ES-自然语言处理之中文分词器
前言
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块。不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性、句法树等模块的效果。当然分词只是一个工具,场景不同,要求也不同。
在人机自然语言交互中,成熟的中文分词算法能够达到更好的自然语言处理效果,帮助计算机理解复杂的中文语言。
根据中文分词实现的原理和特点,可以分为:
- 基于词典分词算法
- 基于理解的分词方法
- 基于统计的机器学习算法
基于词典分词算法
基于词典分词算法,也称为字符串匹配分词算法。该算法是按照一定的策略将待匹配的字符串和一个已经建立好的"充分大的"词典中的词进行匹配,若找到某个词条,则说明匹配成功,识别了该词。常见的基于词典的分词算法为一下几种:
- 正向最大匹配算法。
- 逆向最大匹配法。
- 最少切分法。
- 双向匹配分词法。
基于词典的分词算法是应用最广泛,分词速度最快的,很长一段时间内研究者在对对基于字符串匹配方法进行优化,比如最大长度设定,字符串存储和查找方法以及对于词表的组织结构,比如采用TRIE索引树,哈希索引等。
这类算法的优点:速度快,都是O(n)的时间复杂度,实现简单,效果尚可。
算法的缺点:对歧义和未登录的词处理不好。
基于理解的分词方法
这种分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果,其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象,它通常包含三个部分:分词系统,句法语义子系统,总控部分,在总控部分的协调下,分词系统可以获得有关词,句子等的句法和语义信息来对分词歧义进行判断,它模拟来人对句子的理解过程,这种分词方法需要大量的语言知识和信息,由于汉语言知识的笼统、复杂性,难以将各种语言信息组成及其可以直接读取的形式,因此目前基于理解的分词系统还在试验阶段。
基于统计的机器学习算法
这类目前常用的算法是HMM,CRF,SVM,深度学习等算法,比如stanford,Hanlp分词工具是基于CRF算法。以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文,具备良好的学习能力,因此对歧义词和未登录词的识别都具有良好的效果。
Nianwen Xue在其论文中《Combining Classifier for Chinese Word Segmentation》中首次提出对每个字符进行标注,通过机器学习算法训练分类器进行分词,在论文《Chinese word segmentation as character tagging》中较为详细地阐述了基于字标注的分词法。
算法优点:能很好处理歧义和未登录词问题,效果比前一类效果好
算法缺点: 需要大量的人工标注数据,以及较慢的分词速度
目前常见的中文分词分类器
现在,常见的分词器都是使用机器学习算法和词典相结合的算法,一方面能够提高分词准确率,另一方面能够改善领域适应性。
随着深度学习的兴起,也出现了基于神经网络的分词器,例如有研究人员尝试使用双向LSTM+CRF实现分词器,其本质上是序列标注,所以有通用性,命名实体识别等都可以使用该模型,据报道其分词器字符准确率可以高达97.5%,算法框架的思路与论文《Neural Architectures for Named Entity Recogintion》类似,利用该框架可以实现中文分词,如下图所示:
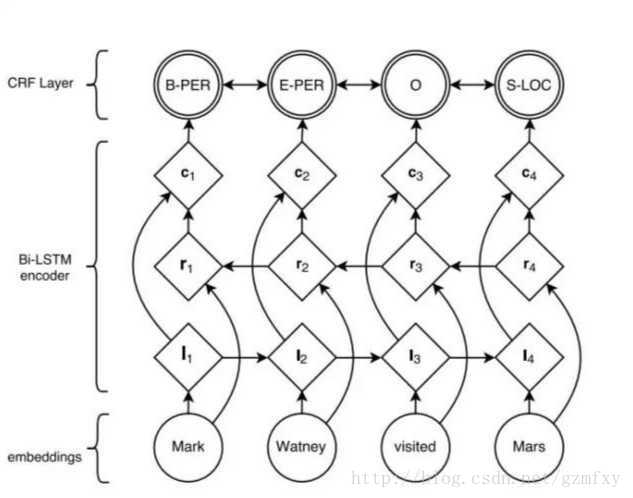
首先对语料进行字符嵌入,将得到的特征输入给双向的LSTM,然后加一个CRF就得到标注结果。
分词器目前存在的问题
目前中文分词难点主要有三个:
分词标准:比如人名,在哈工大的标准中姓和名是分开的,但是在Hanlp中是合在一起的,这需要根据不同的需求制定不同的分词标准。
- 歧义:对于同一个待切分字符串存在多个分词结果。歧义又分为组合歧义,交集型歧义和真歧义三种分类。
- 组合型歧义:分词是有不同的粒度的,指某个词条中的一部分也可以切分未一个独立的词条,比如“中华人民共和国”,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是
中华/人民/共和国 - 交集型歧义:在
郑州天和服装厂中,天和是厂名,是一个专有名词,和服也是一个词,它们共用了和字 - 真歧义:本身的语法和语义都没有问题,即便采用人工切分也会产生同样的歧义,只有通过上下文的语义环境才能给出正确的切分结果,例如:对于句子
美国会通过对台售武法案,既可以切分成美国/会/通过台售武法案也可以切分成美/国会/通过台售武法案。
- 组合型歧义:分词是有不同的粒度的,指某个词条中的一部分也可以切分未一个独立的词条,比如“中华人民共和国”,粗粒度的分词就是“中华人民共和国”,细粒度的分词可能是
新词:也称未被词典收录的词,该问题的解决依赖于人们对分词技术和汉语语言结构进一步认识。
一般在搜索引擎中,构建索引时和查询时会使用不同的分词算法,常用的方案是,在索引的时候,使用细粒度的分词以保证召回,在查询的时候使用粗粒度的分词以保证精度。
分词工具介绍
中科院计算所NLPIR:NLPIR能够全方位多角度满足应用者对大数据文本的处理需求,包括大数据完整的技术链条:网络抓取、正文提取、中英文分词、词性标注、实体抽取、词频统计、关键词提取、语义信息抽取、文本分类、情感分析、语义深度扩展、繁简编码转换、自动注音、文本聚类等。
NLPIR所有功能模块全部备有对应的二次开发接口(动态链接库.dll,.so,及静态链接库等形式),平台的各个中间件API可以无缝地融合到客户的各类复杂应用系统之中,可兼容Windows,Linux, Android,Maemo5, FreeBSD,麒麟等不同操作系统,开发者可使用Java,C/C++,C#, Python,Php, R等各类主流开发语言调用其所有功能。哈工大的LTP:语言技术平台(Language Technology Platform,LTP)是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块(包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library, DLL)的应用程序接口、可视化工具,并且能够以网络服务(Web Service)的形式进行使用。
ansj分词器:这是一个基于n-Gram+CRF+HMM的中文分词的java实现;分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上;目前实现了中文分词、 中文姓名识别 、 用户自定义词典、关键字提取、自动摘要、关键字标记等功能。可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目。
- 清华大学THULAC:THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。THULAC具有如下几个特点:
- 能力强。利用我们集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。
- 准确率高。该工具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%,与该数据集上最好方法效果相当。
- 速度较快。同时进行分词和词性标注速度为300KB/s,每秒可处理约15万字。只进行分词速度可达到1.3MB/s。
斯坦福分词器:作为众多斯坦福自然语言处理中的一个包, Java实现的CRF算法。可以直接使用训练好的模型,也提供训练模型接口。
Hanlp分词器:求解的是最短路径。优点:开源、有人维护、可以解答。原始模型用的训练语料是人民日报的语料,当然如果你有足够的语料也可以自己训练。
结巴分词:基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
KCWS分词器(字嵌入+Bi-LSTM+CRF) https://github.com/koth/kcws):本质上是序列标注,这个分词器用人民日报的80万语料,据说按照字符正确率评估标准能达到97.5%的准确率,各位感兴趣可以去看看。
ZPar:新加坡科技设计大学开发的中文分词器,包括分词、词性标注和Parser,支持多语言,据说效果是公开的分词器中最好的,C++语言编写。
IKAnalyzer:IKAnalyzer是一个开源的,基于java的语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
ES-自然语言处理之中文分词器的更多相关文章
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- ES[7.6.x]学习笔记(七)IK中文分词器
在上一节中,我们给大家介绍了ES的分析器,我相信大家对ES的全文搜索已经有了深刻的印象.分析器包含3个部分:字符过滤器.分词器.分词过滤器.在上一节的例子,大家发现了,都是英文的例子,是吧?因为ES是 ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- Es学习第五课, 分词器介绍和中文分词器配置
上课我们介绍了倒排索引,在里面提到了分词的概念,分词器就是用来分词的. 分词器是ES中专门处理分词的组件,英文为Analyzer,定义为:从一串文本中切分出一个一个的词条,并对每个词条进行标准化.它由 ...
- es学习(三):分词器介绍以及中文分词器ik的安装与使用
什么是分词 把文本转换为一个个的单词,分词称之为analysis.es默认只对英文语句做分词,中文不支持,每个中文字都会被拆分为独立的个体. 示例 POST http://192.168.247.8: ...
- elasticsearch教程--中文分词器作用和使用
概述 本文都是基于elasticsearch安装教程 中的elasticsearch安装目录(/opt/environment/elasticsearch-6.4.0)为范例 环境准备 ·全新最小 ...
- Elasticsearch笔记六之中文分词器及自定义分词器
中文分词器 在lunix下执行下列命令,可以看到本来应该按照中文"北京大学"来查询结果es将其分拆为"北","京","大" ...
- 转:从头开始编写基于隐含马尔可夫模型HMM的中文分词器
http://blog.csdn.net/guixunlong/article/details/8925990 从头开始编写基于隐含马尔可夫模型HMM的中文分词器之一 - 资源篇 首先感谢52nlp的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- es5.0 安装ik中文分词器 mac
es5.0集成ik中文分词器,网上资料很多,但是讲的有点乱,有的方法甚至不能正常运行此插件 特别注意的而是,es的版本一定要和ik插件的版本相对应: 1,下载ik 插件: https://github ...
随机推荐
- Java中Semaphore(信号量) 数据库连接池
计数信号量用来控制同时访问某个特定资源的操作数或同时执行某个指定操作的数量 A counting semaphore.Conceptually, a semaphore maintains a set ...
- ASP.NET Core:WebAppCoreApi
ylbtech-ASP.NET Core:WebAppCoreApi 1.返回顶部 1. 2. 3. 4. 2. Controllers返回顶部 1.ValuesControlle ...
- 用 SDL2 加载PNG平铺背景并显示前景
上一篇中加载的是BMP,这次可以引用 SDL2_image.lib,加载更多格式的图像. LoadImage函数做了改动,区别在于不用将surface转换成texture了. 环境:SDL2 + VC ...
- 【215】◀▶ IDL 文件操作说明
参考:I/O - General File Access Routines —— 基本文件操作函数 01 CD 修改当前的工作空间路径. 02 FILE_SEARCH 对文件名进行特定的查找. ...
- 任务46:Identity MVC:登录逻辑实现
任务46:Identity MVC:登录逻辑实现 实现登陆的方法 退出方法 _layout里面增加如下的代码: Login.cshtml 运行代码测试: 这个地方的单词之前拼错了.这里进行修正 输入账 ...
- 3DMAX 9 角色建模3 uv展开
将角色删除一半,展好uv再镜像出来,节省一半工作量(前提是对称) 添加UVW展开编辑器(Unwrap UVW),选择面 打开UV编辑器 这里要注意映射问题,默认打开UV编辑器后所选择的面是映射到与选择 ...
- P5110 块速递推
传送门 为啥我就没看出来有循环节呢-- 打表可得,这个数列是有循环节的,循环节为\(10^9+6\),然后分块预处理,即取\(k=sqrt(10^9+6)\),然后分别预处理出转移矩阵\(A\)的\( ...
- NowCoder数列
题目:https://www.nowcoder.com/questionTerminal/0984adf1f55a4ba18dade28f1ab15003 #include <iostream& ...
- MySql | 常用操作总结
创建数据库: CREATE DATABASE 数据库名; 删除数据库名: drop database <数据库名>; 选择数据库: use 数据库名; 创建数据表: CREATE TABL ...
- Magic Numbers CodeForces - 628D
Magic Numbers CodeForces - 628D dp函数中:pos表示当前处理到从前向后的第i位(从1开始编号),remain表示处理到当前位为止共产生了除以m的余数remain. 不 ...