TensorFlow+Keras 02 深度学习的原理
1 神经传递的原理
人类的神经元传递及其作用:
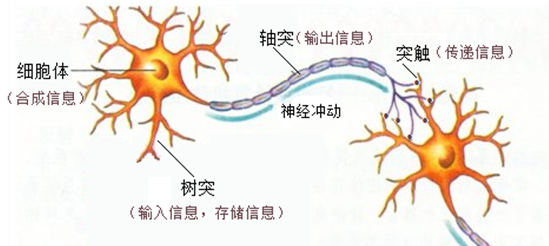
这里有几个关键概念:
- 树突 - 接受信息
- 轴突 - 输出信息
- 突触 - 传递信息
将其延伸到神经元中,示意图如下:
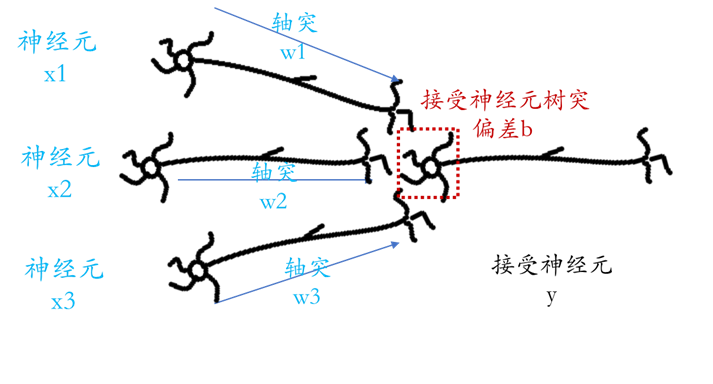
将上图整理成数学公式,则有
y = activation function( x1*w1 + x2*w2 + x3*w3 + b )
相应说明:
- x - 输入值,仿真输入神经元,上图中有:x1、x2、x3
- w - 权重值,仿真输入神经元轴突,传送信息,上图中有:w1、w2、w3
- b - 偏差值,仿真接受神经元树突,代表接受神经元容易被活化的程度,偏差值越高、越容易被激活,上图中接受神经元只有一个,所以也只有一个偏差值b。
- y - 通过一些列信息传导(激活函数运算),最终接受神经元所得到的值,也可以理解为输入神经元 x 有效传递了多少值
- 激活函数 - activation function ,仿真神经传递的工作方式,当接受神经元接收到刺激的总和(x1*w1 + x2*w2 + x3*w3 + b)经过激活函数的运算后,其值大于临界值时,就会传递至下一个神经元,常见的激活函数如Sigmoid、ReLU。
Sigmoid 激活函数
激活函数通常为非线性函数,其可仿真神经传导的工作方式将上一层神经元信号传递到下一层中。
TensorFlow 和 Keras 支持很多激活函数,常用的有两种:Sigmoid 和 ReLU。
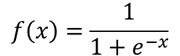
函数图像如下:
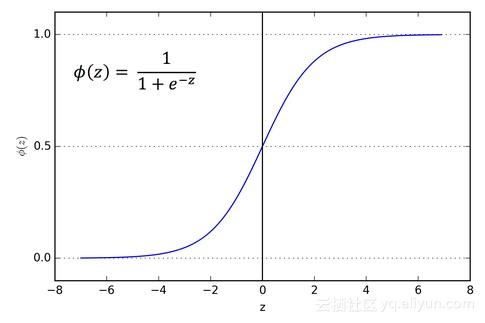
Sigmoid 激活函数类似于人类感觉神经:
- 小于临界值时,刺激被被忽略
- 大于临界值时,刺激会被接受
- 达到一定程度时,感觉会钝化,即使接受更大的刺激,感觉仍维持不变,如上图中为一条直线。
ReLU 激活函数
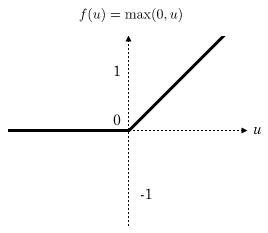
对比人类神经网络,可理解为:
- 小于临界值时,刺激会被忽略
- 大于临界值时,刺激被接受
2 以矩阵运算仿真神经网络
实际的神经网络存在有较多的值,此时一般用矩阵表示。
y = activation(x * w +b )
- x - 输入值,矩阵
- w - 权重值,矩阵
- b - 偏差值,矩阵
- y - 计算结果,矩阵
3 多层感知器模型
多层感知器(Multilayar Perceptron ,MLP)模型是一种受欢迎的及其学习解决方案,尤其是在语音识别、图像识别、和机器翻译等多个领域;20世纪90年代,MLP模型遭遇到更简单模型(如支持向量机SVM)的强烈竞争,近年来,由于深度学习的成功,MLP模型又重新收到业界重视。
以多层感知器模型识别MNIST手写数字图像为例,一般有
- 输入层 input layer
- 隐藏层 hidden layer
- 输出层 output layer
建立输入层与隐藏层的映射关系公式:h1 = ReLU ( x * w1 + b1 )
建立隐藏层与输出层的映射关系公式:y = softmax ( h1 * w2 + b2 )
4 使用反向传播算法进行训练
反向传播(Back Propagation)是训练人工神经网络的常见方法,且与优化器(Optimizer,如梯度下降法)结合使用。
反向传播是一种有监督的学习方法,必须有特征值features 和 标签 label
4.1 训练前必须先进行 ” 数据预处理 “ 和 ” 建立模型 “
4.1.1 数据预处理
MNIST 数据集经过数据预处理产生 数字图像特征值features和图像标签 label;备用。
4.1.2 建立模型
建立多层感知模型,并以随机数初始化模型的权重weight 和偏差值 bias。
4.2 反向传播算法训练多层感知器模型
进行训练时,数据分多批次喂入(如每次200项数据)进行模型训练;重复传播以使权重更新( weight update ),直到误差 bias 收敛。
4.2.1 传播
1 - 向模型中喂入数据
2 - 模型输出计算结果
4.2.2 权重更新
1 - 损失函数计算误差。使用损失函数计算模型输出结果(预测结果)与 Label 标签之间的误差值
2 - 优化器更新权重与偏差。基于误差值更新权重和偏差,以使损失函数的误差值最小化。
4.3 损失函数
损失函数来帮助我们计算误差,其中 Cross Entropy 是深度学习常用的损失函数。
4.4 优化器
优化器是使用某种数值方法在不断的批次训练中不断更新权重与偏差,是损失函数的误差值最小化,并最终找到误差值最小的 ” 权重与偏差的组合 "。
在深度学习中,常用随机梯度下降法(Stochastic Gradient Descent , SGD)来优化权重和偏差。
另外,还有许多随机梯度下降法的变形,如 RMSprop、Adagrad、Adadelta、Adam 等,这些适用于不同的深度学习模型,
5 附件:不同的优化器具有不同的训练效果图
Alec Radford's animations for optimization algorithms(Alec Radford的优化算法动画)
地址:http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html
原文摘录:
Alec Radford创建了一些伟大的动画,比较优化算法SGD,Momentum,NAG,Adagrad,Adadelta,RMSprop(不幸的是没有Adam)的低维问题。另请查看他关于RNN的演讲。
Alec Radford has created some great animations comparing optimization algorithms SGD, Momentum, NAG, Adagrad, Adadelta, RMSprop(unfortunately no Adam) on low dimensional problems. Also check out his presentation on RNNs.
“ 嘈杂的卫星:这是来自sklearn的嘈杂卫星数据集的逻辑回归,它显示了基于动量的技术的平滑效果(这也导致过度射击和校正)。误差表面在经验上可视化为整个数据集的平均值,但是轨迹显示了微型数据在噪声数据上的动态。下图是精确度图。“
"Noisy moons: This is logistic regression on noisy moons dataset from sklearn which shows the smoothing effects of momentum based techniques (which also results in over shooting and correction). The error surface is visualized as an average over the whole dataset empirically, but the trajectories show the dynamics of minibatches on noisy data. The bottom chart is an accuracy plot."
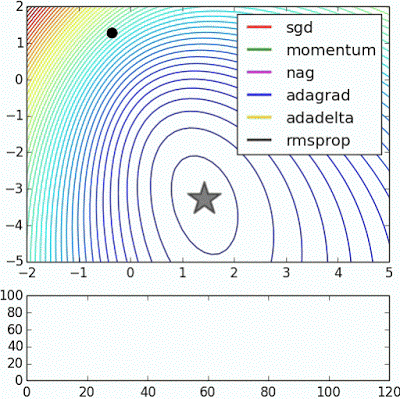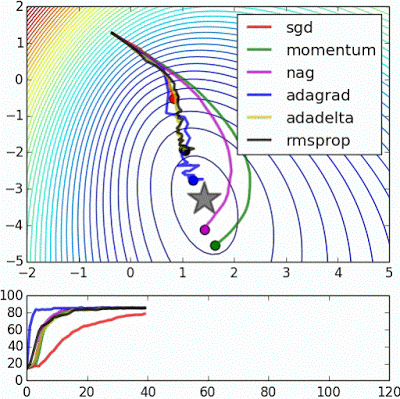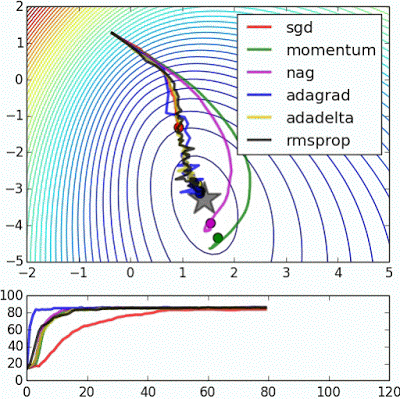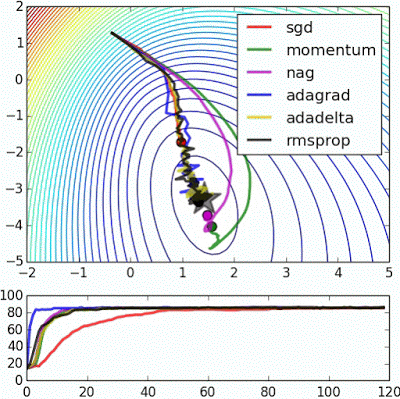
“ Beale的功能:由于大的初始梯度,基于速度的技术射击和反弹 - adagrad几乎变得不稳定,出于同样的原因。像adadelta和RMSProp那样缩放渐变/步长的算法更像加速SGD并处理大的渐变更稳定。“
"Beale's function: Due to the large initial gradient, velocity based techniques shoot off and bounce around - adagrad almost goes unstable for the same reason. Algos that scale gradients/step sizes like adadelta and RMSProp proceed more like accelerated SGD and handle large gradients with more stability."
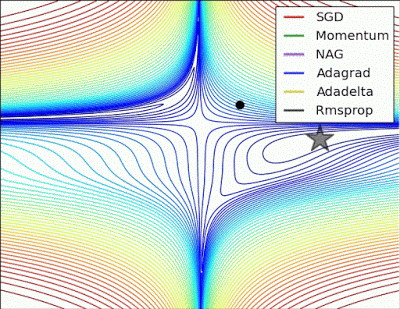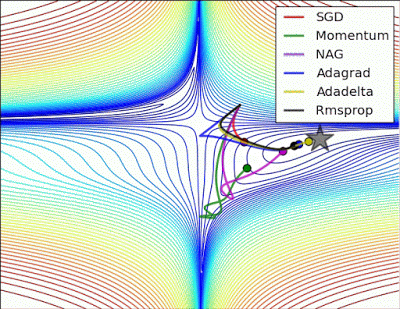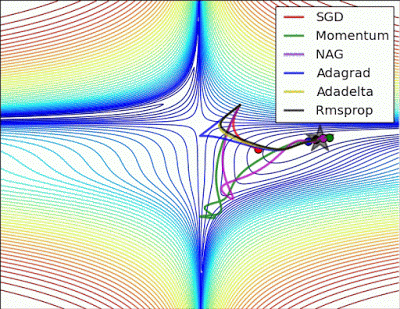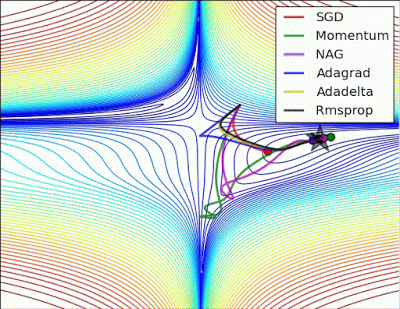
“ 长谷:没有根据梯度信息进行缩放的Algos在这里很难打破对称性 - SGD没有在哪里和Nesterov加速梯度/动量呈现振荡,直到它们在优化方向上建立速度。阿尔戈斯基于梯度快速缩放步长打破对称并开始下降。“
"Long valley: Algos without scaling based on gradient information really struggle to break symmetry here - SGD gets no where and Nesterov Accelerated Gradient / Momentum exhibits oscillations until they build up velocity in the optimization direction. Algos that scale step size based on the gradient quickly break symmetry and begin descent."
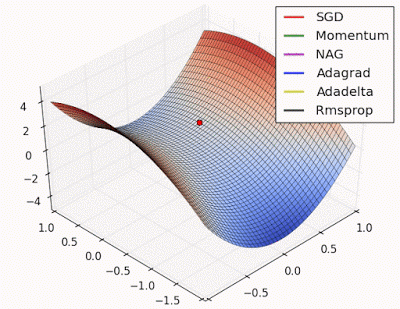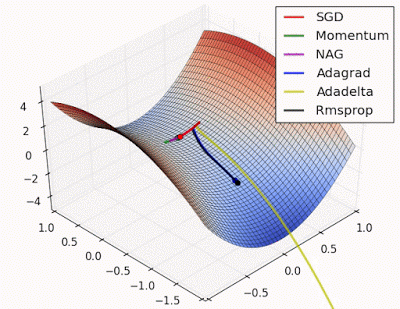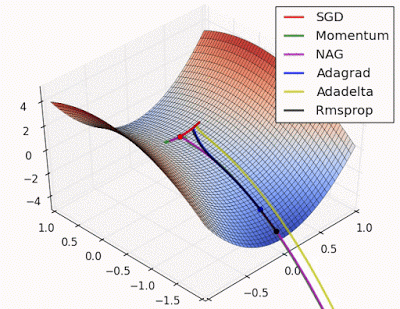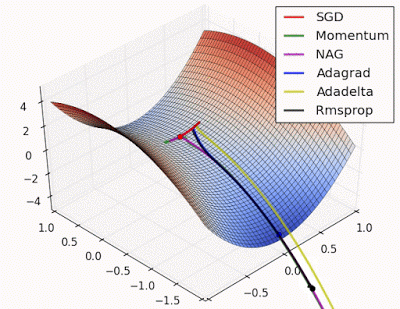
“ 鞍点:围绕鞍点的行为.NAG / Momentum再次喜欢探索周围,几乎采取不同的路径.Adadelta / Adagrad / RMSProp像加速SGD一样前进。”
"Saddle point: Behavior around a saddle point. NAG/Momentum again like to explore around, almost taking a different path. Adadelta/Adagrad/RMSProp proceed like accelerated SGD."

TensorFlow+Keras 02 深度学习的原理的更多相关文章
- ubuntu16.04+七彩虹GTX1060的NVIDIA驱动+Cuda8.0+cudnn5.1+tensorflow+keras搭建深度学习环境【学习笔记】【原创】
平台信息:PC:ubuntu16.04.i5.七彩虹GTX1060显卡 作者:庄泽彬(欢迎转载,请注明作者) 说明:参考了网上的一堆的资料搭建了深度学习的开发环境,下班在宿舍折腾了好几个晚上才搞定,写 ...
- Tensorflow 2.0 深度学习实战 —— 详细介绍损失函数、优化器、激活函数、多层感知机的实现原理
前言 AI 人工智能包含了机器学习与深度学习,在前几篇文章曾经介绍过机器学习的基础知识,包括了监督学习和无监督学习,有兴趣的朋友可以阅读< Python 机器学习实战 >.而深度学习开始只 ...
- 使用Keras进行深度学习:(七)GRU讲解及实践
####欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 介绍 GRU(Gated Recurrent Unit) ...
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 基于 Keras 用深度学习预测时间序列
目录 基于 Keras 用深度学习预测时间序列 问题描述 多层感知机回归 多层感知机回归结合"窗口法" 改进方向 扩展阅读 本文主要参考了 Jason Brownlee 的博文 T ...
- 基于TensorFlow Serving的深度学习在线预估
一.前言 随着深度学习在图像.语言.广告点击率预估等各个领域不断发展,很多团队开始探索深度学习技术在业务层面的实践与应用.而在广告CTR预估方面,新模型也是层出不穷: Wide and Deep[1] ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
随机推荐
- Codeforces 300C Beautiful Numbers 【组合数】+【逆元】
<题目链接> 题目大意: 给出a和b,如果一个数每一位都是a或b,那么我们称这个数为good,在good的基础上,如果这个数的每一位之和也是good,那么这个数是excellent.求长度 ...
- this 相关
对于前端程序媛(员)来说,this这个机制应用的地方是很多的,所以搞懂是必要的,不熟练使用this将遇到一些困惑,下面是一些关于this的学习心得分享,希望大家可以一起学习: 1,this并不是指向自 ...
- C# LnkHelper
using System; using System.Collections.Generic; using System.Text; using Microsoft.Win32; using Syst ...
- Django之ORM字段和字段参数
ORM介绍 ORM概念 ORM由来 ORM的优势 ORM的劣势 ORM总结 Django中的ORM Django项目使用MySQL数据库 Model 快速入门 字段 自定义字段 字段参数 Model ...
- Java 8 (二) 新的时间API
新的时间API 一)时间线 Instant对象:表示时间轴上的一个点,原点为1970-1-1的午夜. Duration对象:表示一段时间. 注意Instant和Duration类都是final. 二) ...
- 深入浅出 SVG
前言 据悉,8月18号将在广州举办中国第一届React开发者大会.今日早读文章由@Starrier翻译分享. 正文从这开始- SVG 是优秀且令人难以置信的强大图像格式.本教程通过简单地解释所有需要了 ...
- [Tyvj1001]第K极值 (贪心?模拟)
考前打tyvj的水题 题目描述 给定一个长度为N(0<n<=10000)的序列,保证每一个序列中的数字a[i]是小于maxlongint的非负整数 ,编程要求求出整个序列中第k大的数字减去 ...
- 获取url参数的精简代码
题目描述 获取 url 中的参数 指定参数名称,返回该参数的值 或者 空字符串 不指定参数名称,返回全部的参数对象 或者 {} 如果存在多个同名参数,则返回数组 输入例子: getUrlParam(' ...
- Ubuntu1404 开启定时任务 crontab
crontab -e 这个 我使用vim编辑,所以选择3,进入到 写了两条,的确隔了一分钟在test.txt文件夹里面会多加一条Good morning进去.而且也会执行dingshi.sh这个she ...
- Vue(四)事件和属性
1. 事件 1.1 事件简写 v-on:click="" 简写方式 @click="" <button v-on:click="show&quo ...