五一培训 清北学堂 DAY1
今天是冯哲老师的讲授~
1.枚举
枚举也称作穷举,指的是从问题所有可能的解的集合中一一枚举各元素。
用题目中给定的检验条件判定哪些是无用的,哪些是有用的。能使命题成立的即为其解。
例一
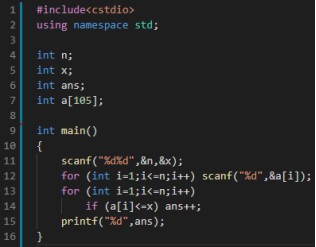
一棵苹果树上有n个苹果,每个苹果长在高度为Ai的地方。
小明的身高为x
他想知道他最多能摘到多少苹果
数据范围: 1 ≤ n, Ai, x ≤ 100
题解
问题相当于询问有多少i满足Ai <= x
考虑用for循环枚举每一个苹果是否能被摘到即可。
例二
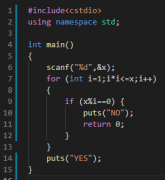
判断一个数X是否是素数
1 ≤ X ≤ 109
题解
考虑定义,若X为合数,则必然有:
∃1 < i < X, i|X
我们考虑直接枚举每个i,看他是否为X的因子。
时间复杂度O(N),不符合要求;
事实上我们发现,假设X是一个合数,那么必然有:
X = a * b,必然有:
min(a, b) <= √X
因此我们枚举的范围可以从X变为√X
时间复杂度O(√N)
例三
求[l, r]这段区间中有多少素数
1 ≤ l ≤ r ≤ 10^6
题解
一个显然的想法是利用for循环枚举[l, r]中的每一个数。然后
利用例二中的知识O(√X)进行判断。
整体复杂度O(N√N),不符合要求
筛法求素数
仍然考虑枚举判断每个数是否是素数,但我们这次从2开始判断。
考虑对于任意一个数x,不论x是否为素数,都
有x*2,x*3,x*4...为合数。我们“筛”掉这些必然为合数的数。
那么当我们枚举到i,i还没有被筛掉,那么i必然为素数。
时间复杂度O(NlogN)
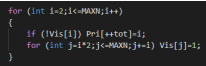
也就是埃拉托斯特尼筛法,简称埃氏筛
具体为什么不用欧拉筛(线性筛),我也不知道,老师说先不讲……
例四
T次询问,每次询问[l, r]中有多少素数
1 ≤ T ≤ 105, 1 ≤ l ≤ r ≤ 10^6
题解
有多次询问,如果每次询问我们都先找一遍,那么肯定TLE,那么咋办呢?
我们用ANSL,R来表示[l, r]中有多少素数
运用前缀和的思想(先进行预处理):

#include<cstdio>
using namespace std;
#define MAXN 1000005
int sum[MAXN],vis[MAXN]; //sum储存1~i的质数个数,vis记录第i个数是否为质数
int t,l,r;
void pre() //预处理所有1~MAXN内的质数个数
{
for(int i=;i<=MAXN;i++)
{
sum[i]=sum[i-]; //1到i的质数个数一定大于等于i到i-1的质数个数,所以利用前缀和求质数个数
if(!vis[i]) sum[i]++; //如果i是质数,个数加一
for(int j=i*;j<=MAXN;j+=i) //埃氏筛把i所有的倍数都判为合数
vis[j]=; //标记为合数
}
}
int main()
{
pre();
scanf("%d",&t);
while(t--)
{
scanf("%d%d",&l,&r);
printf("%d\n",sum[r]-sum[l-]); //直接利用前缀和求质数个数
}
return ;
}
例五
已知n个整数x1, x2, .., xn,以及一个整数k,k < n。从n个数字
中任选k 个整数相加,可分别得到一系列的和。
例如当n = 4, k = 3,四个整数分别为3,7,12,19时,可得全部
的组合与他们的和为:
3 + 7 + 12 = 22
3 + 7 + 19 = 29
7 + 12 + 19 = 38
3 + 12 + 19 = 34
现在,要求计算出和为素数的组合共有多少种。
例如上例,只有一种组合的和为素数:3 + 7 + 19 = 29
1 ≤ n ≤ 20, k < n
1 ≤ x1, x2, .., xn ≤ 5 * 106
题解
首先我们来考虑如何枚举这样的组合。
我们用ai来表示第i个数是否被选
ai = 1表示这个数被选择了
ai = 0表示这个数未被选择
枚举过程相当于枚举了一组二进制状态
比如对于五个数1,2,3,4,5
01010表示我们选择了2,4,未选择1,3,5
在不考虑k的限制的情况下,我们枚举所有组合就相当于
枚举00..00(n个0) → 11..11(n个1)
对于任意一种中间状态,0的个数+1的个数为n
我们假设这是一个长为n的二进制数,我们将它转换成十进制。因为十进制的0(每个都不选)到2^n(每个数都选)中的每个数就是对应着其中的每一情况
事实上就是枚举了一个数,范围是[0, 2^n)
判断位置i是否为1使用位运算来完成
冯哲老师版强势看不懂代码: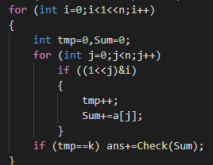
自己看了百度+问老师+问同学+想了半小时的代码吐血:
for(int i=;i<pow(,n);i++) //枚举从0到2^n中的每个数,对应每种情况
{
int tmp=,sum=; //tmp记录已经选的数的个数,sum记录已经选的数的和
for(int j=;i<n;j++) //枚举i的每一位
{
if((i>>j)&==) //将i转化成二进制后的数右移j位,达到将原先的第j位移到后一位的效果,如果&1为1,说明原先的第j位为1,就说明选了a[j]
{
tmp++; //选的数加一
sum+=a[j]; //sum加上当前选的数
}
}
if(tmp==k) ans+=check(sum);//如果选的数够k个,判断一下sum是否为质数,是返回1,不是返回0
}
看二进制中1的个数是否等于k,如果是就进一步判断是否和为素数。Check部分即为判断是否为素数。
考虑到最大Sum不超过20 * 500w,预处理出10000以内的素数可以加速。
例六
求[l,r]中有多少数既是回文数又是素数
1 ≤ l ≤ r ≤ 10
策略一
枚举每个数,判断他是不是回文数,判断他是不是素数
时间复杂度O(N√N + NlogN)
策略二
预处理出区间所有素数,枚举素数判定是否是回文数
时间复杂度O(NlogN) ,判断回文数的时间复杂度可以不计。
策略三
枚举区间内所有回文数,判断是否是素数
枚举回文数即枚举一个数的前一半,再手动扩展成完整的数
另外,偶数位数的回文数都必然是11的倍数,不需要枚举。
时间复杂度O(√N * √N) = O(N),第一个√N是只要枚举前一半就好了,第二个√N是判素数。
枚举法的优缺点:
优点:
简单明了,分析直观
能够帮助我们更好地理解问题
运用良好的枚举技巧可以使问题变得更简单
缺点:
时空间效率低
往往没有利用题目中的特殊性质
产生了大量冗余状态
2.搜索
本质上是一种枚举
搜索算法一般做一些普通的枚举不方便表达状态的情况
例题
给出一个N*N的迷宫,求从起点出发,不经过障碍物到达终点的最短距离
解决这类问题一般有两种方式
1.深度优先搜索(一条路走到黑才改变方向)
2.广度优先搜索(考虑的很周全,每一步都会试试)
前置知识
栈:后进先出的数据结构
支持的操作:
1.加入一个数
2.删除最晚加入的数(符合后进先出)
3.查询最晚加入的数
实现:一个数组+一个用于指向栈顶位置的变量
系统内部递归即使用了栈
1.DFS
DFS的操作过程:
Step 1:
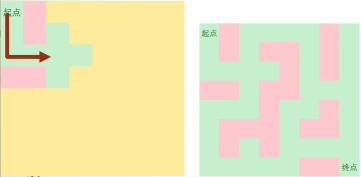
Step 2:
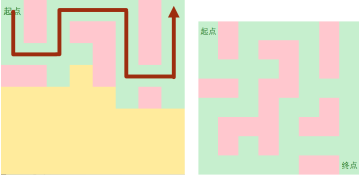
当dfs时发现前方路径不合法时,改变方向
Step 3:
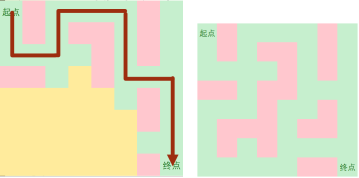
到达终点,但不确定该路径是否为最小路径——继续搜!
Step 4:
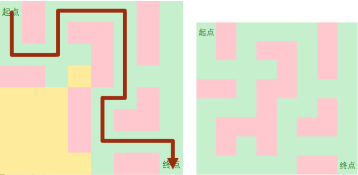
又一条合法路径qaq
DFS的优缺点
优点:1.占用空间小(只需要记录从起点到当前点的路径)
2.代码短
缺点:1.获得的不一定是最优解
2.在图上路径非常多的时候,复杂度可能会达到指数级别
前置知识
队列:先进先出的数据结构
支持的操作:
1.加入一个数
2.删除最早加入的数(符合先进先出)
3.查询最早加入的数
实现:一个数组+头下标+尾下标
2.BFS
BFS的操作过程
Step 1:
Step 2:
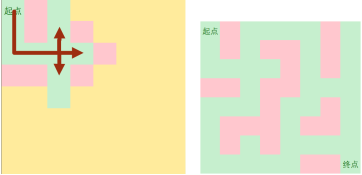
在有多个方向的路口时,bfs会将所有可能到达的点入队
这样可以表示每个点需要起点走多少步才可以到达:

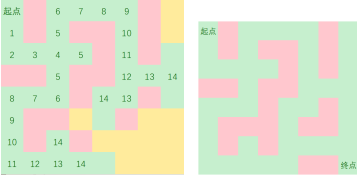
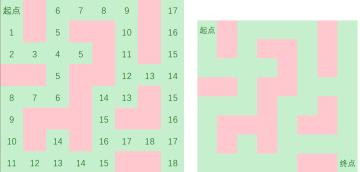
这样,我们可以直观的看到从起点到终点的最小步数
BFS的优缺点
优点:1.找到答案时找到的一定是最优解
2.复杂度不会超过图的大小
缺点:1.需要维护一个“当前箭头的集合”,空间较大
DFS和BFS得区别:

应用:图的遍历(就像上面的迷宫问题)

图的存储结构
1.画图
2.邻接矩阵存储,用A[x][y] = 0/1表示.优点是便于加删,但是需要O(N2)的空间.
3.直接用vector存下所有的边(邻接表法).优点是空间和访问比较快,缺点是删除比较麻烦.
图的连通块

问题来了!!!

当然是bfs!
每次任选一个没有被访问过的点,然后从这个点开始bfs,找到所有和它连通的点.
时间复杂度O(N + M)
树
例如:
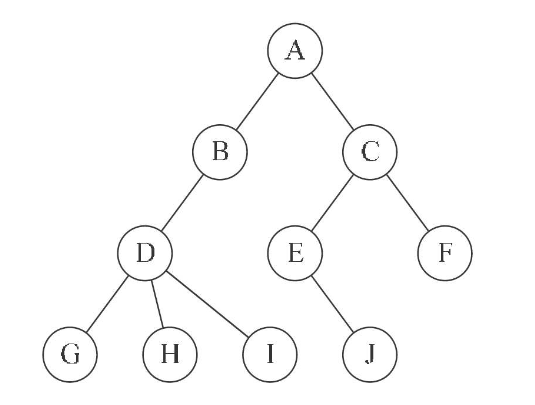
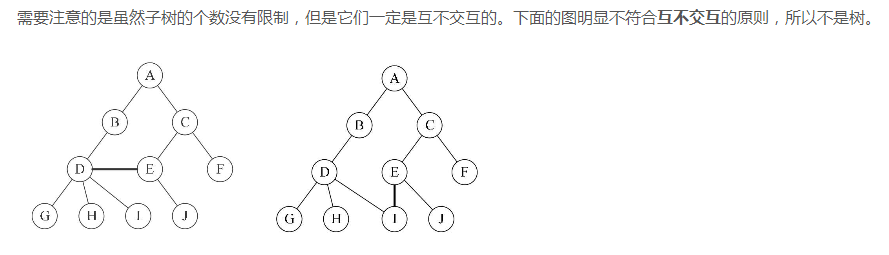
树的遍历


又是自己查百度(鬼畜vector的用法)+问老师将近半小时(老师今晚已经被我拖了一个小时了。。。)的部分代码(因为我也不知道输出什么):
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<iostream>
#include<cstring>
#include<string>
#include<cmath>
#include<ctime>
#include<set>
#include<vector>
#include<map>
#include<queue> #define N 1000005
#define M 20000005 #define ls tree[t].l
#define rs tree[t].r
#define Ls tree[t1].l
#define Rs tree[t1].r
#define mid ((l+r)>>1) #define mk make_pair
#define pb push_back
#define fi first
#define se second using namespace std; vector<int>v[N]; //给每个点开一个vector int i,j,m,n,p,k,size[N],fa[N]; //size数组存从x开始遍历能遍历到的点(包括本身) void dfs(int x) //结点为x
{
int i;
size[x]=; //初始只有本身
for (i=;i<(int)v[x].size();++i) //遍历与x结点相连每条边
{
int p=v[x][i]; //p是第i条边x的另一个端点
if (fa[x]==p) continue; //如果这条边连向它的父亲,就不用管了
fa[p]=x; //否则是它的儿子,因为两点联通必然有一个为父亲,更新fa数组,然后dfs下去算
dfs(p); //继续搜索儿子p的结点
size[x]+=size[p]; //p是x的儿子,前缀和可以顺便计算出x向下一共有多少点
}
} int main()
{
scanf("%d",&n);
for (i=;i<n;++i) //把所有的边加进每个点的vector当中
{
int x,y;
scanf("%d%d",&x,&y);
v[x].push_back(y); //边的另一个点y
v[y].push_back(x); //边的另一个点x
}
dfs(); //从第一个点开始找
}
例一
要求输出1 ∼ n构成的全排列
题解
用一个Vis数组记录每个数字是否被用过,很简单的dfs+回溯
DFS的经典应用
例二

题解
状态?0 ∼ 8 的一个排列
转移?一步能够到达的其他排列
BFS or DFS?
BFS!!!
考虑倒着进行游戏过程。
所有状态都是由最终状态转移得到的
因此我们以最终态为起点做一遍BFS即可预处理出所有状态的答案。
例三
给出一个大小为N*M的迷宫,问从起点到终点最少经过多少障碍物?
1 ≤ n, m ≤ 1000
这个题与普通的迷宫题稍微有所不同,因为它能穿墙qaq
题解
维护两个队列,分别表示当前答案和答案+1的点
每次先走同层的点即可
附上老师打的代码,不懂得太多了,有时间写一份自己的代码:
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<iostream>
#include<ctime>
#include<cmath>
#include<map>
#include<set>
#include<bitset>
#include<vector> #define ls (t<<1)
#define rs ((t<<1)|1) #define N 1005
#define M 200005
#define K 17 #define pb push_back
#define fi first
#define se second
#define mk make_pair using namespace std; int i,j,m,n,p,k,r[]; int vis[N][N]; pair<int,int> Q[][N*N]; char c[N][N]; const int X[]={-,,,};
const int Y[]={,,-,}; int check(int x,int y)
{
if (x<=||y<=||x>n||y>m) return ;
if (vis[x][y]) return ;
return ;
} void bfs(int x,int y)
{
int i,l,now=;
Q[][r[]=]=make_pair(x,y);
memset(vis,-,sizeof(vis));
vis[x][y]=;
for (;;)
{
now^=;
if (!r[now]) return;
for (l=;l<=r[now];++l)
{
int ax=Q[now][r[now]].first,ay=Q[now][r[now]].second;
for (i=;i<;++i)
if (check(ax+X[i],ay+Y[i]))
{
int ck=c[ax+X[i]][ay+Y[i]]=='#';
if (!ck)
{
vis[ax+X[i]][ay+Y[i]]=vis[ax][ay];
Q[now][++r[now]]=make_pair(ax+X[i],ay+Y[i]);
}
else
{
vis[ax+X[i]][ay+Y[i]]=vis[ax][ay]+;
Q[now^][++r[now^]]=make_pair(ax+X[i],ay+Y[i]);
}
}
}
}
} int main()
{
scanf("%d%d",&n,&m);
for (i=;i<=n;++i) scanf("%s",c[i]+);
for (i=;i<=n;++i)
for (j=;j<=m;++j)
if (c[i][j]=='S') bfs(i,j);
for (i=;i<=n;++i)
for (j=;j<=m;++j)
if (c[i][j]=='E') printf("%d\n",vis[i][j]);
}
例四 ——跳房子 

题解

例五——推箱子

题解

例六——迷宫入口

题解

用dfs
不是枚举每个正方形放哪,而是看这个地方应该放什么样的正方形
每次选择下表面最低的点,而且要靠左
看最后能不能填满
比如我们按照要求放小正方形完小正方形,如图所示:
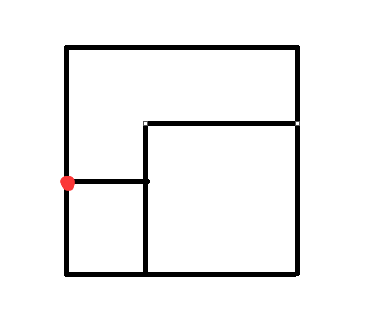
维护一下上表面是否是平的,显然不平!我们按照规则我们继续从红点处开始放小正方形:
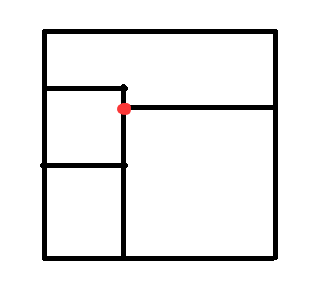
继续放:
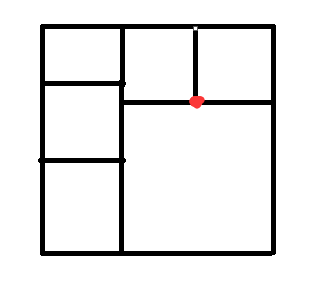
Go on:
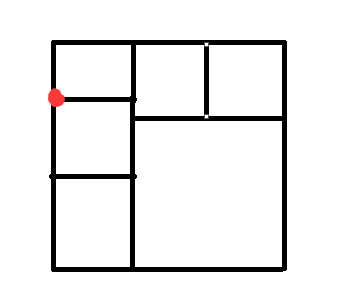
Go on *2:
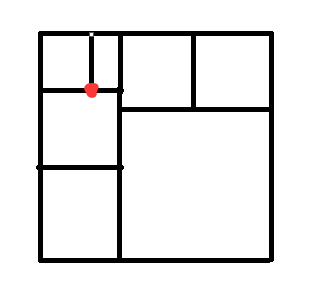
Go on *3:
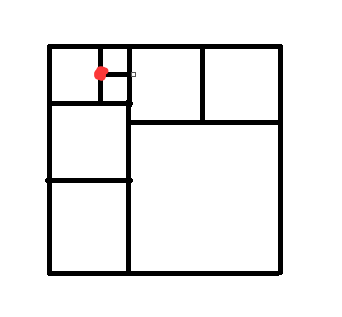
结束:
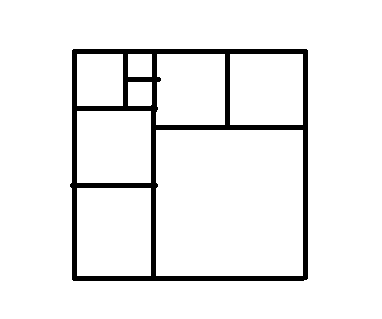
例七——华容道 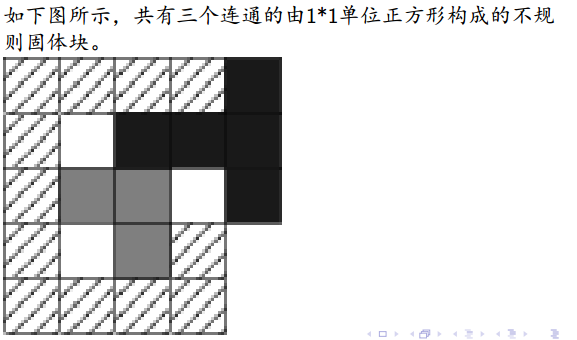
题解

确定了固体块中的一个坐标,整个固体块就确定了,因为固体块的形状不变
Bfs状态写成六维的.....记录三个固体块覆盖矩阵左上角的坐标


暴力降成四维
让一个固体块固定不动,我们只需要动其余两个固体块就好了,相对运动
代码不存在的,老师都说这个题很难,只要了解思路即可!
例八——汇♂合(morning boss)

一波神奇的多源多汇最短路算法(没学qaq):

记忆化搜索
一般说来,动态规划总要遍历所有的状态,而搜索可以排除一些无效状态。更重要的是搜索还可以剪枝,可能剪去大量不必要的状态,因此在空间开销上往往比动态规划要低很多。记忆化算法在求解的时候还是按着自顶向下的顺序,但是每求解一个状态,就将它的解保存下来,以后再次遇到这个状态的时候,就不必重新求解了。这种方法综合了搜索和动态规划两方面的优点,因而还是很有实用价值的。
举个例子:

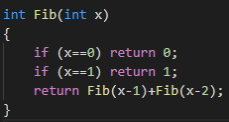
这是最初求斐波那契数列的方法——递归


假设要求F[7]=F[6]+F[5],此时F[6]和F[5]已经计算过了,可直接拿来用,不用再一层层递归到F[1]了
3.贪心

来看个例题:
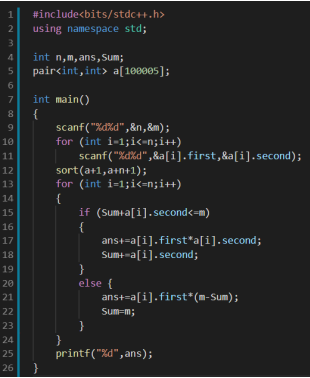
例一
给定N个农民,第i个农民有Ai单位的牛奶,单价Pi
现在要求从每个农民手中购买不超过Ai单位,总共M单位的牛奶。求最小花费
题解
将所有农民按单价排序,能取就取即可
老师的天秀代码(为啥这么麻烦):
例二
给定n个物品,第i个物品有大小li,要求将这些物品装进容积为L的箱子里,每个箱子至多放两个物品,求最少所需箱子数。1 ≤ n ≤ 10^5
题解
将物品从大到小排序
考虑当前的最大物品,假设能与最小值凑成一对,就凑成一对,否则必然不存在一个物品能与他凑成一对,因此单列用双指针维护这个过程即可
例三
有n个物品,每个物品有属性Ai和Bi。你需要将他们排成一行
如果物品i被放在第j个位置,那么会产生代价Ai · (j - 1) + Bi · (n - j),现在要求总代价的最小值,1 ≤ n ≤ 10^5
题解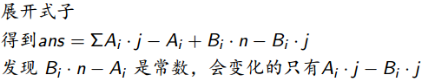
Ai*j-Bi*j=j*(Ai-Bi)
所以对于每个位置j,当j上升的时候,我们让Ai-Bi尽量的小,这样可使得总代价最小
所以贪心思路为:按照Ai-Bi的大小从大到小排序即可
例四

题解
我们可以将上面的式子进行化简(第一行的Ai与第三行的Ai是不同的,第三行的Ai是实际出水量,方便起见下面用Bi表示实际出水量):
根据题意可得出式子:
Σ(Bi*ti)/Σ(Bi)=T
∴Σ(Bi*ti)=T*Σ(Bi)
∴Σ(Bi*ti)=Σ(Bi*T) -------乘法分配律
∴ΣBi*(ti-T)=0
我们知道ti-T是可以大于0或小于0的,所以我们就可以把ti-T的结果分成两组
把数组分成两块,一半小于等于0,一半大于0
进而用贪心的思想,可以发现有一半必须全选,另一半选最靠近T的那些
老师证明:
假设负数集里面还有一些没选,正数集里还有数剩余
那么我们就可以把他们凑出一个0出来,直到某一边用完为止.证毕.
所以就可以直接贪心了
我听了YY的证明后总结的:
ti-T一定有正有负,不然不能平均出T
所以我们分成2种情况:
1.负数居多:
所以部分负数将那一小部分正数抵消掉后,还有一些负数,为了使上面我们化简后的等式成立,这一部分的负数必须接近0,也就是ti尽量靠近T,那么这时,我们将正数全选了;
2.正数居多:
与上面同理,部分正数将那一小部分的负数消掉后还有一些正数,为了使等式成立这一部分正数必须接近0,也就是ti尽量靠近T,那么这时,我们将负数全选了;
综上,我们发现有一半必须全选,另一半选最靠近T的那些
例五
题解

4.二分
一般应用:

原理:

二分答案

例一——跳石头

题解
最小化:最大的跳跃距离
二分答案:设答案为mid,则问题变为:
n个石子,只能跳m次,每次跳远距离不能超过mid,问是否可行。
或者n个石子,每次最远距离不超过mid,问最少跳多少次(然后和m比较即可)。
贪心策略:每次跳的尽量远即可
二分O(logN)*贪心O(N)=O(NlogN)
例二



结论:

二分答案
假设sum(Ai)/sum(Bi) >= mid
对式子进行化简:
则:sum(Ai) - mid * sum(Bi) >= 0
即:sum(Ai-mid*Bi) >= 0
将Ai-mid*Bi作为第i个物品的权值,问题变为能否选k个物品
使得权值和大于0.此时贪心选择权值最大的k个物品即可。
二分O(logN)* 排序O(NlogN) = O(Nlog 2N)
例三

题解
显然k次操作会用完
询问的实际上是使得最小值最大,因此想到二分答案
对于每一个答案判断是否合法即可
考虑一个点如果需要补,必然补在最右侧
差分一下即可


三分:
situation 1:
显然在r右侧的点都不会成为答案
situation 2:
显然在r右侧的点都不会成为答案
situation 3:
显然在l左侧的点都不会成为答案
总结:
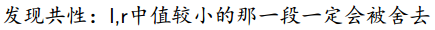

例一

题解

4.分治
分治的思想

应用 1:
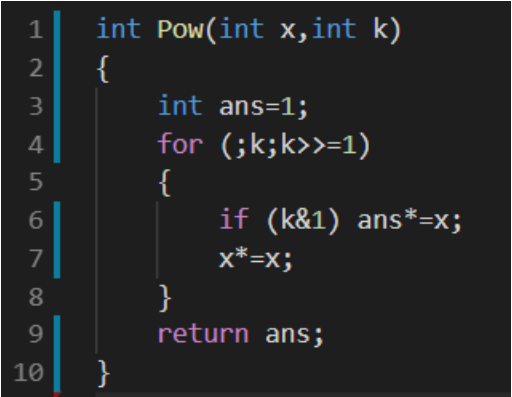
快速幂(quick_pow):
question:

直接跳过O(k)暴力求,来到O(log k)的快速幂:

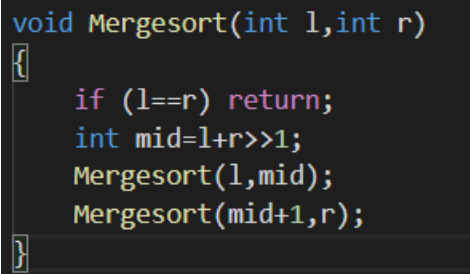
归并排序

1.分:

2.治:
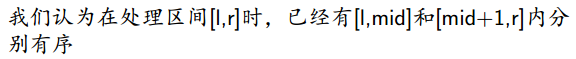

图解一下(原文链接 https://www.cnblogs.com/chengxiao/p/6194356.html):
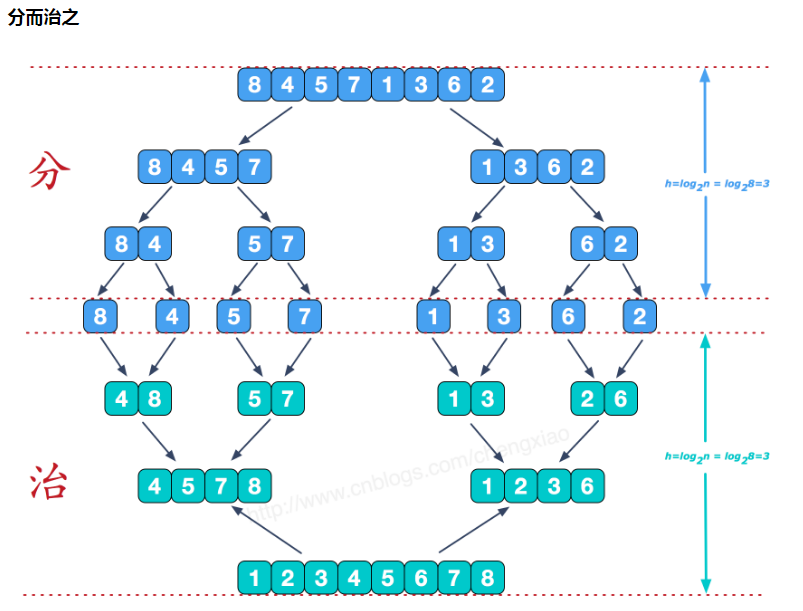
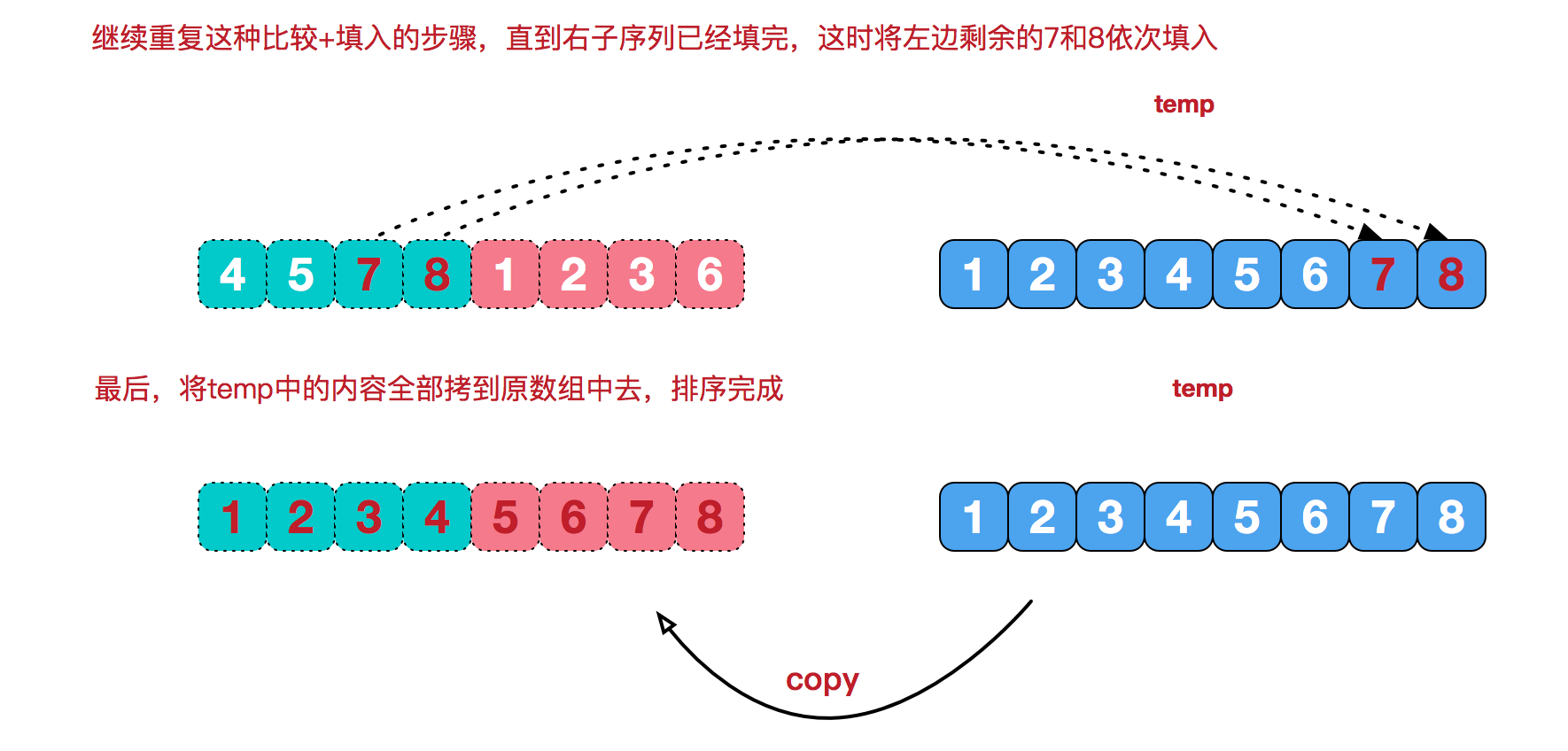
治的过程: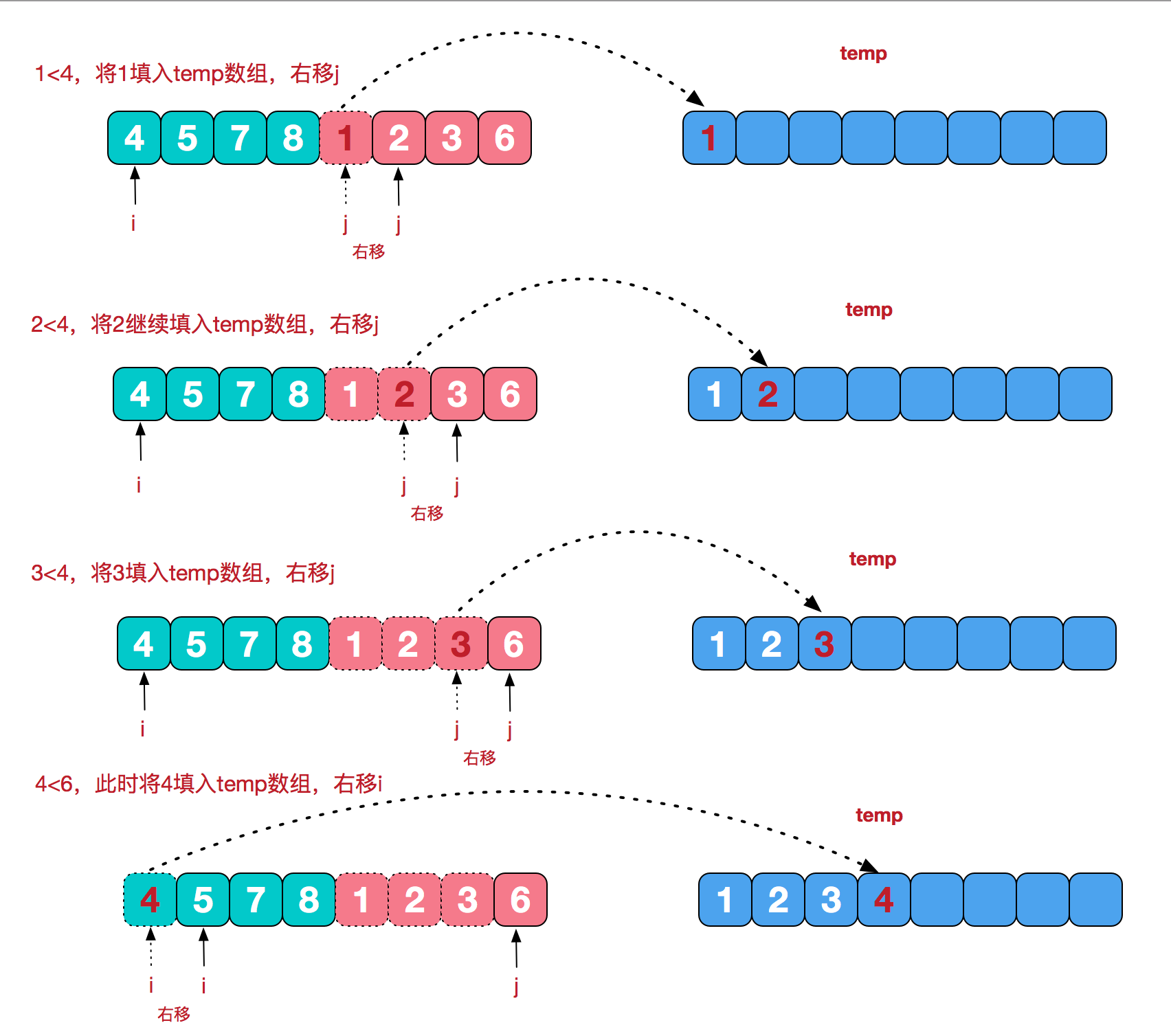
代码实现
package sortdemo; import java.util.Arrays;
public class MergeSort {
public static void main(String []args){
int []arr = {,,,,,,,,};
sort(arr);
System.out.println(Arrays.toString(arr));
}
public static void sort(int []arr){
int []temp = new int[arr.length];//在排序前,先建好一个长度等于原数组长度的临时数组,避免递归中频繁开辟空间
sort(arr,,arr.length-,temp);
}
private static void sort(int[] arr,int left,int right,int []temp){
if(left<right){
int mid = (left+right)/;
sort(arr,left,mid,temp);//左边归并排序,使得左子序列有序
sort(arr,mid+,right,temp);//右边归并排序,使得右子序列有序
merge(arr,left,mid,right,temp);//将两个有序子数组合并操作
}
}
private static void merge(int[] arr,int left,int mid,int right,int[] temp){
int i = left;//左序列指针
int j = mid+;//右序列指针
int t = ;//临时数组指针
while (i<=mid && j<=right){
if(arr[i]<=arr[j]){
temp[t++] = arr[i++];
}else {
temp[t++] = arr[j++];
}
}
while(i<=mid){//将左边剩余元素填充进temp中
temp[t++] = arr[i++];
}
while(j<=right){//将右序列剩余元素填充进temp中
temp[t++] = arr[j++];
}
t = ;
//将temp中的元素全部拷贝到原数组中
while(left <= right){
arr[left++] = temp[t++];
}
}
}
例一——逆序对

题解
首先显然我们枚举x,y可以做到O(N2)
分治:
假设当前问题 Work(l,r) 是求l到r区间内的逆序对数量。
讨论所有(x,y)可能在的位置:
l ≤ x < y ≤ mid :子问题Work(l,mid)
x ≤ mid < y : ???
mid + 1 ≤ x < y ≤ r :子问题Work(mid+1,r)
对于每个mid右边的数,我们要找到mid左边有多少比它大
的数。
1) 对左侧排序,右侧在左侧上二分即可。 总时间复杂度O(nlog2n);
2) 归并排序:
对于数组A和数组B的归并过程,每当我们将B中的元素取出时:说明A中最小的元素比该元素大:说明A中所有元素比该元素大:说明 答案+=A.size();
归并过程时间复杂度O(n),总时间复杂度O(nlogn)。
例二

以15为例:
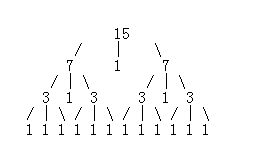
我们可以看到左半边与右半边是完全一样的:
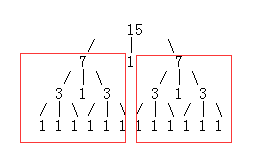
进一步,它们的子树集也是完全一样的:
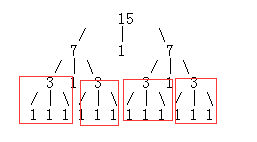
所以我们得到了一个递归式:

后面加的那个1是n%2的结果
最后查询的时候判断一下是否在查询区间中即可
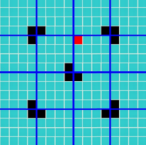
例三——娶公主铺地毯

将宫殿平均分成四等分,并且在除了公主所在的那个小正方形(四等分后的)的其余三个放一个毯子
继续将每个小正方形四等分(也就是整体十六等分),并且在除了毯子所在的那个小正方形(四等分后的)的其余三个放一个毯子
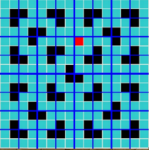
继续重复上述操作

知道将小正方形分成2*2的小正方形,就大功告成啦!
例四——平面最近点对 (afternoon boss)

题目说得不是很清楚,其实是让你求平面内最近两点间的距离最短。
题解
不妨按照x坐标排序。对于区间[l,r],我们将其分成mid左右
两个部分。
两个点都在左侧:子问题Work(l,mid)
两个点都在右侧:子问题Work(mid+1,r)
两个点一个在左侧,一个在右侧:
重点考虑第三种情况
老师的解释:

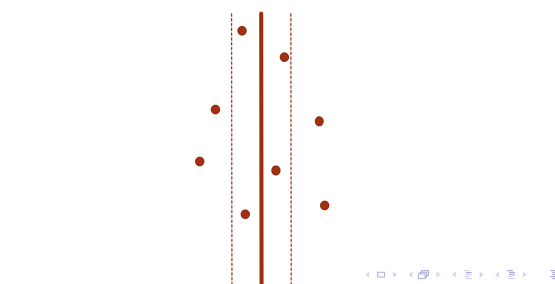
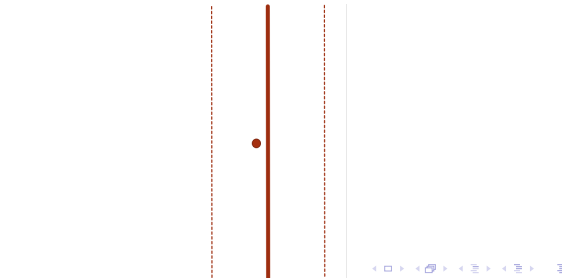


大佬繁夜的解释(我看懂了!!!):附上网址https://www.cnblogs.com/zyxStar/p/4591897.html
分治
1) 把它分成两个或多个更小的问题;
2) 分别解决每个小问题;
3) 把各小问题的解答组合起来,即可得到原问题的解答。小问题通常与原问题相似,可以递归地使用分而治之策略来解决。
在这里介绍一种时间复杂度为O(nlognlogn)的算法。其实,这里用到了分治的思想。将所给平面上n个点的集合S分成两个子集S1和S2,每个子集中约有n/2个点。然后在每个子集中递归地求最接近的点对。在这里,一个关键的问题是如何实现分治法中的合并步骤,即由S1和S2的最接近点对,如何求得原集合S中的最接近点对。如果这两个点分别在S1和S2中,问题就变得复杂了。
为了使问题变得简单,首先考虑一维的情形。此时,S中的n个点退化为x轴上的n个实数x1,x2,...,xn。最接近点对即为这n个实数中相差最小的两个实数。显然可以先将点排好序,然后线性扫描就可以了。但我们为了便于推广到二维的情形,尝试用分治法解决这个问题。
假设我们用m点将S分为S1和S2两个集合,这样一来,对于所有的p(S1中的点)和q(S2中的点),有p<q。
递归地在S1和S2上找出其最接近点对{p1,p2}和{q1,q2},并设
d = min{ |p1-p2| , |q1-q2| }
由此易知,S中最接近点对或者是{p1,p2},或者是{q1,q2},或者是某个{q3,p3},如下图所示。

如果最接近点对是{q3,p3},即|p3-q3|<d,则p3和q3两者与m的距离都不超过d,且在区间(m-d,d]和(d,m+d]各有且仅有一个点。这样,就可以在线性时间内实现合并。
此时,一维情形下的最近点对时间复杂度为O(nlogn)。
在二维的情况下:
我们仿照一维的情况先把所有点按照x(横坐标)从左到右升序排列.

以X横坐标中间的点作为分界线.将平面的点分成左边和右边,以上图为例,分为左边5个右边5个.
然后找到左边的点中最近点对的距离d1,和右边最近点对的距离d2。
令d=min{d1,d2}.那么d是当前整个平面的最近点对的距离吗?
答案不是!!
当前的d1,d2都是两边各自的点的最近距离,但是没有考虑到两边的点相互配对的情况,即是点对一个在左边区域,一个在右边区域.
如果我们这个时候把两边相互配对的所有情况全部罗列出来那么时间复杂度就变为第一种方法的O(n2).
这个时候我们便可以用上面找到的d来限制配对.即是明显超过d的两点不需要配对.如下:

那么在范围内的只有三个点,也就是说只有这个三个点相互配对的距离才可能比d小.那么再按照方法一一样在这些点中找到最短距离再跟d去比较.小的就是当前整个平面中所考虑的所有点中最近点对的距离。
然而在以上问题处理上,有一个问题尚未解决就是如何找到两边区域中的最近点对的距离d1,d2 ?
我们可以发现在处理上面这个问题的时候,和最开始处理所有平面的点最近点距离的问题类似,只是点的数目减半了.
那么我们可以递归以上问题.直到划分的区域中只有一个或者两个点.这样,该区域的最近点对距离就是无穷大或者该两点的距离。这也是递归终止的条件。
终于结束啦!!!qaq~
五一培训 清北学堂 DAY1的更多相关文章
- 清明培训 清北学堂 DAY1
今天是李昊老师的讲授~~ 总结了一下今天的内容: 1.高精度算法 (1) 高精度加法 思路:模拟竖式运算 注意:进位 优化:压位 程序代码: #include<iostream>#in ...
- 五一培训 清北学堂 DAY4
今天上午是钟皓曦老师的讲授,下午是吴耀轩老师出的题给我们NOIP模拟考了一下下(悲催暴零) 今天的内容——数论 话说我们可能真的是交了冤枉钱了,和上次清明培训的时候的课件及内容一样(哭. 整除性 质数 ...
- 五一培训 清北学堂 DAY2
今天还是冯哲老师的讲授~~ 今日内容:简单数据结构(没看出来简单qaq) 1.搜索二叉树 前置技能 一道入门题在初学OI的时候,总会遇到这么一道题.给出N次操作,每次加入一个数,或者询问当前所有数的最 ...
- 五一培训 清北学堂 DAY3
今天是钟皓曦老师的讲授~ 今天的内容:动态规划 1.动态规划 动态规划很难总结出一套规律 例子:斐波那契数列 0,1,1,2,3,5,8,…… F[0]=0 F[1]=1 F[[n]=f[n-1]+ ...
- 五一培训 清北学堂 DAY5
今天是吴耀轩老师的讲解- 今天的主要内容:图论 如何学好图论? 学好图论的基础:必须意识到图论! 图 邻接矩阵存图: 其缺点是显而易见的:1. 空间复杂度O(n^2)不能接受:2.有重边的时候很麻烦: ...
- 2017 五一 清北学堂 Day1模拟考试结题报告
预计分数:100+50+50 实际分数:5+50+100 =.= 多重背包 (backpack.cpp/c/pas) (1s/256M) 题目描述 提供一个背包,它最多能负载重量为W的物品. 现在给出 ...
- 4.4清北学堂Day1 主要内容:数论,数学
Day 1; 1.常见的高精 输入输出都用字符数组: 字符数组的实际长度用strlen()来求: 运算时倒序运算,把每一个字符都-‘0’ 进位的处理上也要注意: 小数减大数时先判断大小然后加负号 只能 ...
- 清明培训 清北学堂 DAY2
今天是钟皓曦老师的讲授~~ 总结了一下今天的内容: 数论!!! 1.整除性 2.质数 定义: 性质: 3.整数分解定理——算数基本定理 证明: 存在性: 设N是最小不满足唯一分解定理的整数 (1) ...
- 7月清北学堂培训 Day 3
今天是丁明朔老师的讲授~ 数据结构 绪论 下面是天天见的: 栈,队列: 堆: 并查集: 树状数组: 线段树: 平衡树: 下面是不常见的: 主席树: 树链剖分: 树套树: 下面是清北学堂课程表里的: S ...
随机推荐
- linux-2.6.18源码分析笔记---中断
一.中断初始化 中断的一些硬件机制不做过多的描述,只介绍一些和linux实现比较贴近的机制,便于理解代码. 1.1 关于intel和linux几种门的简介 intel提供了4种门:系统门,中断门,陷阱 ...
- Celery工具
什么是Celery Celery的功能 Celery是基于python实现的第三方组件,可以实现定时任务.周期任务等. Celery的组成 Celery的角色 - 任务,创建或发布任务. - 使用re ...
- 前端javascript如何阻止按下退格键页面回退 但 不阻止文本框使用退格键删除文本
这段代码可以: document.onkeydown = function (e) { e.stopPropagation(); // 阻止事件冒泡传递 e.preventDefault(); // ...
- DSAPI官方QQ群
DSAPI官方QQ群 请加主群,若主群成员已满,请加分群. 群内除常规的.NET技术交流外,也负责DSAPI的使用技术支持和更新通知. 『VB.NET/C#编程』主群 ...
- .Net Core 实践 - 如何在控制台应用(.Net Core)使用appsettings.json配置
新建控制台应用(.Net Core)程序 添加json文件,命名为appsettings.json,设置文件属性 如果较新则复制.添加内容如下 { "MyWords" : &quo ...
- 数据库缓存mybatis,redis
简介 处理并发问题的重点不在于你的设计是怎样的,而在于你要评估你的并发,并在并发范围内处理.你预估你的并发是多少,然后测试r+m是否支持.缓存的目的是为了应对普通对象数据库的读写限制,依托与nosql ...
- element表格切入按钮以及复选框
1,element表格切入按钮 关键代码: html:<el-table :data="tableList" border style="width: 100%&q ...
- Javascript之高级数组API的使用实例
JS代码中我们可以根据需求新建新的对象解决问题的同时,也有一些常用的内置对象供我们使用,我们称之为API,本篇文章只是对数组部分进行了练习. 例一:伪数组,不能修改长短的数组(所以没办法清零),可以修 ...
- iOS----------Xcode 无线调试
环境要求: 至少Mac OSX 10.12.6 iOS 11 Xcode 9 1. ”自己的工程“ -> windows -> Device and Simulators ,打开设备和模拟 ...
- Android ViewPager+Fragment 在Activity中获取Fragment的控件
如果ViewPager+Fragment实现Tab切换,在activity中利用adapter.getItem获取到fragment然后再根据fragment.的方法获取控件 //隐藏求租,以下代码用 ...