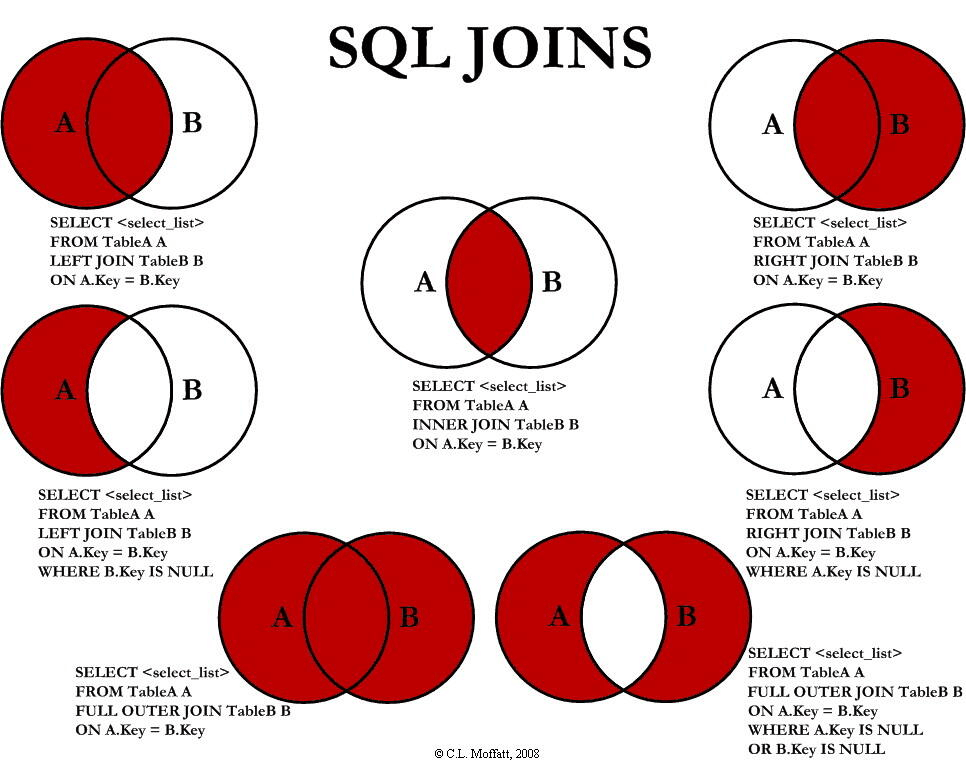
INNER JOIN:将集合取直积,并只返回符合条件的数据。
LEFT (OUTER) JOIN:确保左表的每一行都保留,如果左表有一行配不上任何右表,他仍会显示出来,在右表有关的列显示 NULL。
RIGHT (OUTER) JOIN:同上,确保左表的每一行都保留。如果把上面的例子改成 RIGHT JOIN,就会多出一行没有人的“战神班”,其他列全为 NULL
FULL (OUTER) JOIN:结果上,FULL JOIN 同时拥有 LEFT JOIN 和 RIGHT JOIN 多出来的行。MySQL 是不支持 FULL JOIN 的。
数据库操作和关系模型
Primary Key 主键
关系数据库里,每一行是一条“记录”,每一列是一个“字段”。两条记录不能完全相同,至少要有一个能区分他们的字段,使每条数据都不相同,这个字段叫做主键(Primary Key)。比如在上面的 students 表里,性别和分数可以相同,名字也可以一样,id就适合成为主键,每个 id 可以唯一定位到一个人。
主键是用来直接定位一个记录的,一旦插入就最好不要更改。
数据类型
这是关系数据库,所以每个字段要有唯一的类型,在 students 表中,id、score是整数,而 name、gender则是字符串。
| 一些类型 | 描述 |
|---|---|
| INT | 32位有符号整数 |
| BIGINT | 64位有符号整数 |
| REAL/FLOAT | 32位IEEE浮点 |
| DOUBLE | 64位IEEE浮点 |
| DECIMAL(p,s) | 精确十进制实数,最多p位,小数位最多s位 |
| CHAR(n) | 定长度为 n 的字符串 |
| VARCHAR(n) | 变长字符串,最长为n |
| BOOLEAN | true或者false |
| DATE/TIME/DATETIME | 储存日期,时间。不同数据库规则有差异 |
一般最常见的就是整数 INT 和 字符串 VARCHAR(n)。
Constraints 约束
每一个字段都可以有自己的约束规则,比如不能为空(NOT NULL),唯一(UNIQUE)等等。上面的PRIMARY KEY也是一种约束。约束在创建表的时候就可以添加在数据类型后面或者使用CONSTRAINT单独添加。
CREATE TABLE table_name(
column_name1 type constraint_name,
column_name2 type constraint_name,
column_name3 type constraint_name,
CONSTRAINT constraint_name ……
);
CREATE TABLE Orders(
O_Id int NOT NULL,
OrderNo int NOT NULL CHECK (OrderNo>0),
P_Id int,
PRIMARY KEY (O_Id),
CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
NOT NULL:表示本字段不接受 NULL 值,必须给定值。
UNIQUE:保证该字段在表中不重复
PRIMARY KEY:表示这是主键,主键只能有一个,数据上的限制相当于 NOT NULL 加上 UNIQUE
FOREIGN KEY:表示这是外键,每个外键中的值对应另一个表中的 UNIQUE,比如 students.class 就是指向 classes.id 的外键。逻辑上, students.class 就是用来对应 classes.id 的,即使没有显式指明外键也能连接查询;指定外键后语义更明确,程序会预防插入非法值,外键必须在另一个表里存在,但使用外键也会占用更多的资源。
CHECK:为字段添加条件约束,如
CHECK (OrderNo>0)限制只能取正数DEFAULT:为字段添加默认值,如
score INT DEFAULT 60不给定分数的值,默认赋值60AUTO_INCREMENT:表明该字段无需赋值,每次创建时都会自动加一,多用于没有实际意义的主键。
NULL 的应用
没有限定NOT NULL,没有默认值又没有给定值的数据就是 NULL。WHERE 条件中判定 NULL 不能用等于号。
SELECT score FROM students WHERE score IS NOT NULL; --IS NULL表示是NULL;IS NOT NULL表示不是NULL
SELECT id, IFNULL(score,0) FROM students; --有分数的输出分数,分数为NULL的输出成0
函数
SQL 语句里提供丰富的函数供我们使用,一类是聚合(aggregate)函数,另一类是标量(scalar)函数。
标量函数
这些函数进一个值,出一个值,没有什么特殊的。如:
- LEN():字符串长度
- ROUND():浮点数四舍五入
- UCASE():字符串转为大写
- NOW():当前时间
聚合函数
聚合函数参数是表中的一列,输出一个数。
- AVG():返回平均值
- SUM():返回和
- COUNT():返回长度
- MIN() MAX():返回最值
SELECT COUNT(id) FROM students; --一共有多少个id,即数据数量,输出列名就是COUNT(id),只有一条数据
SELECT AVG(score) FROM students; --求平均分
SELECT class, AVG(score) FROM students; --这是错误的,class列有四行,AVG(score)只有一行,拼不出表
GROUP BY 分组查询
上面的第三句失败了,如果我想查询每个班的平均分,那应该使用 GROUP BY 查询:
SELECT class, AVG(score) FROM students
GROUP BY class;
按照class分组,每一组计算一个 AVG(score),所以 AVG(score) 有了三行,class也是三行,输出的就是每个班的平均分。GROUP BY也可以接受几个值,把值不一样的都分开统计,比如GROUP BY class, gender可以统计每个班每个性别的平均分。
GROUP BY 想和条件筛选一起用怎么办?WHERE 可以在 GROUP BY 之前用,但不能放在 GROUP BY 之后,如果是函数算出的东西还要筛选,HAVING 就排上了用场。
SELECT class, AVG(score) FROM students GROUP BY class
HAVING AVG(score)>90; --筛选平均分大于90的班
SQL一文入门助记的更多相关文章
- 金蝶KIS&K3助记码SQL数据库批量刷新
金蝶KIS&K3助记码SQL数据库批量刷新 用的次数不多,就没有写入存储过程或者触发里面了,可以自行实现. 第一步选择对应账套的数据库,执行下面的命令,这个是一个函数. go if exist ...
- SQL注入攻防入门详解
=============安全性篇目录============== 本文转载 毕业开始从事winfrm到今年转到 web ,在码农届已经足足混了快接近3年了,但是对安全方面的知识依旧薄弱,事实上是没机 ...
- SQL注入攻防入门详解(2)
SQL注入攻防入门详解 =============安全性篇目录============== 毕业开始从事winfrm到今年转到 web ,在码农届已经足足混了快接近3年了,但是对安全方面的知识依旧薄弱 ...
- [转]SQL注入攻防入门详解
原文地址:http://www.cnblogs.com/heyuquan/archive/2012/10/31/2748577.html =============安全性篇目录============ ...
- SQL Server复制入门(一)----复制简介【转】
SQL Server复制入门(一)----复制简介 简介 SQL Server中的复制(Replication)是SQL Server高可用性的核心功能之一,在我看来,复制指的并不仅仅是一项技术,而是 ...
- Bytomd 助记词恢复密钥体验指南
比原项目仓库: Github地址:https://github.com/Bytom/bytom Gitee地址:https://gitee.com/BytomBlockchain/bytom 背景知识 ...
- 【转载】SQL注入攻防入门详解
滴答…滴答…的雨,欢迎大家光临我的博客. 学习是快乐的,教育是枯燥的. 博客园 首页 博问 闪存 联系 订阅 管理 随笔-58 评论-2028 文章-5 trackbacks-0 站长 ...
- 图解SQL Server 2008入门必会
图解SQL Server 2008入门必会 https://jingyan.baidu.com/article/656db918eded1ee381249c0b.html 图解SQL Server ...
- Oracle 助记
title: Oracle 助记 Nothing is impossible! 基础操作 $ sqlplus name/pssword; # 登录数据库 $ create user username ...
- SQL Server2008从入门到全面精通 SQL数据库视频教程
第1章 SQL Server 2008入门知识:1.SQL SERVER 2008简介2.数据库概念3.关系数据库4.范式5.E-R模型6.SQL Server 2008体系结构7.安装IIS服务8. ...
随机推荐
- 推送本地镜像到Dokcer Hub仓库
# 登陆 [root@docker ~]# docker login # 注意:后面不输入网址 Login with your Docker ID to push and pull images fr ...
- 在 Linux 中找出内存消耗最大的进程
1 使用 ps 命令在 Linux 中查找内存消耗最大的进程 ps 命令用于报告当前进程的快照.ps 命令的意思是"进程状态".这是一个标准的 Linux 应用程序,用于查找有关在 ...
- LeetCode - 统计数组中的元素
1. 统计数组中元素总结 1.1 统计元素出现的次数 为了统计元素出现的次数,我们肯定需要一个map来记录每个数组以及对应数字出现的频次.这里map的选择比较有讲究: 如果数据的范围有限制,如:只有小 ...
- 教程:Android手机安装Debian+Wine,打造完全开源的兼容Windows的GNU/Linux!
构建好的系统下载见这里: https://www.cnblogs.com/tubentubentu/p/16721884.html 测试的Android版本: 10 首先下载安装Real VncVie ...
- C#-11 接口
一 什么是接口 接口是指定一组函数成员而不实现它们的引用类型. class Program { static void FlyFunc(IFly obj) { obj.Fly(); } static ...
- 初等数论学习笔记 III:数论函数与筛法
初等数论学习笔记 I:同余相关. 初等数论学习笔记 II:分解质因数. 1. 数论函数 本篇笔记所有内容均与数论函数相关.因此充分了解各种数论函数的名称,定义,符号和性质是必要的. 1.1 相关定义 ...
- 条件期望:Conditional Expectation 举例详解之入门之入门之草履虫都说听懂了
我知道有很多人理解不了 "条件期望" (Conditional Expectation) 这个东西,有的时候没看清把随机变量看成事件,把 \(\sigma\)-algebra 看成 ...
- redis 分布式锁 PHP
redis分布式 1.redis是单线程操作 2.分布式会出现的问题,死锁 3.redis分布式(集群).多台服务器里面都有多个单机redis.然后这些redis之间相互链接.还有查看各个单台服务器之 ...
- SpringBoot内置工具类,告别瞎写工具类了
不知大家有没有注意到,接手的项目中存在多个重复的工具类,发现其中很多功能,Spring 自带的都有.于是整理了本文,希望能够帮助到大家! 一.断言 断言是一个逻辑判断,用于检查不应该发生的情况 Ass ...
- 题解 AT2361 [AGC012A] AtCoder Group Contest
\(\sf{Solution}\) 显然要用到贪心的思想. 既然最终的结果只与每组强度第二大选手有关,那就考虑如何让他的值尽可能大. 其实,从小到大排个序就能解决,越靠后的值越大,使得每组强度第二大选 ...