spark streaming 踩过的那些坑
- 系统背景
- spark streaming + Kafka高级API receiver
- 目前资源分配(现在系统比较稳定的资源分配),独立集群
--driver-memory 50G
--executor-memory 8G
--num-executors 11
--executor-cores 5
- 广播变量
1. 广播变量的初始化
1.1.executor端,存放广播变量的对象使用非静态,因为静态变量是属于类的,不能使用构造函数来初始化。在executor端使用静态的时候,它只是定义的时候的一个状态,而在初始化时设置的值取不到。而使用非静态的对象,其构造函数的初始化在driver端执行,故在集群可以取到广播变量的值。
2. 广播变量的释放
2.1.当filter增量为指定大小时,进行广播,虽然广播的是同一个对象,但是,广播的ID是不一样的,而且ID号越来越大,这说明对于广播来说,它并不是一个对象,而只是名字一样的不同对象,如果不对广播变量进行释放,将会导致executor端内存占用越来越大,而一直没有使用的广播变量,被进行GC,会导致GC开销超过使用上线,导致程序失败。
2.2.解决方案:这广播之前,先调用unpersist()方法,释放不用的广播变量
- 使用Kafka 的高级API receiver
1. 在使用receiver高级API时,由于receiver、partition、executor的分配关系,经常会导致某个executor任务比较繁重,进而影响整体处理速度
1.1.最好是一个receiver对应一个executor
2. 由于前段时间数据延迟比较严重,就想,能不能让所有executor的cores都去处理数据?所以调整receiver为原来的四倍,结果系统启动时,就一下冲上来非常大的数据量,导致系统崩溃,可见,receiver不仅跟partition的分配有关,还跟数据接收量有关
3. 在实际处理数据中,由于消息延迟,可以看到,有的topic处理速度快有的慢,原因分析如下:
3.1.跟消息的格式有关,有的是序列化文件,有的事json格式,而json的解析相对于比较慢
3.2.有时候拖累整个集群处理速度的,除了大量数据,还跟单条数据的大小有关
以下是程序跑挂的一些异常,和原因分析
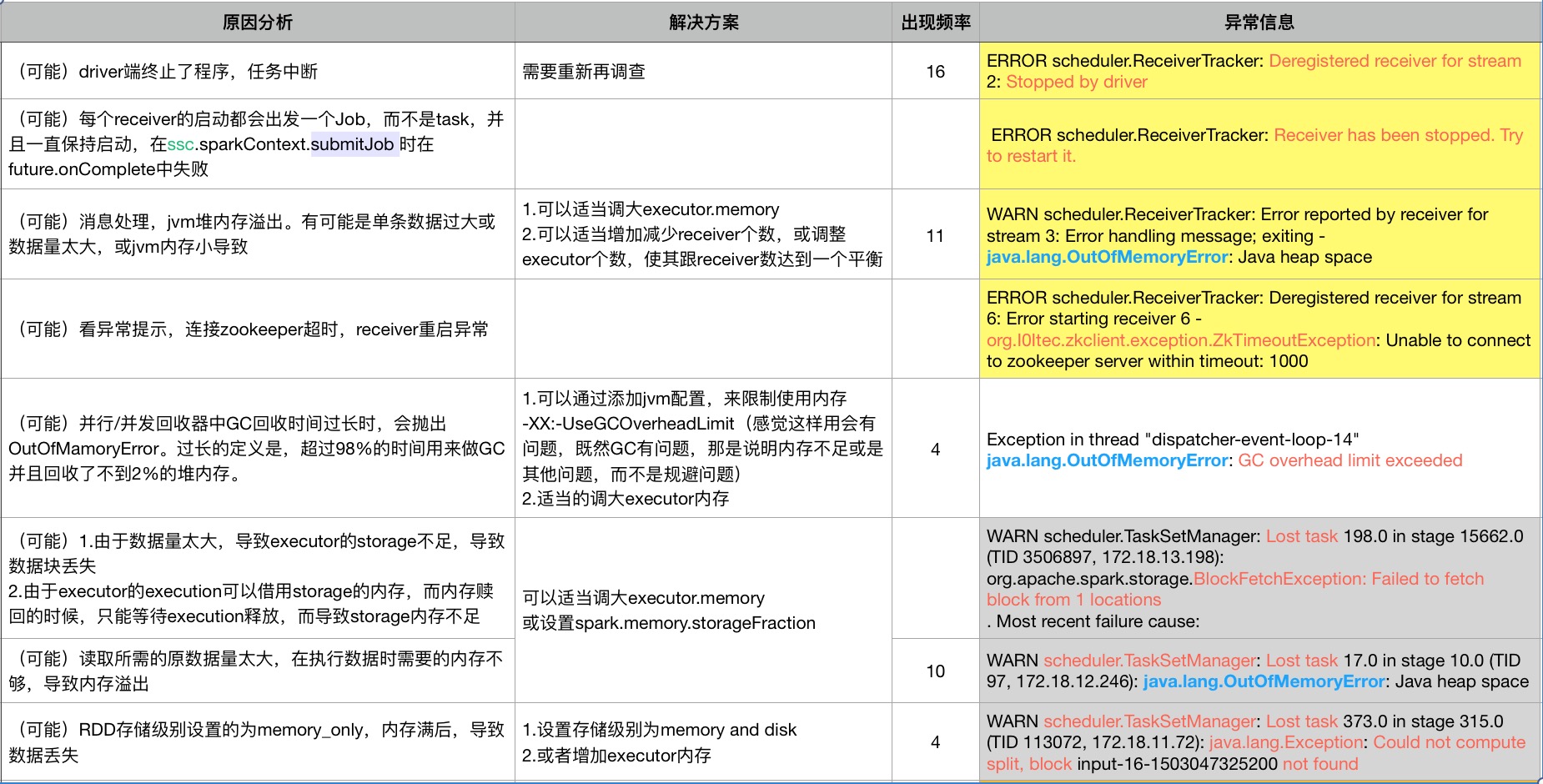

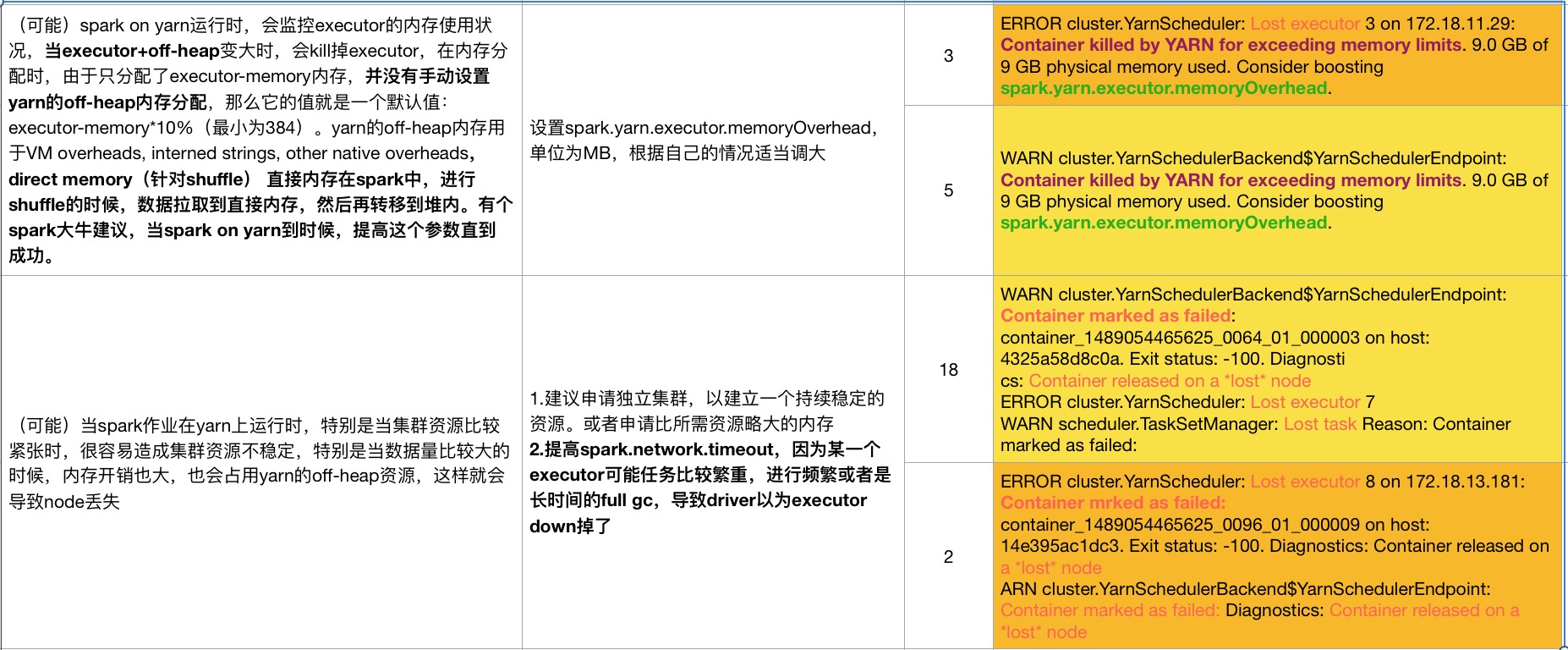
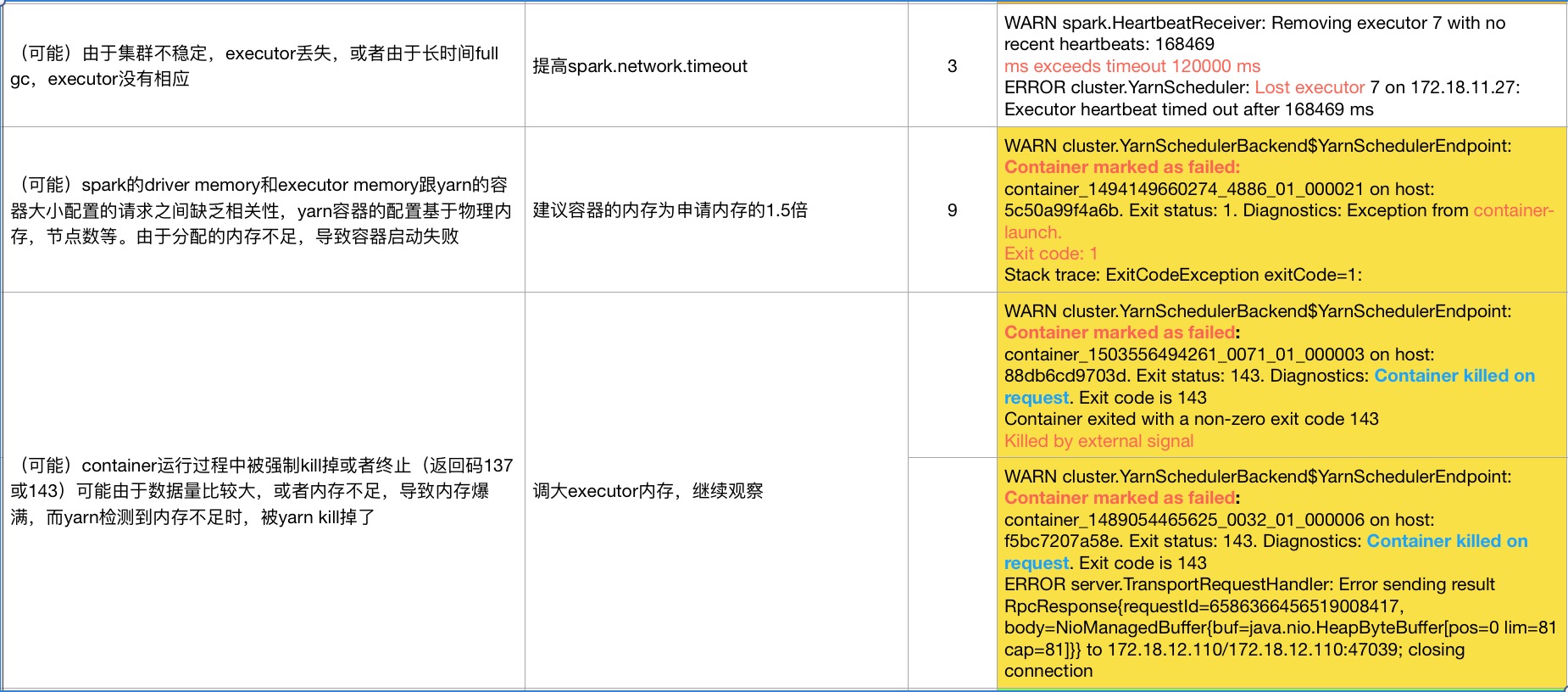


问题矫正:
第一张图片的,解决方案的倒数第二个, spark.memory.storageFraction(动态内存的百分比设置),应该为spark.storage.memoryFraction(静态内存分配的设置) (由于原文档丢失,导致无法修改文档。)
如果有什么问题,欢迎大家指出,共同探讨,共同进步
spark streaming 踩过的那些坑的更多相关文章
- spark streaming 消费 kafka入门采坑解决过程
kafka 服务相关的命令 # 开启kafka的服务器bin/kafka-server-start.sh -daemon config/server.properties &# 创建topic ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Spark streaming消费Kafka的正确姿势
前言 在游戏项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从kafka中不 ...
- Spark Streaming实时写入数据到HBase
一.概述 在实时应用之中,难免会遇到往NoSql数据如HBase中写入数据的情景.题主在工作中遇到如下情景,需要实时查询某个设备ID对应的账号ID数量.踩过的坑也挺多,举其中之一,如一开始选择使用NE ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- Redis上踩过的一些坑
来自: http://blog.csdn.net//chenleixing/article/details/50530419 上上周和同事(龙哥)参加了360组织的互联网技术训练营第三期,美团网的DB ...
- 【自动化】基于Spark streaming的SQL服务实时自动化运维
设计背景 spark thriftserver目前线上有10个实例,以往通过监控端口存活的方式很不准确,当出故障时进程不退出情况很多,而手动去查看日志再重启处理服务这个过程很低效,故设计利用Spark ...
随机推荐
- COT2 - Count on a tree II(树上莫队)
COT2 - Count on a tree II You are given a tree with N nodes. The tree nodes are numbered from 1 to N ...
- 递推DP UVA 473 Raucous Rockers
题目传送门 题意:n首个按照给定顺序存在m张光盘里,每首歌有播放时间ti,并且只能完整的存在一张光盘里,问最多能存几首歌 分析:类似01背包和完全背包,每首歌可存可不存,存到下一张光盘的情况是当前存不 ...
- 输入一个秒数,要求转换为XX小时XX分XX秒的格式输出出来;
package arithmetic; import java.util.Scanner; import org.junit.Test; public class Test02 { /** * 输入一 ...
- JMeter(十三)进行简单的数据库(mysql)压力测试
1.点击测试计划,再点击“浏览”,把JDBC驱动添加进来: 注:JDBC驱动一般的位置在java的安装地址下,路径类似于: \java\jre\lib\ext 文件为:mysql-connect ...
- 173 Binary Search Tree Iterator 二叉搜索树迭代器
实现一个二叉搜索树迭代器.你将使用二叉搜索树的根节点初始化迭代器.调用 next() 将返回二叉搜索树中的下一个最小的数.注意: next() 和hasNext() 操作的时间复杂度是O(1),并使用 ...
- framework7 点取消后还提交表单解决方案
$$('form.ajax-submit').on('submitted', function (e) { var xhr = e.detail.xhr; // actual XHR object v ...
- Oracle 用到的服务
1.Oracle ORCL VSS Writer Service Oracle卷映射拷贝写入服务,VSS(Volume ShadowCopy Service)能够让存储基础设备(比如磁盘,阵列等)创建 ...
- html5表单新增元素与属性2
1.标签的control属性 在html5中,可以在标签内部放置一个表单元素,并且通过该标签的control属性来访问该表单元素. <script> function setValue() ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- iOS:swift :可选类型
import UIKit /*: 可选类型 * 可选类型表示变量可以有值, 也可以没有值 * C 和 Objective-C 中并没有可选类型这个概念 * Swift中只有可选类型才可以赋值为nil ...