Elasticsearch的安装入门

大纲:
一、简介
二、Logstash
三、Redis
四、Elasticsearch
五、Kinaba
一、简介
1、核心组成
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
elk是什么:
Elastic Stack(旧称ELK Stack),是一种能够从任意数据源抽取数据,并实时对数据进行搜索、分析和可视化展现的数据分析框架。(hadoop同一个开发人员)
java 开发的开源的全文搜索引擎工具
基于lucence搜索引擎的
采用 restful - api 标准的
高可用、高扩展的分布式框架
实时数据分析的
官方网站: https://www.elastic.co/products
2、为什么要用elk?
服务器众多,组件众多,日志众多
发现问题困难,技能要求高
业务场景:《实时日志分析展现》
日志主要包括系统日志、应用程序日志和安全日志。
系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。
当务之急我们使用集中化的日志管理,例如:开源的 syslog ,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用 grep 、 awk和 wc 等 Linux 命令能实现检索和统计,
但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析 ELK 平台能够完美的解决我们上述的问题, ELK 由 ElasticSearch 、 Logstash 和 Kiabana 三个开源工具组成。
3、四大组件
Logstash: logstash server端用来搜集日志;
Elasticsearch: 存储各类日志;
Kibana: web化接口用作查寻和可视化日志;
Logstash Forwarder: logstash client端用来通过lumberjack 网络协议发送日志到logstash server;
4、ELK工作流程
在需要收集日志的所有服务上部署logstash,作为logstash agent(logstash shipper)用于监控并过滤收集日志,将过滤后的内容发送到Redis,然后logstash indexer将日志收集在一起交给全文搜索服务ElasticSearch,可以用ElasticSearch进行自定义搜索,通过Kibana 来结合自定义搜索进行页面展示。
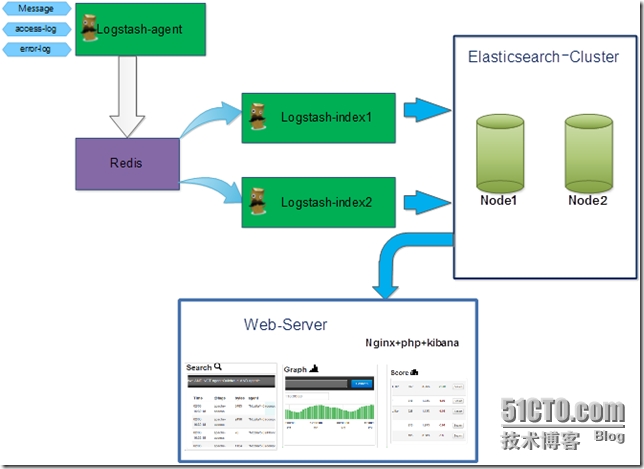
5、体系架构


6、ELK的帮助手册
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide/index.html
ELK中文手册:http://kibana.logstash.es/content/elasticsearch/monitor/logging.html
7、elk的技术架构
gateway:hdfs、Amazon S3、Local FileSystem、Shared FileSystem
Index module、Search module、 Mapping、River(引入异构数据的插件机制:RabbitMQ-River、Twitter-River)
zen和ec2---zk、scripting(mvel、python、js等)
第三方插件(Head、)
Transport(Thrift、Memcached、Http)
Java(Netty)
restful 和 curl
8、elk的基本概念
node 和 cluster
index(数据库)->type(表)->document(行)->field (字段)
shards 分片
replicas 复制
9、其他全文搜索
Solr:文本支持强,html、pdf、word、excel、cvs
Elasticsearch:实时数据分析,支持json格式
splunk
注释
ELK有两种安装方式
(1)集成环境:Logstash有一个集成包,里面包括了其全套的三个组件;也就是安装一个集成包。
(2)独立环境:三个组件分别单独安装、运行、各司其职。(比较常用)
本实验也以第二种方式独立环境来进行演示;单机版主机地址为:192.168.1.104
二、Logstash
1、安装jdk
|
1
2
3
4
5
6
|
Logstash的运行依赖于Java运行环境。# yum -y install java-1.8.0# java -versionopenjdk version "1.8.0_51"OpenJDK Runtime Environment (build 1.8.0_51-b16)OpenJDK 64-Bit Server VM (build 25.51-b03, mixed mode) |
2、安装logstash
|
1
2
3
4
5
6
|
# wget https://download.elastic.co/logstash/logstash/logstash-1.5.4.tar.gz# tar zxf logstash-1.5.4.tar.gz -C /usr/local/配置logstash的环境变量# echo "export PATH=\$PATH:/usr/local/logstash-1.5.4/bin" > /etc/profile.d/logstash.sh# . /etc/profile |
3、logstash常用参数
|
1
2
|
-e :指定logstash的配置信息,可以用于快速测试;-f :指定logstash的配置文件;可以用于生产环境; |
4、启动logstash
4.1 通过-e参数指定logstash的配置信息,用于快速测试,直接输出到屏幕。
|
1
2
3
4
5
|
# logstash -e "input {stdin{}} output {stdout{}}" my name is zhengyansheng. //手动输入后回车,等待10秒后会有返回结果Logstash startup completed2015-10-08T13:55:50.660Z 0.0.0.0 my name is zhengyansheng.这种输出是直接原封不动的返回... |
4.2 通过-e参数指定logstash的配置信息,用于快速测试,以json格式输出到屏幕。
|
1
2
3
4
5
6
7
8
9
10
|
# logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'my name is zhengyansheng. //手动输入后回车,等待10秒后会有返回结果Logstash startup completed{ "message" => "my name is zhengyansheng.", "@version" => "1", "@timestamp" => "2015-10-08T13:57:31.851Z", "host" => "0.0.0.0"}这种输出是以json格式的返回... |
5、logstash以配置文件方式启动
5.1 输出信息到屏幕
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# vim logstash-simple.conf input { stdin {} }output { stdout { codec=> rubydebug }}# logstash -f logstash-simple.conf //普通方式启动Logstash startup completed# logstash agent -f logstash-simple.conf --verbose //开启debug模式Pipeline started {:level=>:info}Logstash startup completedhello world. //手动输入hello world.{ "message" => "hello world.", "@version" => "1", "@timestamp" => "2015-10-08T14:01:43.724Z", "host" => "0.0.0.0"}效果同命令行配置参数一样... |
5.2 logstash输出信息存储到redis数据库中
刚才我们是将信息直接显示在屏幕上了,现在我们将logstash的输出信息保存到redis数据库中,如下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
前提是本地(192.168.1.104)有redis数据库,那么下一步我们就是安装redis数据库.# cat logstash_to_redis.confinput { stdin { } }output { stdout { codec => rubydebug } redis { host => '192.168.1.104' data_type => 'list' key => 'logstash:redis' }}如果提示Failed to send event to Redis,表示连接Redis失败或者没有安装,请检查... |
6、 查看logstash的监听端口号
|
1
2
3
|
# logstash agent -f logstash_to_redis.conf --verbose# netstat -tnlp |grep javatcp 0 0 :::9301 :::* LISTEN 1326/java |
三、Redis
1、安装Redis
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
wget http://download.redis.io/releases/redis-2.8.19.tar.gzyum install tcl -ytar zxf redis-2.8.19.tar.gzcd redis-2.8.19make MALLOC=libcmake test //这一步时间会稍久点...make installcd utils/./install_server.sh //脚本执行后,所有选项都以默认参数为准即可Welcome to the redis service installerThis script will help you easily set up a running redis serverPlease select the redis port for this instance: [6379] Selecting default: 6379Please select the redis config file name [/etc/redis/6379.conf] Selected default - /etc/redis/6379.confPlease select the redis log file name [/var/log/redis_6379.log] Selected default - /var/log/redis_6379.logPlease select the data directory for this instance [/var/lib/redis/6379] Selected default - /var/lib/redis/6379Please select the redis executable path [/usr/local/bin/redis-server] Selected config:Port : 6379Config file : /etc/redis/6379.confLog file : /var/log/redis_6379.logData dir : /var/lib/redis/6379Executable : /usr/local/bin/redis-serverCli Executable : /usr/local/bin/redis-cliIs this ok? Then press ENTER to go on or Ctrl-C to abort.Copied /tmp/6379.conf => /etc/init.d/redis_6379Installing service...Successfully added to chkconfig!Successfully added to runlevels 345!Starting Redis server...Installation successful! |
2、查看redis的监控端口
|
1
2
3
4
|
# netstat -tnlp |grep redistcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 3843/redis-server * tcp 0 0 127.0.0.1:21365 0.0.0.0:* LISTEN 2290/src/redis-serv tcp 0 0 :::6379 :::* LISTEN 3843/redis-server * |
3、测试redis是否正常工作
|
1
2
3
4
5
6
7
8
9
|
# cd redis-2.8.19/src/# ./redis-cli -h 192.168.1.104 -p 6379 //连接redis192.168.1.104:6379> pingPONG192.168.1.104:6379> set name zhengyanshengOK192.168.1.104:6379> get name"zhengyansheng"192.168.1.104:6379> quit |
4、redis服务启动命令
|
1
2
|
# ps -ef |grep redisroot 3963 1 0 08:42 ? 00:00:00 /usr/local/bin/redis-server *:6379 |
5、redis的动态监控
|
1
2
|
# cd redis-2.8.19/src/# ./redis-cli monitor //reids动态监控 |
6、logstash结合redis工作
6.1 首先确认redis服务是启动的
|
1
2
3
4
|
# netstat -tnlp |grep redistcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 3843/redis-server * tcp 0 0 127.0.0.1:21365 0.0.0.0:* LISTEN 2290/src/redis-serv tcp 0 0 :::6379 :::* LISTEN 3843/redis-server * |
6.2 启动redis动态监控
|
1
2
3
|
# cd redis-2.8.19/src/# ./redis-cli monitorOK |
6.3 基于入口redis启动logstash
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# cat logstash_to_redis.confinput { stdin { } }output { stdout { codec => rubydebug } redis { host => '192.168.1.104' data_type => 'list' key => 'logstash:redis' }}# logstash agent -f logstash_to_redis.conf --verbosePipeline started {:level=>:info}Logstash startup completeddajihao linux{ "message" => "dajihao linux", "@version" => "1", "@timestamp" => "2015-10-08T14:42:07.550Z", "host" => "0.0.0.0"} |
6.4 查看redis的监控接口上的输出
|
1
2
3
4
5
|
# ./redis-cli monitorOK1444315328.103928 [0 192.168.1.104:56211] "rpush" "logstash:redis" "{\"message\":\"dajihao linux\",\"@version\":\"1\",\"@timestamp\":\"2015-10-08T14:42:07.550Z\",\"host\":\"0.0.0.0\"}"如果redis的监控上也有以上信息输出,表明logstash和redis的结合是正常的。 |
四、Elasticsearch
1、安装Elasticsearch
|
1
2
|
# wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.7.2.tar.gz# tar zxf elasticsearch-1.7.2.tar.gz -C /usr/local/ |
2、修改elasticsearch配置文件elasticsearch.yml并且做以下修改.
|
1
2
3
4
5
|
# vim /usr/local/elasticsearch-1.7.2/config/elasticsearch.ymldiscovery.zen.ping.multicast.enabled: false #关闭广播,如果局域网有机器开9300 端口,服务会启动不了network.host: 192.168.1.104 #指定主机地址,其实是可选的,但是最好指定因为后面跟kibana集成的时候会报http连接出错(直观体现好像是监听了:::9200 而不是0.0.0.0:9200)http.cors.allow-origin: "/.*/"http.cors.enabled: true #这2项都是解决跟kibana集成的问题,错误体现是 你的 elasticsearch 版本过低,其实不是 |
3、启动elasticsearch服务
|
1
2
3
|
# /usr/local/elasticsearch-1.7.2/bin/elasticsearch #日志会输出到stdout# /usr/local/elasticsearch-1.7.2/bin/elasticsearch -d #表示以daemon的方式启动# nohup /usr/local/elasticsearch-1.7.2/bin/elasticsearch > /var/log/logstash.log 2>&1 & |
4、查看elasticsearch的监听端口
|
1
2
3
|
# netstat -tnlp |grep javatcp 0 0 :::9200 :::* LISTEN 7407/java tcp 0 0 :::9300 :::* LISTEN 7407/java |
5、elasticsearch和logstash结合
|
1
2
3
4
5
6
7
|
将logstash的信息输出到elasticsearch中# cat logstash-elasticsearch.conf input { stdin {} }output { elasticsearch { host => "192.168.1.104" } stdout { codec=> rubydebug }} |
6、基于配置文件启动logstash
|
1
2
3
4
5
6
7
8
9
10
|
# /usr/local/logstash-1.5.4/bin/logstash agent -f logstash-elasticsearch.confPipeline started {:level=>:info}Logstash startup completedpython linux java c++ //手动输入{ "message" => "python linux java c++", "@version" => "1", "@timestamp" => "2015-10-08T14:51:56.899Z", "host" => "0.0.0.0"} |
7、curl命令发送请求来查看elasticsearch是否接收到了数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# curl http://localhost:9200/_search?pretty{ "took" : 28, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 }, "hits" : { "total" : 1, "max_score" : 1.0, "hits" : [ { "_index" : "logstash-2015.10.08", "_type" : "logs", "_id" : "AVBH7-6MOwimSJSPcXjb", "_score" : 1.0, "_source":{"message":"python linux java c++","@version":"1","@timestamp":"2015-10-08T14:51:56.899Z","host":"0.0.0.0"} } ] }} |
8、安装elasticsearch插件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#Elasticsearch-kopf插件可以查询Elasticsearch中的数据,安装elasticsearch-kopf,只要在你安装Elasticsearch的目录中执行以下命令即可:# cd /usr/local/elasticsearch-1.7.2/bin/# ./plugin install lmenezes/elasticsearch-kopf-> Installing lmenezes/elasticsearch-kopf...Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip...Downloading .............................................................................................Installed lmenezes/elasticsearch-kopf into /usr/local/elasticsearch-1.7.2/plugins/kopf执行插件安装后会提示失败,很有可能是网络等情况...-> Installing lmenezes/elasticsearch-kopf...Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip...Failed to install lmenezes/elasticsearch-kopf, reason: failed to download out of all possible locations..., use --verbose to get detailed information解决办法就是手动下载该软件,不通过插件安装命令...cd /usr/local/elasticsearch-1.7.2/pluginswget https://github.com/lmenezes/elasticsearch-kopf/archive/master.zipunzip master.zipmv elasticsearch-kopf-master kopf以上操作就完全等价于插件的安装命令 |
9、浏览器访问kopf页面访问elasticsearch保存的数据
|
1
2
3
4
|
# netstat -tnlp |grep javatcp 0 0 :::9200 :::* LISTEN 7969/java tcp 0 0 :::9300 :::* LISTEN 7969/java tcp 0 0 :::9301 :::* LISTEN 8015/java |
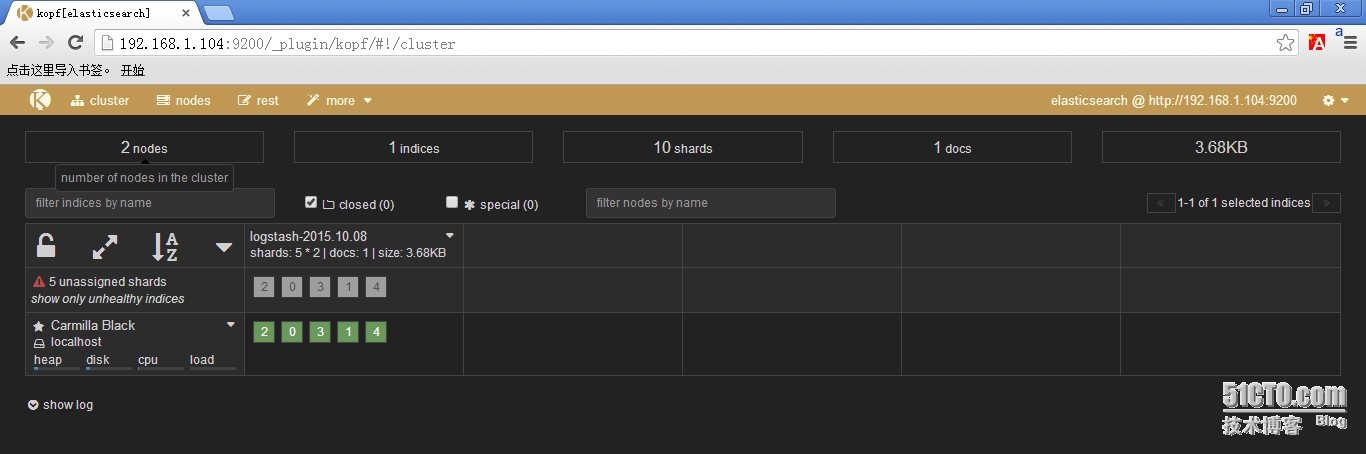
10、从redis数据库中读取然后输出到elasticsearch中
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# cat logstash-redis.confinput { redis { host => '192.168.1.104' # 我方便测试没有指定password,最好指定password data_type => 'list' port => "6379" key => 'logstash:redis' #自定义 type => 'redis-input' #自定义 }}output { elasticsearch { host => "192.168.1.104" codec => "json" protocol => "http" #版本1.0+ 必须指定协议http }} |
五、Kinaba
1、安装Kinaba
|
1
2
|
# wget https://download.elastic.co/kibana/kibana/kibana-4.1.2-linux-x64.tar.gz# tar zxf kibana-4.1.2-linux-x64.tar.gz -C /usr/local |
2、修改kinaba配置文件kinaba.yml
|
1
2
|
# vim /usr/local/kibana-4.1.2-linux-x64/config/kibana.ymlelasticsearch_url: "http://192.168.1.104:9200" |
3、启动kinaba
|
1
2
3
4
5
6
|
/usr/local/kibana-4.1.2-linux-x64/bin/kibana输出以下信息,表明kinaba成功.{"name":"Kibana","hostname":"localhost.localdomain","pid":1943,"level":30,"msg":"No existing kibana index found","time":"2015-10-08T00:39:21.617Z","v":0}{"name":"Kibana","hostname":"localhost.localdomain","pid":1943,"level":30,"msg":"Listening on 0.0.0.0:5601","time":"2015-10-08T00:39:21.637Z","v":0}kinaba默认监听在本地的5601端口上 |
4、浏览器访问kinaba
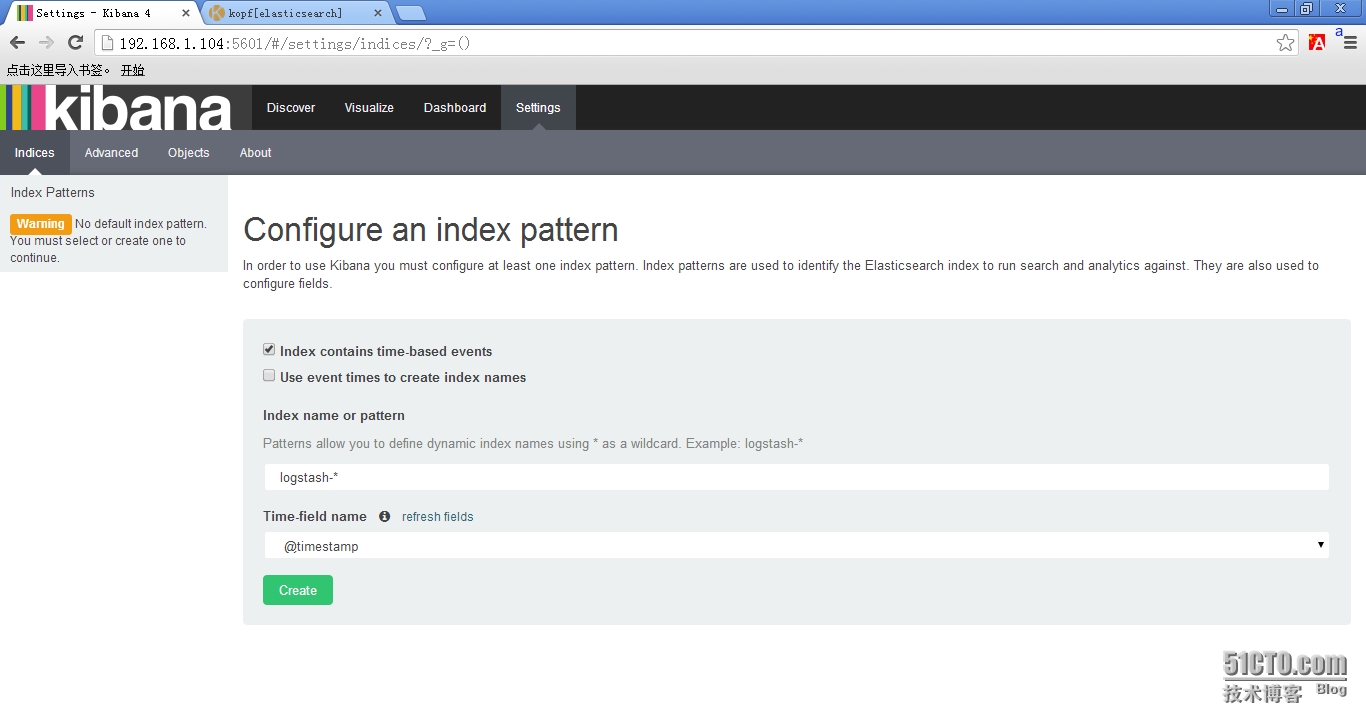
4.1 使用默认的logstash-*的索引名称,并且是基于时间的,点击“Create”即可。
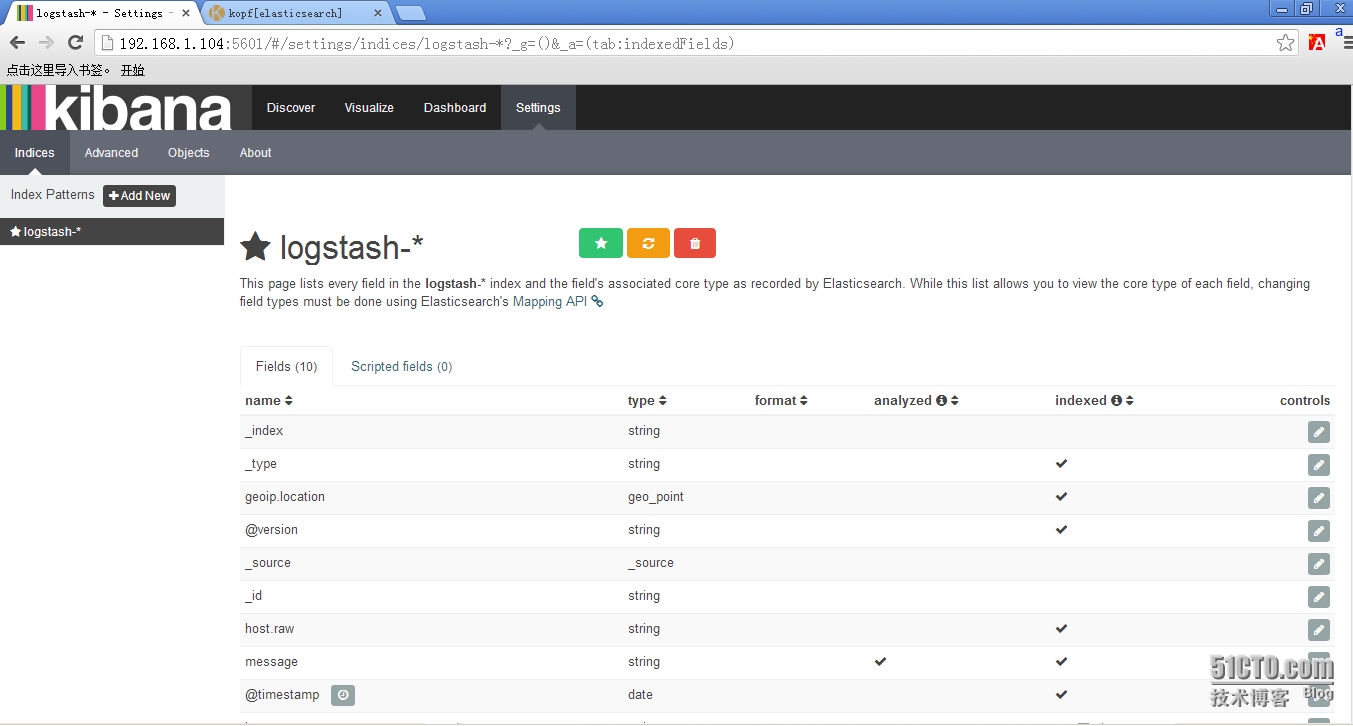
4.2 看到如下界面说明索引创建完成。
4.3 点击“Discover”,可以搜索和浏览Elasticsearch中的数据。
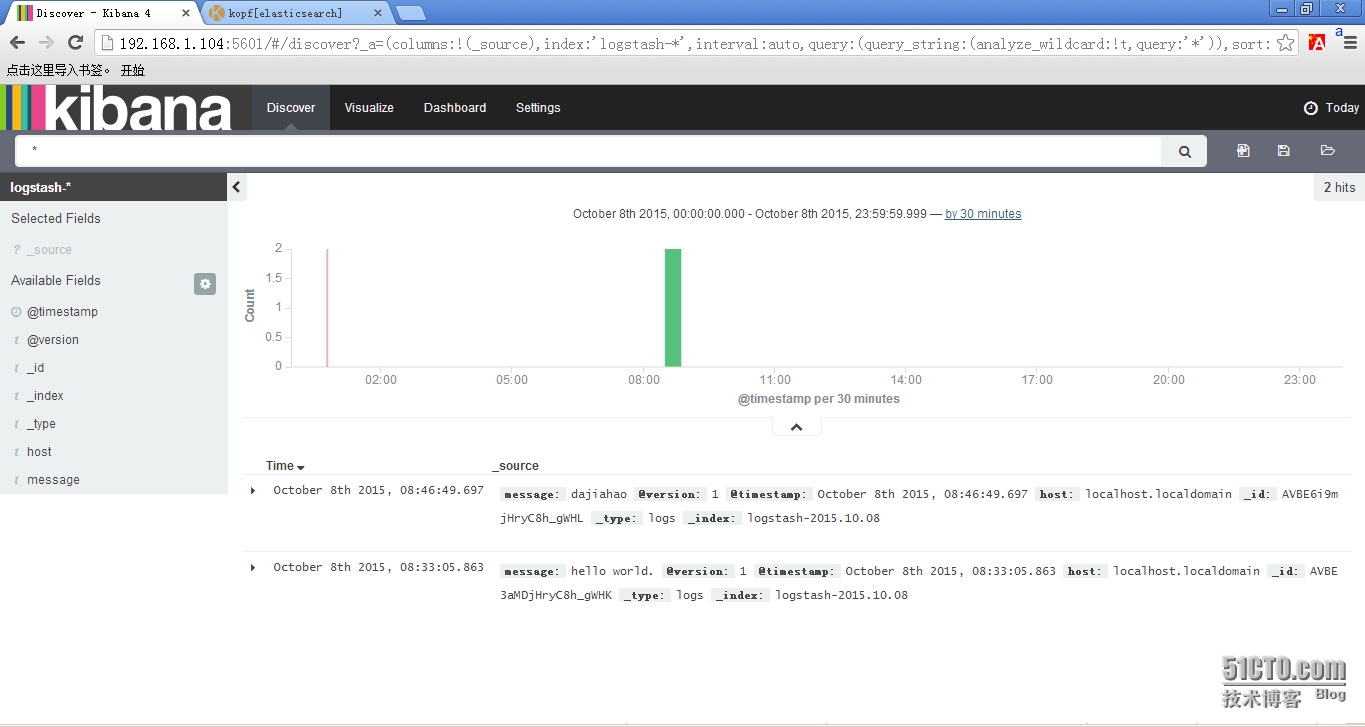
>>>结束<<<
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
1、ELK默认端口号elasticsearch:9200 9300logstash : 9301kinaba : 56012、错误汇总(1)java版本过低[2015-10-07 18:39:18.071] WARN -- Concurrent: [DEPRECATED] Java 7 is deprecated, please use Java 8.(2)Kibana提示Elasticsearch版本过低...This version of Kibana requires Elasticsearch 2.0.0 or higher on all nodes. I found the following incompatible nodes in your cluster: Elasticsearch v1.7.2 @ inet[/192.168.1.104:9200] (127.0.0.1)解决办法: |
软件包以打包上传:http://pan.baidu.com/s/1hqfeFvY
https://www.ibm.com/developerworks/cn/opensource/os-cn-elk/
https://www.jianshu.com/p/797073c1913f
https://www.cnblogs.com/lexiaofei/p/6548528.html
http://blog.51cto.com/467754239/1700828
赛克蓝德日志分析软件(SeciLog)
避免采坑。
1、需要启动四个终端,分别做:
写入日志到redis
logstash agent -f /usr/local/logstash-1.5.4/logstash_to_redis.conf —verbose
日志发送到es
logstash agent -f /usr/local/logstash-1.5.4/logstash-redis.conf —verbose
es启动,可以观察数据
/usr/local/elasticsearch-1.7.2/bin/elasticsearch
启动
/usr/local/kibana-4.1.2-linux-x64/bin/kibana
2、测试的时候,先在第一个终端写入log数据,就可以看到在kibana里看到数据了。
3、我的环境由于系统时间问题,导致kibana查不到数据,坑了好长时间
Elasticsearch的安装入门的更多相关文章
- 最新版本elasticsearch本地搭建入门篇
最新版本elasticsearch本地搭建入门篇 项目介绍 最近工作用到elasticsearch,主要是用于网站搜索,和应用搜索. 工欲善其事,必先利其器. 自己开始关注elasticsearch, ...
- elasticsearch.net search入门使用指南中文版(翻译)
elasticsearch.net search入门使用指南中文版,elasticsearch.Net是一个非常底层且灵活的客户端,它不在意你如何的构建自己的请求和响应.它非常抽象,因此所有的elas ...
- Elasticsearch全文检索工具入门
Elasticsearch全文检索工具入门: 1.下载对应系统版本的文件 elasticsearch-2.4.0.zip 1.1运行elasticsearch-2.4.0\elasticsearch- ...
- elasticsearch.net search入门使用指南中文版
原文:http://edu.dmeiyang.com/book/nestusing.html elasticsearch.net为什么会有两个客户端? Elasticsearch.Net是一个非常底层 ...
- ElasticSearch搜索引擎的入门实战
1.ElasticSearch简介 引用自百度百科: ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elas ...
- ElasticSearch极简入门总结
一,目录 安装es 项目添加maven依赖 es客户端组件注入到spring容器中 es与mysql表结构对比 索引的删除创建 文档的crud es能快速搜索的核心-倒排索引 基于倒排索引的精确搜索. ...
- 如何在Elasticsearch中安装中文分词器(IK+pinyin)
如果直接使用Elasticsearch的朋友在处理中文内容的搜索时,肯定会遇到很尴尬的问题--中文词语被分成了一个一个的汉字,当用Kibana作图的时候,按照term来分组,结果一个汉字被分成了一组. ...
- elasticsearch rpm 安装
参考:http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/setup-repositories.html Dow ...
- Linux初学 - Elasticsearch环境安装
下载 https://www.elastic.co/downloads/elasticsearch 安装 rpm -ivh 也可以双击rpm包安装 修改elastaticsearch host配置 修 ...
随机推荐
- 关于百度Tongji Api的文档补充
百度统计的Tongji Api好像没有人维护了,文档缺胳膊少腿也没人理. 今天在这里指出其中一点,因为这一点花时间也没有傻思考的乐趣的. 引用自百度Tongji API文档 这个文档缺了很多东西,其中 ...
- 生成ID之雪花算法
package com.shopping.test; /** * SnowFlake的结构如下(每部分用-分开):<br> * 0 - 0000000000 0000000000 0000 ...
- db2 with用法
最近在研究db2 递归查询时想到了with,一直以为with只是用来查询递归,但是实际with功能强大,还有更加强大的功能,偶然读到一位大神的文章,对with做了很详细的解读,特贴出来供大家学习研究 ...
- STM32写选项字节(option bytes)的正确姿势
STM32 的 Flash information block 部分,包含有特殊的选项字节,可以用于系统配置等信息, 其中还有两个有效字节(实际四个字节,两个是校验字节)的用户自定义数据字节. 在尝试 ...
- XY//电容
X,Y电容都是安规电容,火线零线间的是X电容,火线与地间的是Y电容.它们用在电源滤波器里,起到电源滤波作用,分别对共模,差模工扰起滤波作用.安规电容是指用于这样的场合,即电容器失效后,不会导致电击,不 ...
- sql server 备份
USE WAP_WORKSHEET; GO BACKUP DATABASE WAP_WORKSHEET TO DISK = 'E:\SQL\Data\backup\WAP_WORKSHEET.Bak' ...
- Lambda表达式语法进一步巩固
上一次已经初步使用到了Lambda表达式了,这次再次对它的语法进行一下巩固,因为它实在是太重要的,所以多花时间彻底理解它是非常有必要的. 在"Java8 in Action"一书中 ...
- 【2019 CCPC 秦皇岛】J - MUV LUV EXTRA
原题: 题意: 给你两个整数a和b,再给你一个正小数,整数部分忽略不计,只考虑小数部分的循环节,对于所有可能的循环节,令其长度为l,在小数部分循环出现的长度为p,最后一个循环节允许不完整,但是缺少的部 ...
- C++获取文件夹下所有文件的路径
代码 getFiles()函数的作用: path是一个文件夹路径,函数在path文件夹下寻找所有文件(包括子文件夹下的文件),然后将所有文件的路径存入files #include <io.h&g ...
- C语言例题
1.连接两个字符串 将两个字符串连接,不要用stract函数 2.求矩阵外围元素之和 求3行3列矩阵的外围元素之和. 3.求矩阵主对角线和副对角线元素之和 求5行5列矩阵的主对角线和副对角线元素之和. ...