python爬虫---抓取优酷的电影
最近在学习爬虫,用的BeautifulSoup4这个库,设想是把优酷上面的电影的名字及链接爬到,然后存到一个文本文档中。比较简单的需求,第一次写爬虫。贴上代码供参考:
# coding:utf-8 import requests
import os
from bs4 import BeautifulSoup
import re
import time '''抓优酷网站的电影:http://www.youku.com/ ''' url = "http://list.youku.com/category/show/c_96_s_1_d_1_u_1.html"
h = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"} #存到movie文件夹的文本文件中
def write_movie():
currentPath = os.path.dirname(os.path.realpath(__file__))
#print(currentPath)
moviePath = currentPath + "\\" + "movie"+"\\" + "youku_movie_address.text"
#print(moviePath)
fp = open(moviePath ,encoding="utf-8",mode="a") for x in list_a:
text = x.get_text()
if text == "":
try:
fp.write(x["title"] + ": " + x["href"]+"\n")
except IOError as msg:
print(msg) fp.write("-------------------------------over-----------------------------" + "\n")
fp.close() #第一页
res = requests.get(url,headers = h)
print(res.url)
soup = BeautifulSoup(res.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank")
write_movie() for num in range(2,1000): #获取“下一页”的href属性
fanye_a = soup.find(charset="-4-1-999" )
fanye_href = fanye_a["href"]
print(fanye_href)
#请求页面
ee = requests.get("http:" + fanye_href,headers = h)
time.sleep(3)
print(ee.url) soup = BeautifulSoup(ee.content,'html.parser')
list_a = soup.find_all(href = re.compile("==.html"),target="_blank") #调用写入的方法
write_movie()
time.sleep(6)
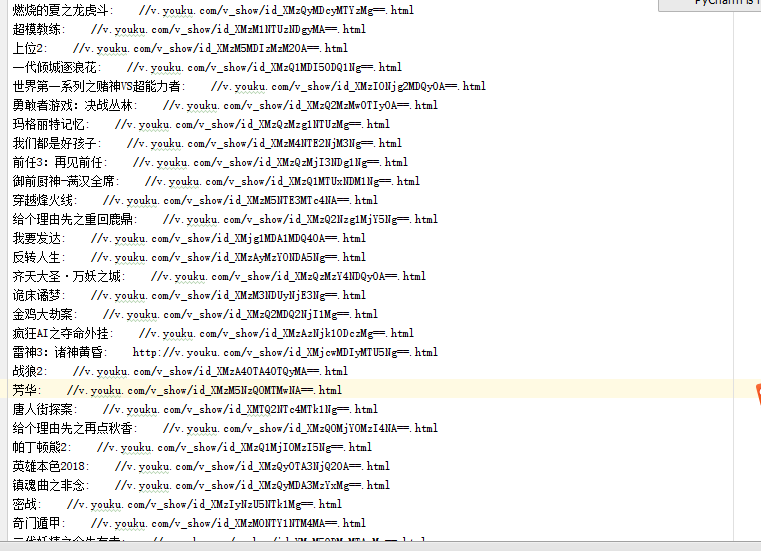
运行后的txt内的文本内容:
python爬虫---抓取优酷的电影的更多相关文章
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- python爬虫 抓取一个网站的所有网址链接
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
随机推荐
- freemarker报错之九
1.错误描述 五月 30, 2014 11:52:04 下午 freemarker.log.JDK14LoggerFactory$JDK14Logger error 严重: Template proc ...
- tar (child): jdk-7u71-linux-x64.tar.gz:无法 open: 没有那个文件或目录
1 错误描述 youhaidong@youhaidong:~$ sudo mkdir /usr/lib/jvm [sudo] password for youhaidong: youhaidong@y ...
- 小白学爬虫-在无GUI的CentOS上使用Selenium+Chrome
爬虫代理IP由芝麻HTTP服务供应商提供各位小伙伴儿的采集日常是不是被JavaScript的各种点击事件折腾的欲仙欲死啊?好不容易找到个Selenium+Chrome可以解决问题! 但是另一个▄█▀█ ...
- Struts+Spring+Hibernate、MVC、HTML、JSP
javaWeb应用 JavaWeb使用的技术,比如SSH(Struts.Spring.Hibernate).MVC.HTML.JSP等等技术,利用这些技术开发的Web应用在政府项目中非常受欢迎. 先说 ...
- OpenStack_I版 7.Cinder部署
Cinder提供块存储 Cinder安装 创建相关的目录 创建数据库 修改Cinder配置文件 同步数据库 keystone相关配置 ...
- 手机端仿ios的单级联动脚本三
脚本 <script>var weekdayArr=['非公司企业法人','个体工商户','私营独资企业','私营合伙企业','有限责任公司','股份有限责任公司'];var mobile ...
- PHPExcel的使用
1.当然是下载PHPexcel的插件了 http://phpexcel.codeplex.com/ 2.应用插件 我把插件和需要用到的excel模板放的是不同文件夹的,excel我放在publi ...
- 如何在Java应用中提交Spark任务?
最近看到有几个Github友关注了Streaming的监控工程--Teddy,所以思来想去还是优化下代码,不能让别人看笑话,是不.于是就想改在一下之前最丑陋的一个地方--任务提交 本博客内容基于Spa ...
- TensorLayer官方中文文档1.7.4:API – 数据预处理
所属分类:TensorLayer API - 数据预处理¶ 我们提供大量的数据增强及处理方法,使用 Numpy, Scipy, Threading 和 Queue. 不过,我们建议你直接使用 Tens ...
- [BZOJ1306] [CQOI2009] match循环赛 (搜索)
Description Input 第一行包含一个正整数n,队伍的个数.第二行包含n个非负整数,即每支队伍的得分. Output 输出仅一行,即可能的分数表数目.保证至少存在一个可能的分数表. Sam ...