使用request+bs4爬取所有股票信息
爬取前戏
我们要知道利用selenium是非常无敌的,自我认为什么反爬不反爬都不在话下,但是今天我们为什么要用request+bs4爬取所有股票信息呢?因为他比较原始,因此今天的数据,爬取起来也是比较繁琐的!接下来让我们emmmm。。。。你懂得
爬取步骤
第一步:获取股票代码
1)我们通过这个链接去网易看一下具体的股票信息,下面这个网页是乐视网的股票信息http://quotes.money.163.com/trade/lsjysj_300104.html#01b07
2)上海证券交易所的官方网站上直接告诉你了所有股票的代码,请点击市场数据---股票列表---下载---整理为csv文件(这样你就拿到了3000多个股票代码)
第二步:处理一些乱糟糟的数据,这些数据要在网页上面找。将数据下载下来,存储为csv文件。
[注意]:为什么要异常处理?
因为有些股票代码里面没有数据,也可能是空的,总之在下载的时候,由于股票代码,就会出现一系列的问题,所以对他异常处理
'''处理不规整数据'''
# http://quotes.money.163.com/trade/lsjysj_300104.html#01b07 #30010就是一个公司的股票代码
import pandas as pd
import requests
from bs4 import BeautifulSoup
log = open("error.log", mode="w", encoding="utf-8") #这是一个错误日志,打开它,把错误的记录填进去
df = pd.read_csv("code.csv")
for code in df['code']: #遍历code
try:
# 000539
# 000001 1
code = format(code, "06") # 进行格式化处理. 处理成6位的字符串 000001
url = f"http://quotes.money.163.com/trade/lsjysj_{code}.html#01b07"
# 发送请求
resp = requests.get(url) # 发送请求. 获取到数据
main_page = BeautifulSoup(resp.text, "html.parser") # 解析这个网页, 告诉它这个网页是html
main_page.find() # 找一个
main_page.find_all() # 找一堆
trs = main_page.find("form", attrs={"name": "tradeData"}).find_all("table")[1].find_all("tr") # <form name="tradeData"> #打开网页,找到网页的一个唯一属性
#这些就是网页的信息,我们对他进行处理就好
start = trs[0].find_all("input")[2].get("value").replace("-", "") #开始上市时间
end = trs[1].find_all("input")[2].get("value").replace("-", "") #今日
href = main_page.find("ul", attrs={"class": 'main_menu'}).find_all("li")[0].find("a").get('href')
# print(href) # /0600000.html#01a01
code_num = href.split(".")[0].strip("/") #对上面的字符串进行切片处理
download_url = f"http://quotes.money.163.com/service/chddata.html?code={code_num}&start={start}&end={end}&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP"
#获取到整个完整的访问股票代码的网址。
resp = requests.get(download_url)
resp.encoding = "GBK" #编码问题
file_name = main_page.find("h1", attrs={"class":"title_01"}).text.replace(" ", "")
with open(f"股票交易记录/{file_name}.csv", mode="w", encoding="UTF-8") as f:
f.write(resp.text)
print("下载了一个")
except Exception as e:
log.write(f"下载{code}股票的时候. 出现了错误. url是:{url} download:{download_url} \n ")
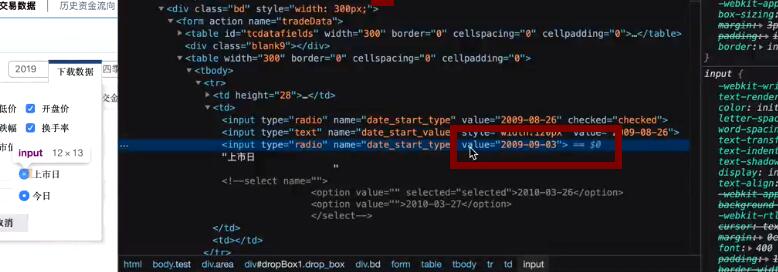
上面这样,我们的每个股票的详细信息就会下载到文件中。
第三步:将数据进行可视化操作,将收盘价,开盘价等数据,用一定的图片显示出来。
import pandas as pd
import matplotlib.pyplot as plt
import mpl_finance as mpl
from matplotlib.pylab import date2num
def main():
main_df = pd.read_csv('目录.csv', dtype=object) # 如果不写后面的dtype, 你读取的code就是数值 int, 此时默认是字符串
while 1:
code = input("请输入一个你想看到的股票代码(6位):") # 00001
if len(code) != 6:
print("代码不对. 请重新输入!")
else:
data_df = main_df[main_df['code']==code]
# 600006,东风汽车(600006)历史交易数据.csv
if data_df.empty:
print("没有这支股票")
else:
print("有这支股票")
file_name = data_df.iloc[0]['file']
show(file_name, code)
def show(file_name, code): # 显示这个股票的历史记录
data_df = pd.read_csv(f"股票所有记录/{file_name}", parse_dates=["日期"]).iloc[:100, :]
data_df = data_df[data_df['开盘价' != 0.0]]
k_data = data_df[["日期", "开盘价", "最高价", "最低价", "收盘价"]]
k_data['日期'] = date2num(k_data['日期'])
# time, open, high, low, close
# [(time, open, high, low, close), (time, open, high, low, close), (time, open, high, low, close), ()]
# gen = [tuple(value) for value in k_data.values] # 1
gen = (tuple(value) for value in k_data.values) # 2
fig, [ax1, ax2] = plt.subplots(2, 1, sharex=True)
ax2.bar(date2num(data_df['日期']), data_df['成交金额'])
ax1.xaxis_date() #x轴
ax2.xaxis_date()
mpl.candlestick_ohlc(ax1, gen)
plt.savefig("abc.jpg", dpi=1000)
plt.show()
if __name__ == '__main__':
main()
有没有发现这张图好丑,好吧!没关系的,基本实现了哈哈。

使用request+bs4爬取所有股票信息的更多相关文章
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- BS4爬取糗百
-- coding: cp936 -- import urllib,urllib2 from bs4 import BeautifulSoup user_agent='Mozilla/5.0 (Win ...
- 使用request+Beautiful爬取妹子图
一.request安装 pip install requests request使用示例 import requests response = requests.get('https://www.mz ...
- 爬虫实战3:使用request,bs4爬动态加载图片
参考网站:https://blog.csdn.net/Young_Child/article/details/78571422 在爬的过程中遇到的问题: 1.被ban:更改header的User-Ag ...
- BS4爬取物价局房产备案价以及dataframe的操作来获取房价的信息分析
因为最近要买房子,然后对房市做了一些调研,发现套路极多.卖房子的顾问目前基本都是一派胡言能忽悠就忽悠,所以基本他们的话是不能信的.一个楼盘一次开盘基本上都是200-300套房子,数据量虽然不大,但是其 ...
- BS4爬取豆瓣电影
爬取豆瓣top250部电影 ####创建表: #connect.py from sqlalchemy import create_engine # HOSTNAME='localhost' # POR ...
- 针对源代码和检查元素不一致的网页爬虫——利用Selenium、PhantomJS、bs4爬取12306的列车途径站信息
整个程序的核心难点在于上次豆瓣爬虫针对的是静态网页,源代码和检查元素内容相同:而在12306的查找搜索过程中,其网页发生变化(出现了查找到的数据),这个过程是动态的,使得我们在审查元素中能一一对应看到 ...
- python使用bs4爬取boss静态页面
思路: 1.将需要查询城市列表,通过城市接口转换成相应的code码 2.遍历城市.职位生成url 3.通过url获取列表页面信息,遍历列表页面信息 4.再根据列表页面信息的job_link获取详情页面 ...
- 爬虫基本库request使用—爬取猫眼电影信息
使用request库和正则表达式爬取猫眼电影信息. 1.爬取目标 猫眼电影TOP100的电影名称,时间,评分,等信息,将结果以文件存储. 2.准备工作 安装request库. 3.代码实现 impor ...
随机推荐
- CodeForces 724C Ray Tracing(碰撞类,扩展gcd)
又一次遇到了碰撞类的题目,还是扩展gcd和同余模方程.上次博客的链接在这:http://www.cnblogs.com/zzyDS/p/5874440.html. 现在干脆解同余模直接按照套路来吧,如 ...
- 阿里云OSS细粒度权限控制
做下工作记录: 自定义安全策略,然后授权即可 { ", "Statement": [ { "Effect": "Allow", & ...
- LeetCode 144. 二叉树的前序遍历(Binary Tree Preorder Traversal)
题目描述 给定一个二叉树,返回它的 前序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,2,3] 进阶: 递归算法很简单,你可以通过迭代算法完成吗? 解题思路 由 ...
- 一、基础篇--1.2Java集合-HashMap源码解析
https://www.cnblogs.com/chengxiao/p/6059914.html 散列表 哈希表是根据关键码值而直接进行访问的数据结构.也就是说,它能通过把关键码值映射到表中的一个位 ...
- java二进制工具
可以运用jdk工具监控java应用性能,再配合 jmeter 进行了一个长时间的加压,在加压过程中重点关注了系统资源的使用情况 D:\Program Files (x86)\Java\jdk1.8.0 ...
- Java异常超详细总结
1.1,什么是异常: 异常就是Java程序在运行过程中出现的错误. 骚话: 世界上最真情的相依就是你在try我在catch,无论你发什么脾气,我都静静接受,默默处理(这个可以不记) 1.2,异常继 ...
- 阶段3 3.SpringMVC·_05.文件上传_1 文件上传之上传原理分析和搭建环境
分成几个部分 里面可能就包含文件上传的值 提交方式要改成post 第三个就是提供一个input file的文件选择域 新建项目 新建一个项目 当前项目没有父工程 跳过联网下载 改成02 构建 编译和目 ...
- AutoResetEvent和ManualResetEvent(多线程操作)
摘自风中灵药的博客:https://www.cnblogs.com/qingyun163/archive/2013/01/05/2846633.html#!comments AutoResetEven ...
- This application's application-identifier entitlement does not match that of the installed application. These values must match for an upgrade to be allowed.
真机运行测试的时候Xcode会报这样的错误: 原因: 你的手机上已经安装了此项目. 解决办法: 把你以前安装的卸掉, 或者把这个项目的 bunldID 改了,再次运行即可.
- java数据结构之ArrayList
一.ArrayList源码注释 /** * ArrayList源码分析,jdk版本为1.8.0_121 */ public class ArrayList<E> extends Abstr ...