贝叶斯线性回归(Bayesian Linear Regression)
贝叶斯线性回归(Bayesian Linear Regression)
标签(空格分隔): 监督学习
@ author : duanxxnj@163.com
@ time : 2015-06-19
原文地址
本文的研究顺序是:
关于参数估计
在很多的机器学习或数据挖掘的问题中,我们所面对的只有数据,但数据中潜在的概率密度函数是不知道的,其概率密度分布需要我们从数据中估计出来。想要确定数据对应的概率密度分布,就需要确定两个东西:概率密度函数的形式 和 概率密度函数的参数。
有时可能知道的是概率密度函数的形式(高斯、瑞利等等),但是不知道具体的参数,例如均值或者方差;还有的时候可能不知道概率密度的类型,但是知道一些估计的参数,比如均值和方差。
关于上面提到的需要确定的两个东西:概率密度函数的形式和参数,至少在机器学习的教课书上,我所看到的情况都是:给了一堆数据,然后假设其概率密度函数的形式为 高斯分布 ,或者是混合高斯分布,那么,剩下的事情就是对高斯分布的参数,μμ 和 σ2σ2 进行估计。所以,参数估计,便成了极其最重要的问题。
其实,常用的参数估计方法有:极大似然估计、最大后验估计、贝叶斯估计、最大熵估计、混合模型估计。他们之间是有递进关系的,想要理解后一个参数估计方法,最好对前一个参数估计有足够的理解。
要想清晰的说明贝叶斯线性回归,或者叫做贝叶斯参数估计,就必须对极大似然估计、最大后验估计做详细的说明,他们之间是有递进的关系的。
极大似然估计
在之前《多项式回归》的文章中,用最后一小节是线性回归的概率解释,其中就说明了以平方误差维损失函数的最小二乘法和极大似然估计的等价性,在这个基础上,本文更为详细的讨论极大似然估计。
这里先以一个分类问题来说明一般参数估计面对的数据形式。考虑一个MM类的问题,特征向量服从p(x|ωi),i=1,2...,Mp(x|ωi),i=1,2...,M 分布。这是现实情况中最常见的一种数据存在形式,数据集合XX是由MM个类别的数据子集Xm,m=1,2...,MXm,m=1,2...,M 组成的,第mm类别的数据子集XmXm 对应的概率密度函数是p(x|ωm)p(x|ωm)。
前面已经介绍过了,想要确定数据的概率分布,需要知道概率密度函数的 形式 和 参数,这里首先做一个基本假设:概率分布的形式已知,比如假设每个类别的数据都满足高斯分布,那么,似然函数就可以以参数 θi θi 的形式表示,如果是高斯分布,则参数为μiμi和σ2iσi2,即θi=(μi,σ2i)θi=(μi,σi2)。
为了强调概率分布p(x|ωi)p(x|ωi)和 θiθi 有关,将对应的概率密度函数记为p(x|ωi;θi)p(x|ωi;θi),这种记法属于频率概率学派的记法。这里的极大似然估计对应于一个类条件概率密度函数。
在概率论中一直有两大学派,分别是频率学派和贝叶斯学派。简单点说,频率学派认为,概率是频率的极限,比如投硬币,当实验次数足够大时,正面朝上的频率可以认为是这枚硬币正面朝上的概率,这个是频率学派。但是,如果要预测一些未发生过的事情,比如,北极的冰山在2050年完全融化的概率,由于这个事情完全没有发生过,所以无法用频率来代替概率表示,只能研究过去几十年,北极冰山融化的速率,并将其作为先验条件,来预测北极的冰山在2050年完全融化的概率,这就是概率的贝叶斯学派。上面的问题,如果用贝叶斯学派的记法的话,是:p(x|ωi,θi)p(x|ωi,θi)。这两个学派适用的情况不太一样,但是,在我目前所用到的概率论的知识中,貌似这两个学派并没有什么太大的区别,只是记法略有不同,稍微注意下即可。
从上面的描述中可以知道,利用每一个类XiXi中已知的特征向量集合,可以估计出其对应的参数θiθi。进一步假设每一类中的数据不影响其他类别数据的参数估计,那么上面的MM个类别的参数估计就可以用下面这个统一的模型,独立的解决:
设x1,x2,...,xNx1,x2,...,xN 是从概率密度函数p(x;θ)p(x;θ)中随机抽取的样本,那么就可以得到联合概率密度函数 p(X;θ)p(X;θ), 其中X={x1,x2,...,xN}X={x1,x2,...,xN} 是样本集合。假设不同的样本之间具有统计独立性,那么:
注意:这里的p(xk;θ)p(xk;θ) 本来的写法是 p(x|ωi;θi)p(x|ωi;θi) , 是一个类条件概率密度函数,只是因为这里是一个统一的模型,所以可以将wiwi 省略。
需要重申一下,想要得到上面这个公式,是做了几个基本的假设的,第一:假设MM个类别的数据子集的概率密度函数形式一样,只是参数的取值不同;第二:假设类别ii中的数据和类别jj中的数据是相互独立抽样的,即类别jj的参数仅仅根据类别jj的数据就可以估计出来,类别ii的数据并不能影响类别jj的参数估计,反之亦然;第三:每个类别内的样本之间具有统计独立性,即每个类别内的样本之间是独立同分布 (iidiid) 的。
此时,就可以使用最大似然估计(Maximum Likelihood,ML)来估计参数θθ了:
为了得到最大值,θ^MLθ^ML必须满足的必要条件是,似然函数对θθ的梯度必须为0,即:
一般我们取其对数形式:
需要注意:极大似然估计对应于似然函数的峰值
极大似然估计有两个非常重要的性质:渐进无偏 和 渐进一致性,有了这两个性质,使得极大似然估计的成为了非常简单而且实用的参数估计方法。这里假设θ0θ0是密度函数p(x;θ)p(x;θ)中未知参数的准确值。
渐进无偏
极大似然估计是渐进无偏的,即:
也就是说,这里认为估计值 θ^MLθ^ML 本身是一个随机变量(因为不同的样本集合XX会得到不同的 θ^MLθ^ML),那么其均值就是未知参数的真实值,这就是渐进无偏。
渐进一致
极大似然估计是渐进一致的,即:
这个公式还可以表示为:
对于一个估计器而言,一致性是非常重要的,因为存在满足无偏性,但是不满足一致性的情况,比如,θ^MLθ^ML在 θ0θ0周围震荡。如果不满足一致性,那么就会出现很大的方差。
注意:以上两个性质,都是在渐进的前提下(N→∞N→∞)才能讨论的,即只有NN足够大时,上面两个性质才能成立
最大后验估计
在最大似然估计(MAP)中,将θθ看做是未知的参数,说的通俗一点,最大似然估计是θθ的函数,其求解过程就是找到使得最大似然函数最大的那个参数θθ。
从最大后验估计开始,将参数θθ 看成一个随机变量,并在已知样本集{x1,x2,...,xN}{x1,x2,...,xN} 的条件下,估计参数θθ。
这里一定要注意,在最大似然估计中,参数θθ是一个定值,只是这个值未知,最大似然函数是θθ的函数,这里θθ是没有概率意义的。但是,在最大后验估计中,θθ是有概率意义的,θθ有自己的分布,而这个分布函数,需要通过已有的样本集合XX得到,即最大后验估计需要计算的是 p(θ|X)p(θ|X)
根据贝叶斯理论:
这就是参数θθ关于已有数据集合XX的后验概率,要使得这个后验概率最大,和极大似然估计一样,这里需要对后验概率函数求导。由于分子中的p(X)p(X)相对于θθ是独立的,随意可以直接忽略掉p(X)p(X)。
为了得到参数θθ,和ML一样,需要对p(θ|X)p(θ|X)求梯度,并使其等于0:
注意:这里p(X|θ)p(X|θ)和极大似然估计中的似然函数p(X;θ)p(X;θ)是一样的,只是记法不一样。MAP和ML的区别是:MAP是在ML的基础上加上了p(θ)p(θ)
这里需要说明,虽然从公式上来看 MAP=ML∗p(θ)MAP=ML∗p(θ),但是这两种算法有本质的区别,ML将θθ视为一个确定未知的值,而MAP则将θθ视为一个随机变量。
在MAP中,p(θ)p(θ)称为θθ的先验,假设其服从均匀分布,即对于所有θθ取值,p(θ)p(θ)都是同一个常量,则MAP和ML会得到相同的结果。当然了,如果p(θ)p(θ)的方差非常的小,也就是说,p(θ)p(θ)是近似均匀分布的话,MAP和ML的结果自然也会非常的相似。
贝叶斯估计
注意:以下所有的概率分布表述方式均为贝叶斯学派的表述方式。
贝叶斯估计核心问题
为了防止标号混淆,这里定义已有的样本集合为DD,而不是之前的XX。样本集合DD中的样本都是从一个 固定但是未知 的概率密度函数p(x)p(x)中独立抽取出来的,要求根据这些样本估计xx的概率分布,记为p(x|D)p(x|D),并且使得p(x|D)p(x|D)尽量的接近p(x)p(x),这就是贝叶斯估计的核心问题。
贝叶斯估计第一个重要元素
虽然p(x)p(x)是未知的,但是前面提到过,一个密度分布的两个要素为:形式和参数,我们可以假设p(x)p(x)的形式已知,但是参数θθ的取值未知。这里就有了贝叶斯估计的第一个重要元素 p(x|θ)p(x|θ),这是一个条件概率密度函数,准确的说,是一个类条件概率密度函数(具体原因参见本文前面关于极大似然估计的说明)。强调一下:p(x|θ)p(x|θ)的形式是已知的,只是参数θθ的取值未知。由于这里的xx可以看成一个测试样本,所以这个条件密度函数,从本质上讲,是θθ 在点 xx 处的似然估计。
贝叶斯估计第二个重要元素
由于参数θθ的取值未知,且,我们将θθ看成一个随机变量,那么,在观察到具体的训练样本之前,关于θθ的全部知识,可以用一个先验概率密度函数p(θ)p(θ)来表示,对于训练样本的观察,使得我们能够把这个先验概率密度转化成为后验概率密度函数p(θ|D)p(θ|D),根据后验概率密度相关的论述知道,我们希望p(θ|D)p(θ|D)在θθ的真实值附近有非常显著的尖峰。这里的这个后验概率密度,就是贝叶斯估计的第二个主要元素。
现在,将贝叶斯估计核心问题p(x|D)p(x|D),和贝叶斯估计的两个重要元素:p(x|θ)p(x|θ)、p(θ|D)p(θ|D)联系起来:
上面式子中,xx是测试样本,DD是训练集,xx和DD的选取是独立进行的,因此,p(x|θ,D)p(x|θ,D)可以写成p(x|θ)p(x|θ)。所以,贝叶斯估计的核心问题就是下面这个公式:
下面这句话一定要理解:这里p(x|θ)p(x|θ)是θθ关于测试样本xx这一个点的似然估计,而p(θ|D)p(θ|D)则是θθ在已有样本集合上的后验概率。这就是为什么本文一开始并没有直接讲贝叶斯估计,而是先说明极大似然估计和最大后验估计的原因。其中,后验概率p(θ|D)p(θ|D)为:
上面这个式子就是贝叶斯估计最核心的公式,它把类条件概率密度p(x|D)p(x|D) (这里一定要理解为什么是类条件概率密度,其实这个的准确写法可以是p(x|Dm)p(x|Dm),或者 p(x|wm,Dm)p(x|wm,Dm),具体原因参见本文前面关于极大似然估计的部分) 和未知参数向量θθ的后验概率密度p(θ|D)p(θ|D)联系在了一起。如果后延概率密度p(θ|D)p(θ|D)在某一个值θ^θ^附近形成显著的尖峰,那么就有p(x|D)≈p(x|θ^)p(x|D)≈p(x|θ^),就是说,可以用估计值 θ^θ^近似代替真实值所得的结果。
贝叶斯估计的增量学习
为了明确的表示样本集合DD中有nn个样本,这里采用记号:Dn={x1,x2,...,xn}Dn={x1,x2,...,xn}。根据前一个公式,在n>1n>1的情况下有:
可以很容易得到:
当没有观测样本时,定义p(θ|D0)=p(θ)p(θ|D0)=p(θ),为参数θθ的初始估计。然后让样本集合依次进入上述公式,就可以得到一系列的概率密度函数:p(θ|D0)p(θ|D0)、p(θ|D1)p(θ|D1)、p(θ|D2)p(θ|D2)、…、p(θ|Dn)p(θ|Dn),这一过程称为参数估计贝叶斯递归法,也叫贝叶斯估计的增量学习。这是一个在线学习算法,它和随机梯度下降法有很多相似之处。
贝叶斯线性回归
根据之前的文章《线性回归》、《多项式回归》中关于极大似然估计的说明,以及本文前面关于极大似然估计的论述,可以很容易知道,如果要将极大似然估计应用到线性回归模型中,模型的复杂度会被两个因素所控制:基函数的数目和样本的数目。尽管为对数极大似然估计加上一个正则项(或者是参数的先验分布),在一定程度上可以限制模型的复杂度,防止过拟合,但基函数的选择对模型的性能仍然起着决定性的作用。
上面说了那么大一段,就是想说明一个问题:由于极大似然估计总是会使得模型过于的复杂以至于产生过拟合的现象,所以单纯的适用极大似然估计并不是特别的有效。
当然,交叉验证是一种有效的限制模型复杂度,防止过拟合的方法,但是交叉验证需要将数据分为训练集合测试集,对数据样本的浪费也是非常的严重的。
基于上面的讨论,这里就可以引出本文的核心内容:贝叶斯线性回归。贝叶斯线性回归不仅可以解决极大似然估计中存在的过拟合的问题,而且,它对数据样本的利用率是100%,仅仅使用训练样本就可以有效而准确的确定模型的复杂度。
这里面对的模型是线性回归模型,其详细的介绍可以参见前面的文章《线性回归》,线性回归模型是一组输入变量xx的基函数的线性组合,在数学上其形式如下:
这里ϕj(x)ϕj(x)就是前面提到的基函数,总共的基函数的数目为MM个,如果定义ϕ0(x)=1ϕ0(x)=1的话,那个上面的式子就可以简单的表示为:
则线性模型的概率表示如下:
假设参数ww满足高斯分布,这是一个先验分布:
一般来说,我们称p(w)p(w)为共轭先验(conjugate prior)。这里tt是xx对应的目标输出,β−1β−1和α−1α−1分别对应于样本集合和ww的高斯分布的方差,ww是参数,
那么,线性模型的对数后验概率函数:
这里TT是数据样本的目标值向量,T={t1,t2,...,tn}T={t1,t2,...,tn},const是和参数ww无关的量。关于这个式子的具体推导,可参见前面的文章《多项式回归》。
贝叶斯线性回归的学习过程
根据前面关于贝叶斯估计的增量学习可以很容易得到下面这个式子,这个就是贝叶斯学习过程:在前一个训练集合Dn−1Dn−1的后验概率p(θ|Dn−1)p(θ|Dn−1)上,乘以新的测试样本点xnxn的似然估计,得到新的集合DnDn的后验概率p(θ|Dn)p(θ|Dn),这样,相当于p(θ|Dn−1)p(θ|Dn−1)成为了p(θ|Dn)p(θ|Dn)的先验概率分布:
有了上面的基础知识,这里就着重的讲下面这幅图,这个图是从RMPL第155页截取下来的,这幅图清晰的描述了贝叶斯线性回归的学习过程,下面结合这幅图,详细的说明一下贝叶斯学习过程。
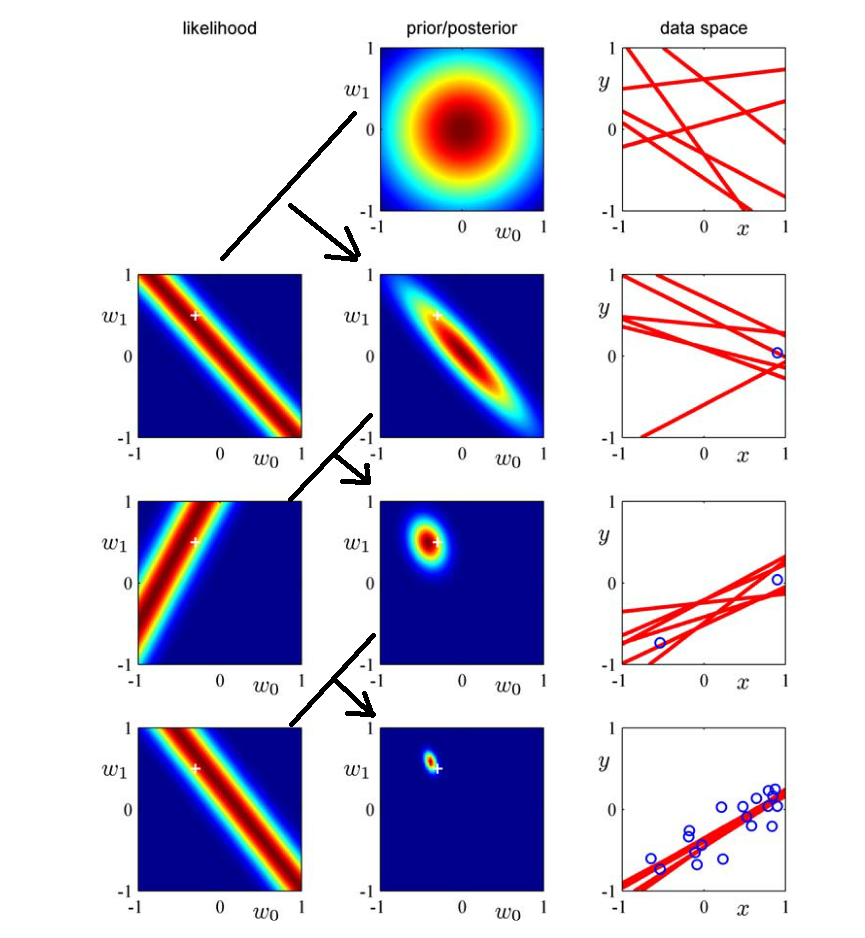
首先,说一下这里的模型:
第一行:
第一行是初始状态,此时只有关于ww的先验信息,即:p(θ|D0)=p(θ)=N(w|0,α−1I)p(θ|D0)=p(θ)=N(w|0,α−1I)。先看中间这幅图,这幅图是关于ww的先验分布,由于我们假设ww初始为高斯分布N(w|0,α−1I)N(w|0,α−1I),故其图形是以(0,0)(0,0)为中心的圆组成的。由于此时还没有样本点进入,所以没有关于样本的似然估计,故第一行中左边likelihood没有图。第一行右边data space的那幅图显示的是从第二幅图prior/posterior中随机抽取一些点(w0,w1)(w0,w1),并以(w0,w1)(w0,w1)为参数,画出来的直线,此时这些直线是随机的。
第二行:
此时有了第一个样本点x1x1,那么根据x1x1就可以得到第二行中,关于x1x1的似然估计,由于y=w0+w1xy=w0+w1x,似然估计的结果其实是这个式子的对偶式,即w1=1xy−1xw0w1=1xy−1xw0。从第二行的最右边data space中的图中可以估计出,第一个样本点的坐标大概为:(0.9,0.1)(0.9,0.1),所以其第一幅图中,似然估计的中心线的方程为:
近似为左边那幅图的画法。由于第二行的先验分布是第一行的后验分布,也就是第一行的中间那幅图。则,第二行的后验分布的求法就是:将第二行的第左边那幅图和第一行的中间那幅图相乘,就可以得到第二行中间那幅图。第二行最右边那幅图就是从第二行中间那幅图中随机抽取一些点(w0,w1)(w0,w1),并以(w0,w1)(w0,w1)为参数,画出来的直线。
第三行之后,就可以一次类推了。
上面就是贝叶斯学习过程的完整描述。
贝叶斯回归的优缺点
优点:
1. 贝叶斯回归对数据有自适应能力,可以重复的利用实验数据,并防止过拟合
2. 贝叶斯回归可以在估计过程中引入正则项
缺点:
1. 贝叶斯回归的学习过程开销太大
贝叶斯脊回归(Bayesian Ridge Regression)
前面已经证明过了,如果贝叶斯线性回归的先验分布为
那么,其最终的后验分布公式为:
这个相当于脊回归,所以将这种特殊情况称为贝叶斯脊回归,它拥有脊回归的所有特性,具体可以参见前面的文章《脊回归》。
下面这份代码提供了贝叶斯回归的用法,以及其和最小二乘法的比较。
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
author : duanxxnj@163.com
time : 2016-06-21-09-21
贝叶斯脊回归
这里在一个自己生成的数据集合上测试贝叶斯脊回归
贝叶斯脊回归和最小二乘法(OLS)得到的线性模型的参数是有一定的差别的
相对于最小二乘法(OLS)二样,贝叶斯脊回归得到的参数比较接近于0
贝叶斯脊回归的先验分布是参数向量的高斯分布
"""
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
import time
from sklearn.linear_model import BayesianRidge, LinearRegression
###############################################################################
# 随机函数的种子
np.random.seed(int(time.time()) % 100)
# 样本数目为100,特征数目也是100
n_samples, n_features = 100, 100
# 生成高斯分布
X = np.random.randn(n_samples, n_features)
# 首先使用alpha为4的先验分布.
alpha_ = 4.
w = np.zeros(n_features)
# 随机提取10个特征出来作为样本特征
relevant_features = np.random.randint(0, n_features, 10)
# 基于先验分布,产生特征对应的初始权值
for i in relevant_features:
w[i] = stats.norm.rvs(loc=0, scale=1. / np.sqrt(alpha_))
# 产生alpha为50的噪声
alpha_ = 50.
noise = stats.norm.rvs(loc=0, scale=1. / np.sqrt(alpha_), size=n_samples)
# 产生目标数据
y = np.dot(X, w) + noise
###############################################################################
# 使用贝叶斯脊回归拟合数据
clf = BayesianRidge(compute_score=True)
clf.fit(X, y)
# 使用最小二乘法拟合数据
ols = LinearRegression()
ols.fit(X, y)
###############################################################################
# 作图比较两个方法的结果
plt.figure(figsize=(6, 5))
plt.title("Weights of the model")
plt.plot(clf.coef_, 'b-', label="Bayesian Ridge estimate")
plt.plot(w, 'g-', label="Ground truth")
plt.plot(ols.coef_, 'r--', label="OLS estimate")
plt.xlabel("Features")
plt.ylabel("Values of the weights")
plt.legend(loc="best", prop=dict(size=12))
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
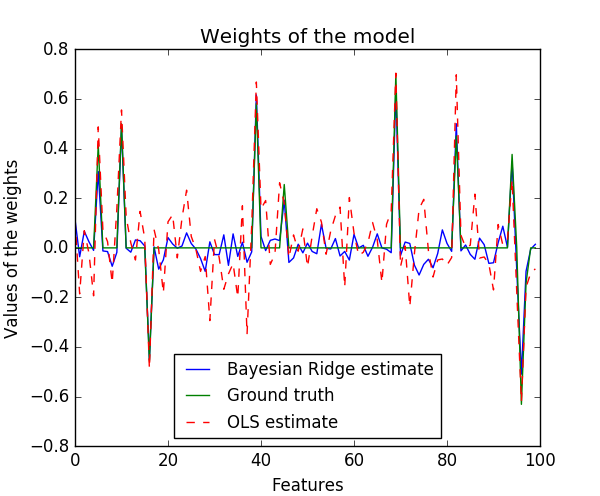
其运行结果为:
贝叶斯脊回归参数:
[ -7.16688614e-02 3.73638195e-02 -4.04171217e-02 7.28338457e-03
...
2.60774221e-01 4.26079127e-02 1.01660304e-02 6.79853349e-02]
最小二乘法参数:
[-1.77270023 -0.38832798 0.58907738 -1.61514115 0.58202424 0.09483505
...
-1.37056305 2.81533169 0.02429617 0.90196961]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以很容易的看出,相对于最小二乘法(OLS)二样,贝叶斯脊回归得到的参数比较接近于0
贝叶斯线性回归(Bayesian Linear Regression)的更多相关文章
- 机器学习理论基础学习17---贝叶斯线性回归(Bayesian Linear Regression)
本文顺序 一.回忆线性回归 线性回归用最小二乘法,转换为极大似然估计求解参数W,但这很容易导致过拟合,由此引入了带正则化的最小二乘法(可证明等价于最大后验概率) 二.什么是贝叶斯回归? 基于上面的讨论 ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- [ML] Bayesian Linear Regression
热身预览 1.1.10. Bayesian Regression 1.1.10.1. Bayesian Ridge Regression 1.1.10.2. Automatic Relevance D ...
- (main)贝叶斯统计 | 贝叶斯定理 | 贝叶斯推断 | 贝叶斯线性回归 | Bayes' Theorem
2019年08月31日更新 看了一篇发在NM上的文章才又明白了贝叶斯方法的重要性和普适性,结合目前最火的DL,会有意想不到的结果. 目前一些最直觉性的理解: 概率的核心就是可能性空间一定,三体世界不会 ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
- 贝叶斯优化 Bayesian Optimization
贝叶斯优化 Bayesian Optimization 2018年07月02日 22:28:06 余生最年轻 阅读数 4821更多 分类专栏: 机器学习 版权声明:本文为博主原创文章,遵循CC 4 ...
- 机器学习之多变量线性回归(Linear Regression with multiple variables)
1. Multiple features(多维特征) 在机器学习之单变量线性回归(Linear Regression with One Variable)我们提到过的线性回归中,我们只有一个单一特征量 ...
- 从零单排入门机器学习:线性回归(linear regression)实践篇
线性回归(linear regression)实践篇 之前一段时间在coursera看了Andrew ng的机器学习的课程,感觉还不错,算是入门了. 这次打算以该课程的作业为主线,对机器学习基本知识做 ...
随机推荐
- leetcode-hard-array-179 Largest Number-NO
mycode 写的很复杂,还报错... 参考: class Solution: # @param {integer[]} nums # @return {string} def largestNum ...
- php连接数据库的两种方式- 面向过程 面向对象
php连接数据库的两种方式- 面向过程 面向对象 一.面向对象1. 链接数据库$conn = @new mysqli("127.0.0.1","root", ...
- eclips注释的快捷键
一 . 注释java或者c++ 代码的快捷键 CTRL + / 二. 注释xml格式的快捷键 注释: CTRL + SHIFT + / 取消注释: CTRL + SHIFT + \
- 小D课堂 - 新版本微服务springcloud+Docker教程_6-06 zuul微服务网关集群搭建
笔记 6.Zuul微服务网关集群搭建 简介:微服务网关Zull集群搭建 1.nginx+lvs+keepalive https://www.cnblogs.com/liuyisai/ ...
- Linux下的C的开发之GCC的初级使用
<span style="font-family: Arial, Helvetica, sans-serif; "><span style="white ...
- Java之Apache Tomcat教程[归档]
前言 笔记归档类博文. 本博文地址:Java之Apache Tomcat教程[归档] 未经同意或授权便复制粘贴全文原文!!!!盗文实在可耻!!!贴一个臭不要脸的:易学教程↓↓↓ Step1:安装JDK ...
- React Native解决安卓图片被挤压
Bug如下图所示: iOS显示正常,而安卓出现图片被挤压上去. 最后的解决方法: 比如你的 图片 是 750 x 513 那么 你设置样式的时候 width 为 屏幕的宽 ,高度为 屏幕的 宽 / ( ...
- docker清理
# 删除退出的容器docker rm $(docker ps -qa --no-trunc --filter "status=exited") # 删除悬挂镜像docker rmi ...
- web代码审计题
@题名:code i春秋https://www.ichunqiu.com/battalion wp:https://www.ichunqiu.com/writeup/detail/4139
- Java学习笔记-网络编程
Java提供了网络编程,并且在实际中有着大量运用 网络编程 网络编程概述 网络模型 OSI参考模型 TCP/IP参考模型 网络通讯要素 IP地址 端口号 传输协议 网络参考模型 网络通讯要素 IP地址 ...