Hibernate学习笔记二
Hibernate持久化类的编写规则
Hibernate是持久层的ORM映射框架,专注于数据的持久化工作。所谓持久化,就是将内存中的数据永久存储到关系型数据库中。
持久化类
一个java类与数据库表建立了映射关系,那么这个类称为持久化类。可以简单的理解为持久化类就是一个java类有一个映射文件与数据库的表建立了关系。
持久化类的编写规则:
1、持久化类需要提供无参数的构造方法。因为在Hibernate的底层需要使用反射生成类的实例。
2、持久化类的属性需要私有,对私有的属性提供共有的get和set方法。因为在Hibernate底层会将查询到的数据进行封装。
3、持久化类的属性要尽量使用包装类的类型。因为包装类和基本类型的默认值不同,包装类的类型语义描述更清晰,而基本数据类型不容易描述。比如:double默认为0,Double默认为null。
4、持久化类要有一个唯一标识OID与表的主键对应。因为Hibernate中需要通过这个唯一标识OID区分在内存中是否是同一个持久化类。Hibernate是不允许在内存中出现两个OID相同的持久化对象的。
5、持久化类要尽量不要使用final进行修饰。因为Hibernate中有延迟加载的机制,这个机制中会产生代理对象,Hibernate产生代理对象使用的是字节码的增强技术完成的,其实就是产生了当前类的一个子类对象实现的。如果使用了final修饰持久化类。那么就不能产生子类。那么Hibernate的延迟加载策略就会失效。
Hibernate主键生成策略
主键的类型分为自然主键和代理主键
自然主键:把具体业务含义的字段作为主键,称为自然主键。比如在customer表中,如果把name字段作为主键,其前提条件必须是:每一个客户的姓名不允许为null,不允许重名,并且不允许修改客户姓名。尽管这也是可行的,但是不能满足不断变化的业务需求,一旦出现了允许客户端重名的业务需求,就必须修改数据模型,重新定义表的主键,这给数据库的维护增加了难度。
代理主键:把不具备业务含义的字段作为主键,称之为代理主键。显然更合理的方式是使用代理主键。
Hibernate的主键生成策略
increment:主键自增.由hibernate来维护.每次插入前会先查询表中id最大值.+1作为新主键值。用于long、short、int类型,由Hibernate自动以递增的方式生成唯一标识符,每次增量为1.只有当没有其它进程向同一张表中插入数据时才可以使用,不能再集群环境下使用。适用于代理主键。
identity:主键自增.由数据库来维护主键值.录入时不需要指定主键。采用底层数据库本身提供的主键生成标识符,条件是数据库支持自动增长数据类型。适用于代理主键。
hilo:高低位算法.主键自增.由hibernate来维护.开发时不使用.
sequence:Oracle中的主键生成策略.Hibernate根据底层数据库序列生成标识符。条件是数据库支持序列。适用于代理主键。
native:hilo+sequence+identity 自动三选一策略。根据底层数据库对自动生成表示符的能力来选择identity、squence、hilo三种生成器中的一种,适合跨数据库平台开发。适用于代理主键。
uuid:产生随机字符串作为主键. 主键类型必须为string 类型。Hibernate采用128位的UUID算法来生成标识符。该算法能够在网络环境中生成唯一的字符串标识符,其UUID被编码为一个长度为32位的石榴进制字符串,这种策略并不流行,因为字符串类型的主键比整数类型的主键占用更多的数据库空间。适用于代理主键。
assigned:hibernate不会管理主键值.由开发人员自己录入。有java程序负责生成标识符,如果不指定id元素的generator属性,则默认使用该主键生成策略,适用于自然主键。
<id name="cust_id" >
<!-- generator:主键生成策略 -->
<generator class="native"></generator>
</id>
Hibernate的持久化对象的三种状态
Hibernate为了更好的来管理持久化类,特将持久化类分成了三种状态。分别是瞬时态、持久态、脱管态。
瞬时态
也称临时态或者自由态,瞬时态的实例是由new命令创建、开辟内存空间的对象,不存在持久化标识OID(相当于主键值),尚未与Hibernate Session关联,在数据库中也没有记录,仅是一个信息携带的载体。
持久态
持久态的对象存在持久化标识(OID),加入到了Session缓存中,并且相关联的session没有关闭,在数据库中有对应的记录,每条记录只对应唯一的持久化对象,需要注意的是,持久对象是在事务还未提交前变成持久态的。
脱管态
脱管态也称离线态或者游离态,当某个持久化状态的实例与Session的关联被关闭时就变成了托管态。脱管态对象存在持久化标识OID,并且仍然与数据库中的数据存在关联,只是失去了与当前Session的关联,脱管状态对象发生改变时Hibernate不能检测到。
区分对象的三种状态
//三种状态特点
//save方法: 其实不能理解成保存.理解成将瞬时状态转换成持久状态的方法
//主键自增 : 执行save方法时,为了将对象转换为持久化状态.必须生成id值.所以需要执行insert语句生成.
//increment: 执行save方法,为了生成id.会执行查询id最大值的sql语句.
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
Customer c = new Customer(); // 没有id, 没有与session关联 => 瞬时状态
c.setCust_name("联想"); // 瞬时状态
session.save(c); // 持久化状态, 有id,有关联
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
以上代码中,Customer对象由new关键字创建,此时还未与Session进行关联,它的状态称为瞬时态;
在执行了session.save(c)之后,Customer对象纳入了Session的管理范围,这时的Customer对象变成了持久态对象,此时的Session的事务还未提交;此时仅仅生成ID,比如:如果主键策略为identity,执行插入操作才会生成ID,所以会生成insert语句,而如果主键策略为increment,则会生成select max(cust_id) from cst_customer语句,当提交事务的时候,才会生成insert语句。
//三种状态特点
// 持久化状态特点: 持久化状态对象的任何变化都会自动同步到数据库中.
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
Customer c = session.get(Customer.class, 1l);//持久化状态对象
c.setCust_name("微软公司");
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
以上代码即时没调用update方法,也会生成update语句。
状态转换
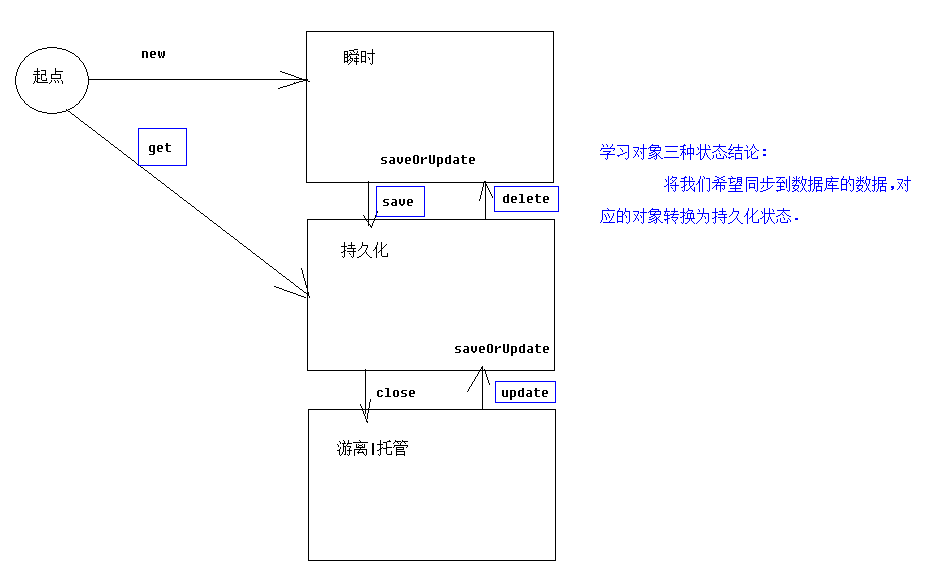

更多请参考这里
Hibernate的一级缓存
缓存的作用是降低应用程序直接读写永久性数据存储源的频率,从而提高应用的运行性能。缓存的数据时数据存储源中数据的拷贝。缓存的物理介质通常是内存。
Hibernate的缓存分为一级缓存和二级缓存,Hibernate的这两级缓存都位于持久化层,存储的都是数据库数据的备份。其中第一级缓存为Hibernate的内置缓存,不能被卸载。
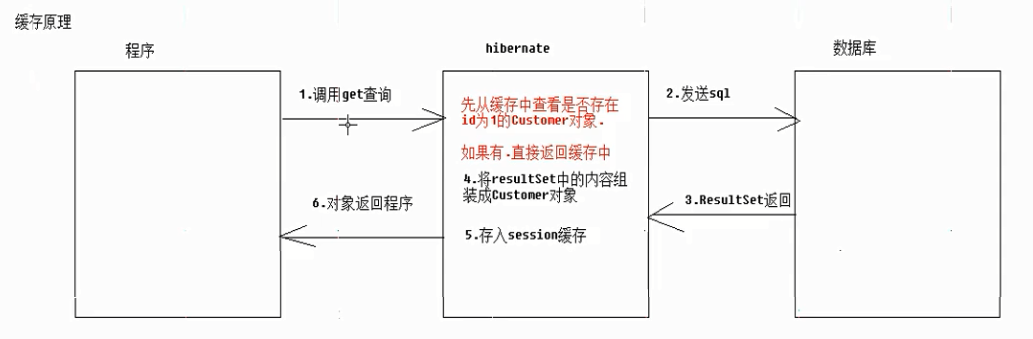
Hibernate的一级缓存就是指Session缓存,Session缓存是一块内存空间,用来存放管理的java对象,在使用Hibernate查询对象的时候,首先会使用对象属性的OID值在Hibernate的一级缓存中进行查找,如果找到,直接取出,不会查询数据库。Hibernate的一级缓存的作用就是减少对数据库的访问次数。
Hibernate的一级缓存特点:
1、当应用程序调用Session接口的save、update、saveOrUpdate时,如果Session缓存中没有相应的对象,Hibernate就会自动地把从数据库中查询到的相应对象信息加入到一级缓存中去。
2、当调用Session接口的load、get方法,一级Query接口的list、iterator方法时,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果缓存中没有要查询对象,再去数据库中查询对应对象,并添加到一级缓存中。
3、当调用Session的close方法时,Session缓存会被清空。
证明一级缓存存在
//证明一级缓存存在
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作 Customer c1 = session.get(Customer.class, 1l);
Customer c2 = session.get(Customer.class, 1l);
Customer c3 = session.get(Customer.class, 1l);
Customer c4 = session.get(Customer.class, 1l);
Customer c5 = session.get(Customer.class, 1l); System.out.println(c3==c5);//true
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
以上代码只生成1次sql语句。
提高效率手段1:提高查询效率
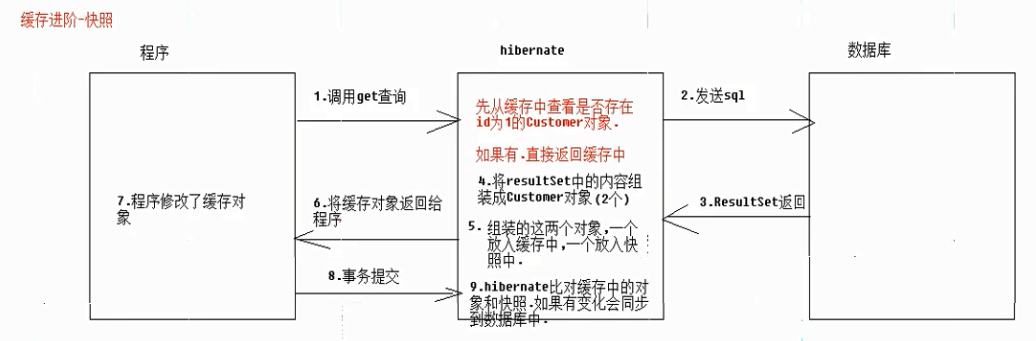
提高效率手段2:减少不必要的修改语句发送
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
Customer c1 = session.get(Customer.class, 1l);
c1.setCust_name("哈哈");
c1.setCust_name("谷歌公司");
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
以上代码当查询出来的cust_name为“谷歌公司”时,不会再生成update语句。
Session session = HibernateUtils.openSession();
Transaction transaction = session.beginTransaction();
Customer c1=new Customer();
c1.setCust_id(1l);
session.update(c1);
Customer c2=session.get(Customer.class,1l);
//session.save(customer);
transaction.commit();
session.close();
以上代码调用update方法,c1变成持久态,加入到缓存中,当执行get方法时,由于缓存中已存在id为1的实体,所以不会查询数据库,当事务提交时,快照中没有数据,所以比对不相同,会生成update语句。
Hibernate的事务控制
在Hibernate中,可以通过代码来操作管理事务,除了在代码中对事务开启,提交和回滚之外,还可以在Hibernate的配置文件中对事务进行配置。配置文件中,可以设置事务的隔离级别。
<!-- 指定hibernate操作数据库时的隔离级别
#hibernate.connection.isolation 1|2|4|8
0001 1 读未提交
0010 2 读已提交
0100 4 可重复读
1000 8 串行化
-->
<property name="hibernate.connection.isolation">4</property>
在项目中如何管理事务
业务开始之前打开事务,业务执行之后提交事务. 执行过程中出现异常.回滚事务.
在dao层操作数据库需要用到session对象.在service控制事务也是使用session对象完成. 我们要确保dao层和service层使用的使用同一个session对象。
在hibernate中,确保使用同一个session的问题,hibernate已经帮我们解决了. 我们开发人员只需要调用getCurrentSession()方法即可获得与当前线程绑定的session对象。
注意:
1、调用getCurrentSession方法必须配合主配置中的一段配置
<!-- 指定session与当前线程绑定 -->
<property name="hibernate.current_session_context_class">thread</property>
2、通过getCurrentSession方法获得的session对象.当事务提交时,session会自动关闭.不要手动调用close关闭.
比如:
Service对象
public void save(Customer c) {
Session session = HibernateUtils.getCurrentSession();
//打开事务
Transaction tx = session.beginTransaction();
//调用Dao保存客户
try {
customerDao .save(c);
} catch (Exception e) {
e.printStackTrace();
tx.rollback();
}
//关闭事务
tx.commit();
}
Dao层
public void save(Customer c) {
//1 获得session
Session session = HibernateUtils.getCurrentSession();
//3 执行保存
session.save(c);
}
hibernate中的批量查询
HQL查询-hibernate Query Language(多表查询,但不复杂时使用)
Hibernate独家查询语言,属于面向对象的查询语言。
1、基本查询:
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
//String hql = " from cn.itheima.domain.Customer ";
String hql = " from Customer "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//3> 根据查询对象获得查询结果
List<Customer> list = query.list(); // 返回list结果
//query.uniqueResult();//接收唯一的查询结果 System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
2、条件查询
?号占位符
//条件查询
//问号占位符
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer where cust_id = ? "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置参数
//query.setLong(0, 1l);
query.setParameter(0, 1l);
//3> 根据查询对象获得查询结果
Customer c = (Customer) query.uniqueResult(); System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
命名占位符
//条件查询
//命名占位符
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer where cust_id = :cust_id "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置参数
query.setParameter("cust_id", 1l);
//3> 根据查询对象获得查询结果
Customer c = (Customer) query.uniqueResult(); System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
3、分页查询
//分页查询
public void fun5(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1> 书写HQL语句
String hql = " from Customer "; // 查询所有Customer对象
//2> 根据HQL语句创建查询对象
Query query = session.createQuery(hql);
//设置分页信息 limit ?,?
query.setFirstResult(1);
query.setMaxResults(1);
//3> 根据查询对象获得查询结果
List<Customer> list = query.list(); System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
Criteria查询(单表条件查询)
Hibernate自创的无语句面向对象查询
1、基本查询
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//------------------------------------------- //查询所有的Customer对象
Criteria criteria = session.createCriteria(Customer.class); List<Customer> list = criteria.list(); System.out.println(list); //Customer c = (Customer) criteria.uniqueResult(); //-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
2、条件查询
//条件查询
//HQL语句中,不可能出现任何数据库相关的信息的
// > gt
// >= ge
// < lt
// <= le
// == eq
// != ne
// in in
// between and between
// like like
// is not null isNotNull
// is null isNull
// or or
// and and
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//添加查询参数 => 查询cust_id为1的Customer对象
criteria.add(Restrictions.eq("cust_id", 1l));
//执行查询获得结果
Customer c = (Customer) criteria.uniqueResult();
System.out.println(c);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
3、分页查询
//分页查询
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//设置分页信息 limit ?,?
criteria.setFirstResult(1);
criteria.setMaxResults(2);
//执行查询
List<Customer> list = criteria.list(); System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
4、设置查询总记录数
//查询总记录数
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//创建criteria查询对象
Criteria criteria = session.createCriteria(Customer.class);
//设置查询的聚合函数 => 总行数
criteria.setProjection(Projections.rowCount());
//执行查询
Long count = (Long) criteria.uniqueResult(); System.out.println(count);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
原生SQL查询(复杂的业务查询)
1、基本查询
返回数组List
//基本查询
public void fun1(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer"; //2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql); //3 调用方法查询结果
List<Object[]> list = query.list();
//query.uniqueResult(); for(Object[] objs : list){
System.out.println(Arrays.toString(objs));
} //-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
返回对象List
//基本查询
public void fun2(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer"; //2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class); //3 调用方法查询结果
List<Customer> list = query.list(); System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联 }
2、条件查询
//条件查询
public void fun3(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer where cust_id = ? "; //2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql); query.setParameter(0, 1l);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class); //3 调用方法查询结果
List<Customer> list = query.list(); System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
3、分页查询
//分页查询
public void fun4(){
//1 获得session
Session session = HibernateUtils.openSession();
//2 控制事务
Transaction tx = session.beginTransaction();
//3执行操作
//-------------------------------------------
//1 书写sql语句
String sql = "select * from cst_customer limit ?,? "; //2 创建sql查询对象
SQLQuery query = session.createSQLQuery(sql); query.setParameter(0, 0);
query.setParameter(1, 1);
//指定将结果集封装到哪个对象中
query.addEntity(Customer.class); //3 调用方法查询结果
List<Customer> list = query.list(); System.out.println(list);
//-------------------------------------------
//4提交事务.关闭资源
tx.commit();
session.close();// 游离|托管 状态, 有id , 没有关联
}
总结
一.hibernate中的实体创建规则
- 对象必须有oid.
- 对象中的属性,尽量使用包装类型
- 不使用final修饰类
- 提供get/set方法....
二.hibernate主键生成策略(7种)
- increment: 查询最大值.再加1
- identity: 主键自增.
- sequence:Oracle使用的
- hilo: hibernate自己实现自增算法
- native: 根据所选数据库三选一
- uuid: 随机字符串
- assigned: 自然主键.
三.对象的三种状态
- 瞬时状态:没有id,没有在session缓存中.
- 持久化状态:有id,再session缓存中。
- 托管|游离状态:有id,不在session缓存中.
持久化: 持久化状态的对象,会在事务提交时,自动同步到数据库中.我们使用hibernate的原则.就是将对象转换为持久化状态.
四.一级缓存
缓存: 为了提高效率.
一级缓存:为了提高效率.session对象中有一个可以存放对象的集合.
- 查询时: 第一次查询时.会将对象放入缓存.再次查询时,会返回缓存中的.不再查询数据库.
- 修改时: 会使用快照对比修改前和后对象的属性区别.只执行一次修改.
五.事务管理
1、如何配置数据库隔离级别
- 1 读未提交
- 2 读已提交
- 4 可重复读
- 8 串行化
2、指定session与当前线程绑定 hibernate.current_session_context_class thread
六.批量查询
- HQL 面向对象的语句查询
- Criteria 面向对象的无语句查询
- SQL 原生SQL
Hibernate学习笔记二的更多相关文章
- Hibernate学习笔记二:Hibernate缓存策略详解
一:为什么使用Hibernate缓存: Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序访问物理数据库的频次,从而提高应用程序的性能. 缓存内的数据是对物理数据源的复制,应用 ...
- Hibernate学习笔记二:常用映射配置
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6760895.html 一:单向一对一 常用唯一外键的方法来配置单向一对一关系. 1:实体关系 类A中有类B对象 ...
- Hibernate学习笔记(二)
2016/4/22 23:19:44 Hibernate学习笔记(二) 1.1 Hibernate的持久化类状态 1.1.1 Hibernate的持久化类状态 持久化:就是一个实体类与数据库表建立了映 ...
- JDBC学习笔记二
JDBC学习笔记二 4.execute()方法执行SQL语句 execute几乎可以执行任何SQL语句,当execute执行过SQL语句之后会返回一个布尔类型的值,代表是否返回了ResultSet对象 ...
- Hibernate学习笔记(一)
2016/4/18 19:58:58 Hibernate学习笔记(一) 1.Hibernate框架的概述: 就是一个持久层的ORM框架. ORM:对象关系映射.将Java中实体对象与关系型数据库中表建 ...
- Hibernate 学习笔记一
Hibernate 学习笔记一 今天学习了hibernate的一点入门知识,主要是配置domain对象和表的关系映射,hibernate的一些常用的配置,以及对应的一个向数据库插入数据的小例子.期间碰 ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
随机推荐
- 查找IFileSourceFilter上的Pin
创建了IFileSourceFilter,可IFileSourceFilter好像不是从IBaseFilter继承来的,没有EnumPins,那应该怎么查找IFileSourceFilter上的pin ...
- Entity Framework Core必须牢记的三条引用三条命令
关于EntityFramework Core有三个重要的引用和三条重要的命令,掌握以这六条,基本用Entity Framework Core就得心应手了. 引用1:Install-PackageMic ...
- Spring Boot Actutaur + Telegraf + InFluxDB + Grafana 构建监控平台
完成一套精准,漂亮图形化监控系统从这里开始第一步 Telegraf是收集和报告指标和数据的代理 它是TICK堆栈的一部分,是一个用于收集和报告指标的插件驱动的服务器代理.Telegraf拥有插件或集成 ...
- 【转载】Spark运行架构
1. Spark运行架构 1.1 术语定义 lApplication:Spark Application的概念和Hadoop MapReduce中的类似,指的是用户编写的Spark应用程序,包含了一个 ...
- iOS学习——自动定位
最近在项目中需要做自动定位功能,就是你在参加会议通过扫描二维码签到的时候自动定位并将你的定位信息在签到中上传,这样可以避免我们进行假签到.在这个功能中,主要用到的是系统自带的定位模块,首先我们是需要配 ...
- AC自动机模板2(【CJOJ1435】)
题面 Description 对,这就是裸的AC自动机. 要求:在规定时间内统计出模版字符串在文本中出现的次数. Input 第一行:模版字符串的个数N. 第2->N+1行:N个字符串.(每个模 ...
- hive数据库的哪些函数操作是否走MR
平时我们用的HIVE 我们都知道 select * from table_name 不走MR 直接走HTTP hive 0.10.0为了执行效率考虑,简单的查询,就是只是select,不带count, ...
- ------ 开源软件 Tor(洋葱路由器,构建匿名网络的方案之一)源码分析——主程序入口点(二)------
---------------------------------------------------------- 第二部分仅考察下图所示的代码片段--configure_backtrace_han ...
- repo 和git的用法
1. 服务器版本下载: repo init -u git@192.168.1.11:i700t_60501010/platform/manifest.git-b froyo_almond -m M76 ...
- Win 及 Linux 查找mac地址的方法
1. Windows系统中 - 调出cmd命令行 - 运行Getmac命令.命令行中输入: getmac /v /fo list 并按下回车键 - 查找物理地址.这是MAC地址的另一种描述方式.因为在 ...