sparkStreaming 读kafka的数据
目标:sparkStreaming每2s中读取一次kafka中的数据,进行单词计数。
topic:topic1
broker list:192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092
1、首先往一个topic中实时生产数据。
代码如下: 代码功能:每秒向topic1发送一条消息,一条消息里包含4个单词,单词之间用空格隔开。
- package kafkaProducer
- import java.util.HashMap
- import org.apache.kafka.clients.producer._
- object KafkaProducer {
- def main(args: Array[String]) {
- val topic="topic1"
- val brokers="192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092"
- val messagesPerSec=1 //每秒发送几条信息
- val wordsPerMessage =4 //一条信息包括多少个单词
- // Zookeeper connection properties
- val props = new HashMap[String, Object]()
- props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
- props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
- "org.apache.kafka.common.serialization.StringSerializer")
- props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
- "org.apache.kafka.common.serialization.StringSerializer")
- val producer = new KafkaProducer[String, String](props)
- // Send some messages
- while(true) {
- (1 to messagesPerSec.toInt).foreach { messageNum =>
- val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
- .mkString(" ")
- val message = new ProducerRecord[String, String](topic, null, str)
- producer.send(message)
- println(message)
- }
- Thread.sleep(1000)
- }
- }
- }
打包运行命令:hadoop jar jar包 (注意jar包是可运行的jar包)
消费者消费命令: ./kafka-console-consumer.sh --zookeeper zk01:2181,zk02:2181 --topic topic1 --from-beginning
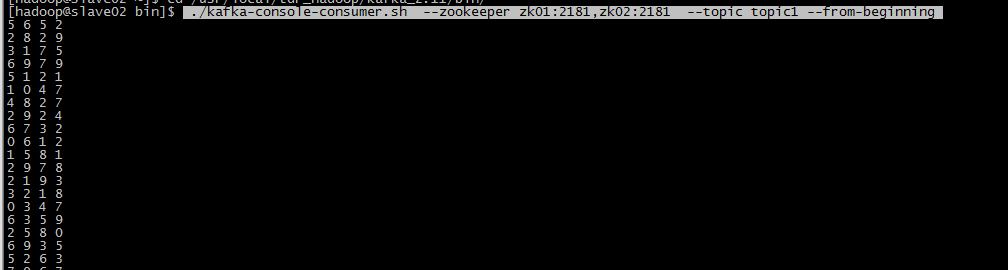
可以正常消费。
2、编写SparkStreaming代码读kafka中的数据,每2s读一次
代码如下:
- package kafkaSparkStream
- import org.apache.spark.SparkConf
- import org.apache.spark.streaming.StreamingContext
- import org.apache.spark.streaming.Seconds
- import org.apache.spark.streaming.kafka.KafkaUtils
- import kafka.serializer.StringDecoder
- /**
- * sparkStreaming读取kafka中topic的数据
- */
- object KafkaToSpark {
- def main(args: Array[String]) {
- if (args.length<2) {
- System.err.println("Usage: <brokers> <topics>");
- System.exit(1)
- }
- val Array(brokers,topics)=args
- //2s从kafka中读取一次
- val conf=new SparkConf().setAppName("KafkaToSpark");
- val scc=new StreamingContext(conf,Seconds(2))
- // Create direct kafka stream with brokers and topics
- val topicSet=topics.split(",").toSet
- val kafkaParams=Map[String,String]("metadata.broker.list"->brokers)
- //获取信息
- val messages=KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
- scc,kafkaParams,topicSet)
- // Get the lines, split them into words, count the words and print
- val lines= messages.map(_._2)
- val words=lines.flatMap(_.split(" "))
- val wordCouts=words.map(x =>(x,1L)).reduceByKey(_+_)
- wordCouts.print
- //开启计算
- scc.start()
- scc.awaitTermination()
- }
- }
打包运行命令:./spark-submit --class kafkaSparkStream.KafkaToSpark --master yarn-client /home/hadoop/sparkJar/kafkaToSpark.jar 192.168.1.126:9092,192.168.1.127:9092,192.168.1.128:9092 topic1
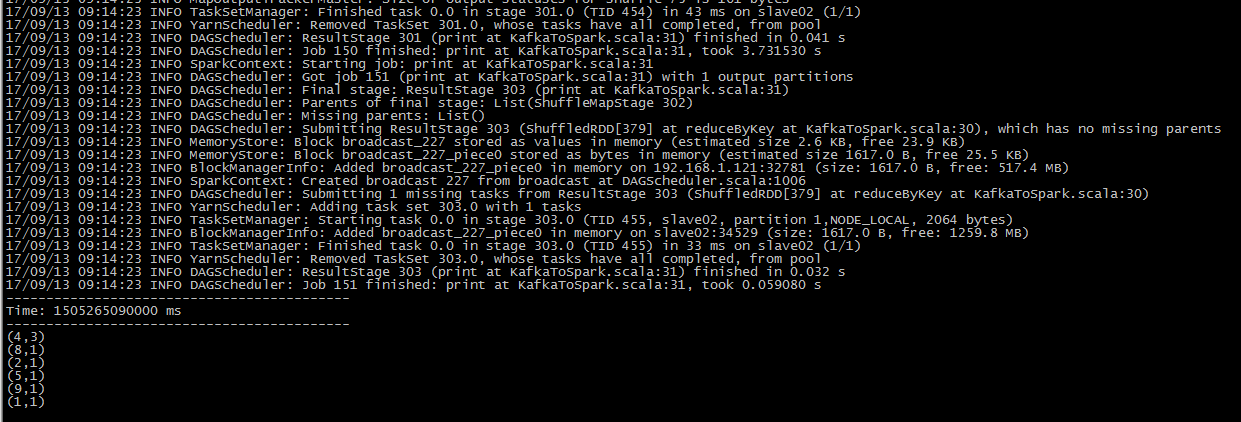
运行成功!
sparkStreaming 读kafka的数据的更多相关文章
- SparkStreaming消费kafka中数据的方式
有两种:Direct直连方式.Receiver方式 1.Receiver方式: 使用kafka高层次的consumer API来实现,receiver从kafka中获取的数据都保存在spark exc ...
- spark-streaming读kafka数据到hive遇到的问题
在项目中使用spark-stream读取kafka数据源的数据,然后转成dataframe,再后通过sql方式来进行处理,然后放到hive表中, 遇到问题如下,hive-metastor在没有做高可用 ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
- 大数据学习day32-----spark12-----1. sparkstreaming(1.1简介,1.2 sparkstreaming入门程序(统计单词个数,updateStageByKey的用法,1.3 SparkStreaming整合Kafka,1.4 SparkStreaming获取KafkaRDD的偏移量,并将偏移量写入kafka中)
1. Spark Streaming 1.1 简介(来源:spark官网介绍) Spark Streaming是Spark Core API的扩展,其是支持可伸缩.高吞吐量.容错的实时数据流处理.Sp ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- 图解SparkStreaming与Kafka的整合,这些细节大家要注意!
前言 老刘是一名即将找工作的研二学生,写博客一方面是复习总结大数据开发的知识点,一方面是希望帮助更多自学的小伙伴.由于老刘是自学大数据开发,肯定会存在一些不足,还希望大家能够批评指正,让我们一起进步! ...
- 读Kafka Consumer源码
最近一直在关注阿里的一个开源项目:OpenMessaging OpenMessaging, which includes the establishment of industry guideline ...
随机推荐
- STL源码剖析——空间配置器Allocator#1 构造与析构
以STL的运用角度而言,空间配置器是最不需要介绍的东西,因为它扮演的是幕后的角色,隐藏在一切容器的背后默默工作.但以STL的实现角度而言,最应该首先介绍的就是空间配置器,因为这是这是容器展开一切运作的 ...
- 数据库基础理解学习-Mysql
1. 简介 数据库,现代化的数据存储存储手段,是一种特殊的文件,其中存储着需要的数据. 特点: 持久化存储 读写速度极高 保证数据的有效性 对程序支持性非常好,容易扩展 2. Mysql (1)具有数 ...
- Linux查询命令帮助信息(知道)
方法一 command --help 方法二 man command 操作涉及到的按键: 空格键:显示手册的下一屏 Enter键:一次滚动手册的一行 b:回滚一屏 f:前滚一屏 q:退出 结果基本上全 ...
- 基于openfire的IM即时通讯软件开发
openfire:http://www.igniterealtime.org/ Xmpp:http://xmpp.org/ IOS(xmppframework):https://github.com/ ...
- Rubost PCA 优化
Rubost PCA 优化 2017-09-03 13:08:08 YongqiangGao 阅读数 2284更多 分类专栏: 背景建模 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA ...
- NetLink通信原理研究、Netlink底层源码分析、以及基于Netlink_Connector套接字监控系统进程行为技术研究
1. Netlink简介 0x1:基本概念 Netlink是一个灵活,高效的”内核-用户态“.”内核-内核“.”用户态-用户态“通信机制.通过将复杂的消息拷贝和消息通知机制封装在统一的socket a ...
- shellexecute的使用和X64判断
bool RunConsoleAsAdmin(std::string appPath, std::string param, bool wait) { LOG_INFO << " ...
- Linux入职基础-1.1_国内开源的主要镜像站
Linux入职基础-1.1_国内开源的主要镜像站 东北地区: 东北大学 http://mirror.neu.edu.cn 大连理工大学 http://mirror.dlut.edu.cn 大连东软 ...
- hadoop入门-centos7.2安装hadoop2.8
1. 安装准备 (1)必须安装jdk: 因为hadoop是基于Java实现的,所有必须安装jdk 是JDK不是jre jdk1.7 jdk1.8 (2)系统位数 (3)创建专用用户 useradd h ...
- PLSQL登录的时候Warning提示:Using a filter for all users can lead to poor performance!
转自: https://blog.csdn.net/athena2015/article/details/81811908