Network in Network

论文要点:
- 用更有效的非线性函数逼近器(MLP,multilayer perceptron)代替 GLM 以增强局部模型的抽象能力。抽象能力指的模型中特征是对于同一概念的变体的不变形。
- 使用 global average pooling 代替全连接层,提高模型的泛化能力。
GLM 与 MLP 的输入都是局部“像素”
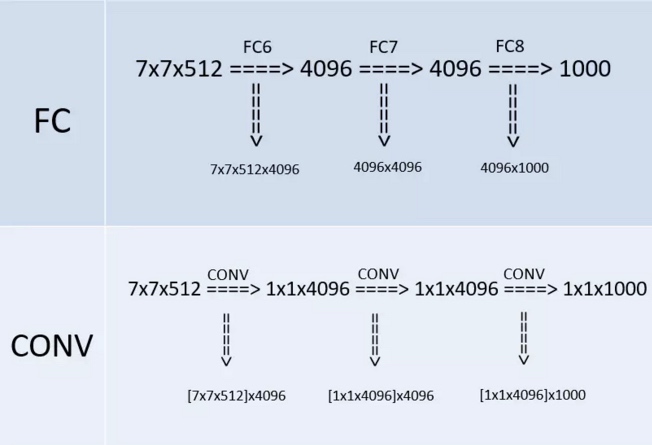
全连接层可以替换成 1×1 卷积层
这个要好好想想!!!

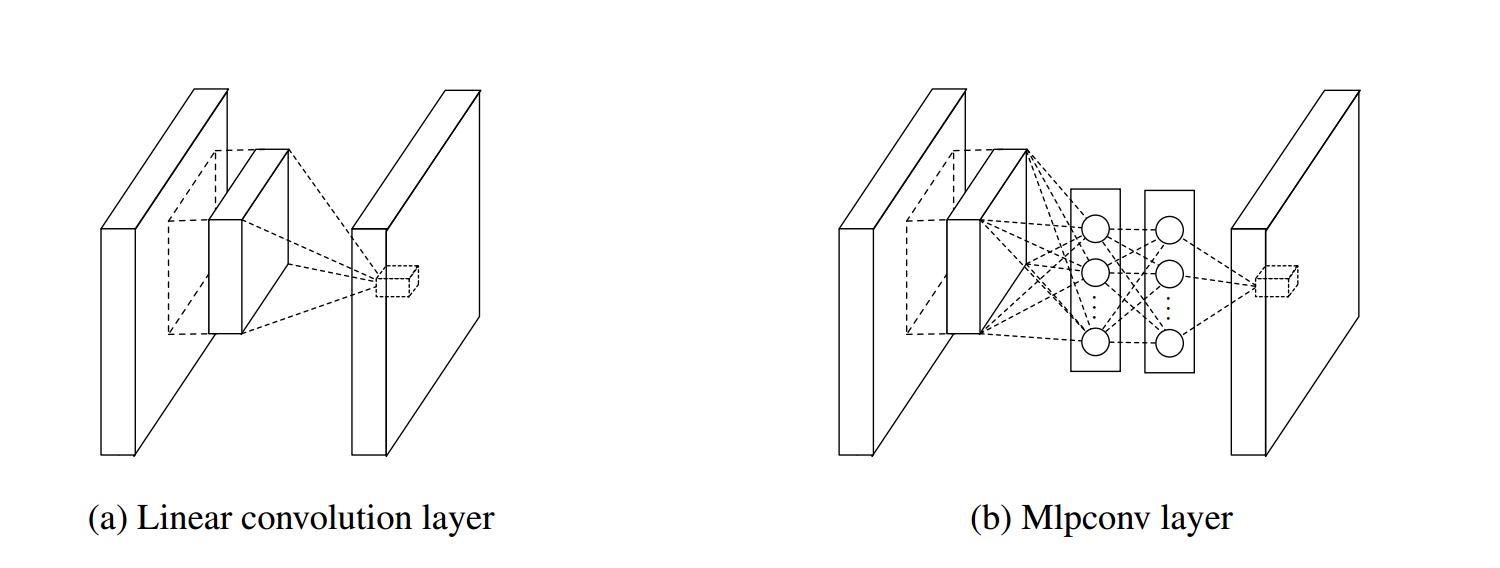
Mlpconv layer
结合下图,来谈谈 Mlpconv layer 的要点:
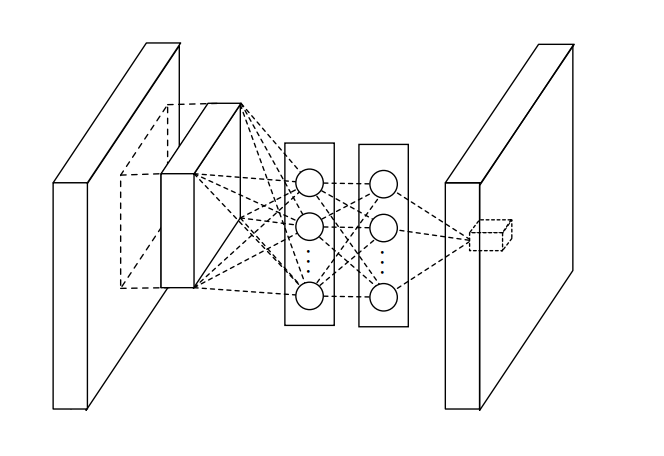 

从交叉通道(即交叉特征映射)池化的角度来看,上图中的网络结构等效于在正常卷积层上的级联交叉通道参数池化层。 每个池化层都会在输入特征图(input feature map)上执行加权线性重组,然后通过整流线性单元。 交叉通道池化所生成的特征图再作为下一交叉通道池化的输入,依次进行下去。这种级联的交叉通道参数池化结构允许交叉通道信息的进行复杂且可学习的交互。 交叉通道参数化池层也等价于具有1x1卷积核的卷积层。
上面是论文中对 NiN 一个很重要的解释,下面解释一下:交叉通道参数池化层也等价于具有1x1卷积核的卷积层到底是何意?
我们就以上图 MLP 的第一层为例说明一下,我们看到上图中一个 patch 作为 MLP 得输入,MLP 第一层的神经元我们可以看成是传统 CNN 中的 filter,即我们在同一个 patch 上同时使用多个 filter(然后通过relu),并且在 MLP 中的第二层将这些 filter 的输出进行线性组合(然后通过 relu),然后通过第三层输出一个值。 这与通过传统 CNN 卷积然后使用 1×1 卷积将一个 patch 上的多个 filter 加权线性组合的总体效果相同,比如一个3层 MLP 来可以通过两次 1×1 卷积(每次过 relu)来达到相同效果。
注意!!! 一个 MLP filter 在一个 patch 上只输出一个值,一个 MLP filter在整个输入层上共享参数,所以和传统 filter 一样, 这里使用多个MLP filter, 而MLP filter 的个数就是下一层feature map的深度。举例如下,下图为使用 NiN 改进的 AlexNet 的网络结构
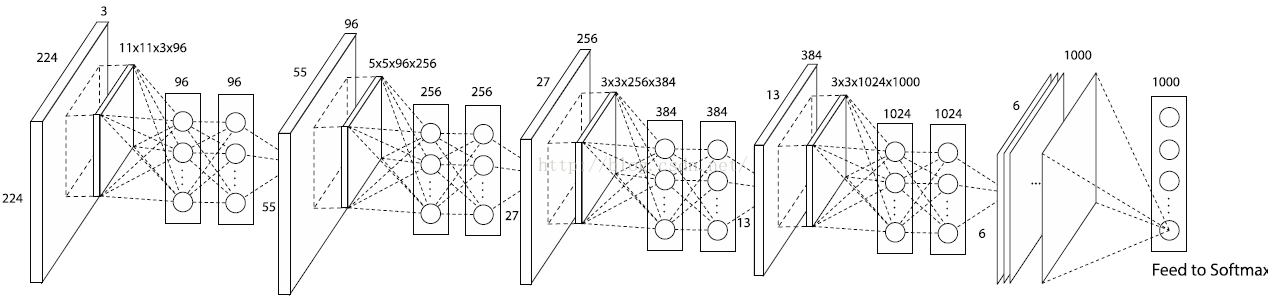 

global average pooling
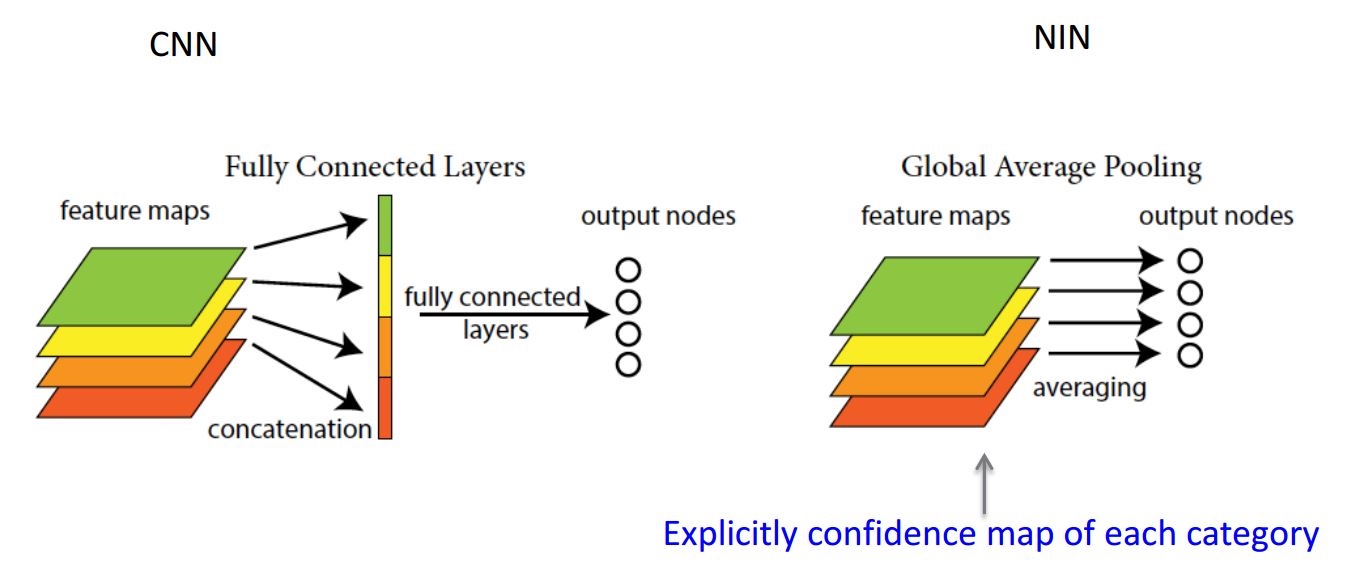 

global average pooling 与 average pooling 的差别就在 "global" 这一个字眼上。global 与 local 在字面上都是用来形容 pooling 窗口区域的。 local 是取 feature map 的一个子区域求平均值,然后滑动这个子区域; global 显然就是对整个 feature map 求平均值了。因此,global average pooling 的最后输出结果仍然是 10 个 feature map,而不是一个,只不过每个 feature map 只剩下一个像素罢了,这个像素就是求得的平均值,10个feature map就变成一个10维的向量,然后直接输入到softmax中。
global average pooling 极大地减少了模型的参数个数,防止模型过拟合,自带正则化光环
Network in Network的更多相关文章
- Deep Learning 24:读论文“Batch-normalized Maxout Network in Network”——mnist错误率为0.24%
读本篇论文“Batch-normalized Maxout Network in Network”的原因在它的mnist错误率为0.24%,世界排名第4.并且代码是用matlab写的,本人还没装caf ...
- Deep Learning 25:读论文“Network in Network”——ICLR 2014
论文Network in network (ICLR 2014)是对传统CNN的改进,传统的CNN就交替的卷积层和池化层的叠加,其中卷积层就是把上一层的输出与卷积核(即滤波器)卷积,是线性变换,然后再 ...
- Linux: service network/Network/NetworkManager
Linux:service network/Network/NetworkManager start 这三种有什么不同? 1.network service的制御网络接口配置信息改动后,网络服务必须从 ...
- 1×1卷积的用途(Network in Network)
1×1卷积,又称为Network in Network 如果卷积的输出输入都只是一个平面,那么1x1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系. 但卷积的输出输入是长方体,所以1x1卷 ...
- Network In Network学习笔记
Network In Network学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50458190 作者:hjimce 一.相关理论 本篇 ...
- Network in Network 2
<Network in Network>论文笔记 1.综述 这篇文章有两个很重要的观点: 1×1卷积的使用 文中提出使用mlpconv网络层替代传统的convolution层.mlp层实际 ...
- Network In Network——卷积神经网络的革新
Network In Network 是13年的一篇paper 引用:Lin M, Chen Q, Yan S. Network in network[J]. arXiv preprint arXiv ...
- 论文《Network in Network》笔记
论文:Lin M, Chen Q, Yan S. Network In Network[J]. Computer Science, 2013. 参考:关于CNN中1×1卷积核和Network in N ...
- NIN (Network In Network)
Network In Network 论文Network In Network(Min Lin, ICLR2014). 传统CNN使用的线性滤波器是一种广义线性模型(Generalized linea ...
- [DeeplearningAI笔记]卷积神经网络2.5-2.7 Network in Network/1*1卷积/Inception网络/GoogleNet
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Inception网络 --Szegedy C, Liu W, Jia Y, et al. Going deepe ...
随机推荐
- 【BZOJ2555】SubString(后缀自动机,Link-Cut Tree)
[BZOJ2555]SubString(后缀自动机,Link-Cut Tree) 题面 BZOJ 题解 这题看起来不难 每次要求的就是\(right/endpos\)集合的大小 所以搞一个\(LCT\ ...
- 【BZOJ1257】余数之和(数论分块,暴力)
[BZOJ1257]余数之和(数论分块,暴力) 题解 Description 给出正整数n和k,计算j(n, k)=k mod 1 + k mod 2 + k mod 3 + - + k mod n的 ...
- PHP之工厂方法模式(三)
定义 定义一个用于创建对象的接口(抽象工厂类),让子类决定实例化哪一个类,工厂方法使得一个类的实例化延迟到其子类(抽象工厂类的子类). 工厂方法模式是简单工厂模式的进一步抽象和推广.在简单工厂 ...
- 云计算之路-阿里云上:3个manager节点异常造成 docker swarm 集群宕机
今天 11:29 - 11:39 左右,docker swarm 集群 3 个 manager 节点同时出现异常,造成整个集群宕机,由此给您带来很大的麻烦,请您谅解. 受此次故障影响的站点有:博问,闪 ...
- hadoop第一课
Hadoop基本概念 在当下的IT领域,大数据很"热",实现大数据场 景的Hadoop系列产品更"热". Hadoop是一个开源的分布式系统基础架构,由 Apa ...
- 【2016北京集训测试赛】river
HINT 注意是全程不能经过两个相同的景点,并且一天的开始和结束不能用同样的交通方式. [吐槽] 嗯..看到这题的想法的话..先想到了每个点的度为2,然后就有点不知所措了 隐隐约约想到了网络流,但并没 ...
- 《阿里巴巴Android编码规范》阅读纪要(一)
版权声明:本文出自汪磊的博客,转载请务必注明出处. 2月28日阿里巴巴首次公开内部安卓编码规范,试想那么多业务线,开发人员,没有一套规范管理起来是多么麻烦,以下是个人阅读Android基本组件部分过程 ...
- tp5 日志文件名称问题
原文:http://www.upwqy.com/details/17.html 我的项目在运行一段时间后 我发现在日志中生成了 1508467147-20.log 这种文件名的日志 开始还以为是bug ...
- css学习の第一四弹—代码格式简写归纳
一.代码简写方式归纳 >>1.盒模型代码简写: 外边距(margin).内边距(padding)和边框(border)设置上下左右四个方向的边距是按照顺时针方向设置的:上右下左 1.如果t ...
- epoll 实现回射服务器
epoll是I/O复用模型中相对epoll和select更高效的实现对套接字管理的函数. epoll有两种模式 LT 和 ET 二者的差异在于 level-trigger 模式下只要某个 socket ...