ByteHouse:基于 ClickHouse 的实时计算能力升级
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
ByteHouse 是火山引擎数智平台旗下云原生数据分析平台,为用户带来极速分析体验,能够支撑实时数据分析和海量离线数据分析;便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性,助力客户数字化转型。
ByteHouse 在字节跳动的发展历程
从 2017 年开始,字节内部的整体数据量不断上涨,为了支撑实时分析的业务,字节内部开始了对各种数据库的选型。经过多次实验,在实时分析版块,字节内部决定开始试水 ClickHouse。
2018 年到 2019 年,字节内部的 ClickHouse 业务从单一业务,逐步发展到了多个不同业务,适用到更多的场景,包括 BI 分析、A/B 测试、模型预估等。
在上述这些业务场景的不断实践之下,研发团队基于原生 ClickHouse 做了大量的改造,同时又开发了大量的优化特性。
2020 年, ByteHouse 正式在字节跳动内部立项,2021 年通过火山引擎对外服务。
截止 2022 年 3 月,ByteHouse 在字节内部总节点数达到 18000 个,而单一集群的最大规模是 2400 个节点。
可以想象,2400 台服务器同时堆在一起是怎样一副壮观的景象。ByteHouse 支撑的最大数据量可达 700 个 PB,自上线以来,支持了 80%大家非常耳熟能详的字节跳动业务。
选择 ClickHouse 作为实时分析的基建
选择原因
那么,字节为什么会选择 ClickHouse 作为内部分析型数据库的基础呢?
2017 年,基于众多的业务场景以及海量分析数据,字节内部对于实时数仓的要求也越来越高。

事实上,要同时满足图上所示的这些要求有着相当大的难度。
首先,要解决数据量大的问题,同时这个数据量还会不断地增长,2019 年,字节内部每天新增的数据量就达到了 100 个 TB。
其次,在数据量大的基础上,仍要保有包含以下三个方向非常强的灵活性:
数据源头的灵活性。也同时去支持批示数据和流式数据的导入,实现批流一体。
查询性能的多样性。希望同时能够支持到明细数据和聚合查询,不希望在数据库当中只存聚合的数据。
交互式分析需求的灵活性。数千个维度都要能够达到秒级的快速响应。
最后,在满足前述两点基础上,还要做到成本可控。最开始,团队内部其实也列出了很多开源解决方案,例如 Redis、Apache 等等,这些方案其实都可以实现上述要求的一点到两点。但如果要去维护不同的开源数据库,成本就会变得非常高,团队希望尽量选择一款可以避免成本无限扩展的计算引擎。与此同时,团队也希望数据整体成本可控的,服务器成本的增加是线性的,而不是指数的。
线性:数据存储都通过磁盘来进行
指数:指数通过内存来进行(快但贵)
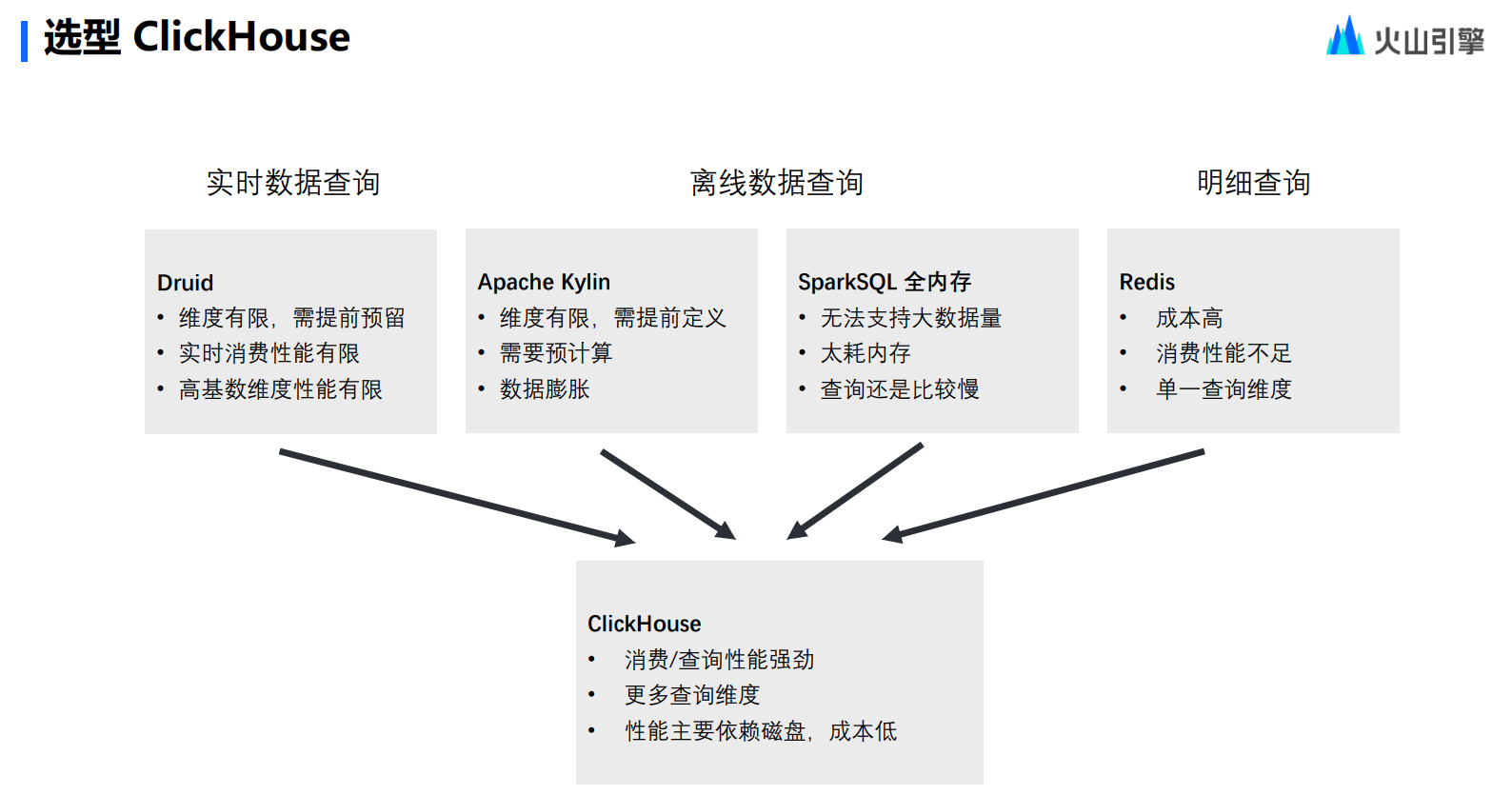
最后,团队发现作为开源产品的 ClickHouse,竟然能够同时满足所有的要求——性能强劲,灵活支持,主要依赖磁盘,成本相对可控,真正做到了 All In One。
多快好省——ClickHouse 基础能力介绍
ClickHouse 是一个用于联机分析处理(OLAP)的列式数据库管理系统,源自俄罗斯的搜索引擎 Yandex。它的最大特点可以概括为”多快好省“。
“多”——指集群规模多。在字节内部最大的集群规模是 2400 台,ClickHouse 可以完全支持。
“快”——在大数据规模下,ClickHouse 也能提供秒级的单表查询性能,性能强。
“好”——指无入侵式架构,可以轻松集成到现有的系统,可复用性好。
“省”——ClickHouse 使用磁盘作为性能的基准,不使用内存,成本随着规模的扩展,可控性强。
开源 ClickHouse 的瓶颈
当字节内部的整体使用规模到了 18000 台服务器之后,其实也发现 ClickHouse 一些瓶颈,比如

OLAP 能力不够好用。在一些特定的场景下,如 upset 场景,实时数据更新场景……原生 ClickHouse 能力难以支持。
ClickHouse 在单表性能上非常的强劲,但多表能力非常局限,且对标准 SQL 兼容性低。
缺乏成熟运维管理工具,运维复杂程度高,需要投入极大的人力,这是一个很大的缺陷。
ClickHouse 是 MPP 架构(存算一体架构),性能和扩展性极强,但缺陷也很明显:
横向扩容成本非常高,增加一个节点要进行数据重新定位。
隔离性差,单一用户的查询会非常容易打满整个集群,导致 ClickHouse 并发度不高。
ByteHouse:实时场景全面进化
字节内部针对 ClickHouse 的很多特性进行了全新的研发,推出了 ByteHouse 产品,在实时场景上全面实现了进化。
OLAP 能力进化:丰富的自研表引擎

ClicHouse 本身就可以支持非常丰富的表引擎,但 ByteHouse 在此基础上逐渐弥补了各种表引擎的不足,衍生出更多全新的表引擎,使 ByteHouse 能够做很多开源 ClickHouse 做不到的场景。
高可用表引擎。相比社区的 ReplicatedMergeTree,高可用表引擎支持的整体表数量更多,支持的集群规模更大,稳定性更高。
实时数据引擎。 ByteHouse 的实时数据引擎相比起社区所支持的数据实时数据引擎,消费能力更强,并且能够支持 At—Least once 语义,能够解决社区版 Kafka 单点写入的性能瓶颈问题。
Unique 引擎。这是最关键的一点,它解决了社区版 Replacing Merge 实时更新延迟问题,真正能够做到实时 upset。
Bitmap 引擎。它可以在特定的场景(如用户圈选)当中,支持大量的“交并补”,做到 10 倍到 50 倍的性能提升。
相比 ClickHouse,ByteHouse 在这四个引擎加持下,整体使用场景做到了大幅的增强。
比如在有一些场景下面,实时消费的性能是不够的,需要做到 At—least once 或者 Exactly once 语义,社区版的 ClickHouse 是做不到的,而 ByteHouse 可以;又比如用户希望导入之后能做到实时地去重,而不希望等到 Merge 之后才能去重,ClickHouse 同样做不到,而 ByteHouse 可以做到。
性能优化:优化器、字典、索引支持
ClickHouse 最大的特点是单表性能强劲,但多表性能存在极大的缺陷。

优化器
主要的问题在于 ClickHouse 不支持优化器。众所周知,在 MySQL、PGSQL、 Oracle 这类传统数据库当中,优化器对于多表的性能优化起到了非常大的作用。此外,优化器还有一个非常关键的作用,就是它能改写 SQL。在不支持优化器的前提下,产生了两个比较大的缺陷。
多表性能差。
从 MySQL 或者很多传统数据库迁移到开源 ClickHouse 之后,要做很多 SQL 的改写。
而 ByteHouse 自研了基于 CBO 和 RBO(基于代价和基于规则的优化器),同时支持了很多优化器的多如牛毛的特性,包括多层嵌套的下推、Join 子查询的下推、Join-Reorder、Bucket Join、Runtime Filter 等。
在做到整体优化器的支持之后,ByteHouse 它能够做到 TPC-DS 的性能,在覆盖率层面, 可以达到 99 条 sql100%覆盖,每一条的查询都比社区版 ClickHouse 要更快。
全局字典、索引支持
参考大量不同的 OLAP 或者 OLTP 数据库,ByteHouse 还做了很多的优化。比如支持了全局字典,支持了更多的索引,如 Bitmap index,可以让查询效率更快。开源 ClickHouse 所具备的“多快好省”,在 ByteHouse 的优化之下,让快更快,以快至快。
运维进化:集群运维能力 & 稳定性优化

第一是集群运维能力优化。之前提到,在更多的服务器场景下面,急需运维工具,使得 SRE 或者 Devops 运维人员的人效更高。为了解决这些问题,ByteHouse 提供了以下工具。
标准化运维工具。比如像在白屏上自动下发配置的工具,在白屏上进行版本自助升级的工具,节点重启、替换等等标准化运维工具。
集群健康度的检测工具。相当于集群的实时巡检,可以报告当前集群是健康状态还是有问题的状态,这些问题是什么?这些问题怎么解决?更大程度地把问题前置化,避免在紧急的时刻要去处理大量的问题。
当问题发生时的诊断工具。比如大查询的诊断,和集群当时负载的诊断。
通过这三个方向的工具,能够让整体的运维效率达到非常高的程度,并且达到可复制化。(在字节跳动内部,总共 18000 个节点,只有不到 10 个运维人员的支持。通过 ByteHouse 这些工具,能够做到自动化、高效化、可复制化)
第二方面是稳定性优化。在长达 6 年多的 ByteHouse 集群运营当中,研发团队发现 ClickHouse 存在大量的稳定性痛点。而 ByteHouse 优化到了代码根本层面的修复,包括云数据的持久化,包括主备同步查询,包括慢节点模式, Zookeeper 的自动的清理和修复等等。当这些问题不再发生后,运维同学可以节省出大量的人力用于工具的开发,最终能够形成一个完整的产品、非常高的人效以及整体非常好的终端用户查询性能的正向循环。
架构进化:存算分离

在 MPP 1. 0 存算一体的模式下面,有着隔离比较困难以及扩容比较困难的瓶颈。ByteHouse 基于这些痛点做了非常大的投入,直接研发出了 MPP 2. 0 的架构,也就是存算分离架构。
简单来说,存算分离架构——就是计算层 Shared Nothing,存储层 Shared Everything。这样做的好处可以分成两个层次。
第一层:更好地做到资源隔离。每一个计算任务都会提交到不同的计算资源上面去,不同用户之间不会有影响的。随时能够扩容计算资源和存储资源,也能够缩容计算资源。结合云计算一些按秒计费的策略,最终能做到用户的成本进一步的降低。
第二层:真正做到云原生(Cloud native),ByteHouse 的存储层既支持 HDFS,也支持 S3 对象或者其他的对象存储,比如火山的 TOS。这样可以支持 MPP2. 0 架构下的 ByteHouse,真正能够实现云原生的部署。
ByteHouse 多场景实践

场景一:实时监控
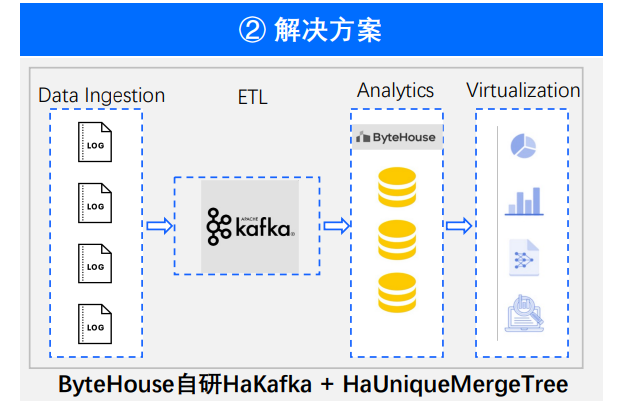
ByteHouse 在实时场景上最典型的应用就是实时监控业务。
比如在抖音的线上活动当中,经常会有数据实时监控需求,从生产到数据展现在大屏上,往往达到分钟级甚至秒级的数据延迟。而 ByteHouse 加入其中,带来了以下价值。
非常高的吞吐性能。实时的线上数据都能够被 ByteHouse 的计算引擎所接收到,而最终能够达到 250W/写入 TPS 的性能指标。
非常高的查询性能。ByteHouse 可以使数据从输入端到输出端的流程达到秒级。
数据保障。ByteHouse 能够最终保障到 Exactly Once 的语义,保证数据不丢失,也不会重复。最终达到数据是高效存储的,准确的,可以在秒级被查询到的。
场景二:行为分析
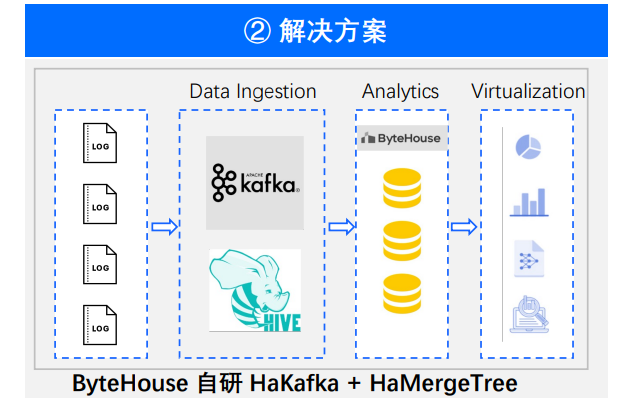
在行为分析的场景下,可以结合到运维同学非常熟悉的一些产品,类似一些事件分析、留存分析、转化分析、各种漏斗图表等等产品功能的底层,其实都非常适合 ByteHouse 作为支撑的。
事实上, 在 2017 年,ByteHouse 最早支撑的内部场景也是行为分析场景。行为分析场景需要非常大数据量的存储、非常高的数据读取、响应的要求,以及非常大的成本诉求。 ByteHouse 的优势价值有以下三点。
支撑大集群。ByteHouse 通过 HaMergeTree 引擎的支持,通过集群扩容能力的研发,最终才能够让个场景能够支撑到 2400 台集群的极大规模。
秒级响应。想做到秒级响应,就需要做到不断地优化支持——通过字典编码来进行减少序列化和反序列化的开销,查询性能才能得到提升。最终达到的效果是 90% 的查询场景能够在 5 秒钟~ 7 秒钟之间得到返回。在这么大一个量级下面,ByteHouse 仍然能够达到 10 秒钟之内的响应,是一个非常了不起的成果。
降本增效。数据量级怎样能够做到进一步的降低成本?事实上,用户每天访问一定是有热数据的,也有着一些长期需要被查询的冷数据。在 ClickHouse 的基础上面, ByteHouse 做了二次迭代开发——在 HDFS 上面进行冷热的分存。热数据存储在本地,在 SSD 磁盘上加快响应;冷数据放在 HDFS 上来进行存储成本的降低。不仅可以做到大集群规模响应很快,它的成本仍然能够保持,非常具有性价比。
场景三:精准营销
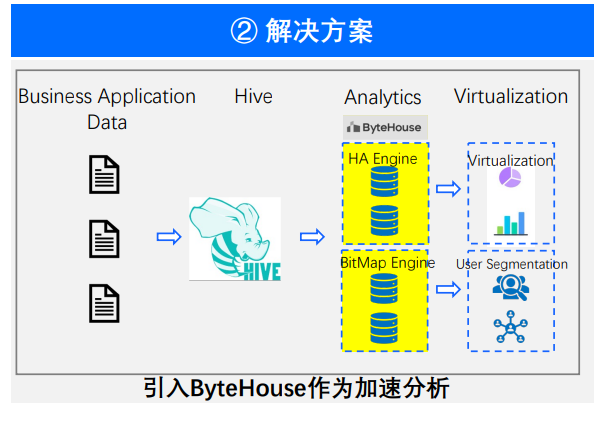
最后是精准营销场景。这个场景其实在生产场景下面非常的普遍,每一个产品都需要精准营销,每个产品都需要画大量的漏斗图。在精准营销的背后,如果使用 ByteHouse 来进行数据支撑,会有三个非常重要的优化节点。
秒级响应。ByteHouse 的优化器支持对于秒级响应做到了很大的优化。在优化器的加持下面,能够做到 P95 的整个时长响应能够在一秒之内,甚至能够在半秒钟之内,满足了用户实时看数,实时分析市场行情的需求。
交并补计算。因为人群的圈选,事实上在用户打了大量的标签,这些标签就是 0 和 1。这些 0 和 1 在进行交并补的计算之后,最终效果可以达到 10 倍到 50 倍的性能提升。
激发效应。因为 ByteHouse 有更多维度的查询能力和非常快的响应能力,所以用户的每一条查询链路,从输入到输出,都能在一秒钟之内得到响应。所以用户的思维是可以不断地去激发,不断地去创造,不断地去迭代的,这条数据链路精准营销的价值得到不断地提升,最终能够带来生产上的真实产品价值和真实业务价值。
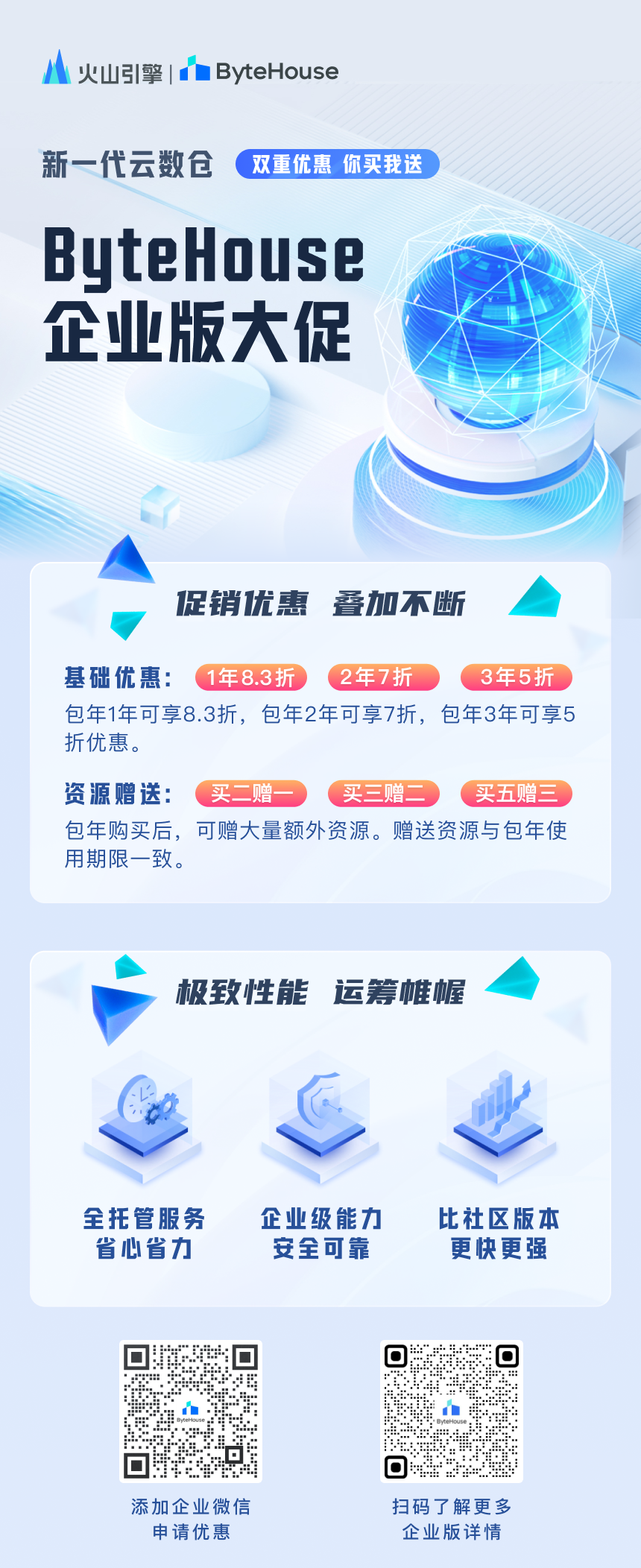
为了助力企业抓稳数字化发展机遇,加速企业数智能力升级,自 2023 年 2 月 1 日开始,火山引擎 ByteHouse 特别推出为期一年的企业级特惠活动。
企业通过本次活动购买 ByteHouse 服务,包年 1 年可享 8.3 折,包年 2 年可享 7 折,包年 3 年可享 5 折。除基础优惠之外,企业包年购买后,还可获得大量额外资源免费赠送,买二送一, 买三送二,买五送三(赠送资源与包年使用期限一致),且以上两项优惠可叠加享受!
点击跳转 ByteHouse云原生数据仓库 了解更多
ByteHouse:基于 ClickHouse 的实时计算能力升级的更多相关文章
- 基于TensorRT车辆实时推理优化
基于TensorRT车辆实时推理优化 Optimizing NVIDIA TensorRT Conversion for Real-time Inference on Autonomous Vehic ...
- 字节跳动基于ClickHouse优化实践之“多表关联查询”
更多技术交流.求职机会.试用福利,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻.但在字节大量 ...
- 基于Xenomai的实时Linux分析与研究
转自:http://blog.csdn.net/cyberlabs/article/details/6967192 引 言 随着嵌入式设备的快速发展,嵌入式设备的功能和灵活性要求越来越高,很多嵌入式设 ...
- 项目-基于视频压缩的实时监控系统--tiny6410
项目-基于视频压缩的实时监控系统--tiny6410 @国嵌linux学习笔记. 1. 构造服务端结构体 server struct server { int epfd; //保存epoll指针 st ...
- 基于GPUImage的实时美颜滤镜
1.背景 前段时间由于项目需求,做了一个基于GPUImage的实时美颜滤镜.现在各种各样的直播.视频App层出不穷,美颜滤镜的需求也越来越多.为了回馈开源,现在我把它放到了GitHub https:/ ...
- (二): 基于ZeroMQ的实时通讯平台
基于ZeroMQ的实时通讯平台 上篇:C++分布式实时应用框架 (Cpp Distributed Real-time Application Framework)----(一):整体介绍 通讯平台作为 ...
- [视觉] 基于YoloV3的实时摄像头记牌器
基于YoloV3的实时摄像头记牌器 github:https://github.com/aoru45/cards_recognition_recorder_pytorch 最终效果 数据准备 数据获取 ...
- 前端Web浏览器基于Flash如何实时播放监控视频画面(前言)之流程介绍
[关键字:前端浏览器如何播放RTSP流画面.前端浏览器如何播放RTMP流画面] 本片文章只是起到抛砖引玉的作用,能从头到尾走通就行,并不做深入研究.为了让文章通俗易懂,尽量使用白话描述. 考虑到视频延 ...
- 制作属于自己的翻译软件(基于PyQt5+Python+实时翻译)
目录 制作属于自己的翻译软件(基于PyQt5+Python+实时翻译) 翻译软件上传到github上. 软件截图 主要的思想 界面方面 程序方面 制作属于自己的翻译软件(基于PyQt5+Python+ ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
随机推荐
- 通过n个线程顺序打印26个英文字母
通过n个线程顺序打印26个英文字母,例如 n=3 则输出: thread0: a thread1: b thread2: c thread0: d 方案一:轮询 多个线程不断轮询是否是该线程执行任务. ...
- JS斐波那契数列O(n)
function fibonacci(n) { return fib(n)[n] } var fib=(function(n){ var meo=[0,1] return function(n){ f ...
- simis报错总结
--笔记开始: 1.在前台模块处理时,[单位应收核定]比[人员缴费信息]的在职人员多一人,但是总金额一样,可能是以下原因造成!!! A.从后台看,若正常核定在职的ab08比ac13多一个人,可能是ac ...
- Js-document操作
# 直接获取标签 document.getElementById('gundong') #获取id为gundong的元素 document.getElementsByClassName('qalist ...
- 2022/7/28 第七组陈美娜 API类
API:Application Program Interface应用程序接口 JDK给我们提供的一些已经写好的类,可以直接调方法来解决问题 类的方法在宏观上都可以称为接口 接口:1.interfac ...
- char *setlocale(int category, const char *locale)
category -- 这是一个已命名的常量,指定了受区域设置影响的函数类别. LC_ALL 包括下面的所有选项. LC_COLLATE 字符串比较.参见 strcoll(). LC_CTYPE 字符 ...
- 接口返回JSON字符串压缩和解压
using System;using System.Collections.Generic;using System.Linq;using System.Web;using System.IO;usi ...
- Linux让部署在服务器上的项目一直保持运行状态…&跑多个项目
在idea通过package得到的.jar包或者.war包可通过 java -jar xxx.jar/xxx.war 命令直接在linux或者windows系统运行: 将打好包的项目放在linux ...
- 6vue分支循环
分支v-if <!DOCTYPE html> <html lang="en"> <head> <meta charset="UT ...
- 艾思(aisi)软件主营业务介绍
1. 移动应用开发 按客户端分类: APP定制开发 小程序定制开发 H5, Web定制开发 微信公众号开发 iOS开发 安卓开发 按行业分类(不限于): 电商, 单商户, 多商户商城 教育APP 聊天 ...