【机器学习】转导推理——Transductive Learning
在统计学习中,转导推理(Transductive Inference)是一种通过观察特定的训练样本,进而预测特定的测试样本的方法。另一方面,归纳推理(Induction Inference)先从训练样本中学习得到通过的规则,再利用规则判断测试样本。然而有些转导推理的预测无法由归纳推理获得,这是因为转导推理在不同的测试集上会产生相互不一致的预测,这也是最令转导推理的学者感兴趣的地方。
Transductive Learning:从彼个例到此个例,有点象英美法系,实际案例直接结合过往的判例进行判决。关注具体实践。
Inductive Learning:从多个个例归纳出普遍性,再演绎到个例,有点象大陆法系,先对过往的判例归纳总结出法律条文,再应用到实际案例进行判决。从有限的实际样本中,企图归纳出普遍真理,倾向形而上,往往会不由自主地成为教条。
强调一点,根据Vapnik的Statistical Learning Theory中提出统计学习中考虑两种不同类型的推理:归纳推理(Inductive inference)和转导推理(Transductive inference).转导推理的目的是估计某一未知预测函数在给定兴趣点上的值(而不是在该函数的全部定义域上的值).关键是,通过求解要求较低的问题,可以得到更精确的解.
传统的推理方法是归纳-演绎方法,人们首先根据用已有的信息定义一个一般规则,然后用这个规则来推断所需要的答案.也就是说,首先从特殊到一般,然后从一般到特殊.但是在转导模式中,我们进行直接的从特殊到特殊的推理,避免了推理中的不适定部分.
归纳推理中的一个经典方法是贝叶斯决策,通过求解P(Y|X)=P(X|Y)P(Y)/P(X)得到从样本X到类别Y的概率分布P(Y|X),进而使用P(Y|X)预测测试样本的类别。这一过程的缺点在于,在预测某一测试样本的类别之前,先要建立一个更通用的判别模型。那么是否能够更直接判别测试样本的类别呢?一个办法就是通过转导推理。转导推理由Vladimir Naumovich Vapnik(弗拉基米尔·万普尼克)于20世纪90年代最先提出,其目的就在于建立一个更适用于问题域的模型,而非一个更通用的模型。这方面的经典算法有最近邻(K
Nearest Neighbour)和支持向量机(Support Vector Machine)等。
特别是当训练样本非常少,而测试样本非常多时,使用归纳推理得到的类别判别模型的性能很差,转导推理能利用无标注的测试样本的信息发现聚簇,进而更有效地分类。而这正是只使用训练样本推导模型的归纳推理所无法做到的。一些学者将这些方法归类于半监督模型(Semi-Supervised Learning),但Vapnik认为是转导推理3。这方面的经典算法有转导支持向量机(Transductive
Support Vector Machine)等。
{kind=link}
转导推理的产生的第三个动机在于模型近似。在某些工程应用中,严格的推导所产生的计算量可能是非常巨大的,工程人员希望找到某些近似模型能适应他们所面临的特定问题,不需要适用于所有情况。
如下图所示。判别模型的任务是预测未标注数据点的类别。归纳推理方法通过训练一个监督学习模型来预测所有未标注点的类别。这样,训练样本中就只有5个点供以训练监督学习模型。对于图中较靠中心的某点(红色圆圈),利用最近邻算法就会将其标记为A或C,但从所有数据组成的类簇来看,此点应标为B。
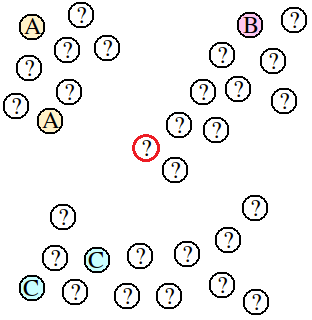
图1:少量标注样本时,使用KNN算法预测样本类别。训练样本是少量已经标注(A、B、C)的点,而其它大部分的点都是未标注的(记为?)。
转导推理会利用所有点的信息进行预测,也就是说转导推理会根据数据所从属的类簇进行类别标注。这样中间红色圈的点由于非常接近标为B的点所从属的类簇,就会标注为B。可以看出转导推理的优势就在于其能通过少量的标注样本进行预测。而其不足之处就在于其没有预测模型。当新未知点加入数据集时,转导推理可能需要与数据量成正比的计算来预测类别,特别是当新数据不断地被获取和加入时,这种计算量的增长显得犹为突出,而且新数据的添加可能会造成旧数据类别的改变(根据实际应用的不同,可能是好的,也可能是坏的)。相反地,归纳推理由于有模型存在,在计算量上可能会优于转导推理(模型的更新可能增加计算量)。
文章的后面部分将以二分类为例,先从较简单的情况开始,即给定大量的标注样本,判断测试样本的类别,讨论最近邻(k Nearest Neighbours,KNN)和支持向量机(Support Vector Machine,SVM)。接着就讨论在给定少量标注样本和大量测试样本的情况下,判断测试样本的方法,主要是转导支持向量机(Transductive Support Vector Machine,TSVM)。
最近邻与支持向量机
最近邻算法是通过考虑与测试样本最近的几个训练样本的信息来分类测试样本。最近邻算法的关键有二:
- 如何度量测试样本到训练样本的距离(或者相似度)
- 如何利用近邻的类别等信息
一种简单的办法是度量测试样本到训练样本间的距离,选择最近的若干个训练样本,若某一类别的点占多数,就简单地将测试样本归为那类。如下图所示,使用了欧几里得距离和街区距离度量测试样本到训练样本的距离。
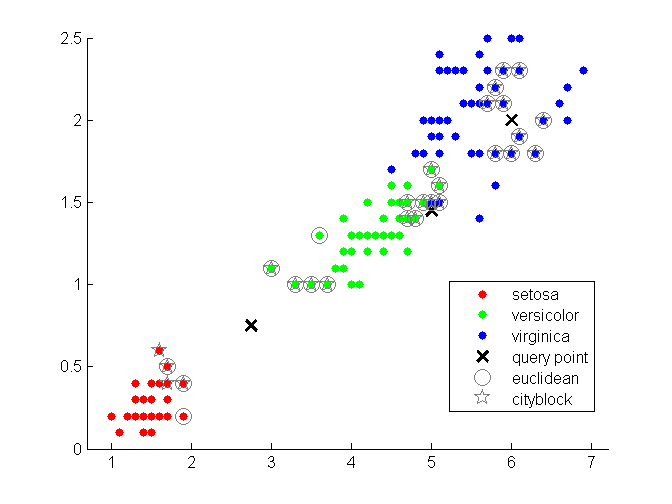
图2:最近邻示意图。使用欧几里得距离和街区距离进行度量
可以发现最近邻算法在预测每个测试样本的类别时,所利用的只是整个训练样本集中一部分。最近邻算法没有在训练样本集上归纳出一个通用的模型,而是只通过测试样本相近的点作判断。接着再来看看支持向量机又是如何从训练样本转导出分类面。
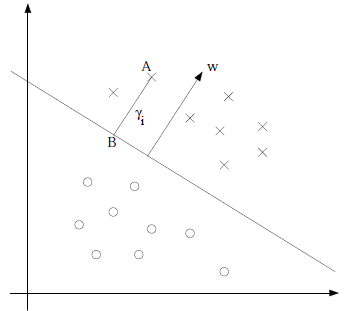
对于二分类问题,给定一个训练样本(xi,yi)(xi,yi),x是特征,y是类别标签(正类为1,负类为-1),i表示第i个样本。定义划分二类数据的分类面为wTx+bwTx+b,其中w为分类面的法向量,b为分类面的偏移量。正类在分类面的上方(wTx+bwTx+b),负类在分类面的下方(wTx+bwTx+b)。定义单个训练样本的函数间隔:
可以看出来,当yiyi=-1时,训练样本是负类,wTx+b<0wTx+b<0,γiγi大于0,反之亦然。良好的分类面应能使训练样本的函数间隔最大。函数间隔不仅代表了特征被判别为正类或反类的确信度,而且是评价分类面的指标。如果同时加大w和b,比如在前面乘个系数(比如2),那么所有点的函数间隔都会增大二倍,这个对求解wTx+b=0wTx+b=0是无影响的。这样,为了限制w和b,可能需要加入归一化条件,毕竟求解的目标是确定唯一一个w和b,而不是多组线性相关的向量。故单个训练样本的函数间隔亦可写为:
函数间隔亦可从几何间隔上推导得到。

图3:以“×”标记的点是正类数据,以“O”标记的点是负类数据。A点位于分类面之上,B在分类面上,w是分类面的法向量。
设A点为(xi,yi)(xi,yi),w方向的单位向量为w∥w∥w∥w∥,则B点横坐标x=xi−γiw∥w∥x=xi−γiw∥w∥,代入B点所处的分类面方程:
与函数间隔的归一化结果是一致的。根据转导推理的原理,我们大可不必使所有训练样本到分类面的函数间隔最大,只需让离分类面比较近点能有更大间距即可。也就是说求得的超平面并不以最大化所有点到其的函数间隔为目标,而是以离它最近的点具有最大间隔为目标。 定义训练样本集(m个样本)上的函数间隔:
也就是训练样本集上离分类面最近的样本点到分类面的距离。求解模型形式化定义如下:
由于∥w∥=1∥w∥=1,此最大化函数不是凸函数,没法直接代入Matlab等优化软件进行计算。注意到几何间隔和函数间隔的关系,令
这里除以∥w∥∥w∥是为了使求出w和b的确定值,而不是w和b的一组倍数。γ=1γ=1的意义是使得训练样本集上的函数间隔为1,也即是将离超平面最近的点的距离定义为1∥w∥1∥w∥。而其最大值,也就是的12∥w∥212∥w∥2最小值,则原最大化函数可改写为:
以上讨论适用于二类可分的情况,当两类不可分时,引入松驰变量ξiξi替代γγ
最终的求解将使用分类面的对偶表达及相关泛函,但这不是本文的重点。KNN和SVM的分类效果如下图所示:
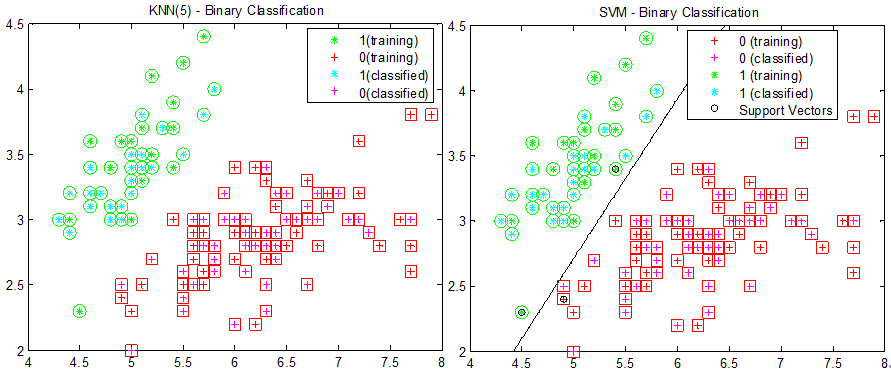
图4:KNN(选择5个最近邻)和SVM的分类结果,数据使用Matlab的Fisher Iris的一维和二维数据
在标注样本充足的情况,最近邻和支持向量机都表现得不错。但当标注样本不足时,最近邻和支持向量机的表现就显著下降。如下图所示。
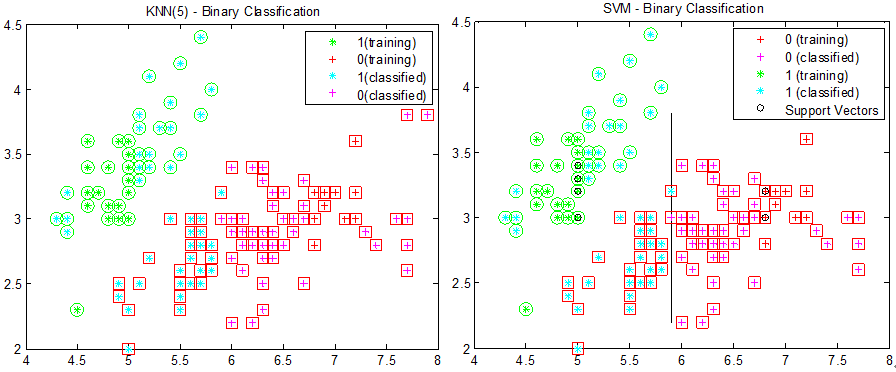
图5:标注数据只取x坐标值在[4.5 5]和[7 7.5]之间的点时,KNN和SVM的分类结果
观察分类结果可以看到,因为训练样本的x坐标只在某一区间,选取的支持向量使得分类面几乎与y轴平行。如果能使得分类方法“看到”两类数据(包括训练样本和测试样本)的分布,那是否就能得到一个较好的分类面了呢?
转导支持向量机
当训练数据和测试数据在训练模型时都可被使用时,如何才能使分类算法更加有效呢?形式化地说明,在给定训练数据
和测试数据
的条件下,在线性函数集y=(w⋅x)+by=(w⋅x)+b中找到一个函数,它在测试集上最小化错误数。在数据是可分的情况下,可以证明通过提供测试数据的一个分类结果
使得训练数据和测试数据
可以被最优超平面以最大间隔分开。也就是说我们的目标是找到最优超平面
使得12∥w∥212∥w∥2最小,且满足
当数据不可分时,在不等式中加入松驰变量。即在满足
的情况下,使得12∥w∥2+C∑li=1ξi+C∗∑kj=1ξj12∥w∥2+C∑i=1lξi+C∗∑j=1kξj最小。如下图所示。
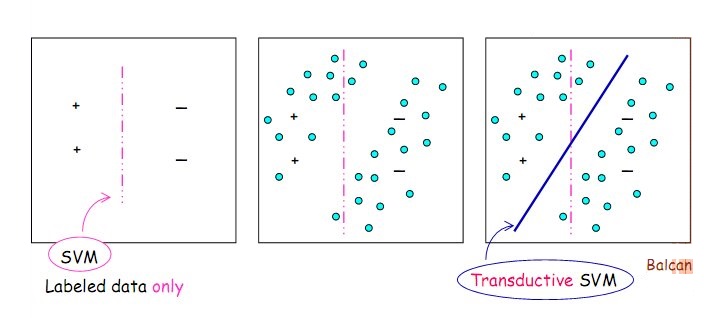
图6:标注数据以“+”和“-”标记,以青色填充的圆圈表示未标注数据。红色虚线代表分类面,左边和中间的分类面由SVM产生,右边的分类面由TSVM产生。 求解上述问题,实际上是针对固定的y∗1,…,y∗ky1∗,…,yk∗找出最优超平面的对偶表达:
为此必须使得泛函
在满足约束
的条件下达到它的最小值。一般而言,这一最小最大问题的精确解需要搜索测试集上所有的2k2k种分类结果。对于少量的测试样本(比如3~7),这一过程是可以完成的。但对于大量的测试样本,可以使用各种启发式过程,例如先通过聚类测试数据将测试数据暂分类,再应用SVM划分各类的分类面。如下图所示。
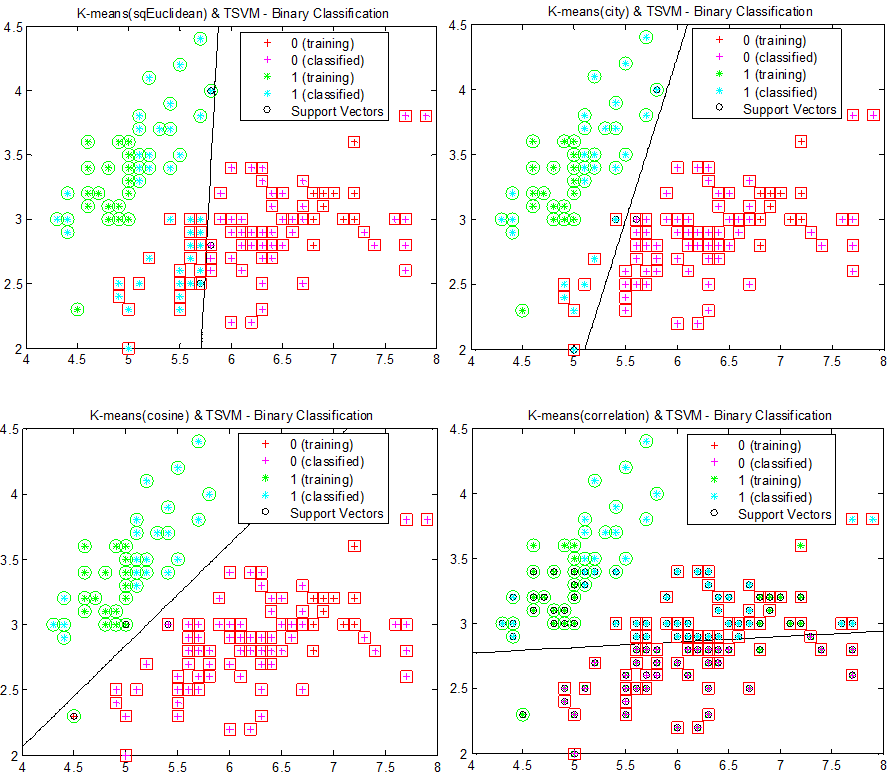
图7:首先对图5的数据进行K-means聚类,接着对两个类使用SVM进行划分分类面。为了比对不同距离对分类的影响,从左至右,从上至下,使用欧几里得距离、街区距离、余弦距离和相关距离(1-相关系数,公式见下)进行K-means聚类。圆形和正方形表示正确的分类。
设数据点x有n个特征,即n维,则任意两个数据点xsxs,xtxt的相关距离dstdst为
图中先对数据点进行聚类,再对聚成的两类做SVM分类。显然这一做法对聚类得到的类簇很敏感。使用余弦距离时,分类效果最好,这其中很大一部分原因就在于使用余弦距离进行K-means聚类后,两类已经被很好地分开了,再使用SVM显然能达到更好地结果。为了降低聚类对之后分类的影响,可以在类簇中随机抽取某些样本作为训练样本,结果如下图所示:
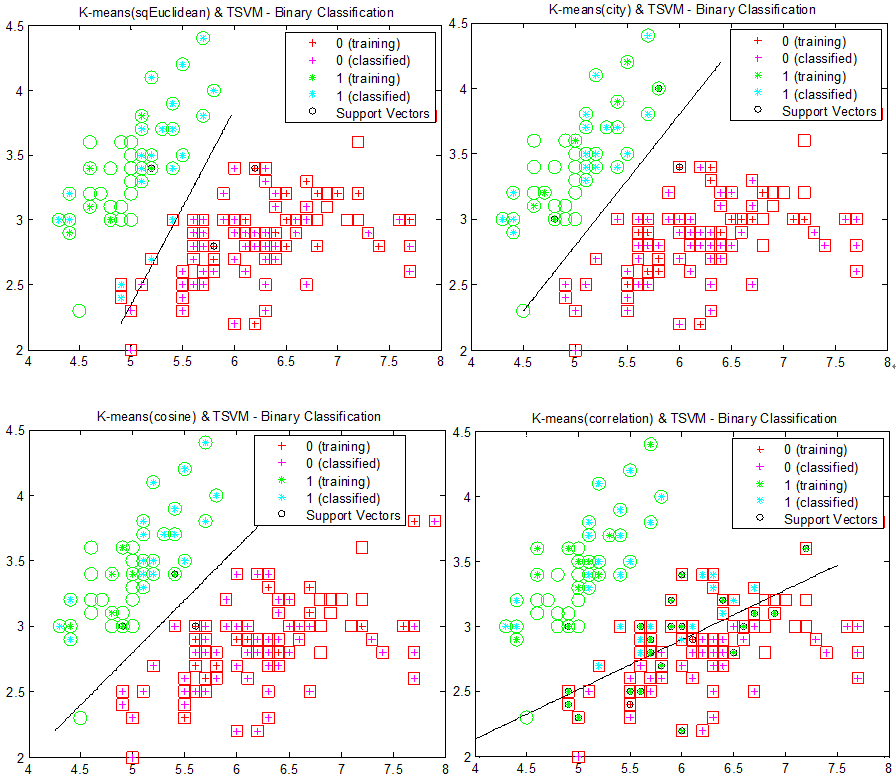
图8:首先对图5的数据进行K-means聚类,以0.2的概率随机抽取聚类中样本作为训练样本,接着对两个类使用SVM进行划分分类面。从左至右,从上至下,使用欧几里得距离、街区距离、余弦距离和相关距离(1-相关系数)进行K-means聚类。圆形和正方形表示正确的分类。
由于训练样本是从聚类样本中随机抽取得到的,原训练样本可能与测试样本相重叠,所以有些圆形和正方形中是中空的。图中所示的结果是分类得到的较好结果。各种距离对应的分类结果较之前相互接近,但付出的代价就是概率。好的分类结果并不会总是出现,甚至会很罕见。可改进的方法还有很多,例如随机抽取时增加原训练样本的比重,缩小测试样本的比重等。这里就不再赘述。
小结
区别于归纳推理(Inductive Inference)从特殊到一般,再从一般到特殊的学习方式,转导推理(Tranductive Inference)是一种从特殊到特殊的统计学习(或分类)方法。在预测样本的类别时,转导推理试图通过局部的标注训练样本进行判断,这与归纳推理先从训练样本中归纳得到一般模型有着很大差异。特别是当训练样本的数量不足以归纳得到全局一般模型时,转导推理能够利用未标注样本补充标注样本的不足。然而转导推理还有很多问题亟待解决,例如KNN每次预测都要遍历所有测试样本,TSVM的精确解如何更好地近似等。
参考文献
- Transduction (machine learning)[EB/OL]. [2012-5-7].http://en.wikipedia.org/wiki/Transduction_(machine_learning).
- Gammerman A, Vovk V, Vapnik V. Learning by transduction[C]//Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence. Morgan Kaufmann Publishers Inc., 1998: 148-155.
- Chapelle O, Schölkopf B, Zien A. Semi-supervised learning[M]. Cambridge: MIT press, 2006. (美)VladimirN.Vapnik著. 统计学习理论[M]. 许建华,张学工译. 北京: 电子工业出版社, 2004
【机器学习】转导推理——Transductive Learning的更多相关文章
- 转导推理——Transductive Learning
在统计学习中,转导推理(Transductive Inference)是一种通过观察特定的训练样本,进而预测特定的测试样本的方法.另一方面,归纳推理(Induction Inference)先从训练样 ...
- 归纳学习(Inductive Learning),直推学习(Transductive Learning),困难负样本(Hard Negative)
归纳学习(Inductive Learning): 顾名思义,就是从已有训练数据中归纳出模式来,应用于新的测试数据和任务.我们常用的机器学习模式就是归纳学习. 直推学习(Transductive Le ...
- 机器学习基石 1 The Learning Problem
机器学习基石 1 The Learning Problem Introduction 什么是机器学习 机器学习是计算机通过数据和计算获得一定技巧的过程. 为什么需要机器学习 1 人无法获取数据或者数据 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集
机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集 关键字:FPgrowth.频繁项集.条件FP树.非监督学习作者:米 ...
- 机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析
机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析 关键字:Apriori.关联规则挖掘.频繁项集作者:米仓山下时间:2018 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
随机推荐
- PHP回顾(4)文件相关函数
touch() 创建文件 (修改时间,不存在时创建) copy() 复制文件,复制过程中可以修改文件名 rename() 重命名 或 移动文件 ...
- SuperSocket框架的系列博文
官方文档 http://docs.supersocket.net/v1-6/zh-CN 对于我等小白,此系列博文,受益匪浅,慢慢看 https://www.cnblogs.com/fly-bird/c ...
- 错误/异常:org.hibernate.MappingException: Unknown entity: com.shore.entity.Student 的解决方法
1.错误/异常视图 错误/异常描述:Hibernate配置文件 映射异常,不明实体类Student(org.hibernate.MappingException: Unknown entity: co ...
- luoguP1739 表达式括号匹配 x
P1739 表达式括号匹配 题目描述 假设一个表达式有英文字母(小写).运算符(+,—,*,/)和左右小(圆)括号构成,以“@”作为表达式的结束符.请编写一个程序检查表达式中的左右圆括号是否匹配,若匹 ...
- python 多线程实现循环打印 abc
python 多线程实现循环打印 abc 好久没写过python了, 想自己实践一下把 非阻塞版 import threading import time def print_a(): global ...
- HDU 6154 CaoHaha's staff(2017中国大学生程序设计竞赛 - 网络选拔赛)
题目代号:HDU 6154 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6154 CaoHaha's staff Time Limit: 2000/1 ...
- python-无联网情况下安装skt-learn
请从上到下安装 numpy importlib pytz python-dateutil pandas scipy pasty statemodels backports.functools_lru_ ...
- python-numpy-1
mean() mean() 函数定义: numpy.``mean(a, axis=None, dtype=None, out=None, keepdims=<class numpy._globa ...
- $\LaTeX$数学公式大全7
$7\ Arrow\ Symbols$ $\leftarrow$ \leftarrow $\Leftarrow$ \Leftarrow $\rightarrow$ \rightarrow $\Righ ...
- C++入门经典-例7.10-运算符的重载,重载加号运算符
1:曾经介绍过string类型的数据,它是C++标准模版库提供的一个类.string类支持使用加号“+”连接两个string对象.但是使用两个string对象相减确实非法的,其中的原理就是C++所提供 ...