Aure Event Hubs小白完全入门指南
refer to
https://www.cnblogs.com/mysunnytime/p/11634815.html?from=groupmessage&isappinstalled=0
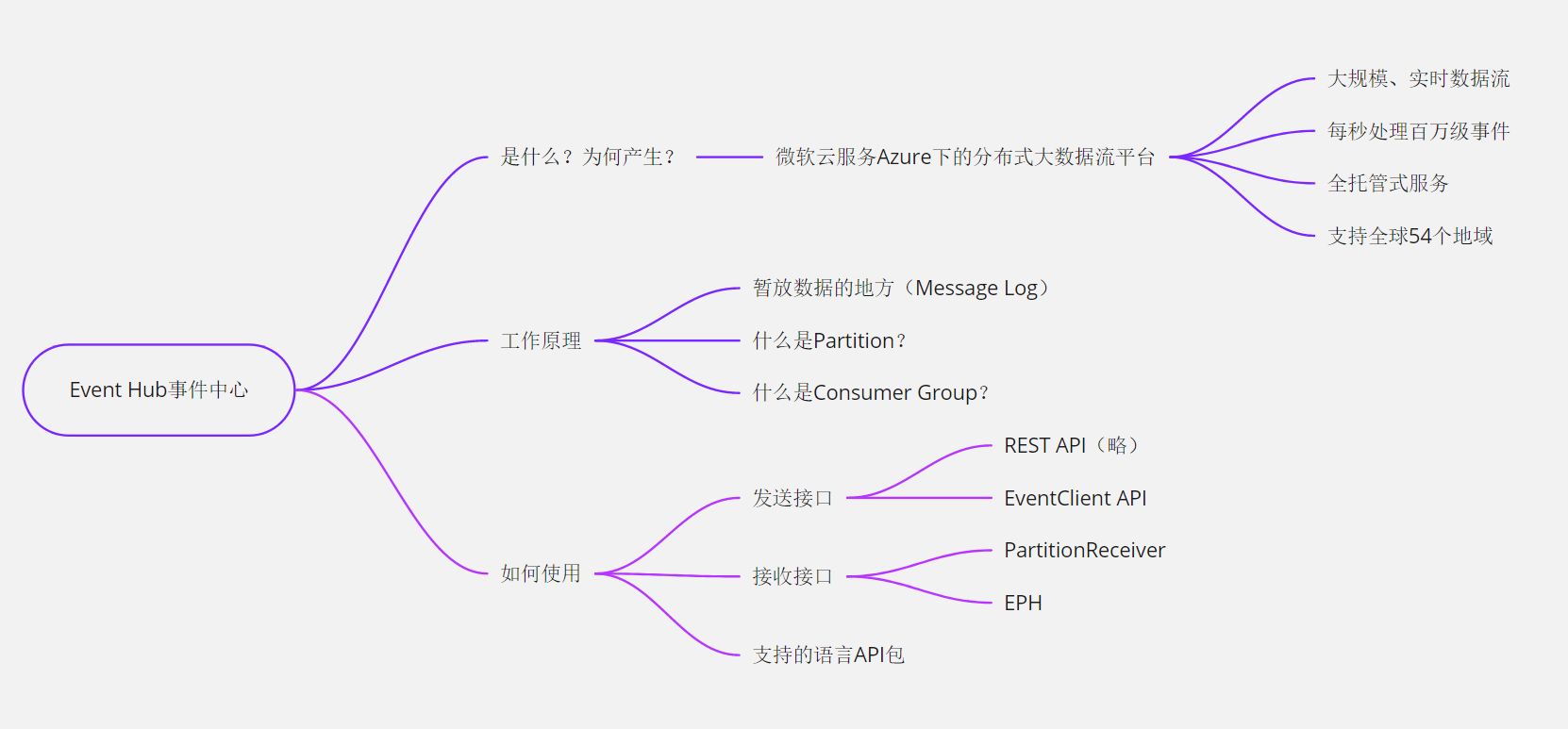
Event Hub事件中心
本文的目的在于用最白的大白话,让你从“完全不懂”开始,理解什么是分布式大数据流平台Event Hub,并且理解它的关键概念,并且初步理解其收发数据API。
定义,Event Hub是什么、产生的目的
Event Hub是微软云服务Azure的一个产品,是分布式大数据流平台。属于PaaS。Event Hub:
- 支持大规模、实时的流数据
- 每秒能处理百万级的事件
- 简单易用,托管式服务
- 支持全球54个Azure地域
这里指的大规模、实时的流数据是指什么?Big Data Streaming 大数据流
很多应用需要从各处搜集数据来进行分析和处理,如网站收集用户的使用数据,或者物联网系统搜集所有连网设备的实时数据。这些数据从多个不同的终端产生,并且随时都在产生。所以这些数据是流数据,即时性的,好像水流一样,源源不断,从一个地方流向下一个地方。
为什么是“大数据”呢?因为这些数据可能从成千上万的客户端发出,并且发出的频率很高,要汇集在一个地方进行处理,形成了很大的数据规模,所以是大数据。
Event Hub可以处理多大的数据?
每秒可以处理百万级别的事件(event)。这里的“事件”:就是你收发的数据。 - https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-about, 2019.8
什么是托管式服务?Managed Service
Event Hub是全托管式的服务。什么意思呢?就是如果不使用Event Hub这样的托管式服务,那么开发者需要自己对大数据流平台进行管理。比如Apache Kafka也是一个大数据流平台,但是它不是全托管的,这意味着开发者将需要自行搭建和管理大数据流的处理,比如搭建(购买和配置)虚拟机集群、安装和管理Kafka、管理储存,也就是说,开发者需要自行进行管理所有涉及的服务、更新、包、版本,或者需要再使用其他平台的服务代为完成这些步骤。而Event Hub为开发者全托管,开发者只需要创建Event Hub,然后就可以进行大数据的收发了,Event Hub保证中间的所有过程,提供稳定的服务。这样开发者对中间过程的控制变弱了,但是可以更加关注自己的业务逻辑。
在大数据流的链条中,client客户端产生数据,server服务器端接收数据和分析数据。Event Hub就像一个client和server中间的缓冲区域(buffer)。
为什么要一个buffer:因为没有buffer的话会造成依赖(dependency)和高耦合(tight coupling)。如果数据量大的话,就会出现问题。而buffer可以在这个数据生产线上起到控流的作用(flow control)。
Event Hub的典型用途是收集在远端产生的遥测(telemetry)数据,包括从1)网络应用的客户端和2)远端设备和门户(如散落各地的共享单车)上获取数据。
工作原理
本质上来讲,Event Hub就是一个暂放数据的地方。
当数据从终端产生,发送数据给一个Event Hub的时候,Event Hub就把数据收集然后写下来,写在其内部的储存里,然后我们就可以阅读这些Event Hub为我们收集的数据,进行可视化、数据分析等等,做我们想做的事情。
Event Hub就好像是一个笔记本,我们从头到尾写,也从头到尾读。
||||||||||||||||||||||||||||||||||||||||||||||||||| --> 写
读-->
笔记本上写下来的数据可以反复阅读,进入Event Hub的数据也可以被多次读取。读取数据的操作并不会将数据从Event Hub上删除。
然而,Event Hub上的数据不是永久保存的。数据到达Event Hub后,会被保存一段时间(这段时间被称作retention day,可以设置为1-7天)。就好比笔记本上,超过某段时间以后,老旧的笔记会被撕掉。
这就是Event Hub的基本工作原理。但是实际上还有一些更细节的概念,开发者们使用时必须要了解。其中最重要的包括Partition和Consumer Group。
什么是Partition?
到达Event Hub的数据其实不是写在同一个地方的,而是写在几个Partition上的。就好比其实Event Hub里面不只有一个笔记本,而是有多个笔记本来记录消息。
Partition好像是Event Hub储存空间的扇区一般。数据在到达Event Hub时,会被挨个分配到某个Partition上,分配默认是轮流的方式(Round Robin)。也就是说,第一条消息到来的时候,会被写到第一个笔记本上,而第二条消息到来的时候,会被写到第二个笔记本上,以此类推。
笔记本 A:1 4
笔记本 B:2 5
笔记本 C:3 <- 6
这种分成多区的形式,目的是为了提供并行接收(读取)的能力。
还是拿笔记本来打比方。比如,一开始的时候,你有一个Event Hub,里面有2个笔记本来记录数据,然后你请了一个人(读取数据的应用)来从这两个笔记本上读取数据(应用可以开两个线程来同时读取数据)。由于刚开始消息并不多,所以一个人的脑子还是够用的。
但是后面,你的业务越做越大,进入的数据流也越来越大,你请的人脑子不够用了(CPU不够,读取速度不够)。这时候,你就需要再请一个人(再开一个读取应用实例),那么这两个人可以每个人管一个笔记本,读取上面的数据。
然而你的业务越做越大,两个人也读不过来了,怎么办呢?这时候你可能要考虑再多加一个笔记本,这样就可以再多请一个人了。不过因为目前partition数量不能在Event Hub创建之后修改,所以只能重新创建一个有更多Partition数量的Event Hub才能满足要求。
当然,Partition并不是越多越好,因为每个Partition都要求有一个单独的Receiver来读取,而这意味着更多CPU资源和Socket连接的代价,所以要谨慎考虑增加Partition的数量,不要随意耗费资源。
最多可以有多少个Partition?
一个Event Hub允许1-32个Partition,在创建Event Hub时设置。目前的话,Event Hub一旦创建就不能修改(只能创建一个新的Event Hub),所以要创建的时候合理预估并行读取的数量。
什么是Consumer Group?
那Consumer Group是什么呢?在Event Hub的概念中,Consumer Group相当于一个读取时的视图(View),我们可以保存一个Consumer Group下,读取流的状态(读取的应用读到了什么位置,或者说偏移量)。这样的话,如果一个应用的读取连接因为某些原因而断开,要重新建立读取连接的话,我们就方便知道要从什么位置继续读取。
我们可以在一个Event Hub中创建多个Consumer Group(最多20个),这样不同的读取应用就可以使用不同的Consumer Group来进行读取。比如,一个Event Hub收集了所有的共享单车的状态数据,而在分析数据的时候,我们有一个应用是用来监测当前单车分布的位置是否需要派人调整,另一个应用则是需要进行用户的使用习惯、行动路线来的分析。两个应用目的不同,读取的频率也并不相同。这样种情况下,就可以使用两个Consumer Group,分别对应每个应用,这样两边的读取可以互不干扰。
如何使用
(*本文是一个介绍,并非教程。所以此处假设已经在Azure里创建了“事件中心命名空间 Event Hub Namespace”和“事件中心 Event Hub”,并且获取了Event Hub的Connection String。)
那么如何使用Event Hub API进行事件的收发呢?
发送接口 Sender API
有两种方式都可以实现将数据发送到Event Hub上的操作。一种是用基于HTTPS协议的REST API来进行发送,也就是在header里设置授权信息,把要发送的数据POST到相应的URL。*
(* 详细操作在这里可以看到:https://docs.microsoft.com/en-us/rest/api/eventhub/event-hubs-runtime-rest。)
但是更推荐的是第二种发送方式,使用EventClient API。它背后是AMQP协议,更为高效。不过这里我们并不需要理解AMQP的实现方式,只需要使用微软提供的接口。
下面以C#为例,简单介绍发送接口:
API接口在Microsoft.Azure.EventHubs的NuGet包里。
1. 创建 EventData,把要发送的消息放在EventData对象中。
var eventData = new EventData(byteArray);
2. 创建 EventHubClient,这时要提供带有授权信息(Connection String)好连接到指定的Event Hub。
EventHubClient eventHubClient = EventHubClient.CreateFromConnectionString(connectionString);
3. 调用EventHubClient的发送API来发送数据
eventHubClient.SendAsync(eventData);
接收接口 Receiver API
从Event Hub里面获取出数据的接口基于AMQP协议(并没有基于HTTPS协议的API)。
其中,仍然有两种方式可以实现数据的获取:1)使用EventHubClient的PartitionReceiver;2)使用EventProcessorHost (EPH)API。下面分别介绍:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-dotnet-standard-api-overview
1)使用PartitionReceiver
这是Event Hub提供的一个读取API,可以从一个指定的Partition上读取数据。
API接口在Microsoft.Azure.EventHubs的NuGet包里。
1. 和发送数据一样,创建EventHubClient连接到Event Hub。这个EventHubClient在发送的时候也有使用到。
EventHubClient eventHubClient = EventHubClient.CreateFromConnectionString(connectionString);
2. 用EventHubClient的CreateReceiver() API来创建PartitionReceiver:
PartitionReceiver partitionReceiver = eventHubClient.CreateReceiver("$Default", "0", DateTime.Now); //从默认ConsumerGroup上,获取“0”号Partition上,从当前时刻以后的所有数据。
在这里,我们想要
3. 调用PartitionReceiver的接收API来接收消息
var eventDatas = await partitionReceiver.ReceiveAsync(10); // 执行接收,设定最多接收10条数据
4. 解析数据
foreach (var ehEvent in ehEvents)
{
var message = UnicodeEncoding.UTF8.GetString(ehEvent.Body.Array);
// 放入数据分析逻辑的代码
}
值得说明的是,一个PartitionReceiver只能从一个partition上读取信息。所以通常的做法是,对于一个Event Hub的每一个partition,都创建一个PartitionReceiver来进行读取,一一对应。
我们可以用EventHubClient的GetRuntimeInfoAsync() API来得到runtime信息,这里面我们可以知道所有的partition,从而一一创建PartitionReceiver:
var runTimeInformation = await eventHubClient.GetRuntimeInformationAsync();
foreach (var partitionId in runTimeInformation.PartitionIds) {
var receiver = eventHubClient.CreateReceiver(PartitionReceiver.DefaultConsumerGroupName, partitionId, Date.Time.Now);
}
2)EventProcessorHost
PartitionReceiver直接从一个指定的partition上读取数据,简单好用。然而,我们往往需要读取多个partition上的数据,并且在大数据的场景下对可扩展性有着相当的需求,这样我们既需要管“给每个partition创建PartitionReceiver”这个事情,还需要管“开了多个应用实例以后partition读取工作的分配”的事情,还要考虑“如果一个应用实例挂了,要怎么从之前的进度开始接着读取”,这样写起来十分复杂。
有没有更自动省力的方法呢?
当然有哒!如果不想要手写一个一个partition的读取、offset的记录、规模的缩放,我们可以使用EventProcessorHost(EPH)来进行处理。
本质上讲,EPH提供两个功能:1. EPH会自动把一个Event Hub中的每一个partition都创建一个EventProcessor(相当于一个receiver),并且把这些Processor平均分配给现有的应用实例去处理,并且实时监控这些应用实例;2. EPH会把读取的进度自动保存下来。这样,不管你有多少个实例在健康运行,或者某个实例挂掉了,都可以保证你的读取正常进行,提供高可用性(availability)。
简单点说,现在你有若干个个笔记本上的数据要读,如果使用PartitionReceiver的方法,就是你请了若干个人来读这些笔记本(创建若干App实例),你自己安排哪个人读哪个笔记本,那么如何分配你就得自己操心。如果使用EPH,那么相当于请了一个经理来管理,经理会根据你请了几个人(开几个App实例),自动分配每个人干的活。如果某个人请假了(某个App挂了),经理也会自动安排他的工作给其他人。同时,经理会记录每个笔记本读到了哪里,以便如果读取工作被中断(如读取连接断开),后面还可以继续从上次的地方接着读。
API接口在Microsoft.Azure.EventHubs.Processor的NuGet包里。**
首先,要实现一个IEventProcessor接口:
CloseAsync(), OpenAsync(), ProcessErrorAsync(), ProcessEventsAsync()
public class YourEventProcessor : IEventProcessor{
public Task CloseAsync(PartitionContext context, CloseReason reason){
// your implementation when close
}
public Task OpenAsync(PartitionContext context){
// your implementation when open
}
public Task ProcessErrorAsync(PartitionContext context, Exception error){
// your implementation to process error
}
public Task ProcessEventAsync(PartitionContext context, IEnumerable<EventData> eventDatas){
// your implementation to process event data
if(eventDatas != null){
foreach(var eventData in eventDatas){
// process data here
}
}
return context.CheckpointAsync(); // save offset
}
}
上面的代码中,实际的数据分析逻辑就写在ProcessEventsAsync()里,最后 “return context.CheckpointAsync();” 进行读取进度的保存。
然后,在主程序中创建EventProcessorHost:
var yourEventProcessorHost = new EventProcessorHost(
eventHubPath,
consumerGroupName,
eventHubConnectionString,
storageConnectionString,
containerName);
其中,eventHubPath、consumerGroupName、eventHubConnectionString是你创建好的EventHub的验证信息,storageConnectionString和containerName是Azure Storage Account的验证信息,这是用来保存读取进度的,它也需要提前创建好(这里不介绍如何创建)*。
下一步,要把这个EPH和刚刚创建的EventProcessor连接起来:
await yourEventProcessorHost.RegisterEventProcessorAsync<YourEventProcessor>();
最后,主程序退出时,取关EventProcessor。
await yourEventProcessorHost.UnregisterEventProcessorAsync();
这样,即使你有多个应用实例,EPH可以帮你管理,并且以你想要的方式处理。
*也可以选择使用别的storage,需要使用ICheckpointManager,这里不详细介绍。
** EPH接口正在进行重新优化设计,在本文发文后,接口可能会有较大变动,读者请以实时的官方文档为主。
Event Hub支持的语言以及API包:
入门指导文档 https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-programming-guide
- Java https://github.com/Azure/azure-event-hubs-java
- Go https://godoc.org/github.com/Azure/azure-event-hubs-go
- Python https://github.com/Azure/azure-sdk-for-python/tree/master/sdk/eventhub/azure-eventhubs
- JavaScript (Node.js & Browser) https://github.com/Azure/azure-sdk-for-js/tree/master/sdk/eventhub/event-hubs
总结
EventHub的本质是messaging queue的变种——messaging log,是大数据时代下的产物,作为大数据分析流的门户,专门为大数据分析提供了一个缓冲、负载平衡,为大数据的收发提供可靠、易于操作的平台服务。希望这篇文章所介绍的Event Hub的定义、工作原理、使用方式能带给大家启发。也希望有说的不够清楚、不够严谨的地方,请大家多多指正 :)
Aure Event Hubs小白完全入门指南的更多相关文章
- Linux运维完全小白入门指南
前几天整理了一下自己入门时候搜集的资料,一边整理一边回忆. 那时候我还是个小白,用虚拟机装了个CentOS系统来玩,但是总也装不上,在论坛上求助也没人理.半天终于有个人说在某网站看过这个问题,我又找了 ...
- Microsoft Orleans 之 入门指南
Microsoft Orleans 在.net用简单方法构建高并发.分布式的大型应用程序框架. 原文:http://dotnet.github.io/orleans/ 在线文档:http://dotn ...
- 李洪强iOS开发之-入门指南
李洪强iOS开发之-入门指南 1零基础小白如何进行iOS系统学习 首先,学习目标要明确:其次,有了目标,要培养兴趣,经常给自己一些正面的反馈,比如对自己的进步进行鼓励,在前期小步快走:再次,学技术最重 ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
- CTF入门指南
转自http://www.cnblogs.com/christychang/p/6032532.html ctf入门指南 如何入门?如何组队? capture the flag 夺旗比赛 类型: We ...
- Ext JS 6学习文档–第1章–ExtJS入门指南
Ext JS 入门指南 前言 本来我是打算自己写一个系列的 ExtJS 6 学习笔记的,因为 ExtJS 6 目前的中文学习资料还很少.google 搜索资料时找到了一本国外牛人写的关于 ExtJS ...
- CTF入门指南(0基础)
ctf入门指南 如何入门?如何组队? capture the flag 夺旗比赛 类型: Web 密码学 pwn 程序的逻辑分析,漏洞利用windows.linux.小型机等 misc 杂项,隐写,数 ...
- mxGraph进阶(一)mxGraph教程-开发入门指南
mxGraph教程-开发入门指南 概述 mxGraph是一个JS绘图组件适用于需要在网页中设计/编辑Workflow/BPM流程图.图表.网络图和普通图形的Web应用程序.mxgraph下载包中包括用 ...
- dogse入门指南
dogse入门指南 Dogse作为游戏服务端引擎,目前只包含游戏服务端的核心部分,但这也是最核心的部分.它全部使用.net c#开发,充分兼顾了程序性能与代码编写的准确性与易用性,再加上以vs作为开发 ...
随机推荐
- jvm(5)---垃圾回收(回收算法和垃圾收集器)
1.垃圾回收算法 1.1 标记-清除算法 算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象.它是最基础的收集算法,效率也很高,但是会带来两个明显的问题 ...
- 解决nginx端口占用问题
1.键入命令:netstat -ano | findstr 80 查看80端口被哪个程序占用: 2.键入命令:netsh http show servicestate 查看http服务状态(注:解决后 ...
- Eclipse 常用配置和基本调试
常用配置 1.显示行号:window->Preferences->General->Editors->Text Editors , 勾选show line numbers 2. ...
- htm5手机端实现拖动图片
htm5手机端实现拖动图片 <pre> <!doctype html><html><head> <title>Mobile Cookbook ...
- STAR软件的学习
下载地址与参考文档 https://github.com/alexdobin/STAR/archive/2.5.3a.tar.gz wget https://github.com/alexdobin/ ...
- Windows 下配置 ApacheBench (AB) 压力测试
下载 http://httpd.apache.org/download.cgi 我用的是ApacheHaus. 安装服务 1. 打开apache目录下的 conf/httpd.conf,搜索并修改 L ...
- 用php做管理后台
最近因处理家庭之事,技术上没有提高,这段时间也陆续的恢复了正常的开发,由于要做一个管理后台,所以在选择语言和架构上搜了不少资料, php 和java 的选择上,后来选择用php作为管理后台开发的语言. ...
- React项目使用Redux
⒈创建React项目 初始化一个React项目(TypeScript环境) ⒉React集成React-Router React项目使用React-Router ⒊React集成Redux Redux ...
- 2019年6月12日——开始记录并分享学习心得——Python3.7中对列表进行排序
Python中对列表的排序按照是排序是否可以恢复分为:永久性排序和临时排序. Python中对列表的排序可以按照使用函数的不同可以分为:sort( ), sorted( ), reverse( ). ...
- python学习-60 面向对象设计
面向对象设计 1.三大编程范式 --面向过程编程 --函数式编程 --面向对象编程 2.编程进化论 --编程最开始就是无组织无结构,从简单控制流中按步写指令 --从上述的指令中提取重复的代码快或逻辑, ...