spark 33G表
http://192.168.2.51:4041
http://hadoop1:8088/proxy/application_1512362707596_0006/executors/

Executors
Summary
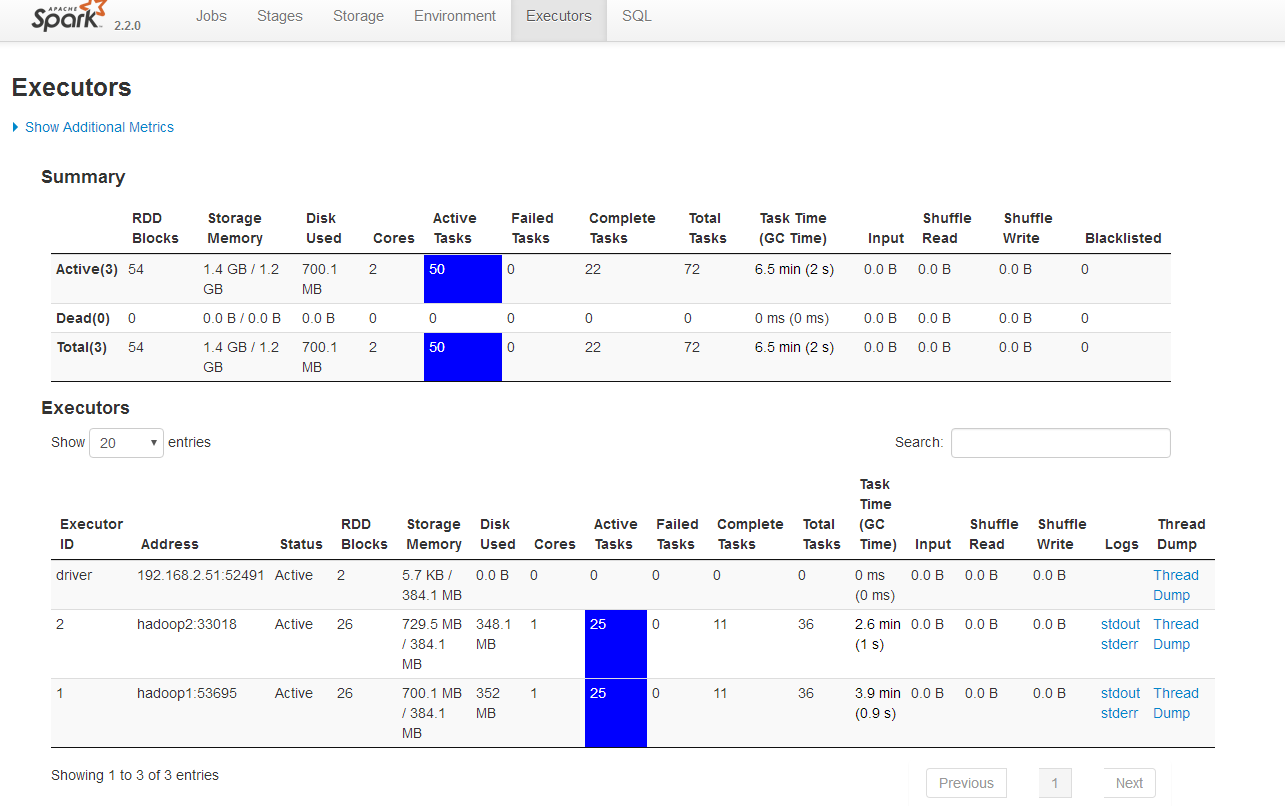
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(0) | 0 | 0.0 B / 0.0 B | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(3) | 54 | 1.4 GB / 1.2 GB | 700.1 MB | 2 | 50 | 0 | 22 | 72 | 6.5 min (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
20
40
60
100
All
entries
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Active | 26 | 729.5 MB / 384.1 MB | 348.1 MB | 1 | 25 | 0 | 11 | 36 | 2.6 min (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Active | 26 | 700.1 MB / 384.1 MB | 352 MB | 1 | 25 | 0 | 11 | 36 | 3.9 min (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
from pyspark.sql import SparkSession my_spark = SparkSession \
.builder \
.appName("myAppYarn-10g") \
.master('yarn') \
.config("spark.mongodb.input.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article") \
.config("spark.mongodb.output.uri", "mongodb://pyspark_admin:admin123@192.168.2.50/recommendation.article") \
.getOrCreate() db_rows = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").load().collect()
Summary
| RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Blacklisted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Active(3) | 31 | 748.4 MB / 1.2 GB | 75.7 MB | 2 | 27 | 0 | 0 | 27 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Dead(2) | 56 | 1.5 GB / 768.2 MB | 790.3 MB | 2 | 0 | 0 | 77 | 77 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
| Total(5) | 87 | 2.3 GB / 1.9 GB | 865.9 MB | 4 | 27 | 0 | 77 | 104 | 2.7 h (2 s) | 0.0 B | 0.0 B | 0.0 B | 0 |
Executors
20
40
60
100
All
entries
| Executor ID | Address | Status | RDD Blocks | Storage Memory | Disk Used | Cores | Active Tasks | Failed Tasks | Complete Tasks | Total Tasks | Task Time (GC Time) | Input | Shuffle Read | Shuffle Write | Logs | Thread Dump |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| driver | 192.168.2.51:52491 | Active | 2 | 5.7 KB / 384.1 MB | 0.0 B | 0 | 0 | 0 | 0 | 0 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 4 | hadoop2:34394 | Active | 12 | 315.9 MB / 384.1 MB | 0.0 B | 1 | 11 | 0 | 0 | 11 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 3 | hadoop1:39620 | Active | 17 | 432.5 MB / 384.1 MB | 75.7 MB | 1 | 16 | 0 | 0 | 16 | 0 ms (0 ms) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 2 | hadoop2:33018 | Dead | 27 | 758.7 MB / 384.1 MB | 390.4 MB | 1 | 0 | 0 | 38 | 38 | 1.3 h (1 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump | |
| 1 | hadoop1:53695 | Dead | 29 | 775.9 MB / 384.1 MB | 399.9 MB | 1 | 0 | 0 | 39 | 39 | 1.4 h (0.9 s) | 0.0 B | 0.0 B | 0.0 B | Thread Dump |
Logs for container_1512362707596_0006_02_000002 |
|
|
Showing 4096 bytes. Click here for full log Manager: Dropping block taskresult_48 from memory |
|
spark 33G表的更多相关文章
- 基于spark实现表的join操作
1. 自连接 假设存在如下文件: [root@bluejoe0 ~]# cat categories.csv 1,生活用品,0 2,数码用品,1 3,手机,2 4,华为Mate7,3 每一行的格式为: ...
- 利用spark将表中数据拆分
i# coding:utf-8from pyspark.sql import SparkSession import os if __name__ == '__main__': os.environ[ ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
- Databricks 第6篇:Spark SQL 维护数据库和表
Spark SQL 表的命名方式是db_name.table_name,只有数据库名称和数据表名称.如果没有指定db_name而直接引用table_name,实际上是引用default 数据库下的表. ...
- Spark SQL概念学习系列之如何使用 Spark SQL(六)
val sqlContext = new org.apache.spark.sql.SQLContext(sc) // 在这里引入 sqlContext 下所有的方法就可以直接用 sql 方法进行查询 ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
- Spark入门之DataFrame/DataSet
目录 Part I. Gentle Overview of Big Data and Spark Overview 1.基本架构 2.基本概念 3.例子(可跳过) Spark工具箱 1.Dataset ...
- 6.3 使用Spark SQL读写数据库
Spark SQL可以支持Parquet.JSON.Hive等数据源,并且可以通过JDBC连接外部数据源 一.通过JDBC连接数据库 1.准备工作 ubuntu安装mysql教程 在Linux中启动M ...
随机推荐
- NOIP一系列模拟赛小结
NOIP越发接近了,于是自己也跟着机房的几位师兄一起做了几次NOIP模拟赛,收获颇多. #1-T1:求点集中的点能否只用三条与坐标轴平行的直线就能全部被经过,其实只要将横纵坐标排序后逐个点检查下就行. ...
- BZOJ 1197: [HNOI2006]花仙子的魔法【DP】
Description 相传,在天地初成的远古时代,世界上只有一种叫做“元”的花.接下来,出 现了一位拥有魔法的花仙子,她能给花附加属性,从此,“元”便不断变异,产生了大千世界千奇百怪的各种各样的花. ...
- mysql查询死锁,执行语句,服务器状态等语句集合
[转]http://blog.csdn.net/enweitech/article/details/52447006
- 【shell】shell编程(四)-循环语句
上篇我们学习了shell中条件选择语句的用法.接下来本篇就来学习循环语句.在shell中,循环是通过for, while, until命令来实现的.下面就分别来看看吧. for for循环有两种形式: ...
- 在Fedora 22下安装配置RealVNC Server 5.2.3的经验总结
RealVNC是目前功能最全.性能最好的VNC商业软件套件,很多时候为了确保性能和功能的统一,还是大量地在使用RealVNC.最近在Fedora 22工作站上安装RealVNC Server 5.2. ...
- [Bzoj3675][Apio2014]序列分割(斜率优化)
3675: [Apio2014]序列分割 Time Limit: 40 Sec Memory Limit: 128 MBSubmit: 4021 Solved: 1569[Submit][Stat ...
- 23. 客户默认选项(Default Customer Options)
Editing Email Templates Email Sender Contact Us
- Effective C++ Item 47 请使用 traits classes 表现类型信息
本文为senlie原创.转载请保留此地址:http://blog.csdn.net/zhengsenlie 经验:Traits classes 使得"类型相关信息"在编译期可用.它 ...
- BUPT复试专题—比较奇偶数(2010)
https://www.nowcoder.com/practice/188472f474d5421cb8218b8ad561023b?tpId=67&tqId=29636&rp=0&a ...
- [WASM] Access WebAssembly Memory Directly from JavaScript
While JavaScript has a garbage-collected heap, WebAssembly has a linear memory space. Nevertheless u ...