pandas数据处理基础——筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构)。
本文为了方便理解会与excel或者sql操作行或列来进行联想类比
1.重新索引:reindex和ix
上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号。列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子。
1.1 Series
比方说:data=Series([4,5,6],index=['a','b','c']),行索引为a,b,c。
我们用data.reindex(['a','c','d','e'])修改索引后则输出:

可以理解成我们用reindex设了索引后,根据索引去原来data里面匹配对应的值,没匹配上的就是NaN。
1.2 DataFrame
(1)行索引修改:DataFrame行索引同Series
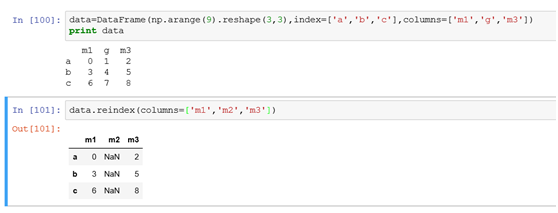
(2)列索引修改:列索引用reindex(columns=['m1','m2','m3']),用参数columns来指定对列索引进行修改。修改逻辑类似行索引,也是相当于用新列索引去匹配原来的数据,没匹配上的置NaN
例:
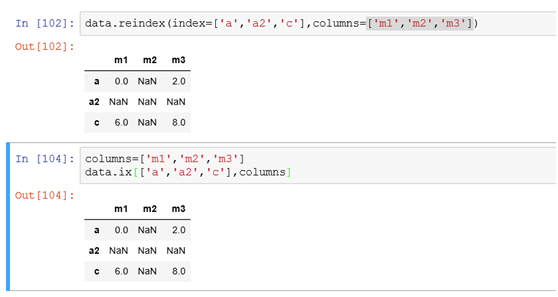
(3)同时对行和列索引进行修改可以用
2.丢弃指定轴上的列(通俗的说法就是删除行或者列):drop
通过索引进行选择删除哪一行或者哪一列
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如

- obj['b']相当于select * from tb where xid='b'
- obj['b','a','c']相当于select * from tb where xid in ('a','b','c'),且结果按照b ,a ,c 的顺序排列后进行展示,这是与sql的区别
- obj[0:1]和obj['a':'b']的区别如下:
#前者是不包含末端,后者是包含了末端

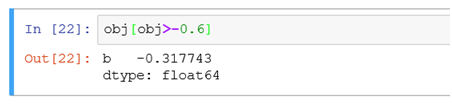
(2)按照值的大小进行筛选obj[obj>-0.6]相当于在obj数据中找出值比-0.6大的记录进行展示
3.2 DataFrame
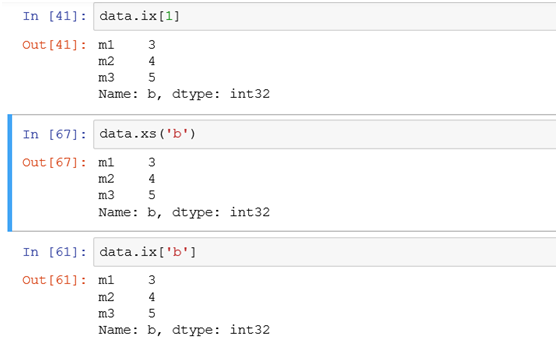
(1)选择单行用ix或者xs:
如筛选索引为b的那条行记录用以下三种方式
(2)选择多行:
筛选索引为a,b的两条行记录的方式
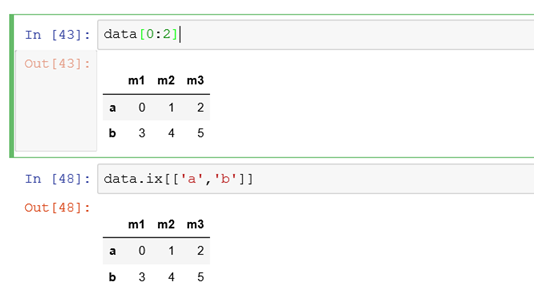
#以上不能直接写成data[['a','b']]
data[0:2]表示从第一行到第二行的记录。第一行默认从0开始数,不包含末端的2。
(3)选择单列
筛选m1列的所有行记录数据
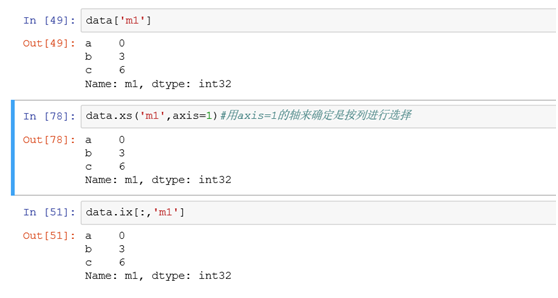
(4)选择多列
筛选m1,m3两个列,所有行记录的数据

ix[:,['m1','m2']]前面的:表示所有的行都筛选进来。
(5)根据值的大小条件筛选行或者列
如筛选出某一列值大于4的所有记录相当于select * from tb where 列名>4
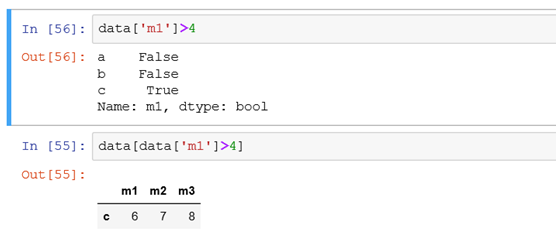
(6)如果筛选某列值大于4的所有记录,且只需展示部分列的情况时

行用条件进行筛选,列用[0,2]筛选第一列和第三列的数据
pandas数据处理基础——筛选指定行或者指定列的数据的更多相关文章
- css3实现超出文本指定行数(指定文本长度)用省略号代替
测试代码: <!DOCTYPE html> <html> <head> <meta name="viewport" content=&qu ...
- pandas数据处理基础——基础加减乘除的运算规则
上周公司对所有员工封闭培训了一个星期,期间没收手机,基本上博客的更新都停止了,尽管培训时间不长,但还是有些收获,不仅来自于培训讲师的,更多的是发现自己与别人的不足,一个优秀的人不仅仅是自己专业那块的精 ...
- linux提取指定行至指定位置
grep查找ERROR,定位位置 awk打印到指定行数 sed打印到文本末尾 awk打印到文本末尾 方法一 #!/bin/csh -f if(-f errorlog.rpt) then rm -rf ...
- shell awk读取文件中的指定行的指定字段
1.awk功能和实用形式 awk指定读取文件中的某一行的某个字段 awk 可以设置条件来输出文件中m行到n行中每行的指定的k字段,使用格式如下 awk 'NR==m,NR==n {pr ...
- 使用sed替换指定文件指定行的指定文本
下面是将85行的127.0.0.1替换为192.168.10.108 sed -i '85{s/127.0.0.1/192.168.10.108/}' /etc/zabbix/zabbix_agent ...
- Pandas数据处理实战:福布斯全球上市企业排行榜数据整理
手头现在有一份福布斯2016年全球上市企业2000强排行榜的数据,但原始数据并不规范,需要处理后才能进一步使用. 本文通过实例操作来介绍用pandas进行数据整理. 照例先说下我的运行环境,如下: w ...
- POI读取指定Excel中行与列的数据
import org.apache.poi.xssf.usermodel.XSSFCell; import org.apache.poi.xssf.usermodel.XSSFRow; import ...
- pandas 一行文本拆多行,一列拆多列
https://zhuanlan.zhihu.com/p/28337202 一列拆多列: http://blog.csdn.net/qq_22238533/article/details/761875 ...
- sql 多行转多列,多行转一列合并数据,列转行
下面又是一种详解:
随机推荐
- expect 简单使用
简单的登陆脚本 这样就不用每次都输入ssh命令了,使用密码还是有些不安全,谨慎使用. #!/usr/bin/expect -f #filename: auto_login.sh #author: or ...
- 收藏了4年的Android 源码分享
Android 超过2个G的源代码集合~~几乎涵盖了所有功能效果的实现,一应俱全~~应有尽有~~ 360云盘地址:Android 各类源码集合汇总 (提取码:f930) 另外,附上Github上及自己 ...
- Linux上程序调试的基石(2)--GDB
3. GDB的实现 GDB是GNU发布的一个强大的程序调试工具,用以调试C/C++程序.可以使程序员在程序运行的时候观察程序在内存/寄存器中的使用情况.它的实现也是基于ptrace系统调用来完成的. ...
- J2EE进阶(十二)SSH框架整合常见问题汇总(三)
在挂失用户时,发现userid值为空,但是在前台输入处理账号22时,通过后台输出可以看出,后台根据前端输入在数据库中查询到结果对象并输出该对象的userid,而且Guashi对象也获取到了其值. 解决 ...
- 解决android 大图OOM的两种方法
最近做程序中,需要用到一张大图.这张图片是2880*2180大小的,在我开发所用的华为3C手机上显示没有问题,但是给米3装的时候,一打开马上报OOM错误.给nexus5装,则是图片无法出来,DDMS中 ...
- hashmap简单实例(个人使用经验)
一.HashMap<int,String>是错误的:因为int是基本类型,而key和value要求是对象,所以要用Integer而不是int.HashMap<String,Objec ...
- Mybatis源码之Statement处理器RoutingStatementHandler(三)
RoutingStatementHandler类似路由器,在其构造函数中会根据Mapper文件中设置的StatementType来选择使用SimpleStatementHandler.Prepared ...
- 【转载】2015 Objective-C 三大新特性 | 干货
Overview 自 WWDC 2015 推出和开源 Swift 2.0 后,大家对 Swift 的热情又一次高涨起来,在羡慕创业公司的朋友们大谈 Swift 新特性的同时,也有很多像我一样工作上依然 ...
- [asp.net]登录协同工作平台安全解决方案
[摘要]公司领导说登录验证的安全性如何保证,建议采用UKEY验证类似网银解决,调用第三方YT公司产品. 解决方案: 前端页面: <embed id="s_simnew61" ...
- Could not find property 'outputFile
* What went wrong: A problem occurred configuring project ':app'. > Could not find property 'outp ...