Hadoop单节点启动分布式伪集群
emm~ 写这篇博客只是手痒,因为开发环境用单节点就够了,生产环境肯定是真实集群,所以这个伪分布式纯属娱乐而已。
配置HDFS
1. 安装好一台hadoop,可以参考这篇博客。
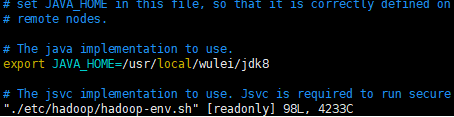
2. 在hadoop目录下编辑文件指定java环境变量 vim ./etc/hadoop/hadoop-env.sh
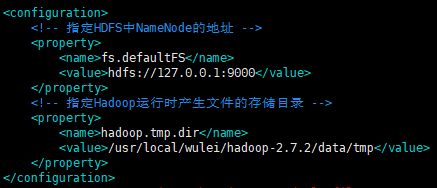
3.指定hdfs存储位置和地址 vim etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/wulei/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
core-site.xml
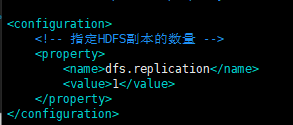
4. 指定hdsf副本数量 vim etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
hdfs-site.xml
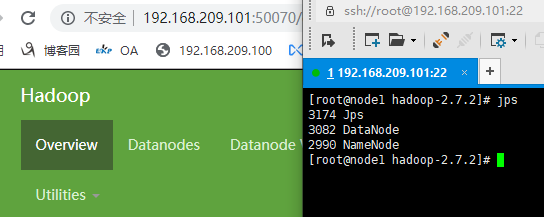
启动集群
(a)格式化NameNode(第一次启动时格式化会生成刚刚指定的data目录,以后就不要总格式化。格式化会让集群找不到已往数据datanode启动失败,所以一定要先删除data文件夹和log文件夹,然后再格式化)
[root@node1 hadoop-2.7.2]# bin/hdfs namenode -format
(b)启动NameNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
(c)启动DataNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
jps查看节点启动状态
配置YARN
1.指定环境变量 vim etc/hadoop/yarn-env.sh

2.配置环境变量 vim etc/hadoop/mapred-env.sh

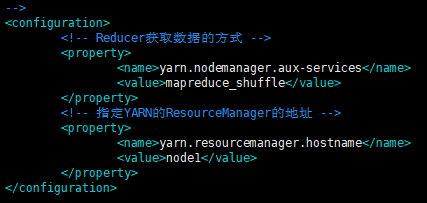
3.配置(node1是当前主机名,可以 vim /etc/hosts 指定) vim etc/hadoop/yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
yarn-site.xml
4.将mapred-site.xml.template重新命名为 mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[wulei@node1 hadoop-2.7.2]$ sudo vim etc/hadoop/mapred-site.xml <configuration>
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml

启动集群
1. 启动前必须保证NameNode和DataNode已经启动
[root@node1 hadoop-2.7.2]# jps
12133 NameNode
12203 DataNode
12303 Jps
2. 启动ResourceManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-resourcemanager-node1.out
3. 启动NodeManager
[root@node1 hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager
starting nodemanager, logging to /usr/local/wulei/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
12609 NodeManager
12371 ResourceManager
12133 NameNode
12203 DataNode
12750 Jps
[root@node1 hadoop-2.7.2]#
Hadoop单节点启动分布式伪集群的更多相关文章
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- windows单节点下安装es集群
linux下的es的tar包,拖到windows下,配置后,启动bin目录下的bat文件,也是可以正常运行的. 从linux下拷的tar包,需要修改虚拟机的内存elasticsearch.in.bat ...
- Kafka 单节点多Kafka Broker集群
Kafka 单节点多Kafka Broker集群 接前一篇文章,今天搭建一下单节点多Kafka Broker集群环境. 配置与启动服务 由于是在一个节点上启动多个 Kafka Broker实例,所以我 ...
- redhat6.5 redis单节点多实例3A集群搭建
在进行搭建redis3M 集群之前,首先要明白如何在单节点上完成redis的搭建. 单节点单实例搭建可以参看这个网:https://www.cnblogs.com/butterflies/p/9628 ...
- 利用shell脚本[带注释的]部署单节点多实例es集群(docker版)
文章目录 目录结构 install_docker_es.sh elasticsearch.yml.template 没事写写shell[我自己都不信,如果不是因为工作需要,我才不要写shell],努力 ...
- Zookeeper集群搭建(单机多节点,伪集群,docker-compose集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Zookeeper详解-伪分布式和集群搭建(八)
说到分布式开发Zookeeper是必须了解和掌握的,分布式消息服务kafka .hbase 到hadoop等分布式大数据处理都会用到Zookeeper,所以在此将Zookeeper作为基础来讲解. Z ...
- zookeeper的单实例和伪集群部署
原文链接: http://gudaoyufu.com/?p=1395 zookeeper工作方式 ZooKeeper 是一个开源的分布式协调服务,由雅虎创建,是 Google Chubby 的开源实现 ...
- hadoop 2.5.1单机安装部署伪集群
环境:ubuntu 14.04 server 64版本 hadoop 2.5.1 jdk 1.6 部署的步骤主要参考了http://blog.csdn.net/greensurfer/article/ ...
随机推荐
- TCP发送窗口更新tcp_ack_update_window
在tcp_ack接收ACK处理函数中,如果确认当前走慢速路径,那么会调用tcp_ack_update_window函数检查窗口是否需要更新并更新之,并且更新未确认数据的位置,即更新窗口左边沿: sta ...
- 精讲JS逻辑运算符&&、||,位运算符|,&
1.JS中的||符号: 运算方法: 只要“||”前面为false,不管“||”后面是true还是false,都返回“||”后面的值. 只要“||”前面为true,不管“||”后面是true还是fals ...
- Oracle 表空间扩容
1 系统表空间扩容 注:表空间监测或扩容方式很多,这里只提供一种方便使用的方法 1)查询SQL 注:需要输入百分比,如:90,就可查出使用率超过90%的表空间, with t as (select b ...
- leetcode-hard-array-287. Find the Duplicate Number
mycode 77.79% class Solution(object): def findDuplicate(self, nums): """ :type nums ...
- DatabaseLibrary数据库测试
DatabaseLibrary常用关键字 关 键 字 描 述 Connect To Database 连接数据库 Connect To Database Using Custom Params ...
- logstash的index值可以为中文
logstash中的 output中 有index属性,表示在elk中的主键标识. 在实际应用中,index的值不能为大写字母,可以是小写字母.数字.下划线.中文. 这里重点强调index为中文时,注 ...
- 理解MVC/MVP/MVVM的区别
转载至[http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html] MVC 所有的通信都是单向的. M(Model)V(View)C(Contro ...
- Mac/Linux 编译安装redis
一.下载安装 官网http://redis.io/ 下载最新的稳定版本,这里是3.2.0 sudu mv redis-.tar /usr/local/ sudo tar -zxf redis-.tar ...
- Hibernate HelloWorld案例
搭建一个Hibernate环境,开发步骤: 1. 下载源码 版本:hibernate-distribution-3.6.0.Final 2. 引入jar文件 hibernate3.j ...
- go 基础 变量和常量
package main import "fmt" //全局变量,赋值 var( PI float32 = 3.1415 Count ) //全局变量,无值 var( x stri ...