算法导论 第八章 线性时间排序(python)
比较排序:各元素的次序依赖于它们之间的比较{插入排序O(n**2) 归并排序O(nlgn) 堆排序O(nlgn)快速排序O(n**2)平均O(nlgn)}
本章主要介绍几个线性时间排序:(运算排序非比较排序)计数排序O(k+n)基数排序O()
第一节:用决策树分析比较排序的下界
决策树:倒数第二层满,第一层可能满的二叉树,它用来表示所有元素的比较操作{于此来分析下界},忽略控制,移动操作
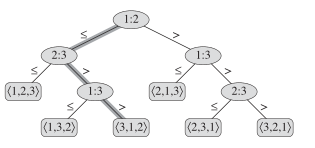
1:2 #A[1]和A[2]比 <= 走左边 >走右边
<3,1,2> 最后的结果 下标对应排序顺序
如A=[5,6,4]-->1:2 <= -->2:3 > -->1:3 > ---><3,1,2>[4,5,6]
看图可知有6钟可能的对比3!(也就是n!)
高度是他要对比的次数h = Ω(n lg n)
n! <= 2**h#数据结构内容
推出8.2:堆排序和归并排序都是渐进最优的比较排序算法
二计数排序
基本思想:对于每个元素x,确定小于x的元素个数
适用范围:小范围 x的跨度比较小的整数排序#跨度过大如0-1000辅助函数C[1000]
稳定性:稳定
时间复杂度:Θ(k+n)
实现:
def COUNTING_SORT(A,B,k):
#A要排序的函数
#B保存排序后的结果
#k A中x的最大值 [0,k] C = list() #临时保存记录x前面的个数
for i in range(k+1):#[0,k]
C.append(0) for j in range(len(A)):
C[A[j]] += 1 #记录A[j] == i C[i]记一个数 这是一个转换 似于hash的思想 for i in range(1,k+1):
C[i] = C[i] + C[i-1] #计算小于x的元素个数 for j in range(len(A)-1,-1,-1): # 从后想前借B排序[0,len(A))
#print(C[A[j]])
B[C[A[j]]-1] = A[j] #B下标从0开始
C[A[j]] -= 1 if __name__ == "__main__":
A = [2,5,3,0,2,3,0,3]
B = list()
for i in range(len(A)): #B初始化?还有没有别的方法
B.append(0)
COUNTING_SORT(A,B,5)
print(B) '''
>>>
============= RESTART: F:/python/algorithms/8_2_counting_sort.py =============
[0, 0, 2, 2, 3, 3, 3, 5] win7 python3.5.1
'''
8.3基数排序(radix sort)
基本思想:按关键字的各个值来排序
排序方式:LSD 由右向左排; MSD 由左向右排
稳定性:稳定
基数:计算的基数就是基本的单元数。比如10进制的基数就是10,二进制的基数就2,八进制的基数是8等等
基数排序:一位一位的对比排序(msd)

arr = list()
res = list()
hash = list()
n = int() def maxbit():
_max = 0
temp = list()
for i in arr:
temp.append(i) for i in range(n):
tt = 1
while (temp[i] //10) >0:
tt += 1
temp[i] //= 10
if _max < tt:
_max = tt print("最大%d位"%_max)
return _max def radixSort():
for i in range(n):
res.append(0)#初始化为0
nbit = maxbit() #最大的数有多少位
radix = 1
#计数排序
for j in range(10):
hash.append(0) for i in range(1,nbit+1):#[1,3]
for j in range(10):
hash[j] = 0
for j in range(n):
tmp = (arr[j]//radix) % 10
hash[tmp] += 1
for j in range(1,10):
hash[j] += hash[j-1]
for j in range(n-1,-1,-1):
tmp = (arr[j]//radix) %10
hash[tmp] -= 1
#print(hash[tmp])
res[hash[tmp]] = arr[j] for j in range(n):
arr[j] = res[j]
print(arr)
radix *= 10; if __name__ == "__main__":
n = int(input("输入元素个数:"))
print("输入%d个元素"%n)
for i in range(n):
arr.append(int(input("第"+str(i+1)+'个:')))
radixSort()
print("排序后",arr)
'''
============== RESTART: F:/python/algorithms/8_3_radix_sort.py ==============
输入元素个数:5
输入5个元素
第1个:54321
第2个:1
第3个:4321
第4个:21
第5个:321
最大5位
[54321, 1, 4321, 21, 321]
[1, 54321, 4321, 21, 321]
[1, 21, 54321, 4321, 321]
[1, 21, 321, 54321, 4321]
[1, 21, 321, 4321, 54321]
排序后 [1, 21, 321, 4321, 54321]
>>> 环境:win7 + python3.5.1
'''
8.4桶排序
思想:同hash = n //x
稳定性:
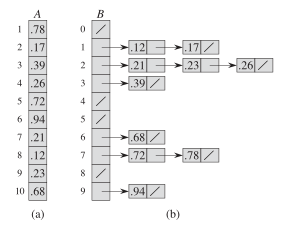
def bucketSort(a,max):
#a 待排序list
#数组中的最大值的范围
if len(a) == 0 and max <1 :
return
buckets = list() #建立容纳max个数的list
for i in range(max):
buckets.append(0) #初始化 #计数
for i in range(len(a)):
buckets[a[i]] += 1 #排序
j = 0
for i in range(max):
while buckets[i] >0:
buckets[i] -= 1
a[j] = i
j += 1 if __name__ == "__main__":
a = [8,2,3,4,3,6,6,3,9]
print("排序前a:",a)
bucketSort(a,10) #桶排序
print("排序后a:",a) '''
============== RESTART: F:/python/algorithms/8_4_bucket_sort.py ==============
排序前a: [8, 2, 3, 4, 3, 6, 6, 3, 9]
排序后a: [2, 3, 3, 3, 4, 6, 6, 8, 9]
>>> win7 + python3.5.1
'''
参考引用:
http://www.wutianqi.com/?p=2378
https://zh.wikipedia.org/wiki/%E5%9F%BA%E6%95%B0_(%E6%95%B0%E5%AD%A6)
http://www.cnblogs.com/skywang12345/p/3602737.html#a32
算法导论 第八章 线性时间排序(python)的更多相关文章
- 算法导论学习之线性时间求第k小元素+堆思想求前k大元素
对于曾经,假设要我求第k小元素.或者是求前k大元素,我可能会将元素先排序,然后就直接求出来了,可是如今有了更好的思路. 一.线性时间内求第k小元素 这个算法又是一个基于分治思想的算法. 其详细的分治思 ...
- 《算法导论》 — Chapter 8 线性时间排序
序 到目前为止,关于排序的问题,前面已经介绍了很多,从插入排序.合并排序.堆排序以及快速排序,每一种都有其适用的情况,在时间和空间复杂度上各有优势.它们都有一个相同的特点,以上所有排序的结果序列,各个 ...
- "《算法导论》之‘排序’":线性时间排序
本文参考自一博文与<算法导论>. <算法导论>之前介绍了合并排序.堆排序和快速排序的特点及运行时间.合并排序和堆排序在最坏情况下达到O(nlgn),而快速排序最坏情况下达到O( ...
- Python线性时间排序——桶排序、基数排序与计数排序
1. 桶排序 1.1 范围为1-M的桶排序 如果有一个数组A,包含N个整数,值从1到M,我们可以得到一种非常快速的排序,桶排序(bucket sort).留置一个数组S,里面含有M个桶,初始化为0.然 ...
- 《算法导论》 — Chapter 7 高速排序
序 高速排序(QuickSort)也是一种排序算法,对包括n个数组的输入数组.最坏情况执行时间为O(n^2). 尽管这个最坏情况执行时间比較差.可是高速排序一般是用于排序的最佳有用选择.这是由于其平均 ...
- 算法导论 第一章and第二章(python)
算法导论 第一章 算法 输入--(算法)-->输出 解决的问题 识别DNA(排序,最长公共子序列,) # 确定一部分用法 互联网快速访问索引 电子商务(数值算 ...
- 《算法导论》读书笔记之排序算法—Merge Sort 归并排序算法
自从打ACM以来也算是用归并排序了好久,现在就写一篇博客来介绍一下这个算法吧 :) 图片来自维基百科,显示了完整的归并排序过程.例如数组{38, 27, 43, 3, 9, 82, 10}. 在算法导 ...
- 排序算法的C语言实现(下 线性时间排序:计数排序与基数排序)
计数排序 计数排序是一种高效的线性排序. 它通过计算一个集合中元素出现的次数来确定集合如何排序.不同于插入排序.快速排序等基于元素比较的排序,计数排序是不需要进行元素比较的,而且它的运行效率要比效率为 ...
- 算法导论 第九章 中位数和顺序统计量(python)
第i个顺序统计量:该集合中第i小的元素(建集合排序后第i位 当然算法可以不排序) 中位数:集合中的中点元素 下中位数 上中位数 9.1最大值和最小值 单独的max或min每个都要扫一遍 n-1次比较 ...
随机推荐
- iOS RSA (Objc)
/* RSA.h @author: ideawu @link: https://github.com/ideawu/Objective-C-RSA */ #import <Foundation/ ...
- 使用c++的一些建议
1: 不要使用宏,用const或enum定义常量 用inline避免函数的额外调用(使用inline的函数,块里面尽量不要使用循环和递归) 用template去荷花一些函数或者类型 用namespac ...
- C++ 的浅拷贝和深拷贝(结构体)
关于浅拷贝和深拷贝这个问题遇上的次数不多,这次遇上整理一下,先说这样一个问题,关于浅拷贝的问题,先从最简单的说起. 假设存在一个结构体: struct Student { string name; i ...
- 利用VS自带的dotfuscator混淆代码的学习
对于一些原创的敏感代码,我们可以通过简单的重命名混淆使得别人难以真正理解执行原理.这一点,使用VS自带的dotfuscator即可实现. 如上图所示,你可以自定义选择哪些类被排除重命名,内置的规则中, ...
- JSP与Servlet的编解码
一.java web中涉及编解码的地方 (1)浏览器端向后台发起请求时:URL.Cookie.Parameter: (2)后台响应返回数据时:页面编码,数据库数据编码:
- subline应用之python
一交互式命令操作快捷键:在安装SublimeREPL插件后,CTRL+~/CTRL+B分别在命令行交互式和编译模式之间进行选择. 为SublimeREPL配置快捷键(每次运行程序必须用鼠标去点工具栏- ...
- Java_静态变量
class c1c { private static int num = 0; private static double pi = 3.14; private double radius; priv ...
- Oracle、MySQL和SqlServe分页查询的语句区别
★先来定义分页语句将要用到的几个参数: int currentPage ; //当前页 int pageRecord ; //每页显示记录数 以之前的ADDRESSBOOK数据表为例(每页显示10条记 ...
- 字符串、数组、json
一.字符串 string 1.字符串的定义: (1).var s="haha"; (2).var s=new string ("hello") 对象形式定义 2 ...
- 微信小程序 图片加载失败处理方案
小程序端展示网络资源图片可能会失败,下面介绍一种自己的处理方法 1. js文件中判断图片 url 是否存在,存在则正常显示,不存在则替换url为本地默认图片 2. 当图片 url 存在,但是加载失败时 ...