python ORM模块sqlalchemy的使用
1、安装sqlalchemy
pip install sqlalchemy
2、导入必要的包及模块
import sqlalchemy
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
3、创建数据库连接实例
#创建数据库连接实例(#"数据库类型+数据库模块://用户名:密码@主机/库名")
db=sqlalchemy.create_engine("mysql+pymysql://root:q1q1q1@localhost/a")
4、创建一个元类的继承类
base = declarative_base(db)
5、定义一个表(使用类)继承base
class Student(base):
__tablename__ = "student"
id = sqlalchemy.Column(sqlalchemy.Integer,primary_key=True)
name = sqlalchemy.Column(sqlalchemy.String(32))
age = sqlalchemy.Column(sqlalchemy.String(32))
6、创建表
base.metadata返回sqlalchemy.schema.MetaData对象,它是所有Table对象的集合,调用create_all()该对象会触发CREATE TABLE语句,如果数据库还不存在这些表的话。
if __name__ == "__main__":
base.metadata.create_all(db)
脚本运行前a数据库中的表:
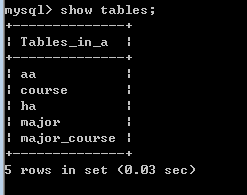
运行上述代码之后,a数据库表:
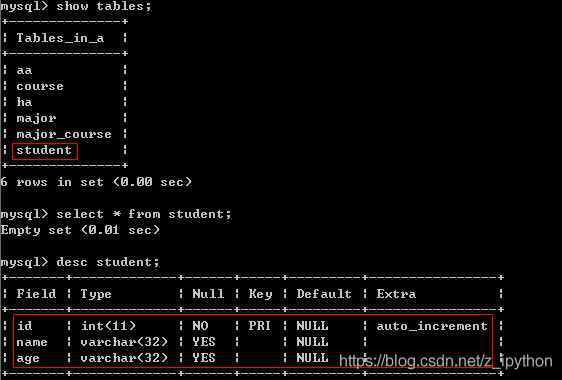
7、绑定连接并创建session
cursor = sessionmaker(bind=db) #得到的时一个类
session = cursor() #实例
8、增(插入数据)
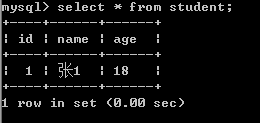
①插入一条数据
stu = Student(
id = 1,
name = "张1",
age = 18
)
session.add(stu)
session.commit()
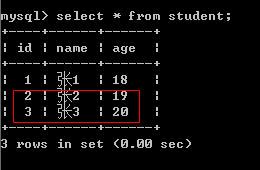
②同时插入多条数据
session.add_all([
Student(id=2,name="张2",age=19),
Student(id=3,name="张3",age=20)
])
session.commit()
9、查询
①查询所有数据
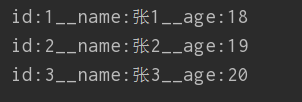
all_data = session.query(Student).all()#得到的是一个可迭代对象
for data in all_data:
print("id:%s__name:%s__age:%s"%(data.id,data.name,data.age))
②根据条件查询多条数据
many_data = session.query(Student).filter_by(age=18)
print(many_data)#实际是一个sql查询语句,其还是一个存储一个对象的带迭代内容
for data in many_data:
print("id:%s__name:%s__age:%s"%(data.id,data.name,data.age))

还可以通过序列解包的方式获取数据
many_data = session.query(Student).filter_by(age=18)
data, = many_data
print("id:%s__name:%s__age:%s"%(data.id,data.name,data.age))
③查询一条数据
data = session.query(Student).get(ident=3) #查一条,只能以主键查
print("id:%s__name:%s__age:%s"%(data.id,data.name,data.age))
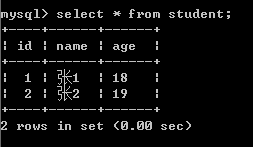
10、删除
#先查询一条
data = session.query(Student).get(ident=3)
#然后删除
session.delete(data)
#然后提交操作
session.commit()
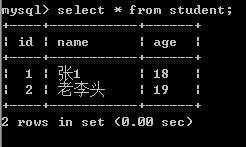
11、修改
# 先查询一条
data = session.query(Student).get(ident=2)
#然后删除
data.name = "老李头"
#然后提交操作
session.commit()
python ORM模块sqlalchemy的使用的更多相关文章
- python ORM之sqlalchemy
前沿对象关系映射ORM是在实际应用编程中常用到的技术,它在对象和关系之间建立了一条桥梁,前台的对象型数据和数据库中的关系型的数据通过这个桥梁来相互转化.简单来说就是开发人员在使用ORM模型编程时,不需 ...
- Python ORM框架SQLAlchemy学习笔记之数据添加和事务回滚介绍
1. 添加一个新对象 前面介绍了映射到实体表的映射类User,如果我们想将其持久化(Persist),那么就需要将这个由User类建立的对象实例添加到我们先前创建的Session会话实例中: 复制代码 ...
- python连接数据库使用SQLAlchemy
参考python核心编程 ORM(Object Relational Mapper),如果你是一个更愿意操作Python对象而不是SQL查询的程序员,并且仍然希望使用关系型数据库作为你的后端,那么你可 ...
- Python与数据库[2] -> 关系对象映射/ORM[0] -> ORM 与 sqlalchemy 模块
ORM 与 sqlalchemy 1 关于ORM / About ORM 1.1 ORM定义 / Definition of ORM ORM(Object Relational Mapping),即对 ...
- python(十二)下:ORM框架SQLAlchemy使用学习
此出处:http://blog.csdn.net/fgf00/article/details/52949973 本节内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- python的ORM框架SQLAlchemy
本节内容 ORM介绍 sqlalchemy安装 sqlalchemy基本使用 多外键关联 多对多关系 表结构设计作业 一.ORM介绍 如果写程序用pymysql和程序交互,那是不是要写原生sql语句 ...
- Django和SQLAlchemy,哪个Python ORM更好?
ORM是什么? 在介绍Python下的两个ORM框架(Django和SQLAlchemy)的区别之前,我们首先要充分了解ORM框架的用途. ORM代表对象关系映射.ORM中的每个单词解释了他们在实际项 ...
- 【Python】ORM框架SQLAlchemy的使用
ORM和SQLAlchemy简介 对象关系映射(Object Relational Mapping,简称ORM),简单的来说,ORM是将数据库中的表与面向对象语言中的类建立了一种对应的关系.然后我们操 ...
随机推荐
- lumen伪静态路由设置示例
lumen路由文件中的配置: $app->get('info-{tid}.html', 'ThreadController@palmInfo'); 控制器中代码示例: public functi ...
- LODOP中带caption的表格被关联并次页偏移测试
ADD_PRINT_TABLE中的thead和tfoot可以每页输出,后面的打印项关联表格,可以紧跟着表格,实现在表格后面紧跟着输出内容的效果,表格可以自动分页,并总是跟在表格后面 ,在表格最后输出. ...
- Python - 在CentOS7.5系统中安装Python3
注意:以下内容均使用root用户执行操作. 1-确认信息 # uname -a Linux localhost.localdomain 3.10.0-957.el7.x86_64 #1 SMP Thu ...
- 清除 sql server 记住密码
引用:https://www.cnblogs.com/zengbin/p/4307013.html SQL Server 2005 Management Studio %AppData%\Micros ...
- [Attention Is All You Need]论文笔记
主流的序列到序列模型都是基于含有encoder和decoder的复杂的循环或者卷积网络.而性能最好的模型在encoder和decoder之间加了attentnion机制.本文提出一种新的网络结构,摒弃 ...
- Docker快速安装
目前装Docker得最简单方式就是脚本安装了,方法如下: curl -fsSL https://get.docker.com -o get-docker.sh sh get-docker.sh 安装后 ...
- go零碎总结
1.go里通过首字母大小写来区分它是私有的还是公有的,比如对于一个结构体属性一般就以大写开头(和Java不一样,不需要什么getter,setter方法):而对于方法而言,它是隶属于包(包名一定是小写 ...
- kafka原理分析
#kafka为什么有高吞吐量 1 由于接收数据时可以设置request.required.acks参数,一般设定为1或者0,即生产者发送消息0代表不关心kafka是否接收成功,也就是关闭ack:1代表 ...
- [转帖]TPC-C解析系列03_TPC-C基准测试之SQL优化
TPC-C解析系列03_TPC-C基准测试之SQL优化 http://www.itpub.net/2019/10/08/3330/ TPC-C是一个非常严苛的基准测试模型,考验的是一个完备的关系数据库 ...
- python基础学习(十一)
22.类 # 类 class # 实例 实体 instance class Student: # 空语句 保持结构的完整性 pass jack = Student() jack.name = &quo ...