Hadoop2.7.6_05_mapreduce-Yarn
1. MAPREDUCE原理
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上;
1.1. 为什么要MAPREDUCE
(1)海量数据在单机上处理因为硬件资源限制,无法胜任
(2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度
(3)引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
设想一个海量数据场景下的wordcount需求:
单机版:内存受限,磁盘受限,运算能力受限
分布式:
、文件分布式存储(HDFS)
、运算逻辑需要至少分成2个阶段(一个阶段独立并发,一个阶段汇聚)
、运算程序如何分发
、程序如何分配运算任务(切片)
、两阶段的程序如何启动?如何协调?
、整个程序运行过程中的监控?容错?重试?
可见在程序由单机版扩成分布式时,会引入大量的复杂工作。为了提高开发效率,可以将分布式程序中的公共功能封装成框架,让开发人员可以将精力集中于业务逻辑。
而mapreduce就是这样一个分布式程序的通用框架,其应对以上问题的整体结构如下:
、MRAppMaster(mapreduce application master)
、MapTask
、ReduceTask
1.2. MAPREDUCE框架结构及核心运行机制
1.2.1. 结构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
1.2.2. MR程序运行流程
1.2.2.1. 流程示意图
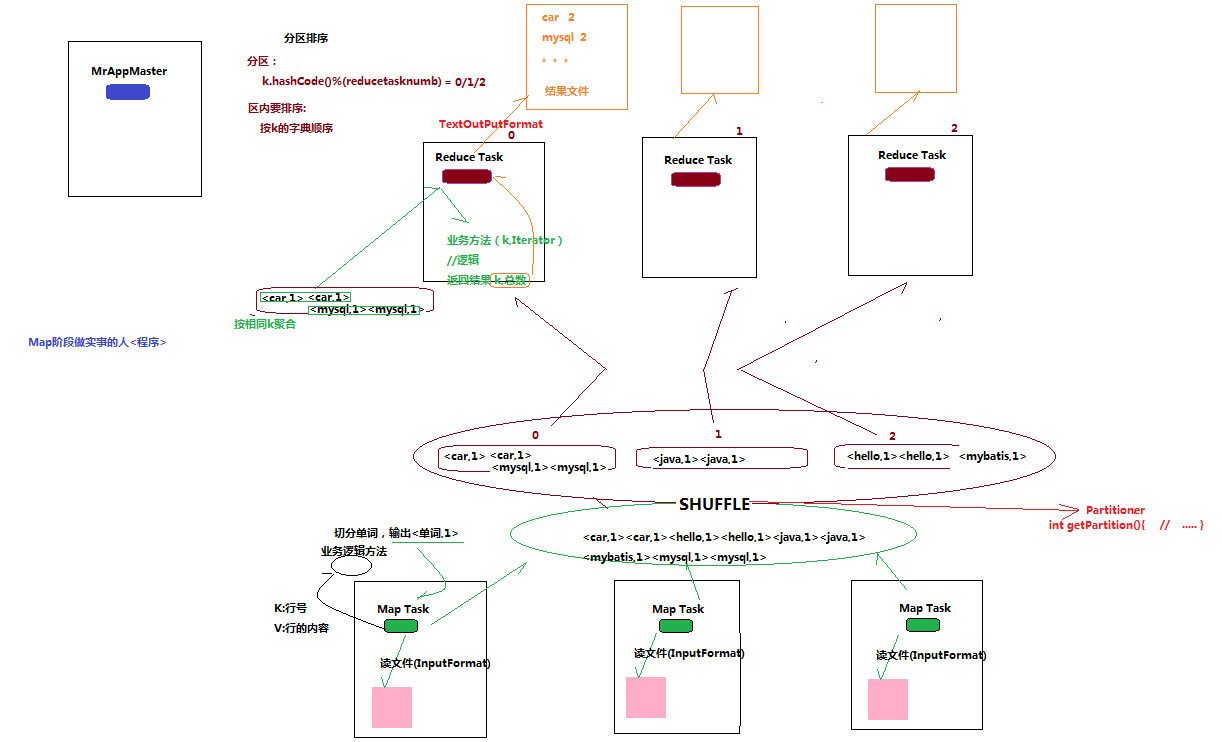
1.2.2.2. 流程解析
1、 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程
2、 maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件
3、 MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区)
4、 Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
1.3. MapTask并行度决定机制
maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度
那么,mapTask并行实例是否越多越好呢?其并行度又是如何决定呢?
1.3.1. mapTask并行度的决定机制
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:

1.3.2. FileInputFormat切片机制

1、切片定义在InputFormat类中的getSplit()方法
2、FileInputFormat中默认的切片机制:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
比如待处理数据有两个文件:
file1.txt 320M
file2.txt 10M
经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- ~
file1.txt.split2-- ~
file1.txt.split3-- ~
file2.txt.split1-- ~10M
3、FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定
minsize:默认值:
配置参数: mapreduce.input.fileinputformat.split.minsize maxsize:默认值:Long.MAXValue
配置参数:mapreduce.input.fileinputformat.split.maxsize
因此,默认情况下,切片大小=blocksize
maxsize(切片最大值):
参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minsize (切片最小值):
参数调的比blockSize大,则可以让切片变得比blocksize还大
选择并发数的影响因素:
1、运算节点的硬件配置
2、运算任务的类型:CPU密集型还是IO密集型
3、运算任务的数据量
1.4. map并行度的经验之谈
如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20-100个map,最好每个map的执行时间至少一分钟。
- 如果job的每个map或者 reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数,每一个task(map|reduce)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。
配置task的JVM重用可以改善该问题:
(mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task
数目(属于同一个Job)是1。也就是说一个task启一个JVM) JVM重用技术不是指同一Job的两个或两个以上的task可以同时运行于同一JVM上,而是排队按顺序执行。
- 如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB
1.5. ReduceTask并行度的决定
reducetask的并行度同样影响整个job的执行并发度和执行效率,但与maptask的并发数由切片数决定不同,Reducetask数量的决定是可以直接手动设置:
//默认值是1,手动设置为4
job.setNumReduceTasks();
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意: reducetask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reducetask 尽量不要运行太多的reduce task。对大多数job来说,最好rduce的个数最多和集群中的reduce持平,或者比集群的 reduce slots小。这个对于小集群而言,尤其重要。
1.6. mapreduce&yarn的工作机制
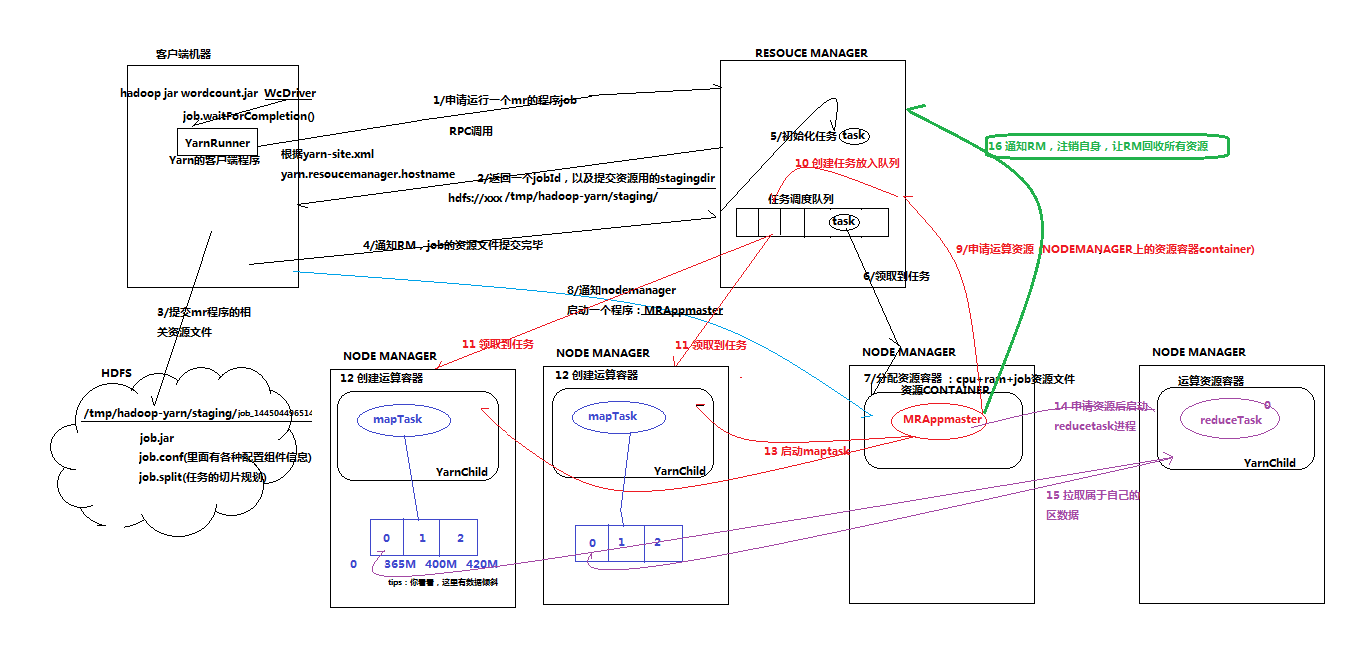
============================== 或者
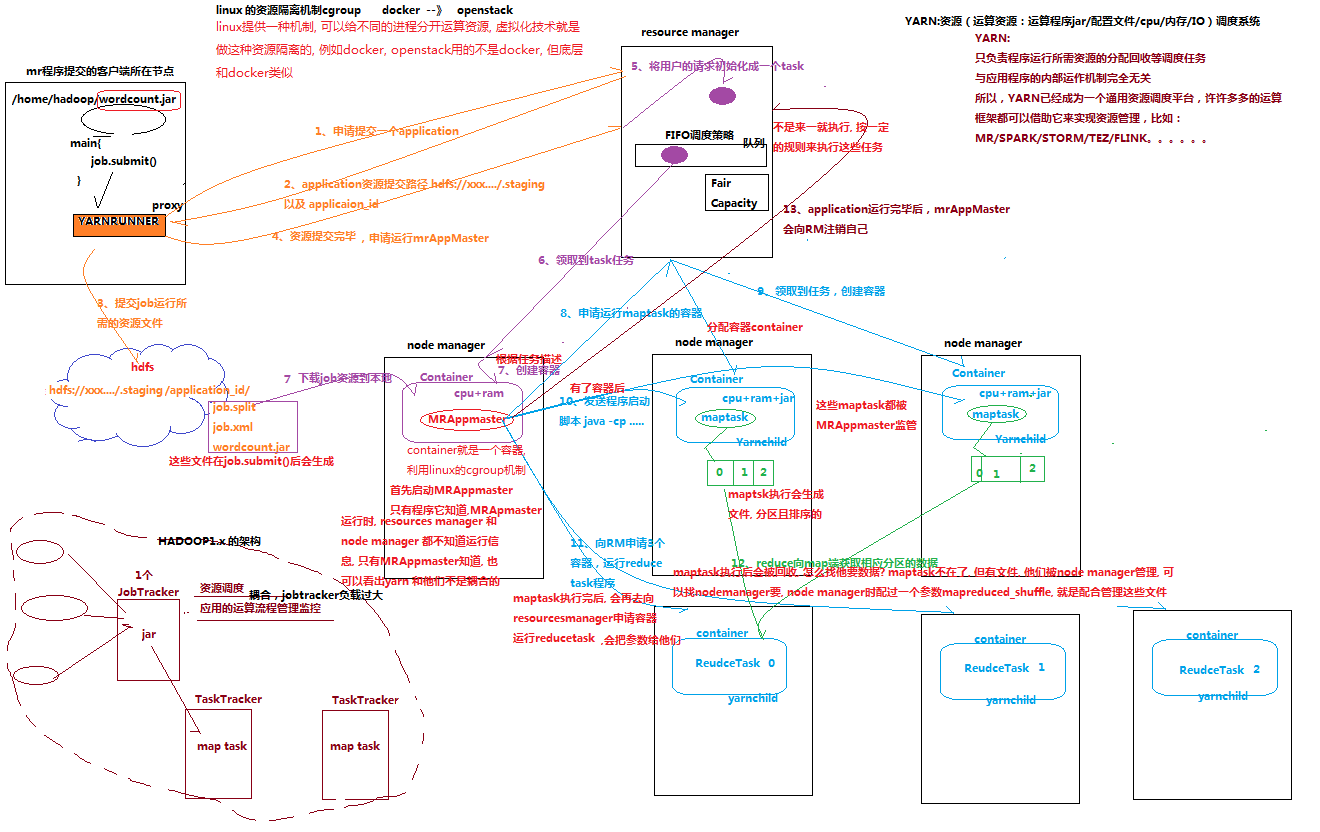
描述如下:
、程序找到resource manager,申请提交一个application
、resource manager返回application资源提交路径 hdfs://xxx.../.staging和application_id
、提交job运行所需的资源文件到HDFS,路径为 hdfs://xxx.../.staging/application_id/{job.split,job.xml,wordcount.jar}
、告诉resource manager资源提交完毕,申请运行MRAppMaster
、将用户的请求初始化成一个task
如果任务系统繁忙,那么resource manager 根据调度策略判断执行task
、node manager 领取到task任务
、对应的node manager 生成响应的容器【容器中有CPU+MEM】,并且到HDFS下载job资源到本地,之后运行MRAppMaster
那么MRAppMaster可以读到job中的信息,就知道了切片信息,需要启动多少个maptask和多少个reducetask等等
比如此处为2个maptask和3个reducetask
、MRAppMaster 向 resource manager申请2个maptask容器
、node manger 领取到 maptask 任务,创建容器【CPU+MEM+jar】
【进程的默认名字 yarnchild】
、MRAppMaster 发启动命令到maptask,最后maptask输出运行结果
该maptask会受到 MRAppMaster 监管
如果maptask运行失败或缓慢,那么 MRAppMaster 会申请另一个相同的maptask
、MRAppMaster 向 resource manager申请3个reducetask容器
、node manger 领取到 reducetask 任务,创建容器【CPU+MEM+数据】
【进程的默认名字 yarnchild】
其中数据为:reduce向map读取的相应分区的数据
、MRAppMaster 发启动命令到reducetask,最后reducetask输出运行结果
该reducetask会受到 MRAppMaster 监管
、application运行完毕后,MRAppMaster 会向 resource manager 注销自己
2. mapreduce数据压缩
2.1. 概述
这是mapreduce的一种优化策略:通过压缩编码对mapper或者reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)
1、 Mapreduce支持将map输出的结果或者reduce输出的结果进行压缩,以减少网络IO或最终输出数据的体积
2、 压缩特性运用得当能提高性能,但运用不当也可能降低性能
3、 基本原则:
运算密集型的job,少用压缩 IO密集型的job,多用压缩
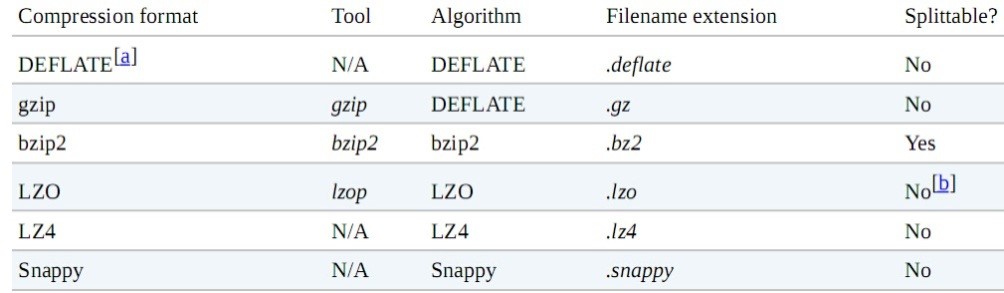
2.2. MR支持的压缩编码
2.3. Reducer输出压缩
在配置参数或在代码中都可以设置reduce的输出压缩
# 、在java配置参数中设置
mapreduce.output.fileoutputformat.compress=false
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
mapreduce.output.fileoutputformat.compress.type=RECORD
// 2、在代码中设置
Job job = Job.getInstance(conf);
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, (Class<? extends CompressionCodec>) Class.forName(""));
2.4. Mapper输出压缩
在配置参数或在代码中都可以设置reduce的输出压缩
# 、在java配置参数中设置
mapreduce.map.output.compress=false
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaultCodec
// 2、在代码中设置:
conf.setBoolean(Job.MAP_OUTPUT_COMPRESS, true);
conf.setClass(Job.MAP_OUTPUT_COMPRESS_CODEC, GzipCodec.class, CompressionCodec.class);
3. MapReduce与YARN
3.1. YARN概述
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
3.2. YARN的重要概念
1、 yarn并不清楚用户提交的程序的运行机制
2、 yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3、 yarn中的主管角色叫ResourceManager
4、 yarn中具体提供运算资源的角色叫NodeManager
5、 这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……
6、 所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
7、 Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
Hadoop2.7.6_05_mapreduce-Yarn的更多相关文章
- Hadoop2.2.0(yarn)编译部署手册
Created on 2014-3-30URL : http://www.cnblogs.com/zhxfl/p/3633919.html @author: zhxfl Hadoop-2.2编译 ...
- 【原创 Hadoop&Spark 动手实践 4】Hadoop2.7.3 YARN原理与动手实践
简介 Apache Hadoop 2.0 包含 YARN,它将资源管理和处理组件分开.基于 YARN 的架构不受 MapReduce 约束.本文将介绍 YARN,以及它相对于 Hadoop 中以前的分 ...
- Hadoop2.0之YARN
YARN(Yet Another Resource Negotiator)是Hadoop2.0集群中负责资源管理和调度以及监控运行在它上面的各种应用,是hadoop2.0中的核心,它类似于一个分布式操 ...
- Hadoop2.7.4 yarn(HA)集群搭建步骤(CentOS7)
群节点分配: Park01:Zookeeper.NameNode(active).ResourceManager(active) Park02:Zookeeper.NameNode(standby) ...
- Hadoop2.0之YARN组件
官方文档:https://hadoop.apache.org/docs/stable/,目前官方已经是3.x,但yarn机制没有太大变化 一.简介 在Hadoop1.0中,没有yarn,所有的任务调度 ...
- 基于Hadoop2.0、YARN技术的大数据高阶应用实战(Hadoop2.0\YARN\Ma
Hadoop的前景 随着云计算.大数据迅速发展,亟需用hadoop解决大数据量高并发访问的瓶颈.谷歌.淘宝.百度.京东等底层都应用hadoop.越来越多的企 业急需引入hadoop技术人才.由于掌握H ...
- 在Ubuntu下配置运行Hadoop2.4.0单节点配置
还没有修改hosts,请先按前文修改. 还没安装java的,请按照前文配置. (1)增加用户并设立公钥: sudo addgroup hadoop sudo adduser --ingroup had ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- YARN内存使用优化配置
在Hadoop2.0中, YARN负责管理MapReduce中的资源(内存, CPU等)并且将其打包成Container. 这样可以精简MapReduce, 使之专注于其擅长的数据处理任务, 将无需考 ...
随机推荐
- 从零开始学 Web 之 JavaScript(五)面向对象
大家好,这里是「 Daotin的梦呓 」从零开始学 Web 系列教程.此文首发于「 Daotin的梦呓 」公众号,欢迎大家订阅关注.在这里我会从 Web 前端零基础开始,一步步学习 Web 相关的知识 ...
- Netty自带连接池的使用
一.类介绍1.ChannelPool——连接池接口 2.SimpleChannelPool——实现ChannelPool接口,简单的连接池实现 3.FixedChannelPool——继承Simple ...
- OS开发(2):自定义tabbar | 导航条 | 突显中间按钮
tabbar是放在APP底部的控件,也叫navigationbar或导航条.常见的APP都使用tabbar来进行功能分类的管理,比如微信.QQ等等. 需求是这样的,需要一个特殊一点的tabbar,要求 ...
- python元祖操作和内置方法
1 元祖:元祖可以理解为一个不可变的列表 2 用途:用于存放多个值,当存放的多个值只有读的需求而没有改的需求时用元祖最合适 3 定义:在()内用逗号分隔开多个任意类型的值.注意:当只有一个元素的时候, ...
- 你不知道的Linux(持续更新中)
1.关于GNU.Linux.GNU/Linux三者的关系 GNU 项目创始于一九八四年,旨在开发一个类似 Unix ,且为自由软件的完整的操作系统: GNU 系统.(也可把GNU看成一个自由软件工程) ...
- LeetCode两数之和-Python<一>
下一篇:LeetCode链表相加-Python<二> 题目:https://leetcode-cn.com/problems/two-sum/description/ 给定一个整数数组和一 ...
- ModBus通信协议的【传输方式】
1.Modbus 传输方式 标准的Modbus口是使用一RS-232C兼容串行接口,它定义了连接口的针脚.电缆.信号位.传输波特率.奇偶校验.控制器能直接或经由Modem组网. 控制器通信使用 ...
- 二进制值和十六进制字符串相互转换的C++代码
#include <iostream> #include <string> #include <stdint.h> using namespace std; str ...
- Nginx学习笔记(二)--- 配置虚拟主机
Linux下安装Nginx https://www.cnblogs.com/dddyyy/p/9780705.html 1.虚拟主机介绍 一台服务器分成多个"独立"的主机,每台虚 ...
- HDU6095
Rikka with Competition Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/O ...