《流畅的Python》Data Structures--第2章序列array
第二部分 Data Structure
- Chapter2 An Array of Sequences
- Chapter3 Dictionaries and Sets
- Chapter4 Text versus Bytes
An Array of Sequences
本章讨所有的序列包括list,也讨论Python3特有的str和bytes。
也涉及,list, tuples, arrays, queues。
概览内建的序列
分类
Container swquences: 容器类型数据
- list, tuple
- collections.deque: 双向queue。
Flat sequences: 只存放单一类型数据
- str,
- bytes, bytearray, memoryview : 二进制序列类型
- array.array: array模块中的array类。一种数值数组。即只储存字符,整数,浮点数。
分类2:
Mutable sequences:
- list, bytearray, array.array
- collections.deque
- memoryview
Immutable sequences:tuple, str, bytes
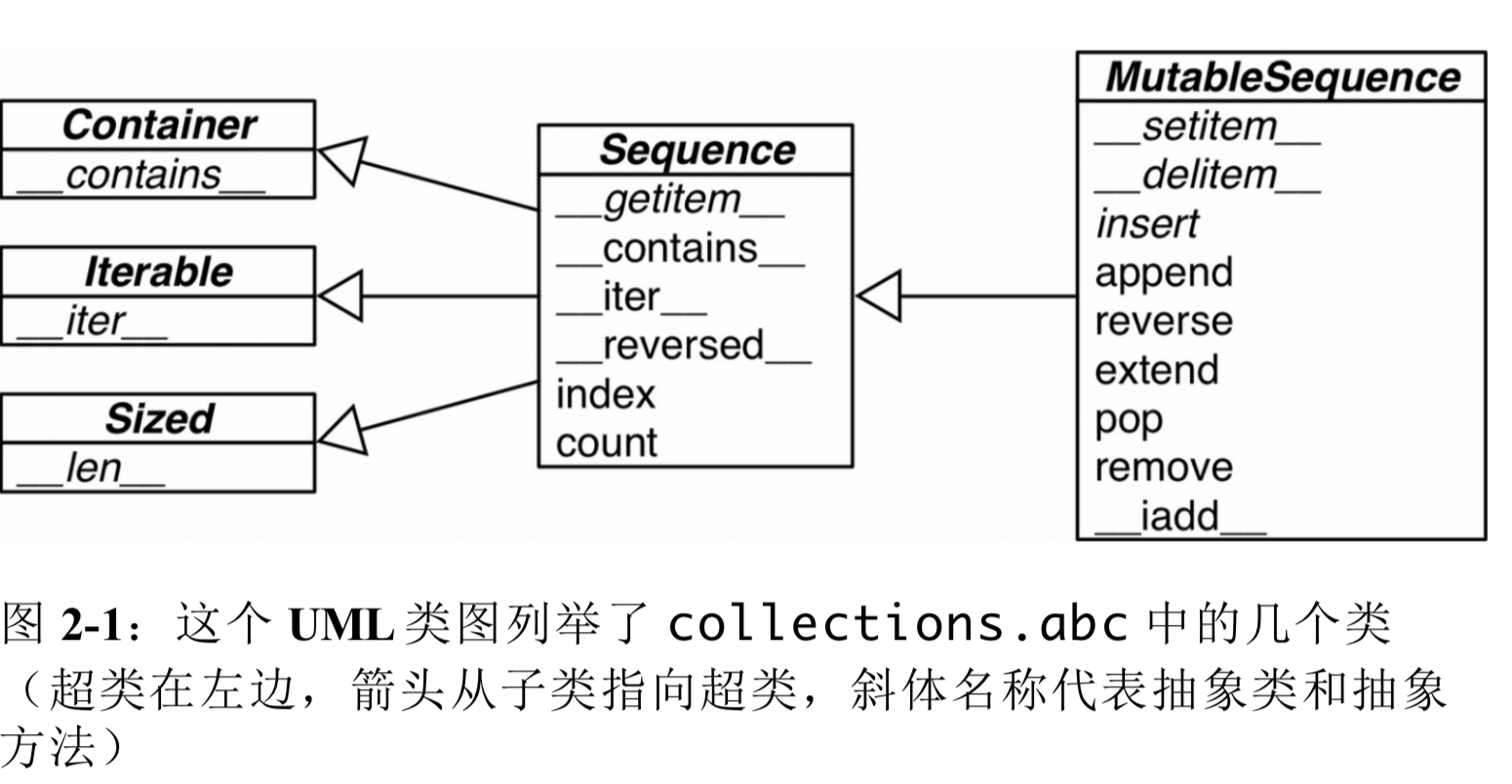
⚠️,内置的序列类型,并非直接从Sequence和MutableSequence这两个抽象基类(Abstract Base Class ,ABC)继承的。
了解这些基类,有助于我们总结出那些完整的序列类型包括哪些功能。
List Comprehensions and Generator Expressions
可以简写表示:listcomps, genexps。
例子:使用list推导式。
- #
- >>> symbols = '$¢£¥€¤'
- >>> codes = [ord(symbol) for symbol in symbols]
- >>> codes
- [36, 162, 163, 165, 8364, 164]
ord(c)是把字符转化为Uicode对应的数值.
列表推导式的好处:
- 比直接用for语句,更方便。也同样好理解。
- 类似函数, 会产生局部作用域,不会再有变量泄露的问题。
map()和filter组合
- symbols = '$¢£¥€¤'
- beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
- print(beyond_ascii)
map(func, iterable) -> iterator
速度上list comprehensions更快。
Generator Expressions
Listcomps只能产生一个list,而genexps可以产生其他类型的序列。
它遵守迭代器协议,逐个产生元素。
例子,利用genexps产生tuple和array.array
- symbols = '$¢£¥€¤'
- a = tuple(ord(symbol) for symbol in symbols)
- print(a)
- import array
- arr = array.array("I", (ord(symbol) for symbol in symbols))
- print(arr)
- print(arr[0])
- colors = ['black', 'white']
- sizes = ['S', 'M', 'L']
- a = ('%s %s' % (c, s) for c in colors for s in sizes)
- print(a)
- #产生一个生成器表达式<generator object <genexpr> at 0x10351b3c0>
⚠️函数生成器,要加yield关键字。
Tuples are not just Immutable lists
tuple除了是不可变数组/列表。
另有一个功能体现: 储存从数据库提取的一条记录:record, 但这个record没有field name,只有value。
例如:
- traveler_ids = [('USA', ''), ('BRA', 'CE342567'),
- ('ESP', 'XDA205856')]
- for passport in sorted(traveler_ids):
- print('%s/%s' % passport)
- for country, _ in traveler_ids:
- print(country)
- #输出
- BRA/CE342567
- ESP/XDA205856
- USA/31195855
- USA
- BRA
- ESP
⚠️:_是一个占位符。
tuple unpacking
一个习惯用法产生的概念:
- >>> lax_coordinates = (33.9425, -118.408056)
- >>> latitude, longitude = lax_coordinates # tuple unpacking >>> latitude
- 33.9425
- >>> longitude
- -118.408056
下面的赋值代码省略了中间变量 :
- >>>b,a=a,b
#等同于
x = (a, b)
b, a = x
这个概念也可以用到其他的类型上,如list。range(), dict。
- >>> a, b, *rest = range(3)
- >>> a, b, rest
- (0, 1, [2])
⚠️使用*号抓起过多的item
有拆包,就有打包:
- >>> o = 1
- >>> n = 2
- >>> o, n
- (1, 2)
Nested Tuple Unpacking 嵌套tuple的解包
只要表达式左边的结构,符合嵌套元祖的结构,嵌套tuple也可以解包
- >>> x = ('Tokyo','JP',36.933,(35.689722,139.691667))
- >>> name, cc, pop, (latitude, longitude) = x
- >>> name
- 'Tokyo'
- >>> longitude
- 139.691667
Named Tuples --一个tuple的子类
具有tuple的方法,同时也有自己的方法和属性。
因为tuple具有拆包封包的特性,用起来很方便。
⚠️list拆包后,再封包,得到的是tuple类型。
- >>> a = list(range(2))
- >>> a
- [0, 1]
- >>> x,y = a
- >>> x
- 0
- >>> y
- 1
- >>> x, y
- (0, 1)
- >>> z = x ,y
- >>> z
- (0, 1)
但是,如果把tuple类型用在一条数据库记录上:因为缺少fields字段。就很不方便,因此出现了Tuples类的子类named tuples。
使用工厂函数:collections.namedtuple(typename, field_names, *)
- field_names可以是['x', 'y']也可以是"x, y, z"或"x y z"
下例子:创建一个子类City, 它的父类是tuple。即Ciyt.__bases__返回(<class 'tuple'>,)
- from collections import namedtuple
- Card = namedtuple("Card", ['rank', 'suit'])
- City = namedtuple('City', 'name country population coordinates')
- tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
- print(tokyo)
- #City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722, 139.691667))
⚠️内存一样
namedtuple和tuple的实例,占用的内存是一样的。因为namedtuple实例把字段名储存在了对应的类中。
因为结构固定,所以可以像dict一样显示key=value;
- Tu = ('Tokyo', 'JP', 36.933, (35.689722, 139.691667))
import sys- print(sys.getsizeof(tokyo))
- print(sys.getsizeof(Tu))
- #
- #
类方法
_fields: 返回类的所有的field的名字。
- >>> City._fields
- ('name', 'country', 'population', 'coordinates')
_asdict:返回一个对应field字段的dict:
- print(tokyo._asdict())
- #返回一个dict {'name': 'Tokyo', 'country': 'JP', 'population': 36.933, 'coordinates': (35.689722, 139.691667)}
_make(): 接受一个可迭代对象来生成这个类的一个实例。等同于City(*tokyo)。
小结:
因为namedtuple的功能扩展,这个类就支持从数据库读取一条记录。但是因为是tuple的子类,不能对记录进行修改。
Slicing --切片的高级用法
list, tuple, str这些sequences类都支持slicing。
Why Slices and Range Exclude the last Item?
就是习惯。真要找原因:
- my_list[:x] and my_list[x:]合起来就是my_list
- a[:3], 直接清楚的表示这个切片包括3个item。
- a[2:6], 6-2等于4。表示这个切片包括四个item。
Slice Objects
切片对象的用途:
一个有固定格式纯文本文件,需要对这个文件的每一行都进行相同的切片操作,那么使用Slice对象保存这种切片的起始位置和step。
之后无需反复重写切片了。
例子:
- #invoice.txt
- 0.....6.................................40........52...55........
- 1909 Pimoroni PiBrella $17.50 3 $17.50
- 1489 6mm Tactile Switch x20 $4.95 2 $9.90
- 1510 Panavise Jr. - PV-201 $28.00 1 $28.00
- #首先,读取文本文件的内容
- with open('invoice.txt', 'r') as invoice:
- line_items = invoice.read()
- #然后,按照文本内的格式,创建3个切片对象,
- sku = slice(0, 6)
- description = slice(6, 40)
- unit_price = slice(40, 52)
- #最后,逐行打印切片的结果
- for item in line_items.split('\n')[1:]:
- print(item[unit_price], item[description])
直接使用切片对象的好处,方便代码的管理和维护。用自然语言描述要切片的字符串。
class slice(start=None, stop[, step=None])
返回一个slice对象。start,step默认为None。
slice对象有三个只读的数据属性(就是instance variable)start, stop, step
- >>> a
- slice(0, 6, None)
- >>> type(a).__dict__.keys()
- dict_keys(['__repr__', '__hash__', '__getattribute__', '__lt__', '__le__',
'__eq__', '__ne__', '__gt__', '__ge__', '__new__', 'indices', '__reduce__', 'start', 'stop', 'step', '__doc__'])- >>> a.start
- 0
- >>> a.stop
- 6
给切片赋值
可以给切片赋值,值必须是可迭代对象。替换原list中的元素。
但如果切片start等于stop,则相当于插入了。
⚠️可参考源码(c写的)或这篇文章https://www.the5fire.com/python-slice-assignment-analyse-souce-code.html
Pythong, Ruby都支持对序列类型进行+和*操作
需要注意*操作对嵌套list:
- >>> d = [[""]*3]*3
- >>> d
- [['', '', ''], ['', '', ''], ['', '', '']]
- >>> d[1][1] = 's'
- >>> d
- [['', 's', ''], ['', 's', ''], ['', 's', '']]
相当于:
- >>> a = ['']*3
- >>> a
- ['', '', '']
- >>> b = [a]*3
- >>> b
- [['', '', ''], ['', '', ''], ['', '', '']]
- >>> b[1][1] = "x"
- >>> b
- [['', 'x', ''], ['', 'x', ''], ['', 'x', '']]
⬆️例子,列表b,使用了3次a。b相当于[a, a, a]。
Augmented Assignment with Sequences 序列的增量赋值操作符 *=, +=
+=的背后是__iadd__方法,即(in-place addition,翻译过来就是,在当场进行加法运算,简单称为就地运算。)
这是因为a.+= b中的a 的内存地址不发生变化,所以称为就地运算。
⚠️但是,是否执行就地运算,要看type(a)是否包括__iadd__这个方法了。如果没有,则只相当于a = a + b, 新的a是一个新的对象。
- 可变序列支持__iadd__
- 不可变序列当然不支持了。比如tuple就不支持。
- ⚠️str作为不可变序列,支持__iadd__,这是因为在循环内对str做+=太普遍了。因此对它做了优化,str实例初始化内存时预留了足够的空间,因此不会复制原有的字符串到新内存位置,
- >>> l = list(range(3))
- >>> l
- [0, 1, 2]
- >>> id(l)
- 4421232256
- >>> l *= 2
- >>> id(l)
- 4421232256
同样 *=及其他增量赋值操作符 都是这样。
关于+=的 Puzzler
- >>> t = (1, 2, [30, 40])
- >>> t[2] += [50,60]
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- TypeError: 'tuple' object does not support item assignment
- >>> t
- (1, 2, [30, 40, 50, 60])
这个例子,完成了操作之后报告了❌。原因分析:
需要前置知识点:字节码,dis模块。 code object等知识。
模块dis:https://docs.python.org/zh-cn/3/library/dis.html 字节码反汇编器
什么是字节码?
字节码就是把可读的源码通过编译转化为bytecode,字节码还需要解释器才能转换为机器代码,所以字节码是一种中间代码。
操作系统都支持字节码转化,因此字节码可以用到不同系统中,通过转化为机器码直接在硬件上运行。
而且字节码也可以逐条执行。有了解释型语言的特点。
Python源代码会被编译成bytecode, 即Cpython解释器中表示Python程序的内部代码。它会缓存在.pyc文件(在文件夹__pycache__)内,这样第二次执行同一文件时速度更快。
具体见博文:https://www.cnblogs.com/chentianwei/p/12002967.html
再说上面的例子: dis.dis(x):反汇编x对象。
- >>> dis.dis('s[a] += b')
- 1 0 LOAD_NAME 0 (s) #把s推入计算栈
- 2 LOAD_NAME 1 (a) #把a推入计算栈
- 4 DUP_TOP_TWO # 复制顶部的两个引用,无需从栈取出item
- 6 BINARY_SUBSCR #执行计算: TOS = TOS1[TOS], 即把s[a]的值推入计算栈(TOS代表栈的顶部), 现在栈里有3个item.
- 8 LOAD_NAME 2 (b) #把b推入栈
- 10 INPLACE_ADD #Tos = tos1+ tos, 即先从栈取出前2个item, 然后s[a] + b的结果推入栈。
- 12 ROT_THREE # 将第2个,第三个栈项向上提升一个位置,栈顶部的项移动到第3个位置。
- 14 STORE_SUBSCR # tos1[tos] = tos3
- 16 LOAD_CONST 0 (None)
- 18 RETURN_VALUE
- t[2] += [50,60]
当进行到上面
《流畅的Python》Data Structures--第2章序列array的更多相关文章
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week6 Tuple课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week6 Tuple 10 Tuples 10.1 Tuples A ...
- 《Python Data Structures》Week5 Dictionary 课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week5 Dictionary 9.1 Dictionaries 字 ...
- 《Python Data Structures》 Week4 List 课堂笔记
Coursera课程<Python Data Structures> 密歇根大学 Charles Severance Week4 List 8.2 Manipulating Lists 8 ...
- 《流畅的Python》 第一部分 序章 【数据模型】
流畅的Python 致Marta,用我全心全意的爱 第一部分 序幕 第一章 Python数据模型 特殊方法 定义: Python解释器碰到特殊句法时,使用特殊方法激活对象的基本操作,例如python语 ...
- 《流畅的Python》第二部分 数据结构 【序列构成的数组】【字典和集合】【文本和字节序列】
第二部分 数据结构 第2章 序列构成的数组 内置序列类型 序列类型 序列 特点 容器序列 list.tuple.collections.deque - 能存放不同类型的数据:- 存放的是任意类型的对象 ...
- Python实验报告——第4章 序列的应用
实验报告 [实验目的] 1.掌握python中序列及序列的常用操作. 2.根据实际需要选择使用合适的序列类型. [实验条件] 1.PC机或者远程编程环境. [实验内容] 1.完成第四章 序列的应用 实 ...
- 流畅的python学习笔记:第二章
第二章开始介绍了列表这种数据结构,这个在python是经常用到的结构 列表的推导,将一个字符串编程一个列表,有下面的2种方法.其中第二种方法更简洁.可读性也比第一种要好 str='abc' strin ...
- 流畅的python学习笔记:第一章
这一章中作者简要的介绍了python数据模型,主要是python的一些特殊方法.比如__len__, __getitem__. 并用一个纸牌的程序来讲解了这些方法 首先介绍下Tuple和nametup ...
- 《流畅的Python》 A Pythonic Object--第9章
Python的数据模型data model, 用户可以创建自定义类型,并且运行起来像内建类型一样自然. 即不是靠继承,而是duck typing. 支持用内建函数来创建可选的对象表现形式.例如repr ...
随机推荐
- vue input 循环渲染问题
<li> <span>下属区县:</span> <div class="quxianList" v-for="(qx,index ...
- python,pycharm,anaconda之间的区别与联系 - python基础入门(2)
Python环境配置-Pycharm下载/Anaconda安装 中我们已经完成了 Pycharm 和Anaconda 的安装.可能对于刚接触的小伙伴还是比较懵逼的,一会python一会Anaconda ...
- 浅谈UML的概念和模型
讲了UML的基本的九种图:http://blog.csdn.net/jiuqiyuliang/article/details/8552956 来具体讲讲这九种视图: 1.用例图(use case di ...
- 某 游戏公司 php 面试题
1.实现未知宽高元素的水平垂直居中,至少两种方法. <div, class="father"> <div class="son">< ...
- Python列表推导
一. 列表推导式 ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数, 它以一个字符(长度为1的字符串)作为参数,返回 ...
- WUSTOJ 1237: 将八进制的字符串转换成等价的十进制字符串(Java)
1237: 将八进制的字符串转换成等价的十进制字符串 题目 输入八进制,输出十进制.更多内容点击标题. 分析 输入的八进制数有20位.已经超出了Integer.MAX_VALUE的范围,因此此 ...
- 解决IIS出现“由于权限不足而无法读取配置文件”的问题
在部署IIS项目的时候,今天突然遇到了如下问题: HTTP 错误 500.19 - Internal Server Error 无法访问请求的页面,因为该页的相关配置数据无效 详细错误信息: 由于权限 ...
- git this exceeds GitHub's file size limit of 100.00 MB
git push origin master过程中,出现如下错误 关键词:this exceeds GitHub's file size limit of 100.00 MB 推的时候忽略文件的操作: ...
- MySQL 字段类型介绍
MySQL 基础篇 三范式 MySQL 军规 MySQL 配置 MySQL 用户管理和权限设置 MySQL 常用函数介绍 MySQL 字段类型介绍 MySQL 多列排序 MySQL 行转列 列转行 M ...
- (一)Spring框架基础
一.什么是spring框架 spring是J2EE应用程序框架,是轻量级的IoC和AOP的容器框架,主要是针对javaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和Struts框架,i ...