深入浅出Hadoop之HDFS
hadoop生态系统一直是大数据领域的热点,其中包括今天要聊的HDFS,和计划以后想聊的yarn, mapreduce, spark, hive, hbase, 已经聊过的zookeeper,等等。
今天主聊HDFS,hadoop distributed file system, 起源于Google 的 GFS,只不过GFS是用c++写的,Hadoop是Doug Cutting在yahoo用Java写的。2008 年 Hadoop成为Apache top-level project。
应用
HDFS适用于什么场景呢? 非常大的文件存储,比如以G或T为单位,因为HDFS内部的block的基本单位已经是128MB。注意这里有一个小文件问题,误区是说怕1K的小文件也能占用128MB的硬盘,其实不是的,它还是占用1K硬盘,但是小文件问题的bottle neck是在name node里,因为name node要存储文件和block的相关信息在内存里,文件数量一多,name node的内存就不够了(比如,百万小文件要占用300MB 内存),当然hdfs federation能够通过sharding的方式解决name node内存不够用的问题,接下来会细说。HDFS还适用于“write once,read-many”的场景,而且它的写是append only,所以想改也没法改。如果是多次写的话,应该考虑一下cassandra(参见我的上一篇文章)。同时HDFS的文件通常只能允许single writer写入(是通过lease的方式来保证只有一个writer能够当前写某个文件)。HDFS因为只需要普通的commodity hardware而不需要昂贵的高可用硬件而被企业欢迎。HDFS不适用于需要low latency的数据访问方式,因为HDFS是拿延迟交换高throughput。
概念
Blocks
HDFS里,文件是被分割成block大小的chunk,每个block是128MB,有人会问了,为什么非要搞这么大,主要是要缩短寻道时间在总硬盘读写时间中的比例,比如寻道时间需要5 ms,而寻到时间只能占总时间0.5%的比例,那么硬盘读写时间差不多在1s左右,1s中能穿多少文件呢,如果硬盘的读写为128MB/s,那么就能传128MB,所以block大小就定义为128MB,这样可以保证硬盘操作的时间有效的应用在读写上而不是花费在寻道上。当然太大了也不行,mapreduce的map通常是以block为单位,如果block太少,mapreduce的效率会比较低。
hdfs fsck $path -files -blocks -locations
上面的命令可以用来提供文件的block信息,比如block在哪台机器,名字是什么,方便你进一步查询block的具体信息。
Namenodes and datanodes
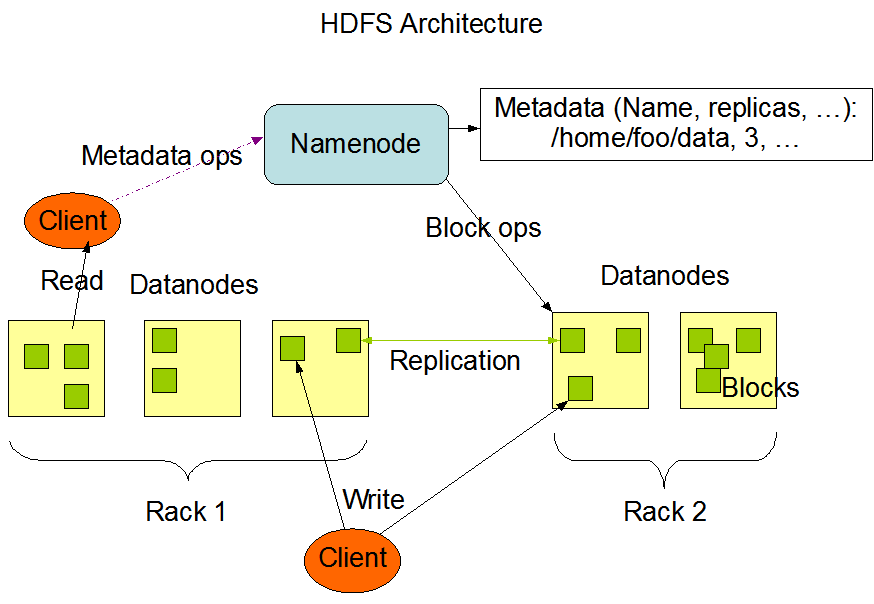
namenode管理namespace, 管理文件系统树状结构和文件/目录的metadata,这些信息以如下方式持久化在硬盘里:namespace image 和 edit log。同时block的metadata也存放在namd node,存放于内存中。前面提到过百万小文件,会占用300MB内存的例子。block信息为什么不持久化呢,因为它会变动,系统重启的时候会从datanode那里重新构建。
name node的备份有几种方式,一种是把持久化存放于硬盘的信息既写到本地硬盘也同时写到远程NFS mount。另一种方式是运行secondary namenode,它其实并没有扮演namenode的角色,而是周期性的merge namesapce image以及edit log来防止edit log过大。它会保存一份merged namespace image,一旦primary fail了,就把NFS上的metadata copy到secondary namenode上,这样secondary就成为了新的primary。
具体过程如下图所示,edit log和fsimage都是在硬盘中,edit log就是WAL(cassandra写操作也用到了WAL的手段,WAL很流行,可以单拉出来讲一次),fsimage是check point of the filesystem metadata。写的时候先写edit log,然后update in-memory representation of filesystem metadata(用来serve读请求),图中没有画出这部分操作。
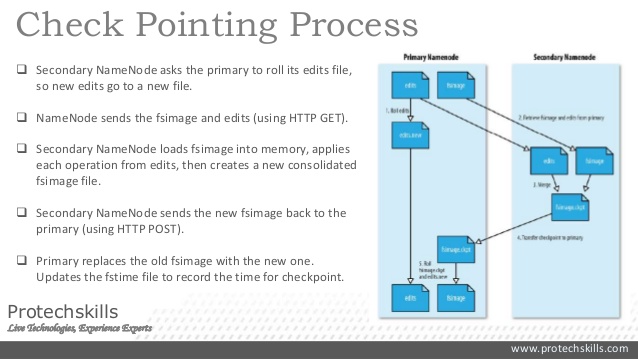
有没有更好的方法呢?上述方法没能提供HA, namenode仍然是single point of failure。新的primary需要(1)load namespace image into memory (2)replay edit log (3)从datanode那边接收足够的block reports(前文提到block信息是在内存中的)。这个过程有可能会话费30分钟或更久。client等不了啊~~
Hadoop 2提供了HA的support。namenode采用active-standby的配置方式:
- namenodes使用高可用共享存储来存edit log。active每次写入都会被standby读出并synchronize到自己的内存中。
- datanodes在发送block reports时会同时发给所有的name nodes,记住block mapping是在内存中。
- 客户端需要配置来handle namenode failover,其实就是watch zookeeper的leader election(参见我之前讲的zookeeper)
- 这样就不需要secondary namenode啦,standby取代了它的作用会周期性的产生check points
上面提到的共享存储主要指的是QJM(quorum journal manager),通常配置3个(当然我也见过50个node配5个journal nodes),写的时候需要满足quorum。
这样当active namenode fail时,standby可以马上扛住,因为latest edit log和 up-to-date block mapping都在内存中。
HDFS write

详细读写内参:https://blog.cloudera.com/blog/2015/02/understanding-hdfs-recovery-processes-part-1/
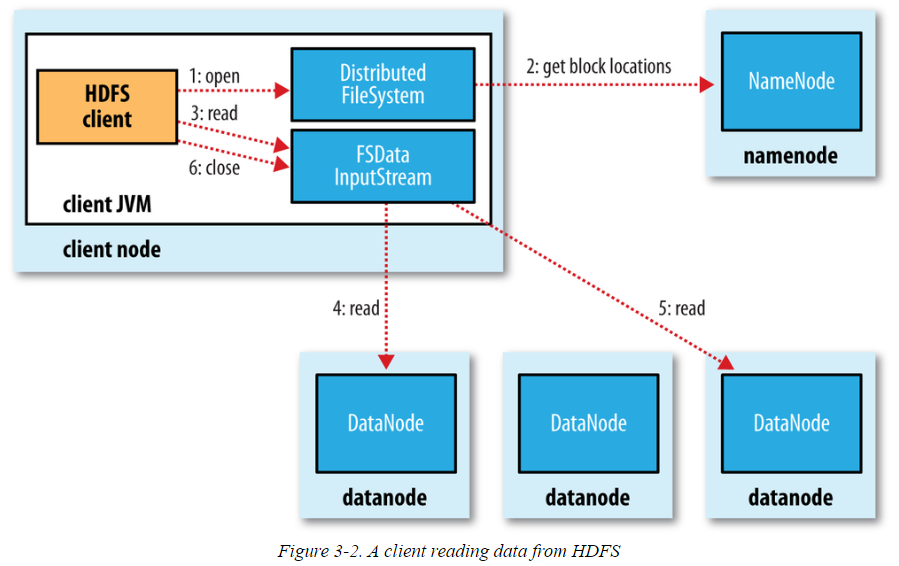
HDFS read
CLI Example
touch test.txt
hdfs dfs -mkdir /user/qingge/testdir
hdfs dfs -copyFromLocal ./test.txt /user/qingge/testdir/
hdfs dfs -ls /user/qingge/testdir/test.txt
hdfs dfs -chmod o-r /user/qingge/testdir/test.txt hdfs dfs -cat /user/qingge/testdir/test.txt | head -
hdfs dfs -mv /user/qingge/testdir/test.txt /user/qingge/testdir/test2.txt hdfs fsck /data/lalala -files -blocks -locations
hdfs fsck -blockId blk_10101010
HTTP 访问
(1) direct access: HDFS daemons server HTTP requests, embedded web servers in the name node and datanodes act as WebHDFS endpoionts.
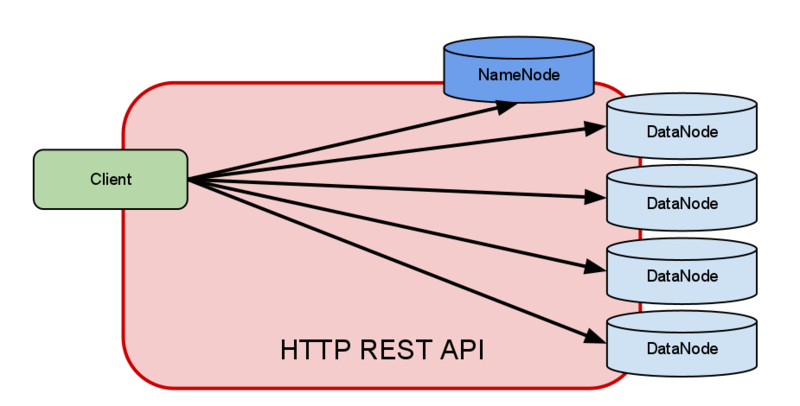
(2) proxy access: 中间有多个HDFS proxy,for strictr firewall and bandwidth-limiting policies, proxy和node之间使用RPC request和block request。
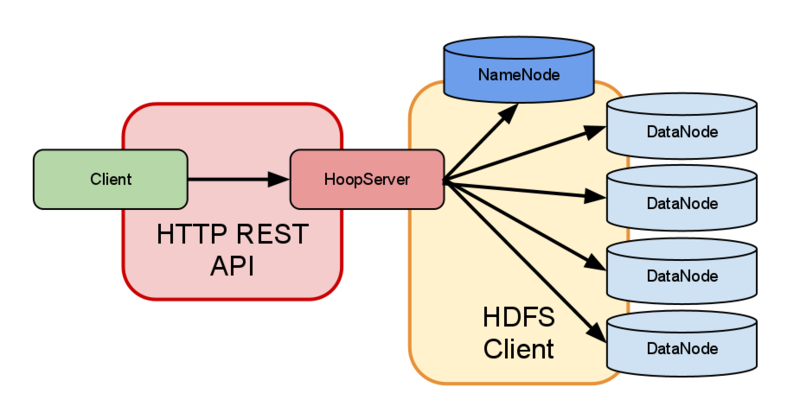
HDFS Federation
相当于namenode sharding了,如果不想用HA,然后namenode内存又要爆了怎么办,答分区呀,每个namenode从根目录下划走几个子目录,无线分区无线扩充,每个namenode之间井水不犯河水,一个爆了或废了丝毫不影响另一个。
思考题:
如果HDFS有1PB容量,每个block大小是64MB,平均的metadata大小是每个block300B,replication factor是3, 那么namenode最小的内存是多少呢?
答:差不多需要1.56G, 1024*1024*1024 MB/(64MB*3)*300B/(1024 * 1024 * 1024) = 1.56 GB
好,今天差不多就到这了~~ happy HDFS!
深入浅出Hadoop之HDFS的更多相关文章
- 深入浅出Hadoop实战开发(HDFS实战图片、MapReduce、HBase实战微博、Hive应用)
Hadoop是什么,为什么要学习Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- 搭建maven开发环境测试Hadoop组件HDFS文件系统的一些命令
1.PC已经安装Eclipse Software,测试平台windows10及Centos6.8虚拟机 2.新建maven project 3.打开pom.xml,maven工程项目的pom文件加载以 ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- Hadoop操作hdfs的命令【转载】
本文系转载,原文地址被黑了,故无法贴出原始链接. Hadoop操作HDFS命令如下所示: hadoop fs 查看Hadoop HDFS支持的所有命令 hadoop fs –ls 列出目录及文件信息 ...
- hadoop执行hdfs文件到hbase表插入操作(xjl456852原创)
本例中需要将hdfs上的文本文件,解析后插入到hbase的表中. 本例用到的hadoop版本2.7.2 hbase版本1.2.2 hbase的表如下: create 'ns2:user', 'info ...
- Hadoop学习-HDFS篇
HDFS设计基础与目标 硬件错误是常态.因此需要冗余 流式数据访问.即数据批量读取而非随机读写,Hadoop擅长做的是数据分析而不是事务处理(随机性的读写数据等). 大规模数据集 简单一致性模型.为了 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
随机推荐
- vim中的批量替换
VI中的批量替换 1) 文件内全部替换: :%s#abc#123#g (如文件内有#,可用/替换,:%s/abc/123/g) --注:把abc替换成123 (或者: %s/str ...
- hdu_1037(水题水疯了。。。史上最水)
#include<cstdio> #include<cstring> #include<algorithm> using namespace std; int ma ...
- flume1.8 开发指南学习感悟
概述: Apache Flume是一个分布式.可用的系统,用于从许多不同的sources有效的收集并移动大量日志数据用于集中存储数据. 架构及数据流动模型: flume实际上就是一个Agent.Age ...
- chorme浏览器的Access-Control-Allow-Origin拦截限制
今天在公司调试一个项目,这个项目的前后端是分离开的,也就是说前后端是在两个站点上的.我负责的前端页面在请求后端数据的时候数据可以拿到,但是chrome安全级别高,自动拦截跨域和站点的数据请求及交互,出 ...
- 废旧鼠标先别丢,用来学习nRF52832 的QDEC
刚发现nRF52832有一个 QDEC,SDK13.0中还有驱动,但是不太友好. 如果大家有废旧鼠标,建议拆一个编码器下来“学习”.鼠标的一般原理如下: 图一 图中那个SW4 ALPS EC10E ...
- 浅析const、let与var
以前无论声明变量还是常量,总是使用var一勺端,知道接触了es6之后,发现原来变量.常量的声明其实是很讲究的. 这里简单来谈谈var.const与let. 1.var.var声明的变量没有块级作用域, ...
- js object 常用方法总结
Object.assign(target,source1,source2,...) 该方法主要用于对象的合并,将源对象source的所有可枚举属性合并到目标对象target上,此方法只拷贝源对象的自身 ...
- GO开发[五]:golang结构体struct
Go结构体struct Go语言的结构体(struct)和其他语言的类(class)有同等的地位,但Go语言放弃了包括继承在内的大量面向对象特性,只保留了组合(composition)这个最基础的特性 ...
- WebService短信网关配置
第一步:WebService框架选择[以CXF为例] 1.下载地址:http://cxf.apache.org/download.html,请事先安装好JDK(本人使用的是apache-cxf-2.7 ...
- Navicat如何进行搜索筛选
分类: Navicat Navicat提供的"在数据库或模式中查找"功能用于一个数据库和/或模式内搜索表和视图的记录.Navicat"对象筛选"功能可以让用户在 ...