NLP学习(3)---Bert模型
一、BERT模型:
1、WordEmbedding到BERT的发展过程:
预训练:先通过大量预料学习单词的embedding,在下游的NLP学习任务中就可以使用了。
下游任务:Frozen(预训练的底层参数embedding不变)和Fine-tuning(预训练embedding参数调整更适应当前任务)。
(1)语言模型:
场景:假设现在让你设计一个神经网络结构,去做这个语言模型的任务,就是说给你很多语料做这个事情,训练好一个神经网络,训练好之后,以后输入一句话的前面几个单词,要求这个网络输出后面紧跟的单词应该是哪个,你会怎么做?
模型: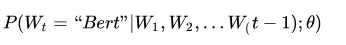
与word Embedding关系:NNLM的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而word embedding只是无心插柳的一个副产品。
(2)word2vec:
与Word Embedding关系:Word2Vec目标单纯就是要word embedding的,这是主产品。一个单词表达成Word Embedding后,很容易找出语义相近的其它词汇。
存在的问题:多义词的不同语义问题。比如多义词Bank【银行、河岸】,有两个常用含义,但是Word Embedding在对bank这个单词进行编码的时候,是区分不开这两个含义的,因为它们尽管上下文环境中出现的单词不同,但是在用语言模型训练的时候,不论什么上下文的句子经过word2vec,都是预测相同的单词bank,而同一个单词占的是同一行的参数空间,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。所以word embedding无法区分多义词的不同语义,这就是它的一个比较严重的问题。
(3)ELMO:【Embedding from Language Models】
word2vec存在的问题:在此之前的Word Embedding本质上是个静态的方式,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的Word Embedding不会跟着上下文场景的变化而改变,所以对于比如Bank这个词,它事先学好的Word Embedding中混合了几种语义 ,在应用中来了个新句子,即使从上下文中(比如句子包含money等词)明显可以看出它代表的是“银行”的含义,但是对应的Word Embedding内容也不会变,它还是混合了多种语义。这是为何说它是静态的,这也是问题所在。
ELMO本质思想:我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路
ELMO优势:
(1)能够处理单词用法中的复杂特性(比如句法和语义)
(2)这些用法在不同的语言上下文中如何变化(比如为词的多义性建模)
ELMO缺点:【与GPT和BERT对比】
(1)LSTM抽取特征能力弱于Transformer
(2)拼接方式双向融合特征融合能力偏弱
为什么ELMo的效果会比word2vec的效果好?
- ELMo的假设前提一个词的词向量不应该是固定的,所以在一词多意方面ELMo的效果一定比word2vec要好。
- word2vec的学习词向量的过程是通过中心词的上下窗口去学习,学习的范围太小了,而ELMo在学习语言模型的时候是从整个语料库去学习的,而后再通过语言模型生成的词向量就相当于基于整个语料库学习的词向量,更加准确代表一个词的意思。
- ELMo还有一个优势,就是它建立语言模型的时候,可以运用非任务的超大语料库去学习,一旦学习好了,可以平行的运用到相似问题。
ELMO两阶段过程:https://www.cnblogs.com/huangyc/p/9860430.html
①利用NNLM模型进行预训练
②做下游任务时,从预训练网络中提取对应单词的网络各层的WordEEmbedding作为新特征补充到下游任务中。
①预训练:
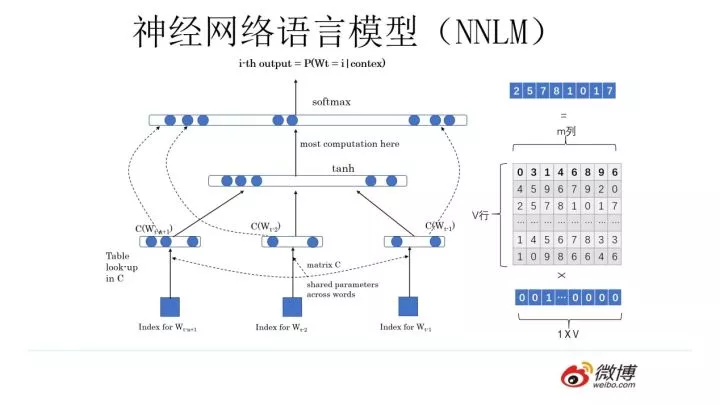
上图展示的是其预训练过程,它的网络结构采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 Wi 的上下文去正确预测单词 Wi ,Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 Wi 的上文Context-before和下文Context-after;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子上文和下文;每个编码器的深度都是两层LSTM叠加,而每一层的正向和逆向单词编码会拼接到一起。这个网络结构其实在NLP中是很常用的。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 Snew ,句子中每个单词都能得到对应的三个Embedding:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。也就是说,ELMO的预训练过程不仅仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。

ELMo模型核心是一个双层双向的LSTM网络,与传统的word2vec算法中词向量一成不变相比,ELMo会根据上下文改变语义embedding。
一个简单的例子就是 “苹果”的词向量
句子1:“我 买了 1斤 苹果”
句子2:“我 新 买了 1个 苹果 X”
在word2vec算法中,“苹果”的词向量固定,无法区分这两句话的区别,而ELMo可以解决语言中的二义性问题,可以带来性能的显著提升。
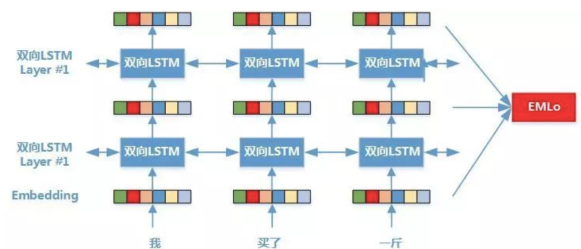
②下游任务:
下图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。至于为何这么做能够达到区分多义词的效果,你可以想一想,其实比较容易想明白原因。
为何可以解决多义词问题?

前面我们提到静态Word Embedding无法解决多义词的问题,那么ELMO引入上下文动态调整单词的embedding后多义词问题解决了吗?解决了,而且比我们期待的解决得还要好。上图给了个例子,对于Glove训练出的Word Embedding来说,多义词比如play,根据它的embedding找出的最接近的其它单词大多数集中在体育领域,这很明显是因为训练数据中包含play的句子中体育领域的数量明显占优导致;而使用ELMO,根据上下文动态调整后的embedding不仅能够找出对应的“演出”的相同语义的句子,而且还可以保证找出的句子中的play对应的词性也是相同的,这是超出期待之处。之所以会这样,是因为我们上面提到过,第一层LSTM编码了很多句法信息,这在这里起到了重要作用。
(4)GPT(Generative Pre-Training)
缺点:
单向语言模型
两阶段:预训练+fine-tuning解决下游任务
预训练:
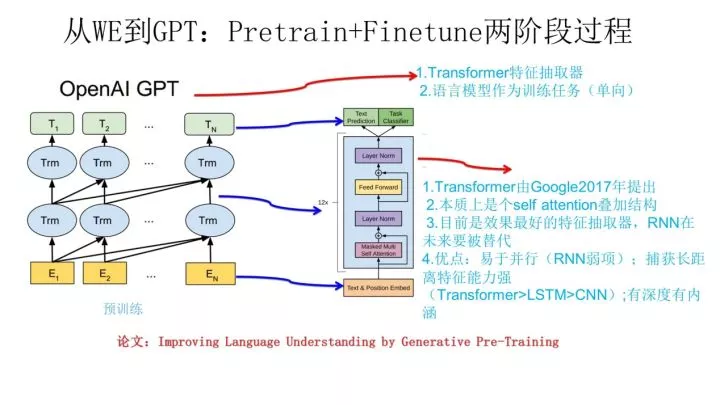
上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:
首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;而且具备并行能力。
其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 Wi 单词的上下文去正确预测单词 Wi ,Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词 Wi 同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的,白白丢掉了很多信息。
下游任务:


GPT论文给了一个改造施工图如上,其实也很简单:对于分类问题,不用怎么动,加上一个起始和终结符号即可;对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
(5)BERT
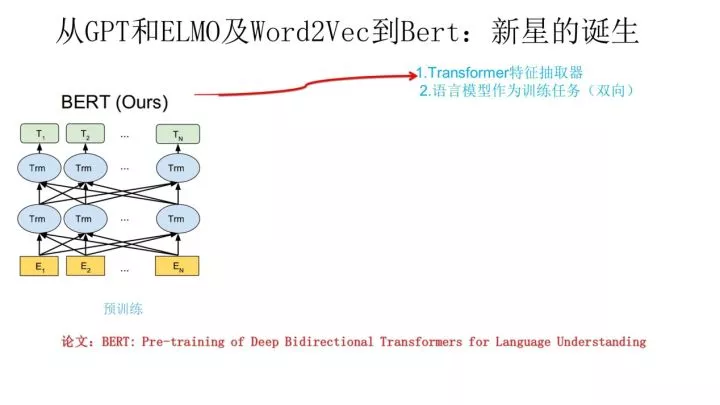
与GPT不同之处:
和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,
当然另外一点是语言模型的数据规模要比GPT大。所以这里Bert的预训练过程不必多讲了。
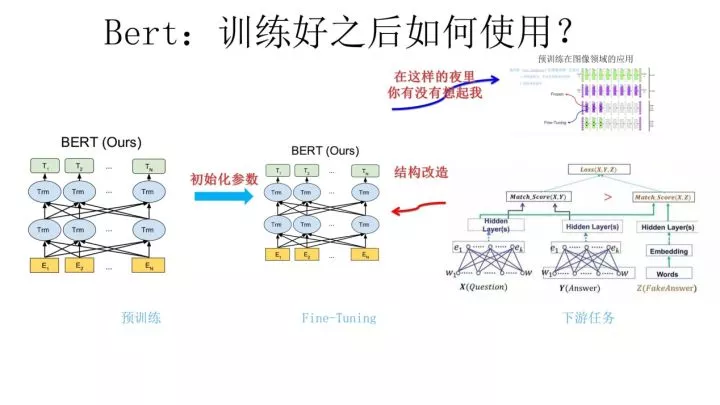
两阶段:
Bert采用和GPT完全相同的两阶段模型,
首先是语言模型预训练;
其次是使用Fine-Tuning模式解决下游任务。
Fine-Tuning阶段:这个阶段的做法和GPT是一样的。当然,它也面临着下游任务网络结构改造的问题,在改造任务方面Bert和GPT有些不同,下面简单介绍一下。

改造下游任务:

对于种类如此繁多而且各具特点的下游NLP任务,Bert如何改造输入输出部分使得大部分NLP任务都可以使用Bert预训练好的模型参数呢?上图给出示例,对于句子关系类任务,很简单,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层即可。对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。从这里可以看出,上面列出的NLP四大任务里面,除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。尽管Bert论文没有提,但是稍微动动脑子就可以想到,其实对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。这是相当直观的一种改造方法。当然,也可以更简单一点,比如直接在单个Transformer结构上加装隐层产生输出也是可以的。不论如何,从这里可以看出,NLP四大类任务都可以比较方便地改造成Bert能够接受的方式。这其实是Bert的非常大的优点,这意味着它几乎可以做任何NLP的下游任务,具备普适性,这是很强的。
(7)总结:
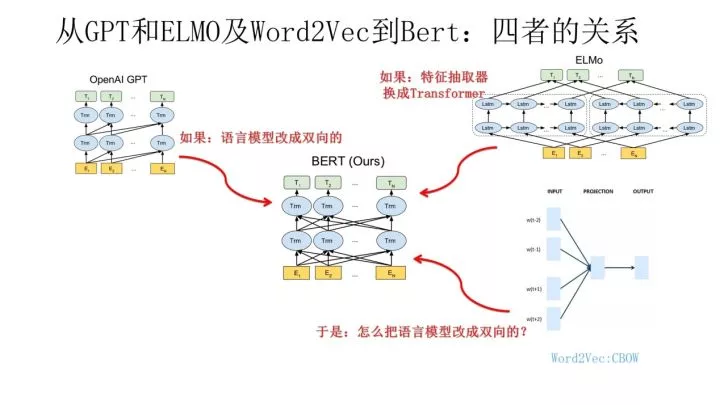
从上图可见,Bert其实和ELMO及GPT存在千丝万缕的关系,比如如果我们把GPT预训练阶段换成双向语言模型,那么就得到了Bert;而如果我们把ELMO的特征抽取器换成Transformer,那么我们也会得到Bert。
所以你可以看出:Bert最关键两点,一点是特征抽取器采用Transformer;第二点是预训练的时候采用双向语言模型。
二、BERT模型:
1、对于Transformer来说,怎么才能在这个结构上做双向语言模型任务呢?
BERT的作者指出这种两个方向相互独立或只有单层的双向编码可能没有发挥最好的效果,我们可能不仅需要双向编码,还应该要加深网络的层数。但加深双向编码网络却会引入一个问题,导致模型最终可以间接地“窥探”到需要预测的词。这个“窥探”的过程可以用下面的图来表示:
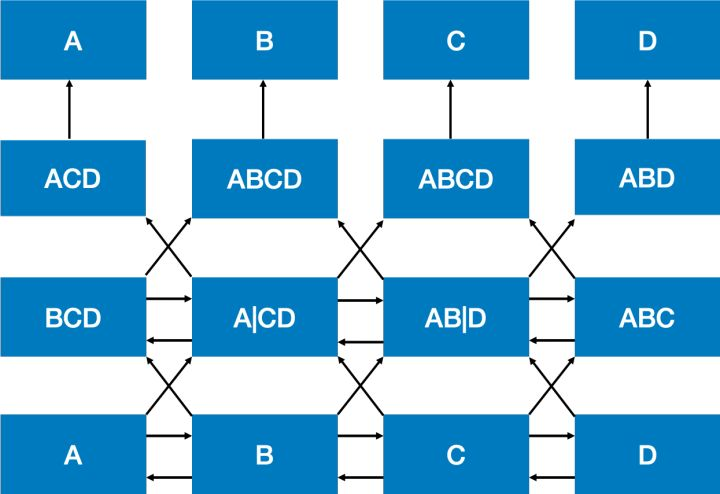
从图中可以看到经过两层的双向操作,每个位置上的输出就已经带有了原本这个位置上的词的信息了。这样的“窥探”会导致模型预测词的任务变得失去意义,因为模型已经看到每个位置上是什么词了。我们无法像传统的语言模型一样训练一个深度双向模型,因为其会产生环路『cycle』,词会间接“感知自身”,而预测变得微不足道『trivial』。
为了解决这个问题,我们可以从预训练的目标入手。我们想要的其实是让模型学会某个词适合出现在怎样的上下文语境当中;反过来说,如果给定了某个上下文语境,我们希望模型能够知道这个地方适合填入怎样的词。从这一点出发,其实我们可以直接去掉这个词,只让模型看上下文,然后来预测这个词。但这样做会丢掉这个词在文本中的位置信息,那么还有一种方式是在这个词的位置上随机地输入某一个词,但如果每次都随机输入可能会让模型难以收敛。
前面提到了CBOW方法,它的核心思想是:在做语言模型任务的时候,我把要预测的单词抠掉,然后根据它的上文Context-Before和下文Context-after去预测单词。其实Bert怎么做的?
Bert就是这么做的。从这里可以看到方法间的继承关系。
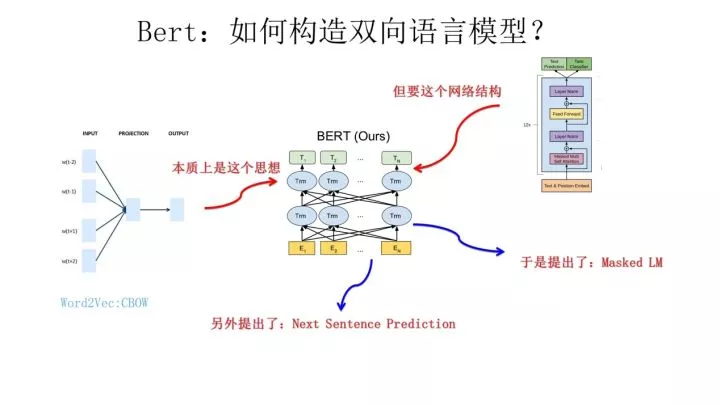
做法:Masked LM + Next Sentence Prediction(模型设置两个loss)
(1)Masked LM:
介绍:
通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号来代替它们。尽管模型最终还是会看到所有位置上的输入信息,但由于需要预测的词已经被特殊符号代替,所以模型无法事先知道这些位置上是什么词,这样就可以让模型根据所给的标签去学习这些地方该填的词了。
然而这里还有一个问题,就是我们在预训练过程中所使用的这个特殊符号,在后续的任务中是不会出现的。
因此,为了和后续任务保持一致,作者按一定的比例在需要预测的词位置上输入原词或者输入某个随机的词。当然,由于一次输入的文本序列中只有部分的词被用来进行训练,因此BERT在效率上会低于普通的语言模型,作者也指出BERT的收敛需要更多的训练步数。
例子:
Input:
the man [MASK1] to [MASK2] store
Label:
[MASK1] = went; [MASK2] = store (这里个人觉得MASK2应为2)尤其是,我们通过一个深层转换『Transformer』编码器进行输入,随后使用对应于遮盖处的最终隐态『final hidden states』对遮盖词进行预测,正如我们训练一个语言模型一样。
做法:
随机选择语料中15%的单词,把它抠掉,也就是用[Mask]掩码代替原始单词,然后要求模型去正确预测被抠掉的单词。
但是这里有个问题:训练过程大量看到[mask]标记,但是真正后面用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,
- 只有80%真正被替换成[mask]标记,
- 10%被狸猫换太子随机替换成另外一个单词,
- 10%情况这个单词还待在原地不做改动。
这就是Masked双向语音模型的具体做法。
(2)Next Sentence Precision
介绍:
BERT另一个创新:在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务。
这个任务的目标也很简单,就是预测输入BERT的两端文本是否为连续的文本,作者指出引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
“Next Sentence Prediction”,指的是做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。
另外,语言模型还不理解句间关系,而这恰恰对于许多自然语言处理任务而言十分重要。为了预训练一个句子关系模型,我们使用了非常简单的二元分类『binary classification』任务:连接两个句子A和B后,预测在原文中B是否真的出现在A之后。
例子:
做法:
在训练的时候,输入模型的第二个片段会以50%的概率从全部文本中随机选取,剩下50%的概率选取第一个片段的后续的文本。
原因:
是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程。这也是Bert的一个创新。
例子:
训练数据:

输入部分:
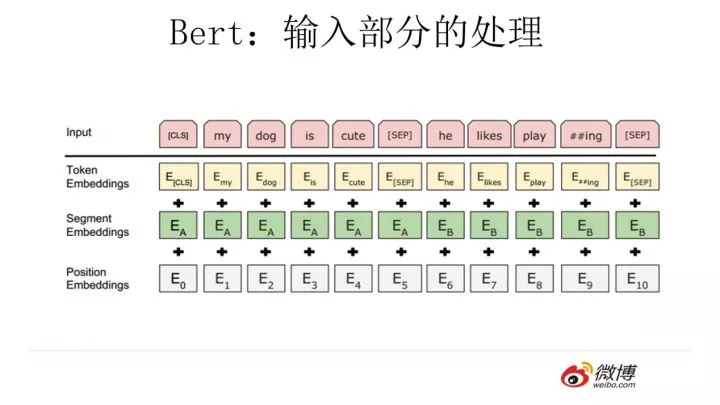
它的输入部分是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding:位置信息embedding,这是因为NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;单词embedding,这个就是我们之前一直提到的单词embedding;第三个是句子embedding,因为前面提到训练数据都是由两个句子构成的,那么每个句子有个句子整体的embedding项对应给每个单词。把单词对应的三个embedding叠加,就形成了Bert的输入。【直接用Transformer encoder会丢失位置信息,Transformer原文采用sin\cos函数编码位置,这里作者直接训练一个位置embedding】

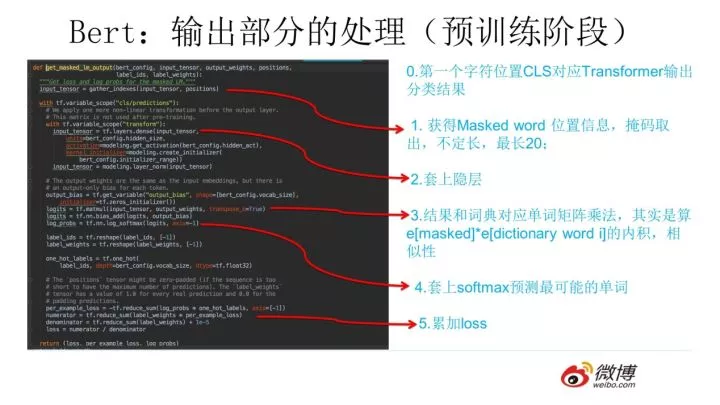
输出部分:
2、BERT优势:
- Bert最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用Bert这种两阶段解决思路,而且效果应该会有明显提升。
- 双向语言模型+Transformer提取特征(非RNN/CNN)
3、为何BERT效果好?
- (模型结构)采用了Transformer提取特征,提取效果比CNN或者RNN要好,CNN对于长距离依赖的特征提取效果不是很好(self-attention克服了),而RNN难并行。
- (训练目标)两个无监督任务:MLM和NSP(△),双向语言模型加上句子级别的任务,有利于学习上下文信息和语义信息的学习。
- (模型大小和数据量)训练预料大,训练充分【采用了英文的开源语料BooksCropus 以及英文维基百科数据,一共有33亿个词。同时BERT模型的标准版本有1亿的参数量,与GPT持平,而BERT的大号版本有3亿多参数量,】
4. 缺点

实战:https://segmentfault.com/a/1190000018420480
NLP学习(3)---Bert模型的更多相关文章
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- NLP学习(4)----word2vec模型
一. 原理 哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html 负采样推导: http://www.hankcs.com/nlp/word2v ...
- 【NLP学习其五】模型保存与载入的注意事项(记问题No module named 'model')
这是一次由于路径问题(找不到模型)引出模型保存问题的记录 最近,我试着把使用GPU训练完成的模型部署至预发布环境时出现了一个错误,以下是log节选 unpickler.load() ModuleNot ...
- win10 + 独显 + Anaconda3 + tensorflow_gpu1.13 安装教程(跑bert模型)
这里面有很多坑,最大的坑是发现各方面都装好了结果报错 Loaded runtime CuDNN library: 7.3.1 but source was compiled with: 7.4.1, ...
- NLP与深度学习(六)BERT模型的使用
1. 预训练的BERT模型 从头开始训练一个BERT模型是一个成本非常高的工作,所以现在一般是直接去下载已经预训练好的BERT模型.结合迁移学习,实现所要完成的NLP任务.谷歌在github上已经开放 ...
- Pytorch | BERT模型实现,提供转换脚本【横扫NLP】
<谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读>,上周推送的这篇文章,全面解读基于TensorFlow实现的BERT代码.现在,PyTorch用户的福利来了:一个名为Huggi ...
- [NLP自然语言处理]谷歌BERT模型深度解析
我的机器学习教程「美团」算法工程师带你入门机器学习 已经开始更新了,欢迎大家订阅~ 任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主 ...
- TF-IDF与主题模型 - NLP学习(3-2)
分词(Tokenization) - NLP学习(1) N-grams模型.停顿词(stopwords)和标准化处理 - NLP学习(2) 文本向量化及词袋模型 - NLP学习(3-1) 在上一篇博文 ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
随机推荐
- java基础系列(一):Number,Character和String类及操作
这篇文章总结了Java中最基础的类以及常用的方法,主要有:Number,Character,String. 1.Number类 在实际开发的过程中,常常会用到需要使用对象而不是内置的数据类型的情形.所 ...
- iostat的坑
简单使用iostat查询io使用量,会让你看不懂所以然,因为很多人疏忽了这个命令查到的结果根本不是实际值,需要注意的是一句话: “第1次采样信息与单独执行iostat的效果一样,为从系统开机到当前执行 ...
- 最新 美团java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.美团等10家互联网公司的校招Offer,因为某些自身原因最终选择了美团.6.7月主要是做系统复习.项目复盘.LeetCode ...
- Python小技巧:使用一行命令把你的电脑变成服务器
不知道你有没有遇到这么一种情况,就是你有时候想要把电脑上的一些东西传输到你的手机或者 Pad ,你要么需要使用数据线连接到电脑,有时候还要装各种驱动才可以进行数据传输,要么需要借助第三方的工具,在局域 ...
- Fiddler之打断点
1..Fiddler可以修改以下请求 --Fiddler设置断点,可以修改HTTP请求头信息,如修改Cookie,User-Agent等 --可以修改请求数据,突破表单限制,提交任意数字,如充值最小1 ...
- Python基础 第7章 再谈抽象
1. 1 多态 多态,即便不知道变量指向的是哪种对象,也能对其执行操作,且操作的行为将随对象所属的类型(类)而异. 1.2 多态与方法 当无需知道对象是什么样的就能对其执行操作时,都是多态在起作用. ...
- 【闭包】Pants On Fire
Pants On Fire 题目描述 Donald and Mike are the leaders of the free world and haven’t yet (after half a y ...
- (十一)mybatis之整合ehcache缓存
一.二级缓存 大家都知道使用mybatis就要先获取sqlsessionfactory,继而使用sqlsession来和数据库交互,每次只需要使用sqlsession对象提供的方法就好,当我们需要第一 ...
- Node初始以及环境搭建(Node01)
1. 相关概念 •什么是JavaScript? •一种遵守ECMAScript标准的脚本语言 •最初只能运行在浏览器端 •浏览器中的 JavaScript 可以做什么? •操作DOM:表单验证.动画 ...
- solr 配置中文分析器/定义业务域/配置DataImport功能(测试用)
一.配置中文分析器 使用IKAnalyzer 配置方法: 1)把IK的jar包添加到solr工程中/WEB-INF/lib目录下 2)把IK的配置文件扩展词典, ...